架构师必备:本地缓存原理和应用
先说结论:本地缓存优先选用caffeine,因为性能比guava cache快,api风格与之兼容、能轻松地平滑迁移,并且在spring/spring boot最新版本中已经是默认本地缓存了。下面展开讲讲本地缓存和Spring cache。
本文讨论堆内缓存,暂不讨论堆外缓存。堆内缓存是指缓存与应用程序在一个JVM应用中,会受GC影响,一般业务层面的应用开发用不到堆外缓存。
1、什么场景使用本地缓存
并非所有的缓存场景,redis都适用,以下情况应当优先考虑本地缓存。
- 数据量不大
- 修改频率低、甚至是静态的数据
- 查询qps极高:通过纯内存操作,避免网络请求
- 对性能有极致要求,速度比redis更快
如:秒杀热点商品缓存、地域信息缓存。
2、缓存基本原理
先简单回顾一下缓存的基本原理。
语义
- get:根据key查询value,缓存未命中时查询底层数据并设置缓存
- put:设置缓存
- evict:删除key
- ttl:kv键值对过期失效
淘汰策略
缓存有大小上限,超过后需要淘汰掉冷数据,保留真正的热数据,以确保缓存命中率。有2种常见算法:LRU和LFU。
LRU(Least Recently Used)
优先淘汰掉最近最少使用的数据,该算法假设最近访问的数据,将来也会频繁地使用。
- 优点 容易理解和实现
- 链表占用空间小
-
临时批量数据,会把真正的热数据冲掉,而造成缓存命中率急剧下降,影响性能
下面给出LRU算法的2种伪代码实现:
- LinkedHashMap实现:LinkedHashMap底层数据结构就是一个HashMap和双向链表的结合体,可以借助它快速实现LRU算法。
public class LRUCache extends LinkedHashMap {
// 缓存最大条目数
private int maxSize;
public LRUCache(int maxSize) {
// 初始大小为16,loadFactor为0.75,accessOrder按访问顺序排列为true
super(16, 0.75f, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
// 大小超过maxSize时,删除最久远的数据
return size() > maxSize;
}
}
- Map+Deque实现: Deque双端队列队尾是最新数据,队首是最久远数据
- 最新访问的元素,如果已存在,则移动至队尾,否则直接插入队尾
- put时如果已满,则删除队首元素
// 泛型支持
public class LRUCache<K, V> {
private int maxSize;
private Map<K, V> map = new HashMap<>();
// 双端队列,用于记录访问的远近;LinkedList是Deque的子类
private LinkedList<K> recencyList = new LinkedList<>();
public LRUCache(int maxSize) {
this.maxSize = maxSize;
}
public V get(K key) {
if (map.containsKey(key)) {
moveToTail(key);
return map.get(key);
} else {
return null;
}
}
public void put(K key, V value) {
if (map.containsKey(key)) {
moveToTail(key);
} else {
addToTail(key);
}
map.put(key, value);
if (map.size() > maxSize) {
removeEldest();
}
}
private void moveToTail(K key) {
recencyList.remove(key);
recencyList.add(key);
}
private void addToTail(K key) {
recencyList.add(key);
}
private void removeEldest(K key) {
recencyList.removeFirst(key);
}
}
LFU(Least Frequently Used)
优先淘汰掉最不经常使用的数据,该算法假设最近使用频率高的数据,将来也会频繁地使用。
- 优点 统计了key的访问频率,淘汰掉的数据大概率是冷数据
- 不会受临时批量数据的影响
-
占用更大的内存,需要额外记录key的访问频率的数据结构
public class LFUCache {
// 容量大小
int cap;
// 最小的频次
int minFreq;
// key到val的映射
HashMap<Integer, Integer> key2Val;
// key到freq的映射
HashMap<Integer, Integer> key2Freq;
// freq到key列表的映射
HashMap<Integer, LinkedHashSet<Integer>> freq2Keys;
public LFUCache(int capacity) {
