论文翻译:2020_Acoustic Echo Cancellation Based on Recurrent Neural Network
论文地址:https://ieeexplore.ieee.org/abstract/document/9306224
#基于RNN的回声消除
###摘要
本文提出了一种基于深度学习的语音分离技术的回声消除方法。传统上,AEC使用线性自适应滤波器来识别麦克风和扬声器之间的声脉冲响应。然而,当传统方法遇到非线性条件时,处理的结果并不理想。我们的实践利用了深度学习技术的优势,这有利于非线性处理。在所采用的RNN系统中,与传统的语音分离方法不同,我们增加了单讲特征,并为每个元素分配特定的权重。实验结果表明,该方法提高了模拟音频的语音质量感知评价(PESQ),提高了录制音频的回声损耗增强(ERLE)。
**关键字:**回声消除,语音分离,循环神经网络
###1 引言
传统的声学回声消除方法是使用线性自适应滤波器来识别麦克风和扬声器之间的声脉冲响应。图1为我们回声消除系统的框图,其中$x(n),h(n), d(n), s(n), v(n), y(n), \hat(n)$分别为远端信号、回声路径、回声信号、近端信号、背景噪声、麦克风信号、重新合成信号。图2为AEC的内部结构图,它是一种使用线性自适应滤波器的AEC方法。预估的近端信号由预估的远端回声信号减去麦克风信号得到。
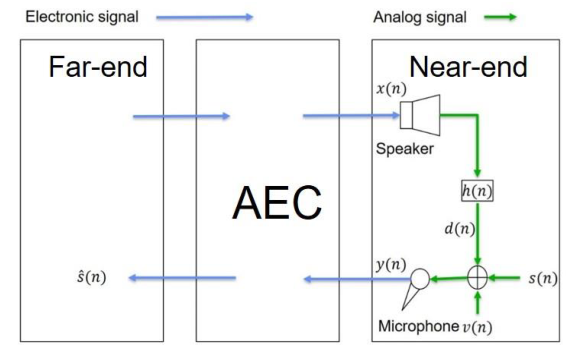
图1 回声消除系统框图
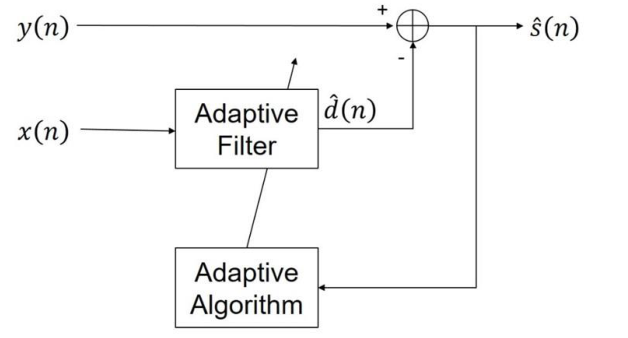
图2 AEC内部结构图
###2 相关背景
1990年, J.-S. Soo等人提出了一种基于归一化最小均方(NLMS)算法的多延迟块频域自适应滤波器(MDF)[1]。NLMS算法在时域内计算输入信号并逐帧更新权值,耗时较长。MDF算法在频域进行计算,对输入信号进行批量处理,并均匀地进行权值更新。MDF算法的实现可以在Speex[2]中找到,这是一种开源算法,我们在实验中进行了比较。2017年D. Yu等人提出了一种排列不变训练(PIT)语音分离方法[3]。他们的方法通过最小化原始语音和估计语音之间的估计误差来训练神经网络。2018年,Zhang, H等人提出了一种深度学习的回声消除方法[4],并利用混合信号和远端回声信号特征的语音分离技术进行回声消除。我们提出的方法同时引用了近端信号和远端回声信号的特征,并对不同特征的权重进行调整。实验结果表明,ERLE和PESQ都得到了改进。通过双向门控回归单元[5][6]对模型进行训练,建立神经网络。
提议的方法将在第三节中说明。第四节和第五节将分别规定评价标准和讨论实验。最后,第六部分对本文进行总结。
###3 提出方法
在本节中,我们将介绍我们提出的基于RNN[7]的方法。A节将介绍数据集的预处理,B节说明训练阶段;最后,C部分将描述测试阶段。图3为所提出方法的架构图。
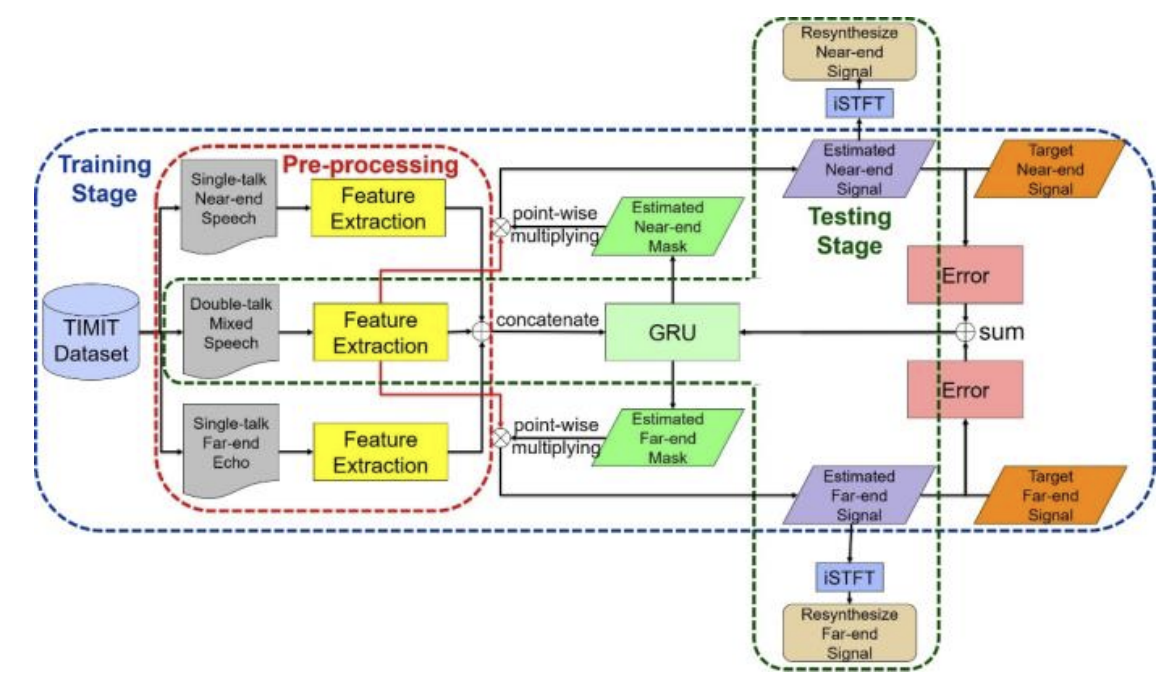
图3 所提出方法的架构图
####A 预处理
在这项工作中,我们采用256点短时傅里叶变换(STFT)和129个频率单元来提取语音数据的特征。采样率为16kHz,帧大小为16ms。STFT的流程图如图4所示。
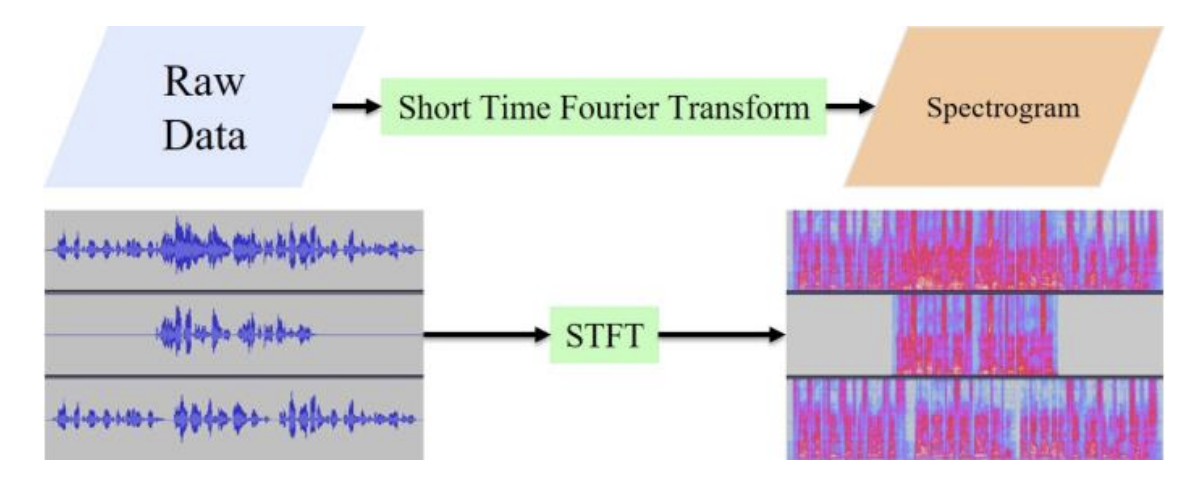
图4 短时傅里叶变换流程图
####B 训练阶段
在该方法中,我们采用了BGRU构造的RNN。与双向长短时记忆(BLSTM)网络[6][8]不同,该方法相对简单。通过添加单讲特征(近端信号和远端回声信号)并调整各元素的权重,实验结果表明了该算法的良好性能。我们使用理想比率掩码[9]作为语音分离目标。式(1)和(2)表示掩模的数学计算。
