论文翻译:2020_Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression
论文地址:https://arxiv.fenshishang.com/abs/2005.07551
#用于实时噪声抑制的双信号变换LSTM网络
###摘要
本文介绍了一种用于实时语音增强的双信号变换LSTM网络(DTLN)作为深度噪声抑制挑战(DNS挑战)的一部分。该方法在具有少于一百万个参数的堆叠网络方法中结合了短时傅里叶变换(STFT)和学习的分析和综合性。该模型受到挑战组织者提供的500小时嘈杂的语音训练 。网络能够实时处理(一个帧,一个帧,一个帧)并达到竞争结果。组合这两种类型的信号变换使得DTLN能够强大地从幅度谱提取信息并从学到的特征中包含相位信息。该方法显示了最先进的性能,并且在平均意见分数(MOS)方面,胜过DNS挑战基线0.24分。
**关键字:**噪声抑制,深度学习,实时,语音增强,深度学习,音频
代码:https://github.com/breizhn/DTLN
###1 引言
噪声抑制的任务是语音增强领域的重要学科; 例如,在家庭方案中特别重要,可以提高通信质量的鲁棒和有效的降噪,从而降低视频会议的认知努力。随着深度神经网络的发展,提出了基于深层模型的音频处理方法的几种新方法[1,2,3,4]。然而,这些通常开发用于离线处理,这不需要实时能力或考虑处理链中的因果关系。这些模型处理完整的序列并利用信号的过去和未来信息来抑制不期望的信号部件。经典信号处理算法[5,6]通常在样本或帧级上工作,以提供低输入输出延迟。在使用神经网络设计基于帧的算法时,循环神经网络(RNN)是一个常见的选择。RNN在语音增强 [7,8]和语音分离[9,10,11] 领域产生了令人信服的结果。长短期记忆网络(LSTM)[12]代表分离技术的最新水平[13]。通过使用双向LSTM,性能最好的网络通常以非因果方式构建,其中时间序列是因果处理的,也是反向处理的。双向无线网络总是需要一个完整的序列作为输入,因此主要不适合实时帧处理。
深度噪声抑制挑战(DNS-Challenge)[14]的基线系统称为NSNet [15],也基于RNN层,通过计算每个输入帧一个输出帧来提供实时能力。基于噪声时间信号的短时傅立叶变换(STFT)的对数功率谱,该模型预测应用于噪声STFT的增益或掩模。通过使用噪声混合物的估计幅度和相位来重构预测的语音信号。这种方法产生了一个有竞争力的基线系统,但它不包含任何相位信息,这可能有助于提高语音质量。不同的方法处理相位估计,例如估计STFT的实部和虚部的掩模,而不是幅度[16]或计算迭代相位重建[17]。像[11,18,19]这样的研究表明,在学习分析和综合的基础上,而不是将幅度和相位信息解耦,说话人分离任务的结果是有希望的。通过将时域帧与学习的基函数相乘来计算表示。这种方法也在[20]中用于分离语音和噪声。
当前研究的动机是通过使用堆叠双信号变换LSTM网络(DTLN)将分析和综合方法合并在一个模型中。堆叠或级联网络已经用于深度聚类说话人分离方法[9],其中在分离网络之后添加了额外的增强网络。在相关研究中,级联模型用于去噪和去混响[19]。这里提出的模型级联了两个分离核,第一个以STFT信号变换为特征,而第二个使用类似于[18]的学习信号表示。选择这个阶数是为了用第一个核心创建鲁棒的幅度估计,并使第二个核心能够用相位信息进一步增强信号。这种组合首次在降噪的背景下进行了探索,由于经典和学习的特征变换的互补性,可以提供有益的效果,同时保持相对较小的计算足迹。本文中的堆叠网络比大多数以前提出的LSTM网络小得多,并且在计算复杂性方面确保了实时能力。
###2 方法
####2.1 信号转换
在说话人分离中,通常选择时频掩蔽方法来分离说话人信号。噪声抑制是一个相关的源分离问题,但不同之处在于它只返回语音信号,而丢弃噪声。在时频域中,分离问题可以表述如下:麦克风信号y由下式描述:
y=x_{s}+x_{n} (1)
其中$x_$和$x_$分别表示时间信号的语音和噪声分量。
在噪声抑制任务中,期望的信号是语音信号。当信号$y$在复时频表示(TF)中用STFT变换时,估计语音信号$\hat_$的TF表示可以预测如下:
\hat{X}_{s}(t, f)=M(t, f) \cdot|Y(t, f)| \cdot e^{j \phi y} (2)其中$|Y|$是$y$的STFT幅度。$M$是应用于$Y$的掩码(掩码值范围从0到1),$e^{j \phi y}是噪声信号的相位。现在,\hat可以用STFT逆变换回\hat$。在这个公式中,噪声信号的相位被用来预测干净的语音信号。在这个公式中,噪声信号的相位用于预测干净的语音信号。
DTLN的第二次信号变换最早是由Luo及其同事提出的[11]。该方法的公式如下:将混合图像分割成长度为L、帧索引为k的重叠帧$y_$,帧乘以U,得到$N \times L$个学习基函数:
w_{k}=y_{k} U (3)为了创建帧$y_$尺寸为$N \times 1$的特征表示$w_$。为了从$w_$中恢复语音表示$d_$,可以由下式估计掩码$m_$:
\hat{d}_{k}=m_{k} \cdot w_{k} (4)其中$\hat$是估计语音信号在索引$k$处的特征表示,$\hat$能够转换为时域:
\hat{x}_{k}=\hat{d}_{k} V (5)其中V包含N个学习的长度为l的基函数。$\hat{x_}$是索引$k$处的估计帧。通过使用重叠相加过程来重构估计的时间信号$\hat{x_}$。
