论文翻译:2020_The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Speech Quality and Testing Framework
论文地址:https://arxiv.53yu.com/abs/2001.08662
#INTERSPEECH 2020深度噪声抑制挑战:数据集,主观语音质量和测试框架
###摘要: INTERSPEECH 2020深度噪声抑制挑战旨在促进实时单通道语音增强的合作研究,旨在最大限度地提高增强语音的主观(感知)质量。评价噪声抑制方法的一种典型方法是对原始数据集进行分割得到的测试集使用客观度量。许多出版物报告了从训练集的相同分布提取的合成测试集的合理性能。然而,通常模型性能在真实记录上显著下降。而且,大多数传统的客观度量与主观测试没有很好的关联,而且实验室主观测试对于大型测试集是不可扩展的。在这个挑战中,我们开源了一个大的纯净的语音和噪声语料库,用于训练噪声抑制模型和一个有代表性的测试集,以真实世界的场景,包括合成和真实录音。我们还开放了一个基于ITU-T P.808的在线主观测试框架,供研究人员快速测试他们的开发。这个挑战的获胜者将在使用P.808框架的一个有代表性的测试集的主观评价的基础上选择。 **关键字:**噪声抑制,语音增强,深度学习,音频,数据集 ###1 引言 随着远程工作和开放式办公环境的人数不断增加,对具有良好语音质量和清晰度的视频/音频通话的需求比以往任何时候都更加重要。背景噪声对语音质量的影响是造成语音通话质量差的主要原因之一。传统的语音增强(SE)技术是基于统计模型估计的噪声观测。这些方法对平稳噪声的抑制效果较好,但对非平稳噪声的抑制效果较差。最近,SE被认为是一个有监督的学习问题,在这个问题中,语音和噪声中的模式是使用训练数据[6]来学习的。利用深度神经网络(DNN)对语音进行频谱或时域估计。基于DNN的方法在抑制非平稳噪声[7]-[10]方面优于传统的SE技术。 经过40多年的噪声抑制技术研究,信号处理和基于深度神经网络的方法得到了发展,这些方法利用时域音频信号或光谱特征[1]-[5]来估计乘性掩模,从而降低噪声。大多数已发表的文献报道了基于客观语音质量度量的实验结果,如语音质量感知评价(perception Evaluation of speech quality, PESQ)、感知客观听力质量分析(perception objective Listening quality Analysis, POLQA)[11]、虚拟语音质量目标听者(Virtual speech quality objective, ViSQOL)[12]、语音失真比(speech to Distortion Ratio, SDR)等。这些指标被证明与主观测试[13]没有很好的相关性。很少有论文报告主观的实验室测试结果,但它们要么没有统计意义,要么测试集非常小。 深度学习中常见的做法是将数据集分成训练集、验证集和测试集。对于SE任务,训练集由噪声语音对和纯净语音对组成。噪声语音通常是由纯净的语音和噪声混合而成的。在综合测试集上测试开发的模型可以对模型性能进行启发式的测试,但这不足以确保在现实环境中部署时的良好性能。开发的模型应该在不同的嘈杂和混响条件下的有代表性的真实录音中进行测试,这些声音和噪声是在相同的声学条件下由相同的麦克风捕获的。由于纯净的语音信号和噪声信号是独立捕获的,因此很难用合成数据来模拟这些情况。这使得研究人员很难比较已发表的SE方法,并选择最好的方法,因为没有通用的测试集是广泛的,并代表真实世界的噪声条件。此外,也没有可靠的主观测试框架,每个人在研究社区可以使用。在[13]中,我们开源了微软可伸缩噪声语音数据集(MS-SNSD)和ITU-T P.800主观评估框架。MS-SNSD包括纯净的语音和噪声记录和脚本,以合成噪声语音和增强生成训练集。此外,还提供了一个不相交测试集进行评价。但测试设备缺少真实的录音,并且没有足够的混响噪声条件。此外,P.800的实现缺少了P.808的一些众包功能,如听力和环境测试,以及陷阱问题。 深度噪声抑制(DNS)挑战是通过开放训练/测试数据集和主观评价框架来统一SE领域的研究工作。我们提供了比MS-SNSD[13]大30倍的大型纯净的语音和噪声数据集。这些数据集附带了可配置的脚本来合成训练集。参与者可以使用他们选择的任何数据集进行培训。测试集的一半将被发布给研究人员在开发过程中使用。另一半将被用作测试集,以决定最终的比赛获胜者。使用ITU-T P.808[14]的在线主观评价框架将用于比较提交的SE方法。我们还提供了一种最先进的SE方法的模型和推理脚本,作为比较的基本算法。基于SE方法的计算复杂度,这个挑战有两条路径。