【论文考古】神经网络优化 Qualitatively Characterizing Neural Network Optimization Problems
2022-02-25 18:39
811 查看
- Goodfellow, O. Vinyals, and A. M. Saxe, “Qualitatively characterizing neural network optimization problems,” arXiv:1412.6544 [cs, stat], May 2015. [Online]. Available: http://arxiv.org/abs/1412.6544
主要工作
文章提出一种方法,用来检测训练好的神经网络,在初始参数与最终解的直线路径上,有没有遇到局部最优点等阻碍。利用$\theta_0,\theta_f$两个参数点的凸组合,通过改变$\alpha$的值来计算合成的参数$\theta= (1-\alpha)\theta_0+\alpha \theta_f$的损失函数$J(\theta)。对于两个不同随机种子下找到的解\theta_,\theta_$,图像如下:
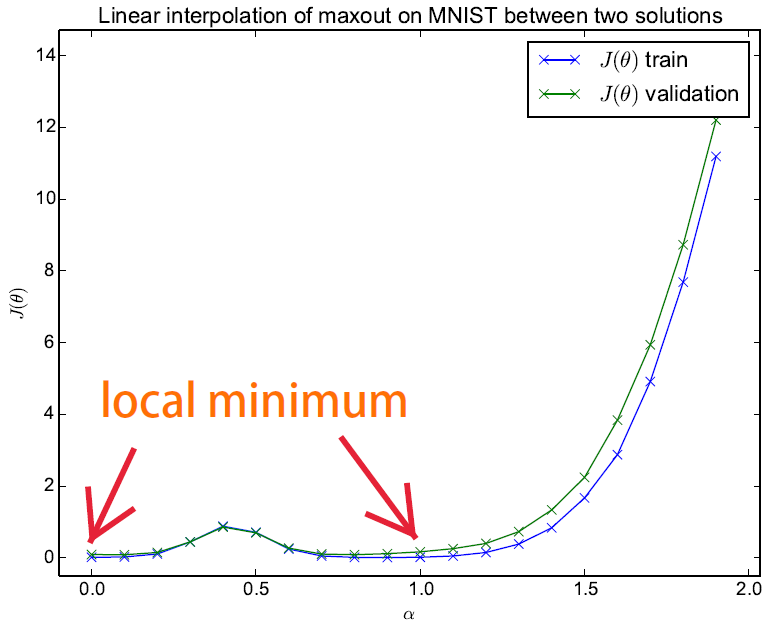
- 两个不同的局部最优点之间包含了一个高loss的障碍,但没有其他局部最优点了。这个性质被McMahan发现后,应用在了相同初始点的过拟合网络合并上,发现loss反而下降。
- 两个局部最优点更像是经过一个鞍点后的不同选择,而不是完全有不同效果的两个解
这个文章的价值在于提出了一种检测的方法,但是实际应用很窄,毕竟直线路径里包含的线性子空间太小了。但是McMahan用这个方法来验证了网络的合并,还是很有创意的。
观点
SGD在有偏的loss估计时是行不通的。也就是说每轮选取一个non iid data的用户来更新全局梯度,最后多半不收敛。
SGD of course only ever acts on unbiased stochastic approximations to this loss function.
局部最优点在训练大型神经网络时不是什么大问题。
These results are consistent with recent empirical and theoretical work arguing that local minima are not a significant problem for training large neural networks.
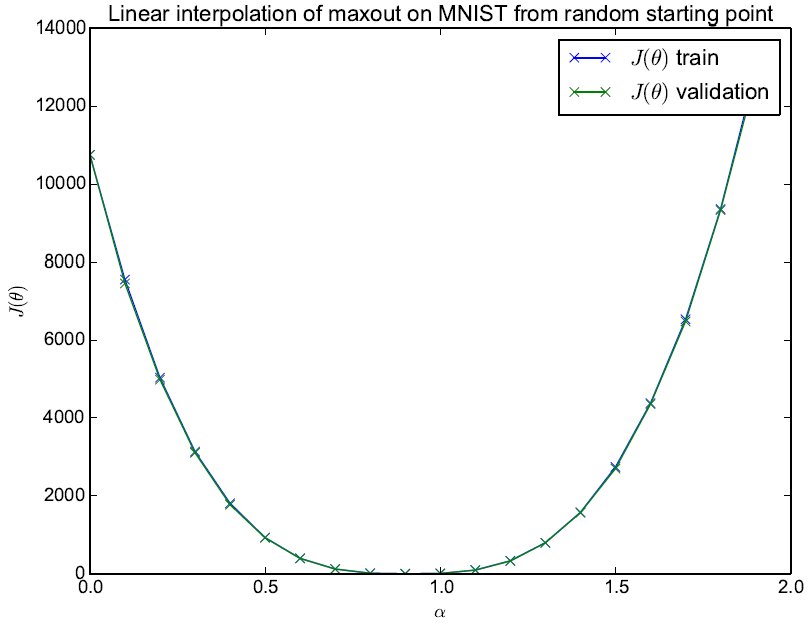
通过实验找了一个随机点和参数点的线性空间中loss的值,没有明显上升,所以局部最优点是稀疏的。(有点太随机了,说服力不够)

相关文章推荐
- 蒸馏神经网络(Distill the Knowledge in a Neural Network) 论文笔记
- 论文阅读:神经网络的有趣性质(Intriguing Properties Of Neural Network)
- 《Deep Attention Neural Tensor Network for Visual Question Answering》视觉问答的深度注意神经张量网络论文理解
- 蒸馏神经网络(Distill the Knowledge in a Neural Network) 论文笔记
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——计算图(Computation Graph)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Building your Deep Neural Network - Step by Step v5
- 一步一步分析讲解神经网络基础-Feedforward Neural Network
- Recurrent Neural Network(循环神经网络)
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——导数(Derivatives)、更多的导数例子(More Derivative
- Few-shot Learning(小样本学习) 之Siamese Neural Network(孪生神经网络)
- Neural Networks and Deep Learning(神经网络与深度学习)_On the exercises and problems
- AutoML论文笔记(三)Semi-Supervised Neural Architecture Search:基于半监督学习的神经网络架构搜索
- 详解循环神经网络(Recurrent Neural Network)
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——梯度下降法(Gradient Descent)
- AutoML论文笔记(二) FedNAS Federated Deep Learning via Neural Architecture Search:基于神经网络搜索的联邦学习
- Java Back Propagation Neural Network(JAVA反向传播神经网络)
- Introduction to neural network —— 该“神经网络” 下拉“祭坛”
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第一周课后习题 Neural Network Basics
- 概述 循环神经网络(RNN-Recurrent Neural Network)(1)
- [Lecture 10 ]Recurrent Neural Network(循环神经网络)