####2.2 网络体系结构
本文介绍的堆叠式双信号转换LSTM网络架构具有两个分离内核,分别包含两个LSTM层、一个全连接层和一个sigmoid激活层,以创建一个掩码输出。第一个分离核心使用STFT分析和合成基础。由FC层和sigmoid激活预测的掩码乘以混合的幅度,并使用输入混合的相位转换回时域,但不重构波形。来自第一个网络的帧由1D-Conv层处理,以创建特征表示。特征表示在被馈送到第二分离核心之前由归一化层处理。第二个核心的预测掩模与特征表示的非标准化版本相乘。该结果被用作1D-Conv层的输入,用于将估计的表示转换回时域。在最后一步中,用重叠相加过程重构信号。该架构如图1所示。
考虑到模型的实时性,使用了即时层归一化(iLN)。即时层标准化类似于标准层标准化[21],并在[22]中作为通道层标准化引入。所有帧都是单独归一化的,不随时间累积统计数据,并使用相同的可学习参数进行缩放。在目前的工作中,这种归一化方案被称为瞬时层归一化,以区别于累积层归一化[18]。
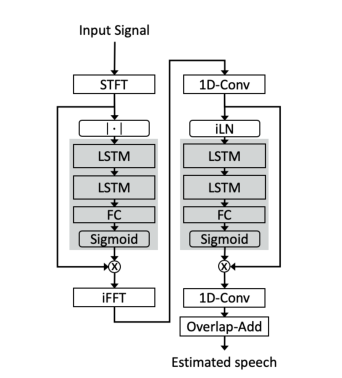
图1 提议的网络架构示意图 左边的处理链显示了使用STFT信号变换的第一个分离核心,
右边的构建块表示具有基于1D-Conv层的学习特征变换的第二个核心
####2.3 数据集
训练数据集是根据DNS系统挑战提供的音频数据创建的。语音数据是Librispeech语料库的一部分[23],而噪声信号来自Audioset语料库[24],Freesound和DEMAND语料库[25]。使用提供的脚本创建了500 小时的数据。默认信噪比范围(0至40分贝)更改为-5至25分贝,以包括负信噪比并限制总范围。为了覆盖更细粒度的信噪比分布,信噪比级别的数量从5增加到30。所有其他参数保持不变。500小时的数据集分为训练数据(400小时)和交叉验证数据(100小时),这对应于80:20 %的常见分割。所有训练数据在16kHz采样。
挑战组织者还提供了一个测试集,包含四个不同的类别,每个类别包含300个样本。类别有无混响合成剪辑,有混响合成剪辑,微软内部收集的真实录音,Audioset的真实录音。合成数据取自格拉茨大学的纯净语音数据集[26]。合成数据的信噪比随机分布在0到25分贝之间。混响数据的脉冲响应是在微软的多个房间中测量的,混响时间(RT_{60})在300到1300毫秒之间。此外,组织者创建了一个盲测试集,并在ITU P-808[27]设置中进行了评估。[14]中提供了训练和测试集的全部细节。
为了在嘈杂的混响环境中正确评估所有客观测量的性能,使用了在16kHz采样频率下的混响单扬声器和噪声测试集。我们转向这个数据集,因为一些客观测量需要适当延迟但纯净的参考信号来进行正确计算。由于DNS-Challenge测试集中没有提供这些信号,所以我们使用了WHAMR数据集,该数据集具有纯净的无混响语音文件,考虑了脉冲响应的延迟。使用的WHAMR测试装置由3000种混合语音组成。语音文件取自说话人分离中常用的WSJ0-mix语料库[28]。语音文件与房间脉冲响应卷积,$RT_{60}$范围为100至1000毫秒,用热声学模拟[29]。噪音由真实生活中的情况记录组成,如咖啡店、餐馆、酒吧、办公楼和公园。信噪比相对于语音从-3分贝到6分贝。
####2.4 模型配置和训练设置
本文中的数字地面线1在其四个LSTM层中各有128个单元。帧大小为32毫秒,移位为8毫秒。快速傅立叶变换大小为512,等于帧长度。用于创建所学要素制图表达的1D-Conv图层有256个过滤器。在培训期间,25%的辍学是适用于LSTM层之间。Adam优化器的学习速率为1e-3和,梯度范数裁剪为3。如果验证集的损失连续三个时期没有改善,学习率将减半。如果验证集的损失在十个时期内没有减少,则应用提前停止。该模型在32个样本的批量上训练,每个样本的长度为15s。英伟达RTX 2080 TI一个训练周期的平均时间约为21分钟。
本文中的DTLN在它的四个LSTM层中各有128个单元。帧大小为32毫秒,帧移为8毫秒。快速傅立叶变换大小为512,等于帧长度。用于创建学习特征表达的1D-Conv图层有256个过滤器。在训练期间,25%的dropout是适用于LSTM层之间。Adam优化器的学习速率为$1 \mathrm-3$,梯度范数裁剪为3。如果验证集的损失连续三个epoch没有改善,学习率将减半。如果验证集的损失在十个epoch内没有减少,则应用提前停止。该模型在32个样本的批量上训练,每个样本的长度为15s。英伟达RTX 2080 TI一个训练周期的平均时间约为21分钟。
作为训练目标,使用了对尺度敏感的负信噪比[20]。与尺度不变信噪比[11]相比,它应该避免输入混合和预测的纯净语音之间可能的电平偏移,这在实时处理系统中是理想的。此外,由于它在时域中操作,因此可以隐含地考虑相位信息。相反,作为训练目标的语音信号的估计和纯净幅度STFT之间的均方误差不能在优化过程中使用任何相位信息。
####2.5 基线
第一条基线是挑战赛组织者提供的噪音抑制网络(NSNet)。神经网络是用基于均方误差的频域语音失真加权损失进行优化的,并在一个相当小的84小时语音和噪声混合语料库上进行训练。它由三个具有256个门控循环单元的循环层(GRU)[30]和一个具有用于掩码预测的sigmoid激活的全连接层组成。帧大小为20毫秒,帧偏移为10毫秒。GRUs类似于LSTMs,但没有随时间推移的单元状态。