一个轨道侧重于实时SE方法,另一个轨道是针对非实时方法。 第2节描述数据集。第3节描述基本SE方法。第4节讨论了在线主观评价框架。挑战赛和其他后勤规则见第5节。 ###2 数据集 发布纯净的语音和噪声数据集的目的是为研究人员提供广泛和有代表性的数据集来训练SE模型。之前,我们发布了MSSNSD[13],重点关注可扩展性。近年来,由于YouTube、智能设备和有声读物上的内容创作不断增加,互联网上可获得的音频数据数量呈爆炸式增长。虽然这些数据集中的大多数对于训练音频事件检测器、自动语音识别(ASR)系统等任务是有用的,但大多数SE模型需要一个清晰的参考,这并不总是可用的。因此,我们合成了噪声-纯净的语音对。 ####2.1 纯净语音 纯净的语音数据集来源于公共音频图书数据集Librivox1。Librivox语料库在许可的创作共用4.0许可证[15]下可用。Librivox拥有志愿者阅读1万多本不同语言的公共领域有声读物的录音,其中大部分是英语。总共有11,350名发言人。这些录音的一部分是高质量的,这意味着讲话是在一个安静和较少混响的环境中使用高质量的麦克风录制的。但也有很多录音存在语音失真、背景噪声和混响等问题。因此,基于语音质量的数据过滤是非常重要的。 我们使用在线主观测试框架ITU-T P.808[14]对书籍章节进行主观质量排序。Librivox中的音频章节长度不等,从几秒到几分钟不等。我们从每本书的章节中随机抽取10个片段,每个片段持续时间为10秒。对于每个剪辑,我们有3个评分,所有剪辑的平均意见得分(MOS)被用作书中的章节MOS。图1显示了结果,显示了质量从非常差到非常好。
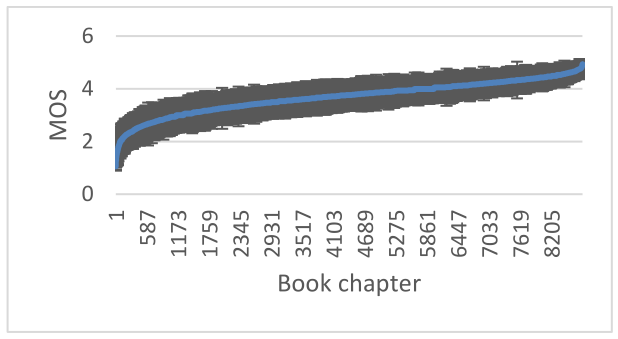
图1:经过95%置信区间排序的Librivox P.808 MOS质量
MOS的上四分位数被选择为我们的纯净语音数据集,它们是MOS作为度量的剪辑的前25%。上四分位由4.3≤MOS≤5的音频章节组成。我们删除了演讲少于15分钟的演讲者的片段。得到的数据集包含了2150名演讲者超过500小时的演讲。所有过滤过的片段都被分成30秒的片段。 ####2.2 噪声数据集 噪音剪辑是从Audioset2[16]和Freesound3中选择的。Audioset收集了从YouTube视频中提取的约200万个人类标记的10个声音片段,属于约600个音频事件。就像Librivox的数据一样,某些音频事件类也被夸大了。例如,有超过100万个音频课程、音乐和演讲的剪辑,而少于200个课程的剪辑,如牙刷、嘎吱声等。大约42%的剪辑有单一类别,但其余可能有2到15个标签。因此,我们开发了一种采样方法来平衡数据集,使每个类至少有500个剪辑。我们还使用了语音活动检测器来删除带有任何类型的语音活动的剪辑。原因是为了避免噪声抑制模型对语音的抑制,该模型训练来抑制语音类噪声。结果数据集有大约150个音频类和6万个剪辑。我们还增加了从Freesound和DEMAND数据库[17]下载的10,000个噪音剪辑。所选择的噪声类型与VOIP应用程序更相关。 ####2.3 噪声语音 纯净的语音和噪声数据集可以在repo4中找到。噪声语音数据库是通过在不同的信噪比(SNR)水平上添加纯净的语音和噪声来创建的。我们使用语音和噪声都活跃的段来计算分段信噪比。这是为了避免在脉冲噪声类型如关门、哗啦声、狗叫等中超过振幅水平。我们通过增加纯净的语音和噪音来合成30秒长的剪辑。信噪比水平是在0到40 dB之间的均匀分布采样的。然后将混合信号设置为目标均方根(RMS)水平,采样范围为-15 dBFS和-35 dBFS之间的均匀分布。数据生成脚本在DNS-Challenge回购协议中是开源的。 ####2.4 测试 我们正在开放一个新的测试集,包括合成和真实的录音。一般的做法是在一个综合测试集上评价SE方法。但是一个合成测试集并不能很好地代表我们在野外观察到的情况。合成测试集在使用需要明确引用的客观度量(如PESQ和POLQA)在开发阶段调优模型时可能很有用。在合成数据中,通常使用两种不同的麦克风在不同的声学条件下采集原始的纯净语音和噪声,并将其混合形成含噪语音。在真实的录音中,纯净的语音和噪音是在相同的麦克风和声学条件下捕获的。 测试集分为4类,每类300个剪辑: 1. 合成剪辑没有混响 2.合成剪辑混响 3.微软内部收集的真实录音。 4.来自Audioset的真实录音 对于合成测试片段,我们使用了格拉茨大学(Graz University)的纯净语音数据集[18],它包含了20个说话者说的4,270个录音句子。对于混响合成剪辑,我们使用在微软内部记录的RT60从300ms到1300ms的房间脉冲响应,将混响添加到纯净的文件。我们从我们认为对VoIP场景非常重要的12个噪音类别中选取15个片段,合成180个噪音片段。