比特跳动公司的一面
故事发生在很平淡的一个早上,一本正经的小扎正端坐在自己的电脑桌前,眼神迷离,因为今天早上要和比特公司进行视频一面,昨晚上紧张的没睡好,为了今天的面试还和领导请了个假,谎称身体不舒服,“求老天保佑”,小扎内心祈祷,毕竟自己也为这次面试准备了好久。
小扎盯着时间,呼吸越来紧促,因为还剩几秒就到约定的面试时间了,6,5,4,3,2,1,叮铃铃,对方拨起了视频邀请,小扎接受了邀请,“你好,我是今天的面试官”,“你好,你好”小扎连忙应答到。
面试官:你先做个自我介绍吧。
小扎:你好,我叫小扎,19年毕业于...
数据库篇
面试官:我看你的简历说到你熟悉MySQL,那我先来问问MySQL相关的知识吧。
小扎:好的。
面试官:现在有张成绩表(grade),它的结构如下,请你统计出平均成绩大于80的同学姓名和平均成绩。
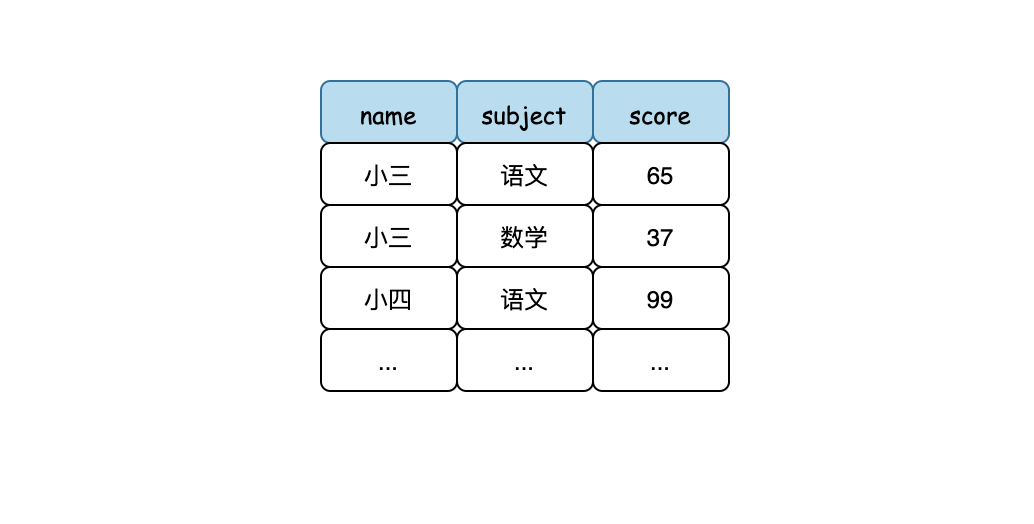
小扎:(我去,一上来直接写sql...)好的,小扎思考一下(看来这题面试官想考我having和group by的用法,不过这简单,难不倒我),过了一会小扎写出以下sql。
select name,avg(score) as avgScore from grade having avgScore>80 group by name
面试官看了看sql,于是说到:你们平时用的什么引擎?
小扎:InnoDB存储引擎(我猜他要问我几种存储引擎的区别了)
面试官:那InndoDB和Myisam的区别是什么?
小扎:(果然不出所料,还好平时八股文看的不少)
- InndoDB是支持事务的,Myisam是不支持的
- InnoDB支持外键,而Myisam不支持
- InnoDB的数据是存储在B+树的叶子节点的,而Myisam的叶子节点只是存储指向数据的指针
面试官:等等,我打断一下,索引这里能在讲清楚点吗,比如聚集索引和非聚集索引分别是怎样存的。
小扎:这里是这样的,对于InnoDB来说,它的聚集索引叶子节点存的是整行数据,而非聚集索引的叶子节点存的是主键id,因此在非聚集索引上查不到的字段时需要通过id回表,而Myisam是没有聚集索引之说的,不管是主键id索引还是普通索引,叶子节点存的不是整行数据或者主键id,而是指向行数据的指针,所以在Myisam中通过普通索引查数据没有回表一说。
面试官:那你继续说。
小扎:好的, InnoDB不保存表的具体行数,比如执行select count(*) from table时需要全表扫描。而Myisam用一个变量保存了整个
20000
表的行数,执行上述语句时只需要读出该变量即可,速度很快。
面试官:对于Myisam,如果我执行了一下sql,它要全表扫描?
select count(*) from xx where name=xx
小扎:首先带where条件的,肯定是不会用到那个行变量的,这时得分情况,如果name没有索引,那么是要全表的扫的,如果name有索引,应该是会走name索引的。
面试官:那对于InnoDB一定每次都是全表扫吗?
