剑指offer之java缓存总结,从单机缓存到分布式缓存架构
1、缓存定义
高速数据存储层,提高程序性能
2、为什么要用缓存(读多写少,高并发)
1、提高读取吞吐量
2、提升应用程序性能
3、降低数据库成本
4、减少后端负载
5、消除数据库热点
6、可预测的性能
3、缓存分类
3.1、单机缓存(localCache)
实现方案
1、基于JSR107规范自研(了解即可):
1、Java Caching定义了5个核心接口,分别是CachingProvider, CacheManager, Cache, Entry 和 Expiry。
2、CachingProvider定义了创建、配置、获取、管理和控制多个CacheManager。一个应用可以在运行期访问多个CachingProvider。
3、CacheManager定义了创建、配置、获取、管理和控制多个唯一命名的Cache,这些Cache存在于CacheManager的上下文中。一个CacheManager仅被一个CachingProvider所拥有。
4、Cache是一个类似Map的数据结构并临时存储以Key为索引的值。一个Cache仅被一个CacheManager所拥有。
5、Entry是一个存储在Cache中的key-value对。
每一个存储在Cache中的条目有一个定义的有效期,即Expiry Duration。
一旦超过这个时间,条目为过期的状态。一旦过期,条目将不可访问、更新和删除。缓存有效期可以通过ExpiryPolicy设置。
2、基于ConcurrentHashMap实现数据缓存
3.2、分布式缓存(redis、Memcached)
4、单机缓存
1、自己实现一个单机缓存
创建缓存类
/**
* @author yinfeng
* @description 本地缓存实现:用map实现一个简单的缓存功能
* @since 2022/2/8 13:54
*/
public class MapCacheDemo {
/**
* 在构造函数中,创建了一个守护程序线程,每5秒扫描一次并清理过期的对象
*/
private static final int CLEAN_UP_PERIOD_IN_SEC = 5;
/**
* ConcurrentHashMap保证线程安全的要求
* SoftReference <Object> 作为映射值,因为软引用可以保证在抛出OutOfMemory之前,如果缺少内存,将删除引用的对象。
*/
private final ConcurrentHashMap<String, SoftReference<CacheObject>> cache = new ConcurrentHashMap<>();
public MapCacheDemo() {
//创建了一个守护程序线程,每5秒扫描一次并清理过期的对象
Thread cleanerThread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
try {
Thread.sleep(CLEAN_UP_PERIOD_IN_SEC * 1000);
cache.entrySet().removeIf(entry -> Optional.ofNullable(entry.getValue()).map(SoftReference::get).map(CacheObject::isExpired).orElse(false));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
cleanerThread.setDaemon(true);
cleanerThread.start();
}
public void add(String key, Object value, long periodInMillis) {
if (key == null) {
return;
}
if (value == null) {
cache.remove(key);
} else {
long expiryTime = System.currentTimeMillis() + periodInMillis;
cache.put(key, new SoftReference<>(new CacheObject(value, expiryTime)));
}
}
public void remove(String key) {
cache.remove(key);
}
public Object get(String key) {
return Optional.ofNullable(cache.get(key)).map(SoftReference::get).filter(cacheObject -> !cacheObject.isExpired()).map(CacheObject::getValue).orElse(null);
}