这12个类别分别是风扇、空调、打字、关门、哗啦声、汽车、咀嚼声、椅子吱吱作响、呼吸、复印机、婴儿哭闹和吠叫。剩下的120个噪音剪辑是随机从剩下的100+噪音类别中抽取的。信噪比水平从0 dB到25 dB之间的均匀分布中采样。微软内部收集的真实录音包括在各种嘈杂的开放办公室和会议室中录制的嘈杂讲话。我们从AudioSet中精心挑选了300个语音混合噪音的音频剪辑,我们认为这些音频剪辑与我们在嘈杂环境中经历的音频通话有关。 ###3 基线SE方法 作为基线,我们将使用最近开发的SE方法,它是基于循环神经网络(RNN)。为了便于参考,我们将此方法称为噪声抑制网(NSNet)。该方法使用对数功率谱作为输入,利用基于门控循环单元(GRU)和全连通层的学习机预测每帧的增强增益。详细的方法请参考论文。NSNet具有计算效率。在使用ONNX运行时v1.1的Intel四核i5机器上,提升20ms帧只需要0.16ms。它是用一个大的测试集进行主观评价的,显示了对传统的SE方法的改进。 我们在挑战dns -挑战repo中开源了ONNX格式的推理脚本和模型。 ###4 在线主观评价框架ITU-T P.808 我们使用ITU-T P.808语音质量主观评价和众包方法[14]方法,使用绝对类别评分(ACR)来估计平均意见得分(MOS)来评估和比较语音质量评价方法。我们使用亚马逊土耳其机械平台创建了P.808的开源实现。本系统具有以下特点/属性: 评级人员首先通过听力和环境测试获得资格,然后才能开始评级剪辑。这确保了评分者有足够的听力能力,一个优质的听力设备,和一个安静的环境进行评分。我们的实现允许评级者在合格后立即开始评级剪辑,这比单独的资格阶段提高了约5倍的评级速度。 评价者会得到几个训练例子,但不会使用结果进行筛选;该培训用于锚定目的。 音频剪辑按剪辑组进行分级(例如,N=10)。每组包括一个已知地面真相的金夹子(例如一个纯净或很差的夹子)和一个陷阱问题(例如,“这是一个中断:请选择选项2”)。黄金和陷阱问题用于过滤那些不注意的“垃圾邮件”评分者。 每个小时的评级者也给予比较评级测试使用黄金样本(例如,哪个更好,A或B),以验证他们的环境仍然是有效的做评级。 评级者被限制为每P.808建议评级有限数量的剪辑,以减少评级者疲劳。 为了验证测量系统的准确性,我们对ITU增补23实验3[19]数据集进行了评级,该数据集已经发布了基于实验室的MOS结果。该系统与ITU增补23中给出的实验室结果的斯皮尔曼相关系数为0.93 (MOS是根据测试条件计算的)。为了验证系统的可重复性,我们运行了两次ITU增补23(在不同的日子,重叠评级<10%,评级为运行1的1/10),结果相似(见表1)。
表1:P.808与ITU增补23的Spearman秩相关

###5 DNS挑战规则和时间表 ####5.1 规则 所有参赛者必须遵守以下规则才有资格接受挑战。 1、参与者可以使用他们选择的任何训练数据集。它们还可以向所提供的数据集增加额外的数据。他们可以以任何方式混合纯净的语音和噪音,以提高他们的SE方法的性能。我们还鼓励参与者将他们的数据集开源,以便帮助更大的研究社区。 2、在开发阶段,参与者可以在任何测试集上测试他们开发的方法。但是我们鼓励他们使用我们的测试集,因为它是广泛的,并且是真实世界场景的一个很好的表示。 3、根据计算复杂度的不同,每个参与的SE方法都将落在两个轨道中的一个。轨道1专注于低计算复杂度。在时钟为2.4 GHz或同等处理器的Intel Core i5四核机器上,该算法处理一帧T(单位ms)大小的帧的时间应该小于T/2(单位ms)。帧长T应小于或等于40ms。Track 2对计算时间没有任何限制,因此研究人员可以探索更深入的模型来获得卓越的语音质量。 4、在这两种轨迹中,SE方法最多可以有40ms的超前。为了推断当前帧T(单位ms),算法可以访问任意数量的过去帧,但只能访问未来帧的40ms (T+40ms)。 5、获胜者将根据在使用ITU-T P.808框架的盲测集上评估的主观语音质量,从每条轨道中选出。 6、盲测套装将于3月18日提供给参赛者。参加者应使用他们开发的模型将增强的剪辑发送给组织者。我们将使用提交的未经修改的剪辑进行ITU-T P.808主观评价,并根据结果选出优胜者。参与者被禁止使用盲测集来重新训练或调整他们的模型。他们不应提交使用其他噪声抑制方法的增强剪辑,因为他们没有提交INTERSPEECH 2020。如不遵守以上规则,将被取消参赛资格。 7、参与者应该报告他们的模型的计算复杂度,包括参数的数量和在特定CPU上推断帧所需的时间(最好是Intel Core i5四核机器的时钟为2.4 GHz)。在提交的建议书中,差异小于0.1 MOS的,将给予复杂性较低的模型较高的排名。 8、每个参与团队都需要提交一份INTERSPEECH论文,总结研究成果并提供所有细节,以确保重现性。作者可以选择在他们的论文中报告额外的客观/主观指标。 9、提交的论文将经过INTERSPEECH 2020的标准同行评审程序。论文需要被会议接受,参与者才有资格接受挑战。 10、提交常会的有关文件可列入这一挑战,以促进深入讨论。