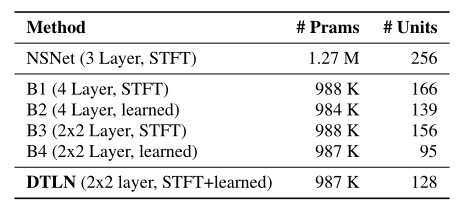
此外,我们的DTLN方法与四个模型进行了比较,四个模型具有与建议模型相同的训练设置:这些模型被探索以量化仅在两种不同拓扑中使用一个特征表示的效果(堆叠对密集连接的LSTMs):第一个和第二个模型由具有sigmoid激活的全连接层组成,以预测掩模。第一个(B1)使用STFT分析和综合基础,而B2使用大小为256的学习基础。第三个模型(B3)和第四个模型(B4)是类似于所提出的方法的堆叠模型。B3的两个分离核心都使用STFT基地。对于两个分离核,B4具有大小为256的学习特征库。选择LSTM层的大小是为了在参数数量方面获得与DTLN方法相似的大小。表1再次显示了这些配置。
表1 提议的DTLN方法与基线系统的每层参数和RNN单位数
####2.6 客观和主观评价
为了比较DTLN模型方法和基线,我们使用了三个客观的测量,即语音质量感知评估(PESQ)[31],定标不变信号失真比(SI-SDR) [32]和短时客观清晰度测量(STOI) [33]。
主观评估是在由微软实施和组织的Amazon mechanical Turk (AMT)上使用ITU-T P .808设置进行的。总共有两次评估运行,一次是在DNS-Challenge 的已知测试数据集上,另一次是在后面提供的盲测试集上。在第一次和第二次运行中,每个文件分别由五个或十个评委评分。
###3 结果
客观评价结果如表2所示,主观评价如表3所示。结果描述如下:
表2 非混响测试集、DNS挑战的混响测试集和WHAMR语料库的 混响单混音测试集的PESQ [MOS]、SI-SDR [dB]和STOI [%]方面的结果。
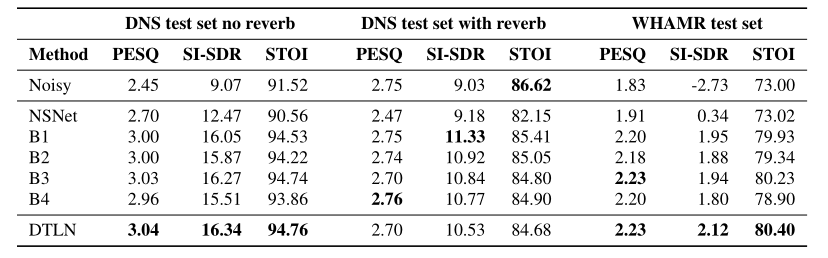
表3 DNS挑战的已知和盲测试集的主观评分。 已知测试集和盲测试集的总体95%置信区间分别为0.04和0.02。

####无回响DNS挑战测试集的客观结果:
在无混响条件下,所有模型都比噪声条件下有所改善。NSNet的表现优于DTLN和所有其他基线。所有经过500小时数据训练的模型都产生了相似的结果。DTLN取得了最佳效果。用B3和DTLN获得的高值显示了叠加模型的强度。尽管B4也是一个堆叠模型,但它的性能要差得多,这将在第4节中讨论。
####回响DNS挑战测试集的客观结果:
在这种情况下,结果不像在非混响条件下那样清晰。就PESQ而言,只有B4比噪声条件略有改善。对于软件无线电,所有型号都有所改进,而STOI预测原始噪声条件下的质量最高。侵入式或双端测量的一个问题是它们需要一个参考信号,在这种情况下是混响纯净语音。利用该参考信号,任何语音增强模型的潜在去混响效果将导致客观测量的减少,这可能是这些结果的重要因素。
####WHAMR 测试集的客观结果:
所有的方法都显示出对噪声条件的改善,最好的分数是通过DTLN方法获得的。B3也达到了类似的表现水平。基线显示所有客观指标都略有改善。值得一提的是,该语料库中使用的混合模型在0附近具有较小的信噪比范围,因此对模型来说是一个更具挑战性的条件。
####DNS 挑战测试集的主观结果:
已知无混响测试集的主观结果与客观结果一致。对于混响测试集,主观评估显示,相对于噪声条件和基线,DTLN有明显的优势。这种影响并没有被客观的标准所反映,除了SI-SDR,它显示出了对基线和噪声条件的一些改善。在混响条件下,由PESQ和STOI预测的NSNet质量的下降也在主观数据中观察到。无论是在已知条件下还是在盲条件下,都可以获得与真实记录一致的结果。
####执行时间的结果:
在DNS挑战环境中,测量了四核I5 6600K CPU上一个32毫秒帧的执行时间。通过处理一个完整的序列或使用逐帧处理来执行测量。顺序处理和帧处理的执行时间分别为0.23毫秒和2.08毫秒。序列和帧处理之间的巨大差异可以用在Keras中调用预测模型导致的开销来解释。将模型转换为Tensorflow的SavedModel格式将逐帧处理的执行时间减少到0.65毫秒,这是一个很大的改进。然而,序列处理时间几乎低了三倍,显示了在CPU上的潜在性能。
###4 讨论
在下文中,我们首先讨论基线系统之间的差异,这也对DTLN系统的组件有影响。非混响、混响和WHAMR测试的结果显示,B1和B3系统(使用STFT特征)的结果优于B2和B4系统(使用已学习的特征表示)。短时傅立叶变换性能更好的一个潜在原因是跨网络的参数数量固定,并且(由于STFT是固定的和基于规则的)B1和B3与学习特征方法相比,利用了可用于LSTM层的更多参数。
其次,我们假设STFT特征为噪声输出提供了更高的鲁棒性,因为相位信息在高噪声条件下是无用的。反之亦然,使用学习特征的网络必须为幅度和相位信息隐式确定掩码。造成这种差异的另一个可能的原因是,在这项工作中,所学习的特征表示所执行的压缩。学习的特征表示将512个音频样本映射到大小为256的特征表示。具有更大尺寸的特征表示将花费更多的参数,并且经验上发现特征表示的减少对所提出的模型的语音质量没有很大影响。
结果还显示,通过使用比纯STFT系统更少的LSTM单元,使用STFT和学习特征变换的堆叠网络略微改善了整体基线系统。LSTM单元的计算比全连接或1D-Conv层更复杂,也就是说,对于这种网络类型,减少单元是特别理想的。然而,DTLN和相关系统(B1-B4)在客观测量方面相对较小的差异也表明,部分性能是由大量训练数据和训练设置产生的。
###5 总结
