Traffic Control“分类器-执行器”子系统架构 译注
本文为本人翻译的“Traffic Control Classfier-Action Subsytem Archtecture”的中文译注版。原文地址为:
关于流量控制的CA子系统的设计原则,该文做了详细描述。可供参考。
摘要:
该文描述了Linux 流量(TC)的分类器-动作器(Classfier-Action)子系统的架构。该子系统在内核中已经超过10年(在此之前,实验补丁时间更长),最终我们企图做任何开源项目中枯燥和不愉快的部分——文档。我们将会描述“包处理图”架构和由分类器-动作执行子系统提供的底层延展性;我们将深入地讨论形式化语言,该语言使该子系统成为很棒的包处理架构。
关键词:
Linux, tc, filters, actions, qdisc, packet processing, Software Defined Networking, iproute2, kernel
介绍
Linux内核提供了一个功能丰富的包处理框架。
图1图示了一个简单的包处理路径的示意图。数据包进入ingress端口并且通过一系列被上图描述为云状的处理组件。从云状图末尾发出去的包最终到达egress端口处,继续它们的旅途。
可以看到,端口是包处理路径(或者图)的锚点/切入点。
端口(Ports)
在Linux世界中,端口被认为是网络设备或者netdev的简称。我们将交替使用这两种术语(inter-changeably)。
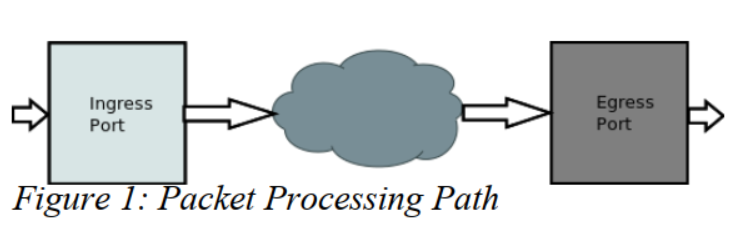
如图1显示,在东西方向上,端口传统上有一个单向的数据通路(Datapath)的包输入和单向的数据通路的包输出。数据通路的切入点也分为出口和入口。一个只有多个切入点中之一个的端口是可能存在的1。
端口2有南北向接口用于控制和事件(基本通过netlink[3] [4]的API)。控制和配置单元如iproute2或者ifconfig利用这些南北向接口。
在东西方向上一个netdev操作一些数据路径的活动。
netdev抽象(netdev abstraction)的简单性导致了它的广泛应用。大多数端口抽象是以太网衍生的3 (意思是它们都拥有L2层地址,即以太网MAC地址)。这使得推广大量工具变得容易。例如,一个工具能够在任何netdev上执行ip命令行,而不管工具操作的是什么netdev。一个工具能够将L3 地址绑定到端口上,并在端口上指定路由,从它的出口(egress)引到邻近设备(例如 ARP/ND工具)。总体上意味着Netdevs可以组成传统的包处理图,通过L3 层处理(即 绑定IPv4/v6地址或甚至设备的DECENT地址),L2层或者其他的更多的外来的设置例如栈式网络设备4 (tunneling,bonding等)
netdev在处理接收到的包的事情广泛多样。可被用于处理硬件或者虚拟的抽象。 一些Netdev实施的例子如下:
lo,即本地回环。抓到数据包并且发送它回本地。处理本地回环不需要通过host。
物理端口。各种物理上的网络控制设备:有线以太网芯片,USB,无线,控制器局域网络(CAN总线),等等,它们一般都被称作ethx。
Tun/tap5。处理内核和用户空间之间的数据包分流。用户程序将包写入文件描述符中,该描述符展示了tuntap的出口上。而且一旦读到文件描述符,用户空间的应用就会收到显示在tuntap的egress上的数据包。Tuntap是受欢迎的虚拟网卡,用于虚拟机以及用户空间下的包处理。
各式各样的隧道。凡是你能说出口的(隧道),Linux就有它: VLAN, GRE,VXLAN, IPIP, L2TP, 基于v4的ipv6,等等。
MACVlan。它一开始被作为一种方法来表示多MAC物理以太网端口上的单个MAC,但是现在功能越来越丰富了。它能作为网桥或者直接硬件卸载到容器或者主机上。
和MACVlan在容器上做的一样,MacVTAP将硬件卸载到VM上。
veth。表现为一对管道的netdev。被注入到一半管道的egress上的包,出现在另一半管道的ingress上。 6 一般地,管道的一半位于host,另一半在container中(虽然也有各自一半都在容器中的例子)。
Bonding/Team7。设备的聚合,比如LACP等,有不少于瑞士军刀的特性。
基于无限带宽技术的IP[^Infiniband].