public void clear() {
cache.clear();
}
public long size() {
return cache.entrySet().stream().filter(entry -> Optional.ofNullable(entry.getValue()).map(SoftReference::get).map(cacheObject -> !cacheObject.isExpired()).orElse(false)).count();
}
/**
* 缓存对象value
*/
private static class CacheObject {
private Object value;
private final long expiryTime;
private CacheObject(Object value, long expiryTime) {
this.value = value;
this.expiryTime = expiryTime;
}
boolean isExpired() {
return System.currentTimeMillis() > expiryTime;
}
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
}
写个main方法测试一下
public static void main(String[] args) throws InterruptedException {
MapCacheDemo mapCacheDemo = new MapCacheDemo();
mapCacheDemo.add("uid_10001", "{1}", 5 * 1000);
mapCacheDemo.add("uid_10002", "{2}", 5 * 1000);
System.out.println("从缓存中取出值:" + mapCacheDemo.get("uid_10001"));
Thread.sleep(5000L);
System.out.println("5秒钟过后");
// 5秒后数据自动清除了
System.out.println("从缓存中取出值:" + mapCacheDemo.get("uid_10001"));
}
2、谷歌guava cache缓存框架
2.1、简介
Guava Cache是一个内存缓存模块,用于将数据缓存到jvm内存中,是单个应用运行时的本地缓存,他不将数据放到文件或外部服务器。
2.2 简单使用
/**
* @author yinfeng
* @description guava测试,https://github.com/google/guava
* @since 2022/2/8 14:13
*/
public class GuavaCacheDemo {
public static void main(String[] args) throws ExecutionException {
//缓存接口这里是LoadingCache,LoadingCache在缓存项不存在时可以自动加载缓存
LoadingCache<String, User> userCache
//CacheBuilder的构造函数是私有的,只能通过其静态方法newBuilder()来获得CacheBuilder的实例
= CacheBuilder.newBuilder()
//设置并发级别为8,并发级别是指可以同时写缓存的线程数
.concurrencyLevel(8)
//设置写缓存后8秒钟过期
.expireAfterWrite(8, TimeUnit.SECONDS)
//设置写缓存后1秒钟刷新
.refreshAfterWrite(1, TimeUnit.SECONDS)
//设置缓存容器的初始容量为10
.initialCapacity(10)
//设置缓存最大容量为100,超过100之后就会按照LRU最近虽少使用算法来移除缓存项
.maximumSize(100)
//设置要统计缓存的命中率
.recordStats()
//设置缓存的移除通知
.removalListener(notification -> System.out.println(notification.getKey() + " 被移除了,原因: " + notification.getCause()))
//build方法中可以指定CacheLoader,在缓存不存在时通过CacheLoader的实现自动加载缓存
.build(
new CacheLoader<String, User>() {
@Override
public User load(String key) {
System.out.println("缓存没有时,从数据库加载" + key);
// TODO jdbc的代码~~忽略掉
