ZooKeeper
[TOC]
ZooKeeper 介绍
ZooKeeper(简称 zk)是一个分布式的、开源的**(分布式)应用程序的协调服务**。
ZooKeeper 是 Apache Hadoop 项目下的一个子项目,是一个树形目录服务。
ZooKeeper 翻译过来就是“动物园管理员”,它是用来管 Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)的管理员。
ZooKeeper 提供的主要功能包括:
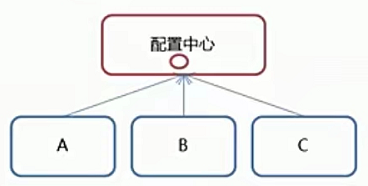
配置管理- 分布式锁
- 集群管理
ZooKeeper 下载安装
ZooKeeper 是用 Java 写的,它运行在 JVM 之上,因此需要安装 JDK7 或更高版本。
下载安装
1)下载
2)安装
# 打开 opt 目录 cd /opt # 创建 zooKeeper 目录 mkdir zooKeeper # 将 zookeeper 安装包移动到 /opt/zookeeper mv apache-zookeeper-3.5.6-bin.tar.gz /opt/zookeeper/ # 将 tar 包解压到 /opt/zookeeper 目录下 tar -zxvf apache-ZooKeeper-3.5.6-bin.tar.gz
配置
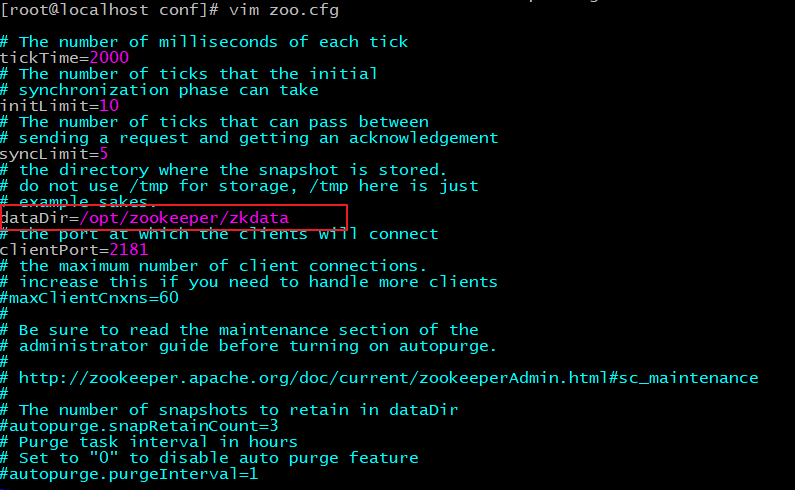
配置 zoo.cfg :
# 进入到 conf 目录 cd /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/conf/ # 拷贝并重命名 cp zoo_sample.cfg zoo.cfg cd /opt/zooKeeper/ # 创建ZooKeeper存储目录 mkdir zkdata # 修改zoo.cfg 配置项 vim /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/conf/zoo.cfg # 修改数据存储目录:dataDir=/opt/zookeeper/zkdata
启停
cd /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/bin/ # 启动 ./zkServer.sh start # 停止 ./zkServer.sh stop # 查看状态 ./zkServer.sh status
如下图所示:ZooKeeper 成功启动。

如下图所示:ZooKeeper 启动成功(standalone 表示 zk 没有搭建集群,现在是单节点)

ZooKeeper 常用命令
数据模型
ZooKeeper 是一个树形目录服务,其数据模型和 Unix 的文件系统目录树很类似,拥有一个层次化结构。
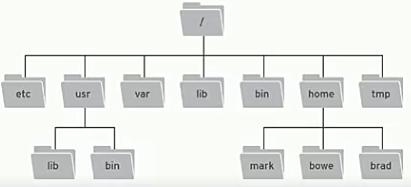
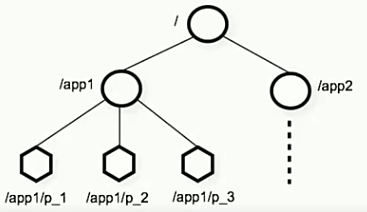
这里面的每一个节点都被称为“ZNode”,每个节点上都会保存自己的数据和节点信息。
节点可以拥有子节点,同时也允许少量(1 MB)数据存储在该节点之下。
节点可以分为四大类:
PERSISTENT(持久化节点,默认类型)- EPHEMERAL(临时节点,随着会话结束而删除):-e
- PERSISTENT_SEQUENTIAL(持久化顺序节点):-s
- EPHEMERAL_SEQUENTIAL(临时顺序节点):-es
服务端常用命令
# 启动 ZooKeeper 服务 ./zkServer.sh start # 查看 ZooKeeper 服务状态 ./zkServer.sh status # 停止 ZooKeeper 服务 ./zkServer.sh stop # 重启 ZooKeeper 服务 ./zkServer.sh restart
客户端常用命令
CRUD 命令:
# 连接 ZooKeeper 服务端 # 不写ip:port则默认连本地2181 ./zkCli.sh –server ip:port # 断开连接 quit # 查看命令帮助 help # 显示指定目录下节点 ls 目录 # 创建节点 create /节点path value # 获取节点值 get /节点path # 设置节点值 set /节点path value # 删除单个节点 delete /节点path # 删除带有子节点的节点 deleteall /节点path
创建临时有序节点:
# 创建临时节点 create -e /节点path value # 创建顺序节点 create -s /节点path value # 查询节点详细信息 ls –s /节点path
节点详细信息说明:
- czxid:节点被创建的事务 ID
- ctime:创建时间
- mzxid:最后一次被更新的事务 ID
- mtime:修改时间
- pzxid:子节点列表最后一次被更新的事务 ID
- cversion:子节点的版本号
- dataversion:数据版本号
- aclversion:权限版本号
- ephemeralOwner:用于临时节点,代表临时节点的事务 ID(如果为持久节点则为 0)
- dataLength:节点存储的数据的长度
- numChildren:当前节点的子节点个数
ZooKeeper Java API
Curator 介绍
- Curator 是 Apache ZooKeeper 的 Java 客户端库。
- 常见的 ZooKeeper Java API : 原生 Java API
- ZkClient
- Curator
常用 API
Curator 的 Maven 依赖:
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.0.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.0.0</version> </dependency>
建立连接
// 重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
// 连接方式一:newClient
/**
* @param connectString 连接信息字符串:zk server 地址和端口,如集群 "192.168.149.135:2181, 192.168.149.136:2181"
* @param sessionTimeoutMs 会话超时时间(单位ms)
* @param connectionTimeoutMs 连接超时时间(单位ms)
* @param retryPolicy 重试策略
*/
CuratorFramework client1 = CuratorFrameworkFactory.newClient(
"192.168.149.135:2181",
60 * 1000,
15 * 1000,
retryPolicy);
// 连接方式二:builder
CuratorFramework client2 = CuratorFrameworkFactory.builder().
connectString("192.168.200.130:2181").
sessionTimeoutMs(60 * 1000).
connectionTimeoutMs(15 * 1000).
retryPolicy(retryPolicy).
namespace("node1"). // 命名空间:之后的操作均以node1为根节点
build();
// 开启连接
client1.start();
client2.start();
// 关闭连接
client1.close();
client2.close();
创建节点
- 创建节点:create().forPath("节点名称")
- 创建节点及其数据:create().forPath("节点名称", 数据)
- 设置节点类型:create().withMode().forPath("节点名称", 数据)
- 创建多级节点:create().creatingParentsIfNeeded().forPath("多级节点名称", 数据)
// 1. 创建节点(无数据):默认将当前客户端的ip作为数据存储
String path1 = client.create().forPath("/app1");
System.out.println(path1); // /app1
// 2. 创建节点且带有数据
String path2 = client.create().forPath("/app2", "hehe".getBytes());
System.out.println(path2); // /app2
// 3. 设置节点的类型(默认类型:持久化)
String path3 = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app3"); // 临时节点
System.out.println(path3); // /app3
// 4. 创建多级节点
//creatingParentsIfNeeded():如果父节点不存在,则创建父节点
String path4 = client.create().creatingParentsIfNeeded().forPath("/app4/p1");
System.out.println(path4); // /app4/p1
查询节点
get
查询数据:getData().forPath()ls
查询子节点:getChildren().forPath()ls -s
查询节点状态信息:getData().storingStatIn(状态对象).forPath()
// 1. 查询节点数据:get
byte[] data = client.getData().forPath("/app1");
System.out.println(new String(data)); // 192.168.56.1
// 2. 查询子节点:ls
List<String> path = client.getChildren().forPath("/");
System.out.println(path); // [dubbo, zookeeper, app2, app1, app4]
// 3. 查询节点状态信息:ls -s
Stat status = new Stat();
System.out.println(status); // 0,0,0,0,0,0,0,0,0,0,0
client.getData().storingStatIn(status).forPath("/app1");
System.out.println(status); // 109,109,1641077872296,1641077872296,0,0,0,0,12,0,109
修改节点数据
- 直接修改数据:setData().forPath()
- 根据版本修改:setData().withVersion().forPath()
// 1. 直接修改节点数据
client.setData().forPath("/app1", "abc".getBytes());
// 2. 根据节点版本修改其数据
Stat status = new Stat();
byte[] path = client.getData().storingStatIn(status).forPath("/app1");