网桥。特性丰富的IEEE网桥抽象。
IFB。用于聚合处理图(graphs)的中间设备,一般用于流的服务质量管理(for flow QoS)。
Dummy(虚节点)。拿到数据包,说明原因(accounts for it)然后丢掉它们。
更多的其他的设备。查看代码自己去看(或者写一个)。
Linux数据通路
图2扩展了笼统的Linux数据通路以及展示了图1中云的更多细节。

图中展示了一些构建的方块(就是框图)。在该文档中,所有被描述的构建块和它们的组件都被写为内核模块。所有数据通路块的控制由用户空间完成(传统意义上,Unix的规则与机制分离的策略;数据通路属于机制实现8)。
在该文中,我们要聚焦在Ingress和egress流量控制部分,但是我们感觉,为了提供上下文(的连贯性),有必要去谈论其他的构建块。
Netfilter
Netfilter[1]是特性丰富,模块化的可扩展包处理框架。它提供了一系列钩子(hooks)[^hook]"钩在"Linux内核包处理点上,该点允许内核模块注册回调函数(callback function)。被注册的回调函数被内核所调用,来处理在内核栈中穿过各自的hook的数据包 9。图2中的hook在数据通路中被标记出了它们的位置。
预先路由(Pre-routing)
转发
出口路由
输入(到本地网络栈)
输出(从本地网络栈)
Netfilter有许多重要特性,在这个简短的描述中,无法做到公正全面,但是我们想强调它拥有的一些功能10:
- 包过滤
- 各种你能想到的网络地址和端口传输
- 多层次用户可见控制和用于写应用和数据通路组件的数据通路API
- 状态醒的连接追踪能力,熟知为 conntrack1
注意:图2展示了栈从ingress到egress的旁路。该旁路可被CA子系统通过镜像(到许多的端口)或者重定向(到某一个端口)得到11。
Linux Traffic Control Overview
图2展示了3个标有"Traffic Control"的块12。从一些概念定义开始,使用figure3展示egress路径并且结合图2中的Egress Traffic Control和Traffic Control调度。
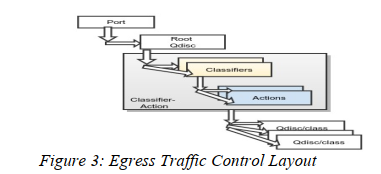
- 队列规则(qdisc)是调度器,分为有分类(classful)和无分类(classless)。有分类的qdisc有多个类(classes),这些类由分类器过滤器选择(selected by classifier filters)。有分类的qdisc可以包含其他的qdisc, 通过policy的定义,等级可以被设置到允许不同的包组处理。每个qdisc通过一个32位classid标识。
- 类是队列或者qdisc[^classes]。如图所示,qdisc进一步允许更多等级。父等级的qdisc可以调度它的子qdisc/queues 通过使用一些预定义的调度算法——下文会提供示例。每个class通过一个32位的classid标识。
- 分类器用于选择数据包。它们要么监视包数据要么监视元数据(meta data),同时选择一种执行动作(Action)去执行。分类器可以被绑定在qdiscs或者classes上。每个分类器类型,操作它自己的算法,并且这算法是专门的。分类器包含了过滤器,过滤器操作与分类器算法适用的语义。对于每个被定义的规则,都有一个内置筛选器13,filter会基于2层协议类型首先匹配。
- 执行动作(Action) 会在分类器过滤匹配成功时执行14。 最原始的执行动作是内建的classid/flowid 选择动作;它的角色是对策略图中的数据包归属的类或流以及多路复用的位置进行排序15。
一个端口有两个默认的qdisc绑定点。root qdisc被绑定在egress路径上,如图3所示。而图4中ingress qdisc被绑定在ingress路径上。
ingress qdisc是一个虚队列规则,其角色是提供对CA子系统的锚点。被ingress qdisc收到的数据包一定会经过基于规则图定义(defined by CA subsystem)的CA子系统。
正如前文提到的,每个qdisc/class被一个32为的id定义,作为classid或者flowid。classid被分成一个16位的高位id和16位的低位id。所以可以看到x:y被用于在这些地方——x是高位数字,常用来指示层级,而y是低位数,用来指示层次结构中的实体。高位数字0xffff留作ingress qdisc。
描述qdisc超出了本文的范围,但是我们将提到一些来提供上下文以及展示不同种类。
Prio。基于TOS或者skb->priority域的内部选择的网络流。基于严格优先排序(意思是低优先级的包可能被丢弃(starved))的节省工作的调度算法16
Pfifo。具有单向FIFO队列的无分类qdisc。包基于先到先出云泽被调度。
Red。基于RED[7]调度算法的无分类队列。
tbf。无分类qdisc, 非节省工作的调度算法,基于令牌桶算法,用于流量整型(for shaping)。
Sfq。宽松地基于[5]的随机公平排队算法。
codel。基于延迟控制算法(controlled delay algorithm)[6].