return new User("yinfeng" + key, key);
}
}
);
// 第一次读取
for (int i = 0; i < 20; i++) {
User user = userCache.get("uid" + i);
System.out.println(user);
}
// 第二次读取
for (int i = 0; i < 20; i++) {
User user = userCache.get("uid" + i);
System.out.println(user);
}
System.out.println("cache stats:");
//最后打印缓存的命中率等 情况
System.out.println(userCache.stats().toString());
}
@Data
@AllArgsConstructor
public static class User implements Serializable {
private String userName;
private String userId;
@Override
public String toString() {
return userId + " --- " + userName;
}
}
}
5、分布式缓存
5.1 redis
5.1.1 介绍
Redis是一个开源的使用C语言缩写、支持网络、可基于内存亦可持久化的日志型,Key-Value数据库,并提供多种语言的API。
本质是客户端-服务端应用软件程序。
特点是使用简单,性能强悍,功能应用场景丰富。
5.1.2通用命令
| 命令 | 作用 |
|---|---|
| DEL key | 用于在key存在是删除key |
| DUMP key | 序列化给定的key,并返回给定的值 |
| EXISTS key | 检查给定key是否存在 |
| EXPIRE key seconds | 为给定key设置过期时间,单位秒 |
| TTL key | 以秒为单位,返回给定key的剩余生存时间 |
| TYPE key | 返回key所存储的值的类型 |
5.1.3 数据结构
1. String
定义
String数据结构是简单的key-value类型,value其实不仅是String,也可以是数字。
使用场景:微博数,粉丝数(常规计数)
常用命令
| 命令 | 作用 |
|---|---|
| Get | 获取指定key的值 |
| Set | 设置指定key的值 |
| Incr | 将key中储存的数字值增一 |
| Decr | 将key中储存的数字值减一 |
| Mget | 获取所有(一个或多个)给定key的值 |
2. List
定义
List就是链表,依赖于链表结构
使用场景:微博的关注列表,粉丝列表
常用命令
| 命令 | 作用 |
|---|---|
| Lpush | 将一个或多个值插入到列表头部 |
| Rpush | 在列表中添加一个或多个值 |
| Lpop | 移出并获取列表的第一个元素 |
| Rpop | 移除列表的最后一个元素,返回值为移除的元素 |
| Lrange | 获取所有(一个或多个)给定key的值 |
3. Set
定义
Set就是一个集合,集合的概念就是一堆不重复值的组合。利用Reds提供的Set数据结构,可以存储一些集合性的数据。
使用场景:实现如共同关注,共同喜好,二度好友
常用命令
| 命令 | 作用 |
|---|---|
| Sadd | 向集合中添加一个或多个成员 |
| Spop | 移除并返回集合中的一个随机元素 |
| Smembers | 返回集合中的所有成员 |
| Sunion | 返回所有给定集合的并集 |
4. Sorted set
定义
Sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。
使用场景:排行榜、按照用户投票和时间排序
常用命令
| 命令 | 作用 |
|---|---|
| Zadd | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| Zrange | 通过索引区间返回有序集合中指定区间内的成员 |
| Zrem | 移除有序集合中的一个或多个成员 |
| Zcard | 获取有序集合的成员数 |
5. Hash
定义
Hash是一个sting类型的field和value的映射表
使用场景:存储部分变更数据,如用户信息
常用命令
| 命令 | 作用 |
|---|---|
| Zadd | 获取存储在哈希表中指定字段的值 |
| Zrange | 将哈希表key中的字段field的值设为value |
| Hgetall | 获取在哈希表中指定key的所有字段和值 |
6. GEO
定义
GEO3.2版本开始对GEO(地理位置)的支持
使用场景:LBS应用开发
常用命令
| 命令 | 作用 |
|---|---|