小扎:不一定,某些情况下,MySQL会选择走覆盖索引
面试官:那为什么会选择走覆盖索引呢?
小扎:覆盖索引话,只需要存索引字段本身和主键id值,因此对于同一页来说,可以存放更多的行,那么扫描的页就会少,速度就会更快。
面试官:那两种存储引擎还有其他区别吗?
小扎:InnoDB支持表、行级锁,而MyISAM支持表级锁。 InnoDB表必须有主键,如果没有设置主键会尝试找到表中的唯一索引来当主键,如果唯一索引也没有,那么会默认一个row_id来当主键,而Myisam可以没有。
面试官:这里能说下myisam为什么可以没有吗?
小扎:前面说了,对于myisam,它的主键索引和普通索引区别不大,叶子节点都是指向整行数据的指针。这个从存储文件上就可以看出:
- Innodb:两个文件,frm是表定义文件,ibd是数据文件
- Myisam:三个文件,frm是表定义文件,myd是数据文件,myi是索引文件。
大概它们的区别就是这么多。
面试官:就这么多吗?不是说InnoDB不支持全文索引,而Myisam支持吗,这个难道不是区别吗?
小扎:(尼玛,不知道这面试官是真不知道还是假不知道),这个是这样的,5.6版本之后InnoDB存储引擎开始支持全文索引,5.7版本之后通过使用ngram插件开始支持中文,所以对于高版本InnoDB引擎的MySQL,是支持全文索引的。(这都几点了,还在问区别,myisam都快淘汰了,我xxx)

面试官:(还行,接着炸他看看),知道查询缓存吗?
小扎:知道,某些执行过的语句及其结果可能会以 key-value 对的形式被直接缓存在内存中。key 是查询的语句,value 是查询的结果,这样当同样的SQL来查询的时候,如果缓存中有,可以从缓存中获取。
面试官:那你知道其实MySQL8.0开始就废弃这个模块了吗?查询缓存不是挺好的吗,为啥要废弃?
小扎:这个了解点,因为对于某些更新频繁的数据表来说,查询缓存太容易失效了,比如刚刚缓存一个数据,可能因为下一个查询,导致这个缓存被踢出去了,那么就白白浪费了一次缓存操作。
面试官:那你说说什么时候需要垂直分表,什么时候需要水平分表?
小扎:如果一张表的字段很多,而且比如有一些text类型字段,建议将其拆出去,让一些不经常被查询的字段不占用解析开销、带宽开销,这是垂直分表,而对于水平分表那就是一张表的数据越来越多的时候,建议多分几张表,这样不会因为一张表越来越大导致查询变慢。
网络篇
面试:(还行,数据库就先不问了吧),接下来我考考你网络相关的知识吧。
小扎:(来吧!谁怕谁)好的,好的。

面试官:先说说http请求中GET和HEAD的区别?
小扎:(我xx,不按常理啊,一般都是GET和POST,奸诈!不过还好俺会),HEAD请求只需要响应头部信息,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源内容,HEAD方法一般用于测试超链接的有效性,是否可以访问,以及最近是否更新等等。

面试官:那你说说cookie和session的区别吧。
小扎:(这么low比的问题,我是来面试app后端的,搞啥呢),session 是存在服务器端的,而cookie存在客户端浏览器的,session 默认被存在服务器的一个文件里,不是内存,当然 session 也可以放在文件、数据库、或内存中, session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie,同时 session 也会失效,但是可以通过其它方式实现,比如在 url 中传递 session_id。
面试官:说说看,http状态码401,301,302,201,304分别是什么意思?
小扎:(你是什么意思,这么多谁能记得住?真想反问你),我想想哈,401是请求要求身份验证,对于需要登录的网页,服务器可能返回此响应,301是永久重定向,302是临时重定向,304是客户端缓存,比如某个静态资源没有改变时,可能会返回304,(201是个什么鬼东西,先糊弄过去吧),大概就这么多。
面试官:嗯~,201没说吧。
小扎:(没想到这个秃头三,还挺较真),201~。(只能坦白了,我来反问他看看,看看他是不是在装x),这个我不太清楚了,你能告诉我一下吗(语气诚恳。。)

面试官:HTTP状态201作为HTTP POST请求的结果,表示已在服务器上成功创建了一个或多个新资源,懂了吗?
小扎:哦哦,懂了,大佬牛逼(说的啥玩意,这么抽象)
面试官:好,那我们继续,你知道http的keep-alive是啥意思?
小扎:这个表示http连接没有断,还能用,在http早期,每个http请求都要求打开一个tcp连接,并且使用一次之后就断开这个tcp连接,有了keep-alive之后,一个http产生的tcp连接在完最后一个响应后,还需要等待一定的timeout秒后,才开始关闭这个连接。
面试官:那tcp和udp有什么区别?