fq-codel。加入sfq的扩展的codel。
Netem。通过允许对协议属性和语义进行修改,为测试协议提供了多种网络仿真功能[14]。
其他的。插件定义很好,今天写一篇。
尽管图3显示不存在锚定在低等级qdisc上的CA,但应注意的是,可以创建锚定在任何qdisc与class上的策略。 我们将抛开细节因为我们感觉该讨论已超出文档的范围。
Linux Traffic Control的一些历史
如果没有对过去的一点回忆,该文便是不完整的。
Alexey Kuznetsov 首创了(pioneered)Linux Traffic Control 架构。Alexey 提交了初始代码补丁,首先展示在内核2.1中。
Werner Almesberger 在形成期间做了许多工作[8] [9] [10], 包括编写了所有ATM相关的工作。
本文作者贡献了CA子系统的行为扩展,并且是当前CA子系统的维护者。
Classfier-Action Subsystem总览
CA子系统的主要角色是查看到来的数据包或者元数据,混合使用分类过滤器和行为执行模块来达到定义的策略。
在CA子系统中对包处理的方法上,有Unix哲学的强烈影响。任何分类器或者操作(Action)可被写作内核模块,并且一个策略能够被用于编织不同的组件来得到定义的结果。
我们将使用受欢迎的tc单元作为指导,通过本文剩余的部分,并且强调不同的架构;然而,我们想指出任何应用能够使用同样的网络链路API,他们被tc使用并且这些特性没有被绑定到tc。
tc filter add dev $DEV parent 1:0 protocol ip prio 10 \ u32 match ip protocol 1 0xff \ classid 1:10 \ action ok
Listing 1: simple Egress Classifier-Action Policy Addition
表单1展示了简单的egress策略,采用了tc的BNF语法。我们使用表单1来描述一些关于CA子系统的重要性质:
- 附着点:将id为1:0的egress qdisc附着到一个任意的端口$DEV上。
- 内置匹配(built-in match):匹配ipv4的数据包(protocol ip)。
- 优先级为10的过滤。
- 使用规定的分类器类型的过滤器:u32分类器,匹配icmp(protocol I mask 0xff)包,注意每种分类器将会属于自己的属性规则,如上表所示。
- 向上的流匹配 内置操作:选择一个id为1:10的queue/disc
- 可编程操作: 接受包。注意,每一个可编程行为都有如图上所示的自己的专有属性。
分类和过滤器
如图3和图4以及表单1所展示的,qdisc被用作策略过滤器的附着点(attachment point)。
内建的过滤器被描述于(be descirbed in)使用“protocol ip”语法的策略(policy)。内建的过滤器查询非常高效因为协议类型(protocol type)已经在cpu缓存中,恰好在查找发生的点上。内建的匹配非常快速地辨别出要使用哪个策略树。
每个过滤器都有被表单1描述的优先级属性。过滤器被保持在用于每个协议的优先级顺序表中(例如匹配内建的分类器)。在相同的协议上用两个过滤器协议来匹配相同的数据 是可能的,但是它们有不同的行为执行路径图,然后将它们合并,以提供图形的连续性,稍后将展示。**优先级域(priority field)的目的是模棱推理以防这些过滤器冲突。**低优先级更加重要。
表单1也展示了被用在策略定义中的u32分类器类型。CA子系统提供了一个附件框架来定义任意的分类器。
(CA子系统)支持许多种分类算法,不限于以下算法:
- u3217。在任意数据包偏移量上使用32位值掩码块进行过滤器匹配。用这个低等级分类器可以建立非常高效的协议解析树。
- fw。非常简单的分类器,使用了skb标记元数据来匹配。
- route。使用ip路由属性元数据(例如路由重新)类匹配。
- rsvp。基于RSVP[13]过滤定义的分类。
- basic。一个更小的分类器的收集,能够被联合进入一个更复杂的匹配。
- BPF。基于伯克利包过滤[17] [21] 作为匹配引擎。
- Flow。各种包流和一般元数据选择器(包括连接跟踪,用户id, 组id等)的集合,它们能够联合成一个复杂的策略。
- 一个Openflow分类器[14]。一个N元组分类器,它观察所有被OF规则定义的数据包域.