| GEOADD | 增加地理位置的坐标,可以批量添加地理位置 |
| GEODIST | 获取两个地理位置的距离 |
| GEOHASH | 获取某个地理位置的geohash值 |
| GEOPOS | 获取指定位置的坐标,可以批量获取多个地理位置的坐标 |
| GEORADIUS | 根据给定地理位置坐标获取指定范围内的地理位置集合(注意:该命令的中心点由输入的经度和结度决定) |
| GEORADIUSBYMEMBER | 根据给定成员的位置获取指定范围内的位置信息集合(注意:该命令的中心点足由给定的位置元素决定) |
7. Stream
定义
Stream5.0版本开始的新结构“流”
使用场景:消费者生产者场景(类似MO)
常用命令
| 命令 | 作用 |
|---|---|
| XADD | 增加地理位置的坐标,可以批量添加地理位置 |
| XLEN | stream流中的消息数量 |
| XDEL | 删除流中的消息 |
| XRANGE | 返回流中满足给定ID范围的消息 |
| XREAD | 从一个或者多个流中读取消息 |
| XINFO | 检索关于流和关联的消费者组的不同的信息 |
5.1.4 持久化机制
1. 介绍
redis的数据都存放在内存中,如果没有配置持久化,重启后数据就全丢失,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据
2. 持久化方式
- RDB持久化:RDB持久化方式能够在指定的时间间隔对你的数据进行快照存储
- AOF持久化: AOF持久化方式记录每次对服务器写的操作,当服务器重后的时候会重新执行这些命令来恢复原始的数据
3.RDB方式
客户端直接通过命令BGSAVE或者SAVE来创建一个内存快照:
- BGSAVE调用fork来创建一个子进程,子进程负责将快照写入磁盘,而父进程仍然继续处理命令。
- SAVE执行SAVE命令过程中,不再响应其他命令。
在redis.conf中调整save配置选项,当在规定的时间内,redis发生了写操作的个数满足条件会触发BGSAVE命令
#900秒之内至少一次写操作 save 900 1 #300秒之内至少发生10次写操作 save 300 10
优缺点
| 优点 | 缺点 |
|---|---|
| 对性能影响最小 | 同步时丢失数据 |
| RDB文件进行数据恢复比使用AOF要快很多 | 如果数据集非常大且CPU不够强(比如单核CPU),Redis在fork子进程时可能会消耗相对较长的时间,影响RediS对外提供服务的能力 |
4. AOF持久化方式
开启AOF持久化
appendonty yes
AOF策略调整
#每次有数据修改发生时都会写入AOF文件 appendfsync always #每秒钟同步一次,该策略为AOF的默认策略 appendfsync everysec #从不同步。高效但是数据不会被持久化 appendfsync no
优点
| 优点 | 缺点 |
|---|---|
| 最安全 | 文件体积大 |
| 容灾 | 性能消耗比RDB高 |
| 易读,可修改 | 数据恢复速度比RDB慢 |
5.1.5 内存管理
1、内存分配
不同数据类型的大小限制:
Strings类型:一个Strings类型的Value最大可以存储512M。
Lists类型:list的元素个数最多为2^32-1个
Sets类型:元素个数最多为2^32-1个
Hashes类型:键值对个数最多为2^32-1个
最大内存控制:
maxmemory 最大内存阈值
maxmemory-policy 到达阈值的执行策略
2、内存压缩
#配置字段最多512个 hash-max-zipmap-entries 512 #配置value最大为64字节 hash-max-zipmap-value 64 #配置元素个数最多512个 lst-max-zipmap-entries 512 #配置value最大为64字节 list-max-zipmap-value 64 #配置元素个数最多512个 set-max-zipmap-entries 512
大小超出压缩范围,溢出后redis将自动将其转换为正常大小
3、过期数据的处理策略
主动处理(redis主动触发检测key足否过期)每秒抗行10次。过程如下:
- 从具有相关过期的key集合中测试20个随机key
- 删除找到的所有已过期key
- 如果超过25%的key已过期,请从步骤1重新开始
被动处理:
- 每次访问key的时候,发现超时后被动过期,清理掉
数据恢复阶段过期数据的处理策略:
RDB方式:过期的Key不会被持久化到文件中。载入时过期的key,会通过redis的主动和被动方式清理掉。
AOF方式:每次遇到过期的key,redis会追加一条DEL命令到AOF文件,也就是说只要我们顺序载入执行AOF命令文件就会删除过期的key
注意:过期数据的计算和计算机本身的时间是有直接联系的!
Redis内存回收策略:
配置文件中设置:maxmemory-poIicy noeviction
命令动态调整:config set maxmemory-policy noeviction
| 回收策略 | 说明 |
|---|---|
| noeviction | 客户端尝试执行会让更多内存被使用的命令直接报错 |
| allkeys-lru | 在所有key里执行LRU算法清除 |
| volatile-lru | 在所有已经过期的key里执行LRU算法清除 |
| allkeys-lfu | 在所有key里执行LFU算法清除 |
| volatile-lfu | 在所有已经过期的key里执行LFU算法清除 |
| allkeys-random | 在所有key里随机回收 |
| volatile-random | 在已经过期的key里随机回收 |
| volatile-ttl | 回收已经过期的key,并且优先回收存活时间(TTL)较短的key |
4、LRU算法
LRU(最近最少使用):根据数据的历史访问记录来进行沟汰数据
核心思想:如果数据最近被访问过,那么将来被访问的几率也更高。
注意:Redis的LRU算法并非完整的实现,完整的LRU实现需要太多的内存。
方法:通过对少量keys进行取样(50%),然后回收其中一个最好的key。
配置方式:maxmemory-samples 5
5、LFU算法
LFU:根据数据的历史访问频率来沟汰数据
核心思想:如果数据过去被访问多次,那么将来被访问的频率也更高。
启用LFU算法后,可以使用热点数据分析功能。
5.1.6 主从复制
1、介绍
为什么要主从复制
redis-server单点故障
单节点QPS有限
应用场景分析
读写分离场景,规避redis单机瓶颈
故障切换,master出问题后还有slave节点可以使用
2、搭建主从复制
主Redis Server以普通模式启动,主要是启动从服务器的方式
-
命令行
#连接需要实现从节点的rediS,执行下面的命令 slaveof [ip] [port]
-
redis.conf配置文件
#配置文件中增加 slaveof [ip] [port] #从服务器是否只读(默认yes) slave-read-only yes
-
退出主从集群的方式
slaveof no one
3、检查主从复制
#redis客户端执行 info replication
4、主从复制流程
- 从服务器通过psync命令发送服务器已有的同步进度(同步源ID,同步进度offset)
- master收到请求,同步源为当前master,则根据偏移量增量同步
- 同步源非当前master,则进入全量同步:maser生成rdb,传输到slave,加载到slave内存
5、主从复制核心知识
- Redis默认使用异步复制,slave和master之间异步地确认处理的数据量
- 一个master可以拥有多个slave
- Slave可以接受其他slave的连接。slave可以有下级sub slave
- 主从同步过程在master侧是非阻塞的
- slave初次同步需要删除旧数据,加载新数据,会阻塞到来的连接请求
6、应用场景
- 主从复制可以用来支持读写分离
- slave服务器设定为只读,可以用在数据安全的场景下。
- 可以使用主从复制来避免master持久化造成的开销。master关闭持久化,slave设置为不定期保存或开启AOF
- 注意:重新启动的master程序将从一个空数据集开始,如果一个slave试图与它同步,那么这个slave也会被清空。
7、注意事项
-
读写分离场景:
数据复制延时导致读到过期数据或者读不到数据(网络原因,slave阻塞)
从节点故障(多个client如何迁移)
-
全量复制情况下:
第一次建立主从关系或者runid不匹配会导致全量复制
故障转移的时候也会出现全量复制
-
复制风暴:
master故障重启,如果slave节点过多,所有slave都要复制,对服务器的性能,网络的压力都有很大影响。
如果一个机器部署了多个master
-
写能力有限
主从复制还是只有一台master,提供的写服务能力有限
-
master故障情况下:
如果是mater无持久化,Slave开启持久化来保留数据的场展,建议不要配置redis自动重启。
启动redis自动重启,master启动后,无备份数据,可能导致集群数据丢失的情况
-
带有效期的key:
Slave不会让key过期,而是等待master让key过期
在Lua脚本执行期间,不执行任何key过期操作
5.1.7 哨兵模式
1、哨兵(Sentinel)机制核心作用
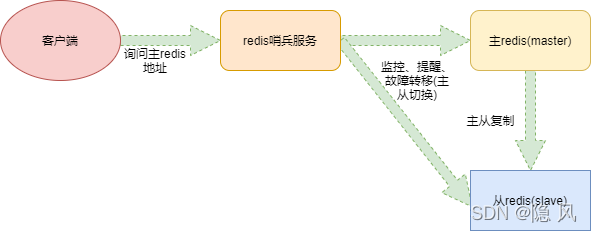
2、核心运作流程
服务发现和健康检查流程
搭建redis主从集群 ==> 启动哨兵(客户端通过哨兵发现Redis实例信息) ==> 哨兵通过连接master发现主从集群内的所有实例信息 ==> 哨兵监控redis实例的健康状况