####5.2 时间轴 2020年1月20日:发布用于培训和测试的数据集和脚本。 2020年3月18日:发布盲测装置。 2020年3月22日:参与者提交增强片段的截止日期。 2020年3月25日:主办单位将通知参赛者竞赛结果 2020年3月30日:INTERSPEECH 2020常规论文提交截止日期。
####5.3 支持 参赛队伍可向dns_challenge@microsoft.com发送电子邮件向组织者提出问题或需要澄清挑战的任何方面。
###6 结论 这一挑战旨在促进实时单麦克风噪声抑制异常主观语音质量。我们正在为研究人员提供训练和测试数据集来训练他们的模型。最终评估将使用ITU-T P.808进行。
###7 感谢 P.808的实现是Babak Naderi编写的。
###8 参考文献 [1] Y. Ephraim and D. Malah,“Speech enhancement using a minimum mean-square error log-spectral amplitude estimator,” IEEE Trans. Acoust. Speech Signal Process., vol. 33, no. 2, pp. 443–445, Apr. 1985, doi: 10.1109/TASSP.1985.1164550. [2] C. Karadagur Ananda Reddy, N. Shankar, G. Shreedhar Bhat, R. Charan, and I. Panahi,“An Individualized Super-Gaussian Single Microphone Speech Enhancement for Hearing Aid Users With Smartphone as an Assistive Device,” IEEE Signal Process. Lett., vol. 24, no. 11, pp. 1601–1605, Nov. 2017, doi: 10.1109/LSP.2017.2750979. [3] P. J. Wolfe and S. J. Godsill,“Simple alternatives to the Ephraim and Malah suppression rule for speech enhancement,” in Proceedings of the 11th IEEE Signal Processing Workshop on Statistical Signal Processing (Cat. No.01TH8563), Singapore, 2001, pp. 496–499, doi: 10.1109/SSP.2001.955331. [4] T. Lotter and P. Vary,“Speech Enhancement by MAP Spectral Amplitude Estimation Using a Super-Gaussian Speech Model,” EURASIP J. Adv. Signal Process., vol. 2005, no. 7, p. 354850, Dec. 2005, doi: 10.1155/ASP.2005.1110. [5] S. Srinivasan, J. Samuelsson, and W. B. Kleijn, “Codebook-Based Bayesian Speech Enhancement for Nonstationary Environments,” IEEE Trans. Audio Speech Lang. Process., vol. 15, no. 2, pp. 441–452, Feb. 2007, doi: 10.1109/TASL.2006.881696. [6] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee,“A Regression Approach to Speech Enhancement Based on Deep Neural Networks,” IEEEACM Trans. Audio Speech Lang. Process., vol. 