- 其他各种各样的分类算法。如果以上的你都不喜欢,则自己写一个。
注意,以上每个分类器都有内在的由自己的元素组成的结构。图5展示了一个u32过滤器设置布局的解析树。可以创建非常高效的解析树用于规则设置但是需要注意细节[^9]。
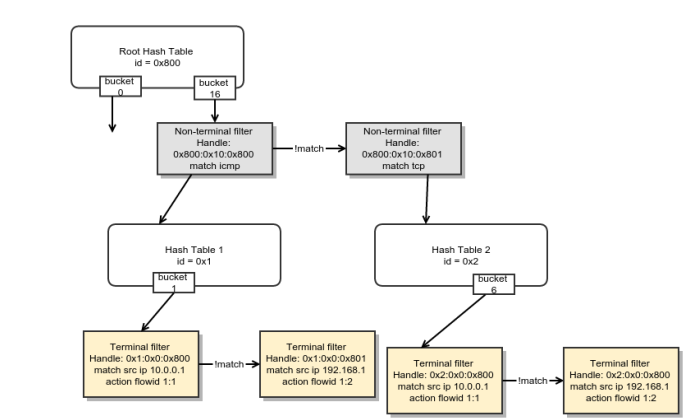
译注: 此图展示了u32分类器解析树的结构。
分类器设计原则(Classifier Design Principles)
分类器结构的两个指导原则:
- 不可能拥有一个普适的分类器,因为当下的技术在不断改变,总是有一些新的专业的flavor-of-the-day的分类算法。例如,展示的u32分类器匹配使用任意的32位值/mask对的skb数据,在任意的包偏移量上。而fw 分类器匹配的是skb->mark的元数据。
- 有时我们需要超过1个的分类器类型,针对不同的类型都要有一个,来正确地匹配需求。因此一个重要的CA设计准则是允许多个分类器类型可以在策略需要时被使用。
基于这些原则,基于一个分类算法(例如u32或者bpf)首先匹配,然后再基于一个不同的算法(例如, ematch 文本分类,用字符串匹配,通过 Boyer-Moore算法[16] 或者通过Knuth-Morris-Pratt算法[17] 又或者无论什么最新的文本搜索算法)[^10]。通过不许被选择的分类算法的垄断,CA设计选择孕育出了创新。
执行动作(Actions)
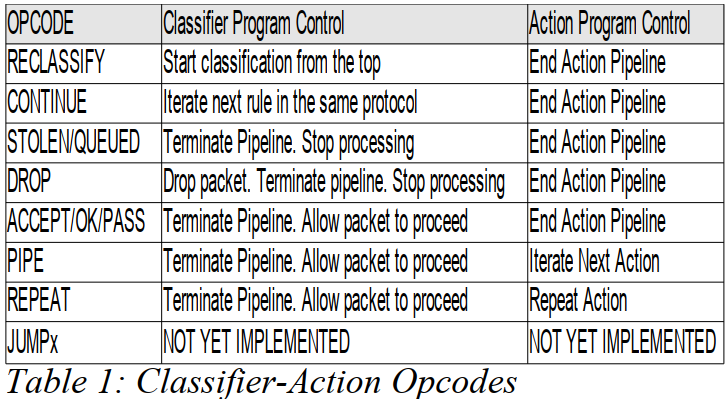
表1展示了当过滤器实现匹配时要被执行的动作。
正如早前提到的,存在选择class/flow/queue的内建行为。表单1展现了内建行为正选择一个id为1:10的class。表1的策略更长远地描绘了数据包可以被接受,并且被允许处理在处理管道(processing pipeline)中继续。通过设计,行为遵守了Unix哲学——写程序要每次只做一件事并做好它。**一个例子是,一个策略可以和多种action组合,用类unix“A|B|C|D”管道,在管道中,每个后来的行为都精炼更远的先前的执行动作的执行结果,并且在unix管道中的任何位置都能被管道中的任何行为终结。**当我们谈论关于可编程执行动作管道的时候还有更多。
每个行为类型实例都维持了自己的私有状态,该状态一般被到达的数据包更新。但是有时候会被系统行为更新(计时器等)。
为了展现一些行为的语法,让我们展现一些从表1中被编成的执行动作的属性。在发送10个ping包到一个远程位置后,输出被捕获了,如表单2展示:
action order 0: gact action pass index 1 ref 1 bind 1 installed 32 sec used 15 sec Action statistics: Sent 980 bytes 10 pkt(dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0
List 2: 执行动作的运行时策略细节
执行动作“pass” 是gact(通用行为,即generic action的缩写)。在这个案例中有些事物被展现:
- 该行为(index 1)的32位系统全局的每个行为类型实例的标识符,独特地标识了行为类型。
- 该行为被绑定到了多少个策略图上(bind 1); 一个在这种情况下。行为能够被分享在多个策略上(稍后将会做详细介绍)。
- 时间(Age)。多久前该行为被安装(Installed)了(32秒)。
- 活动。什么时候最新一次的行为被使用了(15秒前)。
- 一串标准的策略像有多少字节(380)和多少包(10)被该行为处理了。其他的状态
一些行为的例子包括:
- nat。没有无状态NAT。
- 检验和。重新计算IP和传输校验和并且修复它们。
- TBF 策略器。 一个和简单费率表一样的令牌桶。
- 一般行为(Generic Action, gact)。一般行为会接受、丢弃数据包或者协助管道处理(aid in CA pipeline processing)。下文有更多关于gact的。
- Pedit。一个通过用的包编辑器。它使用值/掩码对(value/mask pairs) 并且能够在包上进行各类运算(异或,或,并且, 等等)。
- Mirred。将包重定向或者镜像到一个端口。
- vlan。加密或者解密VLAN 标记。