故障切换流程
哨兵一旦发现master不能正常提供服务,则通知给其他哨兵 ==> 当一定数量的哨兵都认为master挂了 ==> 选举一个哨兵作为故障转移的执行者 ==> 执行者在slave中选取一个作为新的master ==> 将其他slave重新设定为新master的从属
3、哨兵如何知道Redis主从信息
哨兵配置文件中,保存着主从集群中master的信息,可以通过info replication命令,进行主从信息自动发现。
4、什么是主观下线(sdown)
主观下线:单个哨兵自身认为redis实例已经不能提供服务
检测机制:哨兵向redis发送ping请求,+PONG,-LOADING,-MASTERDOWN三种情况视为正常,其他回复均视为无效
对应配置文件的配置项:sentinel down-after-milliseconds mymaster 1000
5、什么是客观下线(odown)
客观下线:一定数量值的哨兵认为master已经下线。
检测机制:当哨兵主观认为maser下线后,则会通过SENTINEL is-master-down-by-addr命令询问其他哨兵是否认为master已经下线,如果达成共识(达到quorum个数),就会认为master节点客观下线,开始故障转移流程
对应配置文件的配置项:sentinel monitor mymaster 1.0.0.1 6380 2
6、哨兵之间如何通信
- 哨兵之间的自动发现:发布自己的信息,订阅其他哨兵消息(pub/sub)
- 哨兵之间通过命令进行通信:直连发送命令
- 哨兵之间通过订阅发布进行通信:相互订阅指定主题(pub/sub)
7、哨兵领导选举机制
基于Raft算法实现的选举机制,流程简述如下:
- 拉票阶段:每个哨兵节点希望自己成为领导者;
- Sentinel节点收到拉票命令后,如果没有收到或同意过其他sentinel节点的请求,就同意该sentinel节点的请求(每个sentinel只持有一个同意票数)
- 如果sentinel节点发现自己的票数已经超过一半的数值,那么它将成为领导者,去执行故障转移
- 投票结束后,如果超过failover-timeout的时间内,没进行实际的故障转移操作,则重新拉票选举。
8、slave选举方案
slave节点状态 > 优先级 > 数据同步情况 > 最小的run id
9、最终主从切换的过程
针对即将成为master的slave节点,将其撒出主从集群,自动执行:slaveof NO ONE
针对其他slave节点,使它们成为新master的从属,自动执行:slaveof new_master_host new_master_port
10、哨兵服务部署方案
不推荐:一主一从,两个哨兵
推荐:一主两从,三个哨兵
redis集群非强一致:一主两从,网络分区下可能出现数据不一致或丢失。
5.1.8 redis集群分片存储
1、为什么要分片存储
redis的内存需求可能超过机器的最大内存。(一台机器不够用)
2、官方集群方案
redis cluster是redis的分布式集科解决方案,在3.0版本推出后有效地解决了redis分布式分面的需求,实现了数据在多个Redis节点之间自动分片,故障自动转移,扩容机制等功能。
主要基于CRC16(key) % 16384 计算出每个key对应的slot,然后根据redis集群中实例的预设槽slot(16384个)进行对应的操作,slot不存储数据,仅仅用来做片区划分。
3、搭建集群
- 准备6个独立的redis服务
- 通过redis-cli工具创建集群
- 检验集群
- 故障转移测试
- 集群扩容
- 集群节点删除
4、集群关心的问题
-
增加了slot槽的计算,是不是比单机性能差?
不是的,为了避免每次都需要服务器计算重定向,优秀的Java客户端都实现了本地计算,并且缓存服务器slots分配,有变动时再更新本地内容,从而避免了多次重定向带来的性能损耗。
-
redis集群大小,到底可以装多少数据?
理论是可以做到16384个槽,每个槽对应一个实例,但是redis宫方建议是最大1000个实例,因为存储已经足够大了。
-
集群节点间是怎么通信的?
每个Redis群集节点都有一个额外的TCP端口,每个节点使用TCP连接与每个其他节点连接。检测和故障转移这些步骤基本和哨兵模式类似。
-
ask和moved重定向的区别
重定向包括两种情况
若确定slot不属于当前节点,redis会返回moved。
若当前redis节点正在处理slot迁移,则代表此处请求对应的key暂时不在此节点,返回ask,告诉客户端本次请求重定向。
-
数据倾斜和访问倾斜的问题
倾斜导致集群中部分节点数据多,压力大。解决方案分为前期和后期:
前期是业务层面提前预测,哪些key是热点,在设计的过程中规避。
后期是slot迁移,尽量将压力分摊(slot调整有自动rebalance、reshard和手动)。
-
slot手动迁移怎么做?