I R M_{1}(t, f)=\sqrt{\frac{X_{1}^{2}(t, f)}{Y^{2}(t, f)}} (1) \operatorname{IRM}_{2}(t, f)=\sqrt{\frac{X_{2}^{2}(t, f)}{Y^{2}(t, f)}} (2)其中,X_{1}, X_{2} , $Y$分别是目标近端信号、目标远端回声信号和麦克风信号。理想比率掩码是目标信号在混合信号中的比率,定义为我们的训练目标。理想的比值掩模值在0到1之间,所以我们使用ReLU作为激活函数,将其限制在这个范围内。BGRU的输入层和输出层都有129个神经元。有三个隐藏的层,每个层有496个神经元。学习率为0.0005,迭代次数为60。BGRU中使用的损失函数为均方误差(MSE),如式(3)所示。
J_{x}=\frac{1}{T \times F \times S} \sum_{t=1}^{T} \sum_{f=1}^{F} \sum_{S=1}^{S}\left\|\hat{X}_{S}(t, f)-X_{S}(t, f)\right\|^{2} (3)其中$T$是时间帧的个数,$F$是频率窗口的个数,$\widehat是估计的说话人的信号,$是目标说话人的信号,$S$是说话人的人数。 ####C 测试阶段
在测试阶段,将待测混合信号的特征输入BGRU,将特征与估计的掩码逐点相乘得到估计的信号。
###4 评价
为了减少训练阶段的时间消耗,我们使用GPU来执行程序进行加速。我们使用RTX 2080 GPU来运行我们的Python程序,其中我们使用tensorflow和librosa作为我们的神经网络和特征提取的工具。在本节中,我们将介绍A节中的性能指标和B节中的实验设置。
####A 性能指标
我们使用两个性能指标来评估实验的结果。在单话音场景中,我们使用ERLE来评估远端回声的衰减程度。数值越高,说明系统消除回声的能力越强。在双语场景下,我们使用PESQ[10]来评估估计信号与原始信号之间的相关性。当计算值较高时,说明相关性较高,因此可以保持一定的语音质量。ERLE数学计算可表示为(4),其中$y(n)为麦克风信号,\hat(n)$为复合成信号。
E R L E=10 \log _{10}\left\{\frac{\varepsilon\left[y^{2}(n)\right]}{\varepsilon\left[\hat{s}^{2}(n)\right]}\right\} (4)####B 实验设置
我们在实验中采用了TIMIT数据集[11]。TIMIT数据集有630个扬声器。每个演讲者讲10个句子。总共有6300个句子。每个句子的采样频率为16khz。首先,我们将这些句子组成近端信号和远端信号。我们将从随机的说话者中随机选择三句话,并将它们连接起来形成一个远端信号。我们将随机选取另一个说话人的句子,并在前后加上与远端信号相同长度的零,形成近端信号。在远端信号部分,训练阶段使用的扬声器数量为30个,测试阶段使用的扬声器数量为6个,其余的扬声器作为近端信号。我们在模拟和现场录音两种情况下生成混合语音。在仿真的情况下,我们使用[12]图像法产生房间脉冲响应,与远端信号卷积得到远端回声信号。模拟房间大小为(4,4,4)米,麦克风置于房间中央(2,2,2)米,扬声器随机放置。在仿真的情况下,我们使用高斯噪声产生的信噪比(SNR)在0到5 dB之间。在录音的情况下,我们在门窗紧闭的会议室进行现场录音。此外,我们还可以通过信号回声比(SER)来计算近端信号和远端回声信号之间的关系。我们在实验中分别选择了10 dB, 0 dB和-10 dB的SER。信噪比和SER分别表示为(5)和(6),