- SKb编辑。编辑SKb元数据。
- 连接码。联系网络过滤器连接总积细节到skb标记。
- 等等。可写一个新的。
(分类器行为可编程控制)Classifier Action Programmatic Control
CA子系统提供了丰富的低等级可编程接口用来组成策略以实现包服务。
CA的策略定义的核心是两种管道控制(pipeline controls)。因为缺乏更好的描述词(term), 我们将会称它们为pipeline opcodes。 opcode的第一部分驱动了分类模块,而第二部分驱动了执行模块行为(the action block behavior)。
每个action通过用一个或者更多的opcode来驱动策略流。举例来说,一个策略行为能够被编程,当速率过大时,结束管道和表明一个包要被丢弃或者它可能被编程到采取一个不同的处理路径到更低的服务质量上(the quality of service)。 本质上,意图是从控制层面编程的,内核CA模块实现这些机制。(译注: Linux哲学中的意图与机制分离)
这一点是重要的,即介绍通用行为gact, 它存在的唯一原因就是去传播(propagate) 管道opcode 用来实现可编程性(for the purpose of programmability)。一个gact实例总是可用管道opcode编程的(例如表单1, “ok” 这一行为)。当gact收到一个包,它便计算这个包并且基于该可编程管道的opcode来帮助定义控制流。
分类控制(Classfication Controls)
图6展示了一些控制图,这些图提供了可影响包服务的管道可编程性。

包进入了分类器模块(classfifier block),一旦匹配了一个规定的过滤器规则,便通过执行模块(the action block)被执行操作。靠着规定好的行为定义,执行结果肯恩是:
- 重新分类(Reclassify)。包通过整组被绑定的过滤器规则从顶部再次执行。对于一些情况,这可能是有用的——在解隧道(detunneling)和需要在内部包(inner packet)的包头(header)或者隧道上增加策略,以及需要加入策略到外部的包头(outer headers)上。
- 继续(Contiune)。包继续被处理,通过下一步更低级的过滤器规则。
- 丢弃(Drop)。管道被终结并且包被丢弃。
- 通过(Pass/OK)。管道被终结,然而包被接受,并且被允许处理更远的协议栈,在ingress口或者从egress口上出去。
- 偷取(Stolen)。管道被终结,数据包被action偷取。这意味着包已经被注射到一个不同的管道中,或者它能够被行为排队到某处,因此它能够后来被注射(injected)到一些任意的管道中。
操作码:重新分类(Opcode: Reclassify)
看一看如何在策略定义中使用重新分类控制码。
表3展示了一系列规则,将一个vlan的报头弹出并且丢弃。

如果数据包来自10.0.0.21,否则如果来自任何属于10.0.0.0/24网段的host, skb的元数据队列映射被设置到3,被用于接下来的向下流量(downstream)。
为了展示可编程性的方面,用图来标识更加简单。表3被图7虚拟化了。
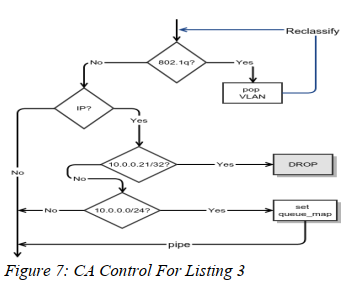
如图所示,我们能通过利用过滤器规则优先级来轻松构建if/else结构。 重新分类操作码给我们机会来重新开始策略图。本质上,它是一个循环程序控制,因为(in that)解析操作被重启了。改图也展示了丢弃操作码。
图7中也展示了管道操作码(a pipe opcode)控制结构。虽然它没有在表3的策略中展示,但是该操作码是被skbedit 行动(Action)默认配置的。管道是一个指向管道线的事物,为了继续处理接下来的行动(在上图中没有显示)。
操作码:继续(Opcode: Continue)
让我们看一看如何能使用“Continue”操作码。

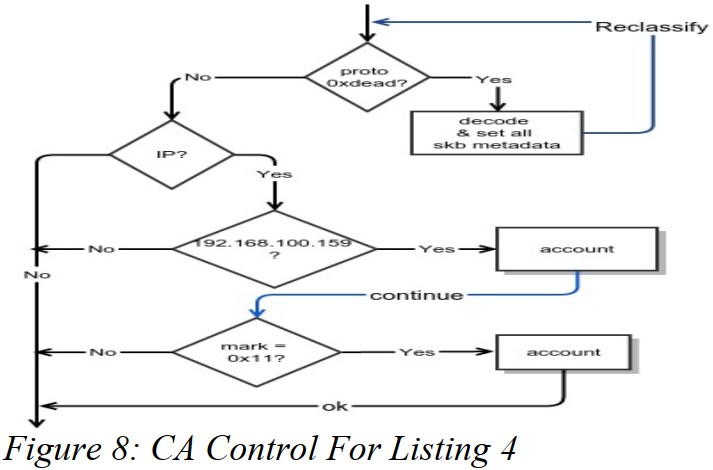
表4展示了一系列弹出(pop)IFE协议报头的规则,深入挖掘包是否是从192.168.100.159发过来,再看是否它有0x11的skb掩码。
图8展示了表4的图形化(visualization)。
观察该图的重要细节是,"继续"控制结构本质上给了我们一个 else if 扩展结构,对if/else结构进行了扩充。也在图中观察到了另一个出现的操作码"Ok"。