在迁移目的节点执行cluster setslot IMPORTING 命令,指明需要迁移的slot和迁移源节点。
- 在迁移源节点执行cluster setslot MIGRATING 命令,指明需要迁移的slot和迁移目的节点。
- 在迁移源节点执行cluster getkeysinslot获取该slot的key列表
- 在迁移源节点执行对每个key执行migrate命令,该命令会同步把该key迁移到目的节点。
- 在迁移源节点反复执行cluster getkeysinslo命令,直到该slot的列表为空。
- 在迁移源节点和目的节点执行cluster setslot NODE ,完成迁移操作。
节点之间会交换信息,传递的消息包括槽的信息,带来带宽消耗。注意:避免使用大的一个集群,可以分多个集群。
Pub/Sub发布订阅机制:对集群内任意的一个节点执行pubish发布消息,这个消息会在集群中进行传播,其他节点都接收到发布的消息。
读写分离:
redis-cluster默认所有从节点上的读写,都会重定向到key对应槽的主节点上。
可以通过readonly设置当前连接可读,通过readwrite取消当前连接的可读状态。
注意:主从节点依然存在数据不一致的问题
5.1.9 redis监控
1、monitor命令
monitor是一个调试命令,返回服务器处理的每个命令。对于发现程序的错误非常有用。出于安全考虑,某些特殊管理命令CONFIG不会记录到MONITOR输出。
注意:运行一个MONITOR命令能够降低50%的吞吐量,运行多个MONITOR命令降低的吞吐量更多。
2、info命令
INFO命令以一种易于理解和阅读的格式,返回关于Redis服务器的各种信息和统计数值。
| info命令 | 返回信息 |
|---|---|
| server | Redis服务器的一般信息 |
| clients | 客户端的连接部分 |
| memory | 内存消耗相关信息 |
| persistence | 持久化相关信息 |
| stats | 一般统计 |
| replication | 主/从复制信息 |
| cpu | 统计CPU的消耗 |
| commandstats | Redis命令统计 |
| cluster | Redis集群信息 |
| keyspace | 数据库的相关统计 |
可以通过section返回部分信息,如果没有使用任何参数时,默认为detault。
3、图形化监控工具: Redis-Live
5.2 memcached入门
由于memcached慢慢淡出了人们的视野,使用的公司越来越少,所以这里只是做个入门介绍。
1、简介
是一个免费开源的、高性能的、具有分布式内存对象的缓存系统,它通过减轻数据库负载加速动态web应用。
本质上就是一个内存key-Value缓存
协议简单,使用的是基于文本行的协议
不支持数据的持久化,服务器关闭之后数据全部丢失
Memcached简洁而强大,便于快速开发,上手较为容易
没有安全机制
2、设计理念
-
简单的键/值存储:服务器不关心你的数据是什么样的,只管数据存储
-
服务端功能简单,很多逻辑依赖客户端实现
客户端专注如何选择读取或写入的服务器,以及无法联系服务器时要执行的操作。
服务器专注如何存储和管理何时清除或重用内存
-
Memcached实例之间没有通信机制
-
每个命令的复杂度为0(1):慢速机器上的查询应该在1ms以下运行。高端服务器的吞吐量可以达到每秒数百万
-
缓存自动清除机制
-
缓存失效机制
3、常用命令
| 分组 | 命令 | 描述 |
|---|---|---|
| 存储命令 | set | 用于将value存储在指定的key中。key已经存在,更新该key所对应的原来的数据。 |
| add | 用于将value存储在指定的key中,存在则不更新。 | |
| replace | 替换已存在的key的Value,不存在,则替换失败。 | |
| append | 用于向已存在key的value后面追加数据 | |
| prepend | 向已存在key的value前面追加数据 | |
| cas | 比较和替换,比对后,没有被其他客户端修改的情况下才能写入。 | |
| 检索命令 | get | 获取存储在key中的value,不存在,则返回空。 |
| gets | 获取带有CAS令牌存的value,若key不存在,则返回为空 | |
| 删除 | delete | 删除已存在的key |
| 计算 | incr/decr | 对已存在的key的数字值进行自增或自减操作 |