S N R=10 \log _{10}\left\{\frac{\varepsilon\left[s^{2}(n)\right]}{\varepsilon\left[v^{2}(n)\right]}\right\} (5) S E R=10 \log _{10}\left\{\frac{\varepsilon\left[s^{2}(n)\right]}{\varepsilon\left[d^{2}(n)\right]}\right\} (6)其中$s(n)$是近端信号,$v(n)$是背景噪声,$d(n)$是远端回波信号。在仿真的情况下,远端信号与房间脉冲响应卷积以得出远端回波信号。远端回波信号的数学计算可表示为(7):
d(n)=x(n) * h(n) (7)其中$d(n)$是远端回声信号,$x(n)$是远端信号,$h(n)$是房间脉冲响应。麦克风信号的数学计算可表示为(8):
y(n)=d(n)+s(n)+v(n) (8)其中$d(n)$是远端回声信号,$s(n)$是近端信号,$v(n)$是背景噪声。
###5 实验结果
将提出的方法与MDF算法和PIT语音分离方法进行比较。实验分别在高、中、低三种不同的情况下进行模拟,并记录数据进行比较。
表1和表2列出了高SER情况下ERLE和PESQ的结果。在模拟的情况下,BLSTM的ERLE是最高的,但在记录的情况下,具有近端信号特征的神经网络的训练模型得到的结果是所有方法中最高的。在仿真的情况下,加入近端信号特征并调整特征的权重进行训练,得到的PESQ是最高的。实验结果表明,该方法可以有条件地提高ERLE和PESQ。
表1 ERLE的高SER (10db)
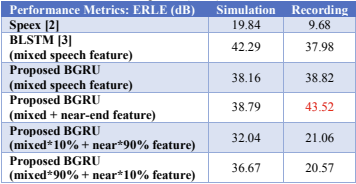
表2 PESQ的高SER值(10db)
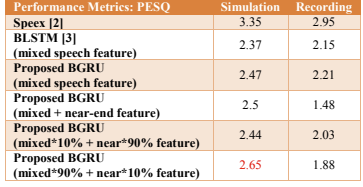
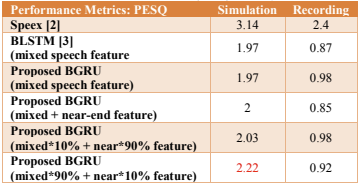
表3和表4列出了中等SER情况下ERLE和PESQ的结果。总体结果不如高SER情况下的高。同样的,在BLSTM中模拟的ERLE是最高的,而我们的方法在记录的情况下表现最好。在模拟的情况下,可以发现类似的结果在高SER情况下。
表3 ERLE的介质SER (0 dB)
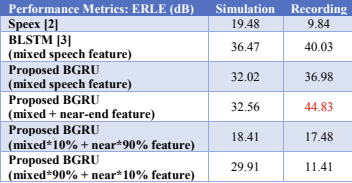
表4 PESQ的介质SER (10db)
 最后,从表5和表6中可以看出,即使在较低的SER情况下,我们的方法在一定的条件下也能提高性能。
最后,从表5和表6中可以看出,即使在较低的SER情况下,我们的方法在一定的条件下也能提高性能。
传统的语音分离方法只使用混合信号特征,而我们提出的方法增加了一个单语音特征并调整每个元素的权重。实验结果表明,在记录的情况下,添加单语特征后,ERLE达到了所有方法中最高的。在仿真的情况下,在加入单语特征和调整元素权重后,PESQ在深度学习方法中也达到最高。
表5 ERLE的低SER (- 10db)
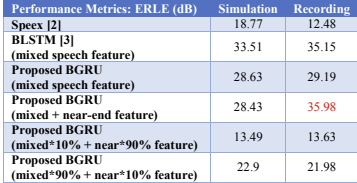
表6 PESQ的低SER (- 10db)
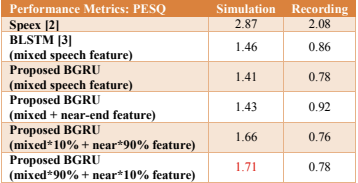
###6 结论