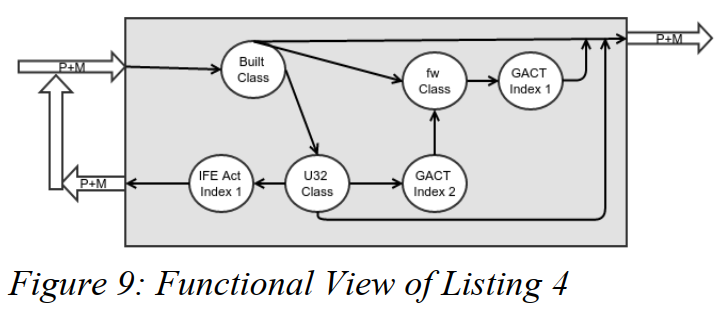
图形化该策略的另一种方式是从一个功能点(a functional point of view)视图来看。图9展示了表4的功能点。
行为控制(Action Controls)
行动也具有操作码,该码是在它们的管道线范围内被规定好的(译注:应该是对这些行为进行编排)。这些是:
- Pipe。等价于Unix的pipe结构(Equivalent to unix pipe construct)
- Repeat。循环结构。
- Jumpx。本质上是goto结构。
操作码:pipe
图10展示了一个简单的行动的pipe控制的功能图。
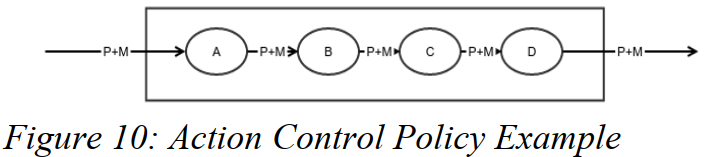
上面被展示的简单的例子中数据包被一个行动连导(pipe)到下一个(行动)(译注: A, B, C ,D 四个表示行动,action block)。图10的意图通过用pipe操作码对每个行为进行编程来实现。与在Unix中一样,行动工作管道也可以被编程进入到行动的条件终结(译注: 有些条件可以被编到行动中,从而终结pipeline)As in unix, the action work pipeline can also be terminated by conditions programmed into actions ; 有时候这是由于反应处理错误或者其他的情况,例如一些被超越的门槛。
操作码:Repeat
另一个操作码,被重定向到行动模块的,是REPEAT模块。如图11展示的行动C在一些条件下可能会分支跳转到行动D,或者请求管道(pipeline)来重新重新关联(re-invoke)它。
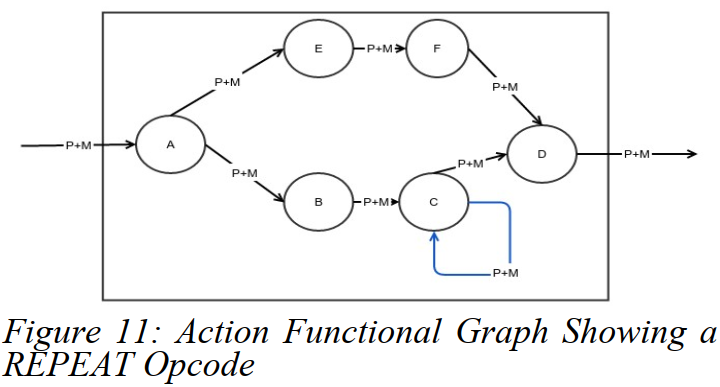
本质上REPEAT操作码是循环结构。REPEAT操作码的范围(和PIPE操作码一样)旨在行动块(action block)中有效(对应地对reclassify来说,它是全局影响的)。
有一个额外的操作码JUMPx, 被设想展望过,但是由于没有强大的用例,因为从没有被实现。An additional opcode, JUMPx, was envisioned back then but was never fully implemented because no strong use cases emerged. 作者仍然相信,它是有用的,并且当时机成熟会实现它(when time follows)。JUMPx 被设计的意图是作为一种在管道中跳过某个行为的方式。
正如先前提到的行为块工作流能够被如OK,DROP,STOLEN操作码终结。
对分类器行动的可编程控制性的总结(Classifier Action Programmatic Control Summary)
我们已经展示了组成复杂策略定义是可能的,该策略可以由CA操作码实现。程序控制结构像 if/else/else if / loop(以及goto)是可以被具有可编程状态的行动和过滤器规则的形式来实现的。
下表Table1提供了所有被支持的操作码的总结以及它们如何被分类器或者行动块进行解释。
行动实例分享(Action Instance Sharing)
行动实例可被分享以及被多个策略图约束(bound by multiple policy graphs)。在复杂的策略图中,这可能是有用的,在途中,流(flow)中的联合计数或者资源分享是被需要的。
我们使用图12来证明一个用例,在该用例中,几个行动实例被分享(conntrack实例1, 策略器实例2, 丢包器实例1)。图11展示了一个设置,在该设置中, 连接到网络的行动和它们的下一个邻居分享了它们的通路。邻居被无线端口,wlan0连接。所有者的家庭网络通过有线端口,eth0连接。目标是限制邻居的下载速度不超过256Kbps并且将这256Kbps的下载与所有者的下载相竞争。The goal is to restrict the neighbor's downloads rates to no more than 256Kbps and to have the shared 256Kbps contended for with the owner's downloads.