// version 需要事先查询,目的是为了让其他客户端或者线程不干扰自己的修改操作
int version = status.getVersion();
client.setData().withVersion(version).forPath("/app1", "efg".getBytes());
删除节点
- 删除单个节点:delete().forPath("/app1");
- 删除带有子节点的节点:delete().deletingChildrenIfNeeded().forPath("/app1");
- 确保删除成功(为了防止网络抖动,本质就是重试):client.delete().guaranteed().forPath("/app2");
- 回调:inBackground()
// 1. 删除单个节点
client.delete().forPath("/app1");
// 2. 删除带有子节点的节点
client.delete().deletingChildrenIfNeeded().forPath("/app2");
// 3. 必须成功的删除
client.delete().guaranteed().forPath("/app3");
// 4. 回调
client.delete().guaranteed().inBackground(
new BackgroundCallback() {
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("我被删除了~");
System.out.println(event);
}
}
).forPath("/app4");
Watch(事件监听)
介绍
ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去。该机制是 ZooKeeper 实现分布式协调服务的重要特性。
ZooKeeper 中引入了 Watcher 机制来实现了发布/订阅功能,能够让多个订阅者同时监听某一个对象。当一个对象自身状态变化时,会通知所有订阅者。
ZooKeeper 原生支持通过注册 Watcher 来进行事件监听,但是其使用并不是特别方便(需要开发人员自己反复注册 Watcher,比较繁琐)。
Curator 引入了 Cache 来实现对 ZooKeeper 服务端事件的监听。
ZooKeeper 提供了三种 Watcher:
NodeCache:仅监听某个节点本身(不包括其子节点)。- PathChildrenCache:监听某个节点的所有子节点(不包括父节点本身)。
- TreeCache:监听某个节点及其所有子节点(类似于 PathChildrenCache 和 NodeCache 的组合)。
NodeCache
NodeCache:仅监听某个节点自身(不包括子节点)。
// 1. 创建NodeCache对象
final NodeCache nodeCache = new NodeCache(client,"/app4");
// 2. 注册监听
nodeCache.getListenable().addListener(
new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("节点变化了~");
// 获取修改节点后的数据
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
}
);
// 3. 开启监听(设置为true,则在开启监听时加载缓冲数据)
nodeCache.start(true);
PathChildrenCache
PathChildrenCache:监听某个节点的所有子节点(不包括父节点本身)。
// 1.创建监听对象
PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/app4", true);
// 2. 绑定监听器
pathChildrenCache.getListenable().addListener(
new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("子节点变化了~");
System.out.println(event);
// 监听子节点的数据变更,并且拿到变更后的数据
// 1.获取类型
PathChildrenCacheEvent.Type type = event.getType();
// 2.判断类型是否是update
if (type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)) {
System.out.println("子节点数据修改了~");
byte[] data = event.getData().getData();
System.out.println(new String(data));
}
}
}
);
// 3. 开启监听器
pathChildrenCache.start();
TreeCache
TreeCache:监听某个节点自己和所有子节点们。
// 1. 创建监听器
TreeCache treeCache = new TreeCache(client, "/app2");
// 2. 注册监听
treeCache.getListenable().addListener(
new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
System.out.println("节点变化了");
System.out.println(event);
}
}
);
// 3. 开启
treeCache.start();
分布式锁
什么是分布式锁?