介绍了一种基于大规模数据集上训练的实时语音增强叠加双信号变换LSTM网络的噪声抑制方法。我们能够展示在堆叠网络方法中使用两种类型的分析和合成基础的优势。DTLN模型在嘈杂的混响环境中工作稳定。尽管我们将基本的训练设置与简单的体系结构相结合,但我们观察到相对于噪声条件,在所有主观评估中,MOS的绝对改善为0.22。
###6 参考文献 [1] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “An experimental study on speech enhancement based on deep neural networks,” IEEE Signal processing letters, vol. 21, no. 1, pp. 65–68, 2013. [2] K. Han, Y . Wang, and D. Wang, “Learning spectral mapping for speech dereverberation,” in 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE,2014, pp. 4628–4632. [3] S. Pascual, A. Bonafonte, and J. Serra, “Segan: Speech enhancement generative adversarial network,” arXiv preprint arXiv:1703.09452, 2017. [4] S. R. Park and J. Lee, “A fully convolutional neural network for speech enhancement,” arXiv preprint arXiv:1609.07132, 2016. [5] Y . Ephraim and D. Malah, “Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator,” IEEE Transactions on acoustics, speech, and signal processing, vol. 32, no. 6, pp. 1109–1121, 1984. [6] L. Griffiths and C. Jim,“An alternative approach to linearly constrained adaptive beamforming,” IEEE Transactions on antennas and propagation, vol. 30, no. 1, pp. 27–34, 1982. [7] C. V alentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi,“Investigating rnn-based speech enhancement methods for noise-robust text-to-speech.” in SSW, 2016, pp. 146–152. [8] J.-M. V alin, “A hybrid dsp/deep learning approach to real-time full-band speech enhancement,” in 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP). IEEE,2018, pp. 1–5. [9] Y . Isik, J. L. Roux, Z. Chen, S. Watanabe, and J. R. Hershey,“Single-channel multi-speaker separation using deep clustering,”arXiv preprint arXiv:1607.02173, 2016. [10] M. Kolbæk, D. Y u, Z.-H. Tan, and J. Jensen, “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 10, pp. 1901–1913, 2017. [11] Y . Luo and N. Mesgarani, “Tasnet: time-domain audio separation network for real-time, single-channel speech separation,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 696–700. [12] S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997. [13] Y . Luo, Z. Chen, and T. Y oshioka, “Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation,” arXiv preprint arXiv:1910.06379, 2019. [14] C. K. A. Reddy, E. Beyrami, H. Dubey, V . Gopal, R. Cheng,R. Cutler, S. Matusevych, R. Aichner, A. Aazami, S. Braun,P . Rana, S. Srinivasan, and