两个策略规则被提供——一个给家庭网络,一个给邻居网络(分别被用红色和蓝色线条展示)。

所有的邻居的接受包都被标记,通过使用nftable用连接追踪掩码1标记。家庭网络流量被掩码值2标记。Netfilter子系统存储了这些掩码的连接状态。下载请求从WAN端口eth1出来。从互联网上得到的回应数据包从eth1的Ingress口进入;它们被u32过滤器发送到connmark行动实例1。Connmark实例1咨询了netfilter连接追踪状态并且将所有流映射到了追踪掩码上。接着包在有追踪掩码的前提下被fw过滤器重新分类。所有有着掩码1和2的包都被传入shared policer 实例1中。如果总速率(aggregate)超过了256Kbps,policer就会做出判断(pass a verdict on),将发给邻居的数据包丢弃。另一方面家庭网络使用者的包就不会被丢弃。当policer实例1总速率超过,它们(指家庭网络)被送到另一个policer(实例2)上,该实例允许它们使用额外的1Mbps速率,直到超过被丢弃。
流生命周期(Flow Aging)
所有的行动在它们被安装和到最后一次使用时都是被追踪的。延长流的生命周期的简单方式就是向filter中添加pipe行动。一个控制空间的应用能够被用于取消空闲流条目, 通过定期查看生命周期字段(the age fields)的方式。
延后绑定(Late binding)
创件行为实例,给他们身份验证并且之后绑定它们到一个或者更多的策略上是可能的。

表单5展示了连接掩码行动被实例化(instantiated)并且被后续绑定到了一个流上。注意:同样的行动实例能够被绑定到多个流上。
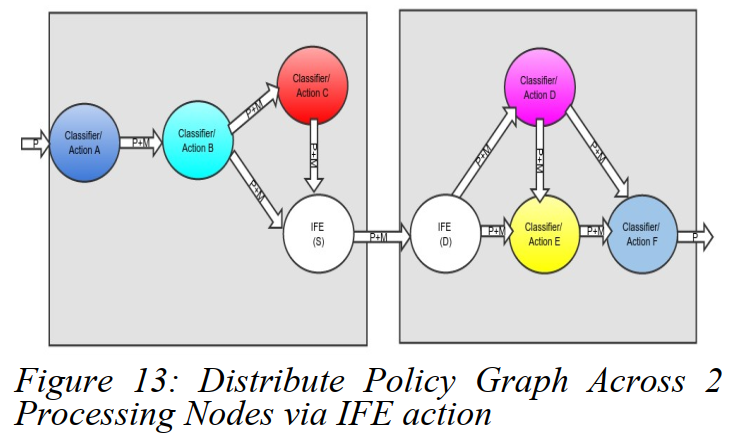
跨CA节点间的扩展(Extending the Classifier-Action Across Nodes)
文献[15]描述了InterFE(IFE)行动,它能够扩展一个策略图并且让它跨多个节点。这一般用于缩放实例化的策略图或者访问专门的处理。可以认为IFE作为一个扩展包(a patch)扩展了跨节点的策略图(物理机,虚拟机,容器等)。
未来的工作(Future Work)
社区可以开展一些适当的活动,使我们进入下一阶段。
提升可用性(Improving Usability)
TC架构的一个主要挑战是可用性。一些tc单元BNF语法的结构,尽管是准确和完善的,仍是非常低等级的并且对于懒人不友好。Werner Almesberger尝试用tcng[11]提高可用性,但是在某些方面偏离了该主题。那项工作,如果任何人有兴趣都可参与。
TC与CA子系统总体上是合适的编程语言。如我们展示的许多必备的可编程控制(循环,分支,状态执行)已经在其中。它是可能扩展tc的BNF语法到更高级的语言的。作者对此工作非常有兴趣并且欢迎大家在此领域讨论。
功能发现(Functional Discovery)
CA子系统早期版本(几年前的)内置了一些基本的发现功能。没有任何用户空间的代码在未来会被添加,所以十年后删除它听起来很合理。过去这些年作者感到它已经学习了一些课程尤其是对ForCES[22]的提高并且与许多含有高价值但是功能各不相同的硬件打交道,这使得他感到是时候去做一个更新的展望。然而,这不属于该文的讨论级别。
硬件卸载(Hardware Offloading)
对于CA子系统结构(协议结构和功能状态表达式,the control constructs and functional statement expression),它将会非常适合去操作硬件的整个结构。Infact on reviewing a lot of hardware layout one would observe there is already a lot of synergy with the TC CA architecture defintions. 译:事实上,回顾大量硬件的布局,我们可以发现已经有许多与TC的CA架构定义协同的布局了。
图13展示了一个Realtek RTL8366xx的数据路径和到TC的映射。
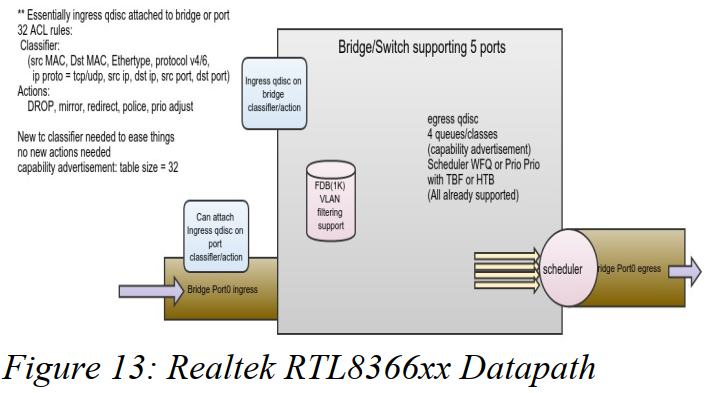
尽管RTL8366xx是一个微型芯片,许多其他的ASIC具有相同的结构展示,但是功能与能力不同。有许多挑战要解决,如硬件间的功能不匹配以及策略映射。我们有许多社区处理过quarks(来自硬件的bug)以及特征差别,可以利用这些差别正确使用此部件。从图13可看到,硬件数据通路(datapath)与linux数据通路有非常接近的相似性。
作者相信在Linux控制接口间有很强的需求用于紧耦合,这些接口已经被广泛部署并且硬件卸载。有必要去提供工具的透明度。在linux工具中存在巨大的生态系统,当它可能去拥有一个新工具是,它就应该被完成,如果当前的工具及无法提供平滑连续性(smooth continuity)。换句话说,硬件的ASIC提供了驱动,驱动被当前的Linux工具与API执行了透明性。