- 在我们进行单机应用开发的并发同步时,我们往往采用 synchronized 或者 lock 的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个 JVM 之下,没有任何问题。
- 但当我们的应用是分布式集群工作的情况下,即属于多 JVM 下的工作环境时,跨 JVM 之间已经无法通过多线程的锁解决同步问题。
- 那么就需要一种更加高级的锁机制,来处理
跨机器的进程之间的数据同步
问题——这就是分布式锁。
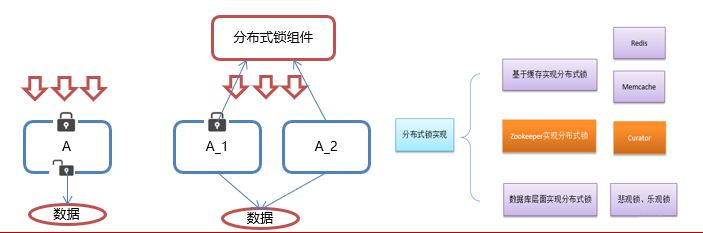
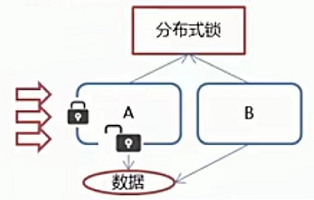
ZooKeeper 分布式锁原理
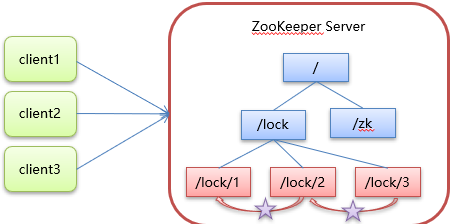
核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
客户端获取锁时,在 lock(自定义)节点下创建临时顺序节点。
然后获取 lock 下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
如果发现自己创建的节点并非 lock 所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
如果发现比自己小的那个节点被删除,则客户端的 Watcher 会收到相应通知,此时再次判断自己创建的节点是否是 lock 子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
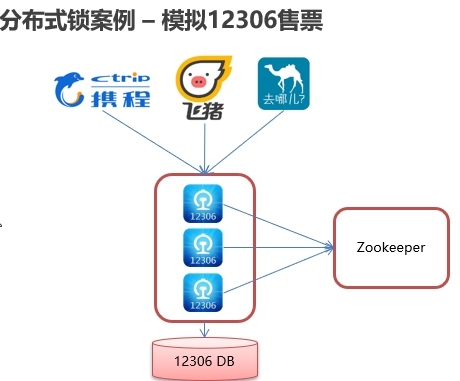
分布式锁案例:模拟售票
在 Curator 中有五种锁方案:
InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
InterProcessMutex:分布式可重入排它锁
InterProcessReadWriteLock:分布式读写锁
InterProcessMultiLock:将多个锁作为单个实体管理的容器
InterProcessSemaphoreV2:共享信号量
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import java.util.concurrent.TimeUnit;
// 测试分布式锁
public class ZkDemoTest {
public static void main(String[] args) {
TicketServer ticketServer = new TicketServer();
Thread t1 = new Thread(ticketServer, "携程");
Thread t2 = new Thread(ticketServer, "飞猪");
t1.run();
t2.run();
}
}
// 分布式锁实现
class TicketServer implements Runnable {
// 票库存
private int tickets = 10;
// zk的锁对象
private InterProcessMutex lock ;
// 在构造方法中连接zk
public TicketServer() {
// 重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.3.244:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.build();
// 开启连接
client.start();
lock = new InterProcessMutex(client, "/lock");
}
// 售票
@Override
public void run() {
while (tickets>0) {
// 获取锁
try {
// 获取锁的频率:每3秒获取一次
// 当3秒获取不到时会有报错信息,但会继续重试
lock.acquire(3, TimeUnit.SECONDS);
if(tickets > 0) {
System.out.println(Thread.currentThread()+": "+tickets);
Thread.sleep(100);
tickets--;
}
} catch (Exception e) {
e.printStackTrace();
}finally {
// 释放锁
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
ZooKeeper 集群
集群介绍
Leader 选举机制:
Serverid(服务器 ID):比如有三台服务器,编号分别是 1、2、3,那么编号越大,在选择算法中的权重越大。
Zxid(数据 ID):服务器中存放的最大数据 ID。值越大说明数据越新,那么在选举算法中数据越新,权重越大。
在 Leader 选举的过程中,如果某台 ZooKeeper 获得了超过半数的选票,那么此 ZooKeeper 就可以成为 Leader 了。
集群搭建
1)搭建要求
真实的集群是需要部署在不同的服务器上的,这里示例搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分,即搭建一个 3 个节点的 ZooKeeper 集群(伪集群)。
2)准备工作
- 安装 JDK
- ZooKeeper 压缩包上传到服务器
- 将ZooKeeper 解压,建立 /usr/local/zookeeper-cluster 目录,将解压后的ZooKeeper 复制到以下三个目录:
mkdir /usr/local/zookeeper-cluster cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-1 cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-2 cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-3
- 创建 data 目录 ,并且将 conf 下 zoo_sample.cfg 文件改名为 zoo.cfg :