J. Gehrke, “The interspeech 2020 deep noise suppression challenge: Datasets, subjective speech quality and testing framework,” 2020. [15] Y . Xia, S. Braun, C. K. A. Reddy, H. Dubey, R. Cutler, and I. Tashev, “Weighted speech distortion losses for neural-network based real-time speech enhancement,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 871–875. [16] D. S. Williamson, Y . Wang, and D. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM transactions on audio, speech, and language processing, vol. 24, no. 3, pp. 483–492, 2015. [17] Z.-Q. Wang, J. L. Roux, D. Wang, and J. R. Hershey, “End-to-end speech separation with unfolded iterative phase reconstruction,”arXiv preprint arXiv:1804.10204, 2018. [18] Y . Luo and N. Mesgarani, “Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation,” IEEE/ACM transactions on audio, speech, and language processing, vol. 27,no. 8, pp. 1256–1266, 2019. [19] M. Maciejewski, G. Wichern, E. McQuinn, and J. Le Roux,“Whamr!: Noisy and reverberant single-channel speech separation,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020,pp. 696–700. [20] I. Kavalerov, S. Wisdom, H. Erdogan, B. Patton, K. Wilson,J. Le Roux, and J. R. Hershey, “Universal sound separation,” in 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2019, pp. 175–179. [21] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016. [22] Y . Luo and N. Mesgarani, “Conv-tasnet: Surpassing ideal time-frequency magnitude masking for speech separation,” arXiv preprint arXiv:1809.07454, 2018. [23] V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,”in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5206–5210. [24] J. F. Gemmeke, D. P . Ellis, D. Freedman, A. Jansen, W. Lawrence,R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 776–780. [25] J. Thiemann, N. Ito, and E. Vincent, “The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings,” The Journal of the Acoustical Society of America, vol. 133, no. 5, pp. 3591–3591, 2013. [26] G. Pirker, M. Wohlmayr, S. Petrik, and F. Pernkopf, “A pitch tracking corpus with evaluation on multipitch tracking scenario,”in Twelfth Annual Conference of the International Speech Communication Association, 2011. [27] “Itu-t p. 808: Subjective evaluation of speech quality with a crowdsourcing approach,” 2018. [28] J. R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” in