知识(Acknowledgements)
略
注解
vethhttps://segmentfault.com/a/1190000009251098
链路聚合,分为bonding聚合和team聚合。所谓链路聚合,就是用
参考:https://www.geek-share.com/detail/2635871540.html
https://blog.csdn.net/lhwhit/article/details/108007853
https://blog.51cto.com/u_9291927/2594168
内核旁路,
-
在SNMP世界,Linux端口将能够等价于抽象的接口(interface)↩
-
ethernet-derived, derive是获得,被动有衍生之意↩
-
stacking netdev,↩
-
tun/tap是Linux内核栈中的虚拟网络设备,参考Linux虚拟网络设备↩
-
veth是成对出现的。它本质是管道。↩
-
原文为“in the traditional Unix sense of separating policy from mechanisms; the datapath being the mechanism implementation.” 省略了it is, 指代前一句,说这是Unix传统意义上的策略与机制分离。 separate A from B是指A从B中分离出来。 mechanism,机制,机理。机制决定了如何做,策略决定做什么,策略只能在机制下做出,所以datapath是机制,基于datapath的control可以是用户空间,也可以是内核空间,Linux中选择用户空间,这就是策略↩
-
be invoked by, 被调用。内核调用回调函数用于处理数据包,这些数据包在内核栈中穿过对应的hook点。↩
-
Netfilter[1] has too many powerful features that we would not be doing it justice in this short description, but we wanted to highlight a few features it possesses。 do it justice , 做到公正,在possess, v,拥有↩
-
Figure 2 shows 3 blocks labeled with the term Traffic Control. the term 可以理解为说法,术语,称作,标有,标识,就是“指代。指称”。↩
-
built-in filter, 内置的,原文似乎写漏 了中间的符号。↩
-
原文为,Actions are executed when a resulting classfier filter matches. resulting意为作为结果的,整句话可以理解为,通过policy生成的classifier, 需要结合上下文。↩
-
It's role is to sort which class/flow a packet belongs to and where to multiplex to in the policy graph. which 修饰class/flow, 宾语实际就是class/flow, 这个宾语是 a packet belongs to的。 which和where做宾语从句,which后面要接名词,where不用接,可以翻译为什么的位置。↩
-
节省工作的算法, work conserving, 实际上应是work-conserving, 动名词结合成形容词。↩

- input 子系统架构总结
- wifi android 子系统架构
- input 子系统架构总结
- Linux 输入(input)子系统架构分析
- linux之i2c子系统架构---总线驱动
- Linux内核架构 Linux设备驱动 Linux电源管理 Linux音频子系统 Linux中断子系统 Linux时间管理系统 Linux输入子系统
- SPI子系统驱动架构 - 具体实现
- input 子系统架构总结
- 子系统不同,架构不同
- 子系统不同,架构不同
- 子系统不同,架构不同
- 输入子系统_架构流程及详解
- input子系统——架构、驱动、应用
- input 子系统架构总结
- 分布式架构学习之:019--分布式服务子系统的划分
- LinuxI2C子系统架构
- 基于MTK架构的input子系统分析
- Linux网络协子系统架构
- SPI子系统驱动架构 - 驱动框架
- 主动分层设计的驱动子系统架构模拟