mkdir /usr/local/zookeeper-cluster/zookeeper-1/data mkdir /usr/local/zookeeper-cluster/zookeeper-2/data mkdir /usr/local/zookeeper-cluster/zookeeper-3/data mv /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg mv /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg mv /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
- 配置每一个 Zookeeper 的 dataDir,且 clientPort 分别为 2181、2182、2183 :
vi /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg clientPort=2181 dataDir=/usr/local/zookeeper-cluster/zookeeper-1/data vi /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg clientPort=2182 dataDir=/usr/local/zookeeper-cluster/zookeeper-2/data vi /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg clientPort=2183 dataDir=/usr/local/zookeeper-cluster/zookeeper-3/data
3)配置集群
- 在每个 ZooKeeper 的 data 目录下创建一个 myid 文件,内容分别是 1、2、3 。这个文件就是记录每个服务器的 ID 。
echo 1 >/usr/local/zookeeper-cluster/zookeeper-1/data/myid echo 2 >/usr/local/zookeeper-cluster/zookeeper-2/data/myid echo 3 >/usr/local/zookeeper-cluster/zookeeper-3/data/myid
- 在每一个 ZooKeeper 的 zoo.cfg 配置客户端访问端口(clientPort)和集群服务器 IP 列表:
vi /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg vi /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg vi /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg # 集群服务器 IP 列表如下 server.1=192.168.149.135:2881:3881 server.2=192.168.149.135:2882:3882 server.3=192.168.149.135:2883:3883 # 说明:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
4)启动集群
启动集群就是分别启动每个实例。
# 按序启动 /usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start /usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
启动后我们查询一下每个实例的运行状态:
# Mode 为 follower 表示是跟随者(从) /usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status # Mode 为 leader 表示是领导者(主),因为超过半数 /usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status # 跟随者(从) /usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
集群异常
- 3 个节点的集群,当其中 1 个从服务器挂掉时,集群正常。
- 3 个节点的集群,当 2 个从服务器都挂掉时,主服务器也无法运行。因为可运行的机器没有超过集群总数量的半数。
- 当集群中的主服务器挂了,集群中的其他服务器会自动进行选举状态,然后产生新得 leader 。
- 当领导者产生后,再次有新服务器加入集群,不会影响到现任领导者。
核心理论:ZK 集群角色
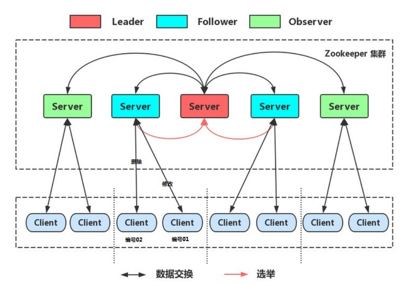
在 ZooKeeper 集群中有三种角色:
Leader(领导者)
:-
处理事务(增删改)请求。
- 集群内部各服务器的调度者。
Follower(跟随者)
:-
处理客户端非事务(查询)请求,转发事务请求给 Leader 服务器。
- 参与 Leader 选举投票。
Observer(观察者)
:-
处理客户端非事务请求,转发事务请求给 Leader 服务器。

- 搭建 Zookeeper-3.4.10 集群
- Windows环境部署ZooKeeper
- 我的大数据之路(二):从zookeeper说起
- Zookeeper3.4.10 + ActiveMQ-5.15.0 集群搭建
- 基于zookeeper分布式锁的解决方案
- Zookeeper学习(二):Zookeeper中的基本概念
- centos下安装zookeeper
- 安装 Zookeeper 集群
- Zookeeper安装部署
- zookeeper 认识与Windows下集群布置
- 【转】分布式锁实现(二):Zookeeper
- Zookeeper实现集群和负载均衡---(5)Zabbix集成Zookeeper示例
- zookeeper的php扩展安装及使用
- 对Zookeeper的简单理解
- ZooKeeper简介
- Zookeeper配置项的含义
- 集群-ubuntu-16.04.3-server+zookeeper
- ZooKeeper 基本操作
- 部署与管理ZooKeeper(转)
- ssm+dubb+zookeeper:使用ssm+dubb搭建分布式项目时出现的问题(从数据库中读取到的数据显示到浏览器中出现500)