提出了一种基于双向门控循环单元(BGRU)的回声消除算法,该算法增加了近端特征。实验结果表明,通过添加单语特征和调整元素的权重可以提高算法的性能。在仿真的情况下,我们提出的方法比BLSTM[3]好0.2-0.3。在记录的情况下,所提出的方法比Speex[2]好20-30 dB。该方法在仿真情况下可以提供更好的PESQ,而在ERLE上的性能略有下降。在未来的训练阶段,我们会增加各种记录数据,针对不同环境增强系统模型。
###7 参考文献 [1] J.-S. Soo and K. Pang, "Multidelay block frequency domain adaptive filter," IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 38, no. 2, pp. 373–376, 1990. [2] J.-M. Valin, Speex: A Free Codec For Free Speech, Available: http://www.speex.org/ [3] M. Kolbak, D. Yu, Z.-H. Tan, and J. Jensen, "Multi-talker speech separation with utternance-level permutation invariant training of deep recurrent neural networks" IEEE/ACM Trans. Audio Speech Lang. Proc., vol. 25, pp. 1901-1913, 2017. [4] Zhang, Hao, and DeLiang Wang. "Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios,"Training 161.2 (2018): 322. [5] Chung, Junyoung, et al. "Empirical evaluation of gated recurrent neural networks on sequence modeling." arXiv preprint arXiv:1412.3555 (2014). [6] Schuster, Mike, and Kuldip K. Paliwal. "Bidirectional recurrent neural networks." IEEE Transactions on Signal Processing 45.11 (1997): 2673-2681. [7] A. Graves, A. Mohamed, and G. Hinton, "Speech recognitionwith deep recurrent neural networks," in ICASSP, 2013, pp.6645–6649 [8] S. Hochreiter and J. Schimidhuber, "Long short-term memory,"Neural Computation, vol. 9, pp. 1735–1780, 1997 [9] Y. Wang, A. Narayanan, and D. L. Wang, "On training targets for supervised speech separation," IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), vol. 22, no. 12, pp. 1849–1858, 2014. [10] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra,"Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs," in