23, no. 1, pp. 7–19, Jan. 2015, doi: 10.1109/TASLP.2014.2364452. [7] Y. Luo and N. Mesgarani,“Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation,” IEEEACM Trans. Audio Speech Lang. Process., vol. 27, no. 8, pp. 1256–1266, Aug. 2019, doi: 10.1109/TASLP.2019.2915167. [8] A. Pandey and D. Wang,“TCNN: Temporal Convolutional Neural Network for Real-time Speech Enhancement in the Time Domain,” in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019, pp. 6875–6879, doi: 10.1109/ICASSP.2019.8683634. [9] D. Yin, C. Luo, Z. Xiong, and W. Zeng,“PHASEN: APhase-and-Harmonics-Aware Speech Enhancement Network,”ArXiv191104697 Cs Eess, Nov. 2019. [10] A. Ephrat et al.,“Looking to Listen at the Cocktail Party:A Speaker-Independent Audio-Visual Model for Speech Separation,” ACM Trans. Graph., vol. 37, no. 4, pp. 1–11, Jul. 2018, doi: 10.1145/3197517.3201357. [11] J. G. Beerends, M. Obermann, R. Ullmann, J. Pomy, and M. Keyhl, “Perceptual Objective Listening Quality Assessment (POLQA), The Third Generation ITU-T Standard for End-to-End Speech Quality Measurement Part I–Temporal Alignment,” J Audio Eng Soc, vol. 61, no. 6, p. 19, 2013. [12] A. Hines, J. Skoglund, A. C. Kokaram, and N. Harte, “ViSQOL: an objective speech quality model,” Eurasip J. Audio Speech Music Process., no. 1, p. 13, 2015, doi: 10.1186/s13636-015-0054-9. [13] C. K. A. Reddy, E. Beyrami, J. Pool, R. Cutler, S. Srinivasan, and J. Gehrke,“A Scalable Noisy Speech Dataset and Online Subjective Test Framework,” in Interspeech 2019, 2019, pp. 1816–1820, doi: 10.21437/Interspeech.2019-3087. [14] “ITU-T P.808: Subjective evaluation of speech quality with a crowdsourcing approach,” 2018. [15] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210, doi: 10.1109/ICASSP.2015.7178964. [16] J. F. Gemmeke et al.,“Audio Set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, 2017, pp. 776–780, doi: 10.1109/ICASSP.2017.7952261. [17] J. Thiemann, N. Ito, and E. Vincent, “The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings,” presented at