IEEE International Conference on Acoustics,Speech, and Signal Processing (ICASSP), Mar. 2016, pp.31–35. [Online]. Available: https://www.merl.com/publications/TR2016-003 [29] R. Scheibler, E. Bezzam, and I. Dokmani´c, “Pyroomacoustics: A python package for audio room simulation and array processing algorithms,” in 2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 351–355. [30] J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,”arXiv preprint arXiv:1412.3555, 2014. [31] “Itu-t p. 862: Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs.” 2001. [32] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “Sdrhalf-baked or well done?” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626–630. [33] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in 2010 IEEE international conference on acoustics, speech and signal processing. IEEE, 2010, pp. 4214–4217.

- 语义分割经典论文:BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation (ECCV2018)
- DANet:Dual Attention Network for Scene Segmentation 论文翻译(学习)2019-8-30
- 论文阅读-《BlitzNet: A Real-Time Deep Network for Scene Understanding》
- 精读论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Network(附翻译)
- 【论文翻译】GCNv2: Efficient Correspondence Prediction for Real-Time SLAM
- Multi-style Generative Network for Real-time Transfer论文理解
- 【那些年我们一起看过的论文】之《ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation》
- 实时语义分割BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation论文解读
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution and Super-Resolution 论文笔记
- 【论文读后感】:Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- 多尺度R-CNN论文笔记(4): PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- 论文总结-Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- 论文笔记:Siamese Cascaded Region Proposal Networks for Real-Time Visual Tracking
- 目标检测分割--BlitzNet: A Real-Time Deep Network for Scene Understanding
- 论文翻译:Multi-View 3D Object Detection Network for Autonomous Driving
- 论文Batch DropBlock Network for Person Re-identification and Beyond 全文翻译简单解读以及代码理解复现
- 论文解读之Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- [论文翻译]Pedestrian Alignment Network for Large-scale Person Re-Identification
- Semantic Segmentation--ICNet for Real-Time Semantic Segmentation on High-Resolution Images论文解读
- 论文笔记:Perceptual Losses for Real-Time Style Transfer and Super-Resolution[doing]