ICASSP, 2001, pp. 749–752. [11] L. F. Lamel, R. H. Kassel, and S. Seneff, "Speech database development: Design and analysis of the acoustic-phonetic corpus," in Speech Input/Output Assessment and Speech Databases, 1989. [12] J. B. Allen and D. A. Berkley, "Image method for efficiently simulating small-room acoustics," The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, 1979.

- 论文翻译:2020_CAD-AEC: CONTEXT-AWARE DEEP ACOUSTIC ECHO CANCELLATION
- 论文翻译:2020_ICASSP 2021 ACOUSTIC ECHO CANCELLATION CHALLENGE: DATASETS, TESTING FRAMEWORK, AND RESULTS
- 论文翻译:2020_A Robust and Cascaded Acoustic Echo Cancellation Based on Deep Learning
- 论文翻译:2020_The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Speech Quality and Testing Framework
- 【目标检测】论文阅读与翻译——Arbitrary-Oriented Object Detection with Circular Smooth Label(2020)
- 论文翻译:2020_Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression
- 一种镜像生成式机器翻译模型:MGNMT | ICLR 2020满分论文解读
- 论文翻译:2020_Joint NN-Supported Multichannel Reduction of Acoustic Echo, Reverberation and Noise
- Inception-V3论文翻译——中英文对照
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition论文翻译
- HMM经典介绍论文【Rabiner 1989】翻译(五)——HMM的三个基本问题
- CVPR 2017论文集锦(论文分类)—— 附录部分翻译
- 区块链毕业设计必读论文【2020-5】
- U-GAT-IT 论文翻译
- Mask-RCNN论文翻译
- 论文翻译:Neural conditional random felds
- 干货丨ICRA2020论文分享:一种基于层次强化学习的机械手鲁棒操作
- 【翻译+原创】Deep Learning Face Representation from Predicting 10,000 Classes 论文笔记
- 【综述论文】Salient Object Detection in the Deep Learning Era: An In-Depth Survey翻译整理
- [持续更新] 神经机器翻译论文汇总 Papers on Neural Machine Translation