this.cap = capacity;
this.minFreq = 0;
key2Val = new HashMap<>();
key2Freq = new HashMap<>();
freq2Keys = new HashMap<>();
}
public int get(int key) {
if (!key2Val.containsKey(key)) {
return -1;
}
// 增加访问频次
increaseFreq(key);
return key2Val.get(key);
}
public void put(int key, int value) {
if (this.cap == 0) {
return;
}
// 判断是否包含key,包含直接增加访问频次,更新值
if (key2Val.containsKey(key)) {
// 增加访问频次
increaseFreq(key);
key2Val.put(key, value);
return;
}
// 不包含,判断是否达到容量,达到容量删除最少频次,最先访问的元素
if (key2Val.size() >= this.cap) {
removeMinFreqKey();
}
// 保存数据,更新频次
key2Val.put(key, value);
// 设置key热度
key2Freq.put(key, 1);
freq2Keys.putIfAbsent(1, new LinkedHashSet<>());
// 热度与key关联
freq2Keys.get(1).add(key);
this.minFreq = 1;
}
private void increaseFreq(Integer key) {
int freq = key2Freq.get(key);
// 增加热度
key2Freq.put(key, freq + 1);
freq2Keys.putIfAbsent(freq + 1, new LinkedHashSet<>());
freq2Keys.get(freq + 1).add(key);
// 调整热度与key关系的数据
freq2Keys.get(freq).remove(key);
if (freq2Keys.get(freq).size() == 0) {
freq2Keys.remove(freq);
if (freq == this.minFreq) {
this.minFreq++;
}
}
}
private void removeMinFreqKey() {
// 查看最小的热度
// 找到最先访问的key
int oldKey = freq2Keys.get(this.minFreq).iterator().next();
// 删除key及val
key2Val.remove(oldKey);
key2Freq.remove(oldKey);
// 删除热度与key的关系
freq2Keys.get(this.minFreq).remove(oldKey);
if (freq2Keys.get(this.minFreq).size() == 0) {
freq2Keys.remove(this.minFreq);
}
}
}
3、Guava cache大致原理
- 淘汰策略使用LRU算法
- 使用了2个队列accessQueue、writeQueue,分别记录读、写缓存时数据访问和写入的顺序,更加精细
- 惰性删除:访问缓存的时候判断数据是否过期,如果过期才将其删除,并没有专门的后台线程来删除过期数据
- 并发:map数据结构类似ConcurrentHashMap,有多个segment,不同segment之间的读写可并发;
4、caffeine大致原理
- 淘汰策略使用window tiny-lfu算法,是一种高效的近似LFU算法
- 使用3个队列:WindowDeque作为前置的LRU,ProbationDeque(试用期队列)、ProtectedDeque(受保护队列),当WindowDeque满时,会进入Segmented LRU中的ProbationDeque,在后续被访问到时,它会被提升到ProtectedDeque。当ProtectedDeque满时,会有数据降级到ProbationDeque
- 异步淘汰数据
下面是从github wiki和高性能缓存 Caffeine 原理及实战 摘抄的。
一、近似统计频率,而非精确:采用 Count–Min Sketch 算法降低频率信息带来的内存消耗; 二、维护一个PK机制保证新进入的热点数据能够缓存。
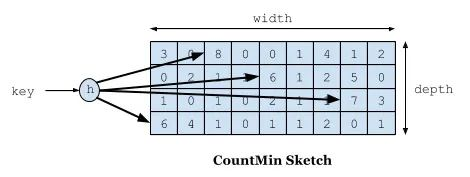
如下图所示,Count–Min Sketch 算法类似布隆过滤器 (Bloom filter)思想,对于频率统计我们其实不需要一个精确值。存储数据时,对key进行多次 hash 函数运算后,二维数组不同位置存储频率(Caffeine 实际实现的时候是用一维 long 型数组,每个 long 型数字切分成16份,每份4bit,默认15次为最高访问频率,每个key实际 hash 了四次,落在不同 long 型数字的16份中某个位置)。读取某个key的访问次数时,会比较所有位置上的频率值,取最小值返回。对于所有key的访问频率之和有个最大值,当达到最大值时,会进行reset即对各个缓存key的频率除以2。