| 统计 | stats | 返回统计信息如PID(进程号)、版本号、连接数等 |
| stats items | 显示各个slab中item的数目和存储时长(最后一次访问距离现在的秒数) | |
| stats slabs | 显示各个slab的信息,包括chunk的大小、数目、使用情况等。 | |
| stats sizes | 显示所有item的大小和个数 | |
| 清除 | flush_all | 清除所有内容 |
4、客户端使用
客户端支持的特性:集群下多服务器选择,节点权重配置,失败/故障转移,数据压缩,连接管理
5、服务端配置
-
命令行参数
查看memcached-h或man memcached获取最新文档
-
init脚本
如果通过yum应用商店安装,可以使用/etc/sysconfig/memcached文件进行参数配置
-
检查运行配置
stats settings查看运行中的memcached的配置
6、memcached性能
Memcached性能的关键是硬件,内部实现是hash表,读写操作都是0(1)。硬件好,几百万的OPS都是没问题的。
最大连接数限制:内部基于事件机制(类似JAVA NIO)所以这个限制和nio类似,只要内存,操作系统参数进行调整,轻松几十万。
集群节点数量限制:理论是没限制的,但是节点越多,客户端需要建立的连接就会越多。
注意:memcached服务端没有分布式的功能,所以不论是集群还是主从备份,都需要第三方产品支持。
7、服务器硬件需要
CPU要求:CPU占用率低,默认为4个工作线程
内存要求:
memcached内容存在内存里面,所有内存使用率高。
建议memcached实例独占服务器,而不是混用。
建议每个memcached实例内存大小都足一致的,如果不一致则需要进行权重调整
网络要求:
根据项目传输的内容来定,网络越大越好,虽然通常10M就够用了
建议:项目往memcached传输的内容保持尽可能的小
8、Memcached应用场景
- 数据查询缓存:将数据库中的数据加载到memcached,提供程序的访问速度
- 计数器的场景:通过incr/decr命令实现评论数量、点击数统计,操作次数等等场景。
- 乐观锁实现:例如计划任务多实例部暑的场景下,通过CAS实现不重复执行
- 防止重复处理:CAS命令
5.3 互联网高并发缓存架构
5.3.1 缓存架构分析图
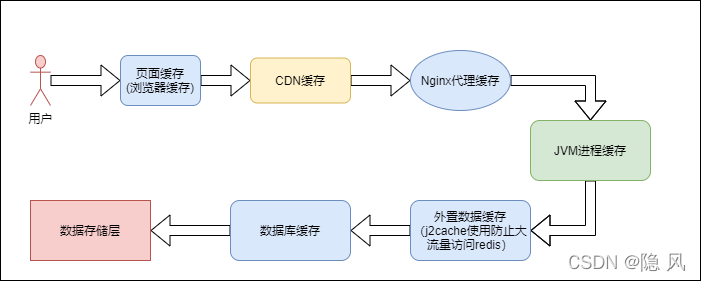
5.3.2 缓存雪崩
定义:因为缓存服务挂掉或者热点缓存失效,从而导致所有请求都去查数据库,导致数据库连接不够用或者数据库处理不过来,从而导致整个系统不可用。
常用解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 缓存降级,直接返回错误码;
- 加锁实现防止大量请求堆到数据库。
- 设置热点数据永远不过期,防止了自动失效的情况,通过其他后台检查程序,防止缓存数据和数据库长期不同步
5.3.2 缓存击穿
定义:查询必然不存在的数据,请求透过Redis,直击数据库。
常用解决方案:
- 用户内容预生成。
- 访问频率限制。
- 缓存中无数据,也不查询数据库,直接返回错误码。
- 布隆过滤器

- 牛客网做题总结:剑指offer中题目,java版一
- 剑指Offer题目总结(java版)
- 牛客网做题总结:剑指offer中题目,java版三
- 牛客网做题总结:剑指offer中题目,java版二
- 基于java技术的软件开发架构总结
- 剑指offer--面试题10:二进制中1的个数--Java实现
- 基于java技术的软件开发架构总结
- 【剑指offer】面试题3:二位数组中的查找 java
- 剑指offer--面试题7:用两个栈实现队列--Java实现
- 剑指offer--面试题23:从上往下打印二叉树--Java实现
- 基于java技术的软件开发架构总结
- java架构搭建(八)--EhCache缓存在web下的使用实例
- 对JAVA中MVC设计模式、JAVAWEB的三层架构、AOP面向切面编程的总结
- 剑指offer--面试题4:替换空格--Java实现
- 剑指offer 替换空格 java实现
- 剑指Offer——反转单词顺序(Java)
- [转]剑指offer面试题总结
- 剑指Offer面试题9(java版)斐波那契数列
- 基于java技术的软件开发架构总结
- Ehcache二级缓存,查询缓存,分布式缓存总结 推荐