the ICA 2013 Montreal, Montreal, Canada, 2013, pp. 035081–035081, doi: 10.1121/1.4799597. [18] G. Pirker, M. Wohlmayr, S. Petrik, and F. Pernkopf,“A Pitch Tracking Corpus with Evaluation on Multipitch Tracking Scenario,” p. 4. [19] “ITU-T Supplement 23 ITU-T coded-speech database Supplement 23 to ITU-T P-series Recommendations (Previously CCITT Recommendations),” 1998.

- 论文翻译:2018_Integrated acoustic echo and background noise suppression based on stacked deep neural networks
- 论文翻译:2019_Deep Learning for Joint Acoustic Echo and Noise Cancellation with Nonlinear Distortions
- 论文翻译:2020_Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression
- 扫描线算法的论文《The Intersections for a Set of 2D Segments, and Testing Simple Polygons》的部分翻译
- 论文翻译:2020_Joint NN-Supported Multichannel Reduction of Acoustic Echo, Reverberation and Noise
- 【综述论文】Salient Object Detection in the Deep Learning Era: An In-Depth Survey翻译整理
- Analyzing and Improving the Image Quality of StyleGAN论文解读笔记
- Mark 一下论文链接 AAAI 2020《An Iterative Polishing Framework based on Quality Aware Masked Language Model》
- Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions论文笔记
- 论文阅读(Lukas Neumann——【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recognition Framework)
- 翻译 | Keras : Deep Learning library for Tensorflow and Theano
- The Definitive Guide to symfony | Chapter 15 - Unit And Functional Testing | symfony | Web PHP Framework
- Introducing home screen widgets and the AppWidget framework (翻译)
- 【论文笔记】Show and Tell: Lesson learned from the 2015 MSCOCO Image Captioning Challenge
- 论文翻译:2020_CAD-AEC: CONTEXT-AWARE DEEP ACOUSTIC ECHO CANCELLATION
- 论文翻译:Training Deep Networks with Synthetic Data:Bridging the Reality Gap by Domain Randomization
- 【翻译+原创】DeepFace: Closing the Gap to Human-Level Performance in Face Verification 论文笔记
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
- 【论文精读】Deep Learning and the Information Bottleneck Principle
- 论文笔记:Show and Tell Lessons learned from the 2015 MSCOCO Image Captioning Challenge