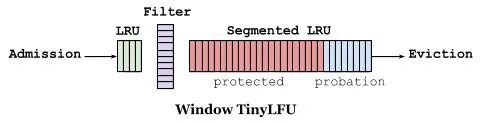
如下图缓存访问频率存储主要分为两大部分,即 LRU 和 Segmented LRU 。新访问的数据会进入第一个 LRU,在 Caffeine 里叫 WindowDeque。当 WindowDeque 满时,会进入 Segmented LRU 中的 ProbationDeque,在后续被访问到时,它会被提升到 ProtectedDeque。当 ProtectedDeque 满时,会有数据降级到 ProbationDeque 。数据需要淘汰的时候,对 ProbationDeque 中的数据进行淘汰。具体淘汰机制:取ProbationDeque 中的队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者频率大小,大胜小汰。
5、Spring cache使用示例
通过Spring可以很方便地集成本地缓存,先介绍基本概念。有2个核心类,Cache、CacheManager。 Cache是缓存的抽象接口,提供put、putIfAbsent(不存在时才设置kv)、get、evict(删除kv)、clear(清空所有kv)、getName(获取缓存名称)等操作。 CacheManager是一个包含了一至多个相同配置的Cache的集合,提供getCache(获取Cache对象),getCacheNames(获取包含的所有Cache对象的名称)操作。
配置
以Caffeine为例,Guava cache类似。 需注意:在@Configuration修饰的Spring配置类上,加上@EnableCaching,相当于Spring cache的总开关。
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public Caffeine cacheConfig() {
return Caffeine.newBuilder() // 默认配置,kv强引用类型(strong reference,相对于软引用、弱引用)
// 写入10秒后过期
.expireAfterWrite(10, TimeUnit.SECONDS)
// 缓存kv个数上限
.maximumSize(10000)
// 统计
.recordStats();
}
@Bean
public CacheManager cacheManager() {
// 该CacheManager包括2个缓存userCache、orderCache
CaffeineCacheManager cacheManager = new CaffeineCacheManager("userCache", "orderCache");
// 使用cacheConfig bean的配置
cacheManager.setCaffeine(cacheConfig());
return cacheManager;
}
}
注解声明
- @Cacheable:优先查缓存,如果查不到再通过执行方法逻辑查询,最后塞到缓存中。key用SpEL表达式,如果不指定默认是所有参数作为整体的key
- @CachePut:立即更新缓存,而不是等待key失效
- @CacheEvict:显式删除kv
// 使用的cache名为userCache,cacheManager是cacheManager,key为userDetail拼上user对象的id字段
@Cacheable(value="userCache", cacheManager="cacheManager", key="'userDetail' + #user.id")
public UserDetail queryUserDetail(User user) {
// 查询实际逻辑
return userDetailResult;
}

- 架构师必备:MySQL主从同步原理和应用
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
- Apache环境下PHP利用HTTP缓存协议原理解析及应用分析
- 【ASP.NET】缓存原理与应用
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
- iOS应用本地缓存
- localStorage应用(写的时间缓存在本地浏览器)
- PHP如何利用HTTP缓存协议原理解析及应用指南
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
- 设计一个移动应用的本地缓存机制(转)
- Apache环境下PHP利用HTTP缓存协议原理解析及应用分析
- 详解Memcached、Redis等缓存的特征、原理、应用
- SQLite做为本地缓存的应用需要注意的地方
- Android native应用开发简明教程 (2) - 本地应用的原理
- 计一个移动应用的本地缓存机制
- 设计一个移动应用的本地缓存机制
- 设计一个移动应用的本地缓存机制
- Oracle关于快速缓存区应用原理
- iOS应用的本地缓存机制设计