小扎:tcp连接需要3次握手,断连需要4次挥手,而udp不需要,tcp可以保证数据正确性,udp可能丢包,tcp能保证数据顺序,udp不保证。
面试官:那udp既然这么不可靠是不是就没什么应用场景了?
小扎:不不,像QQ聊天、在线视频、网络语音电话等对效率要求比较高,但是偶尔可以忍受数据丢失的问题,应该是可以采用udp协议的。
面试官:前面你说到了 tcp 4次挥手,你能具体说下哪四次吗?
小扎:好的,我来画张图吧
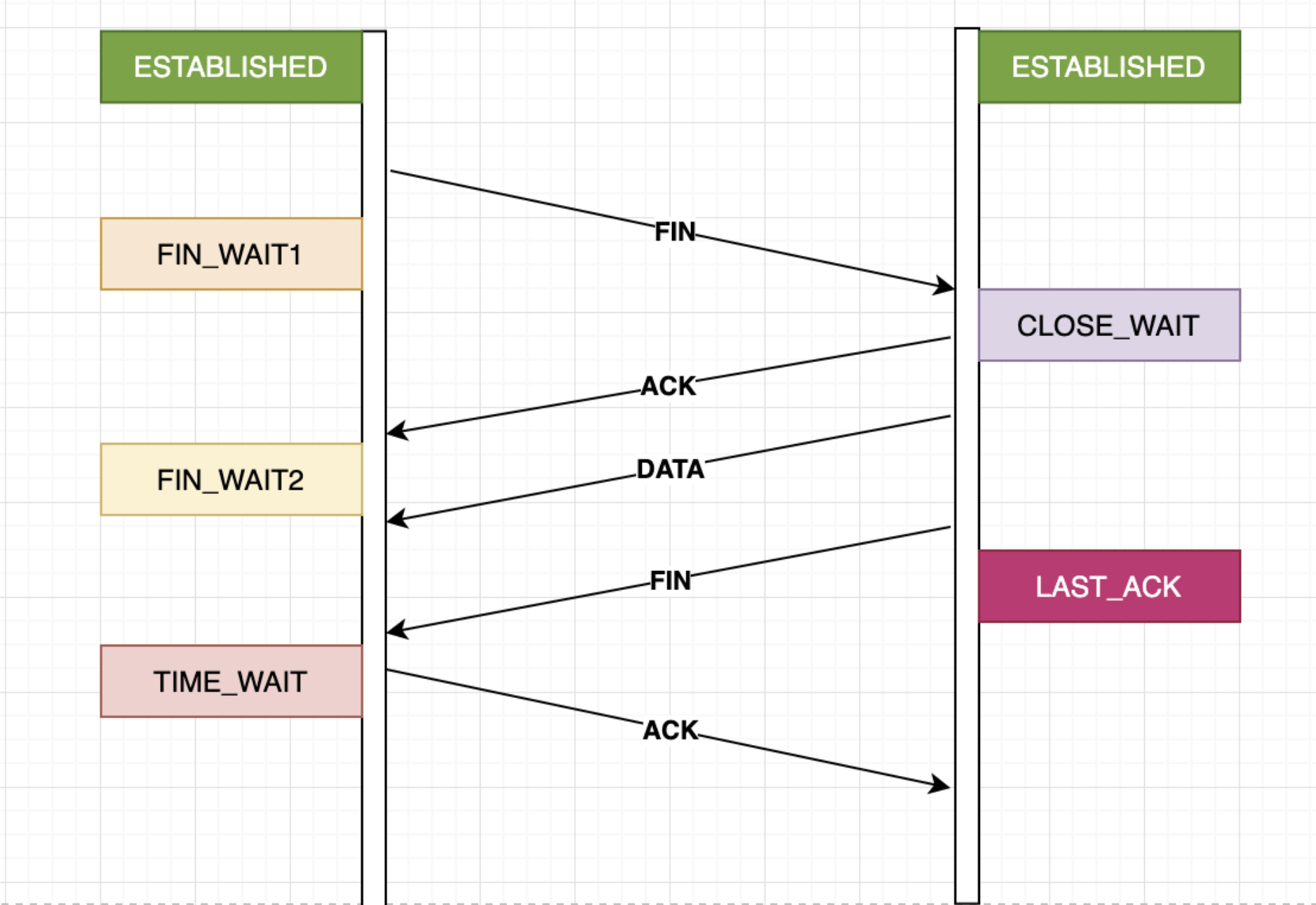
第一次:主动断开那一方会发送一个FIN包,就好像说:“喂,我准备断开连接了”
第二次:接收方收到FIN之后,回复一个ACK包,就好像说:“好的,知道了”,然后把处理好的数据一起发给对端。
第三次:接收方在把数据处理完之后,也发个FIN包给主动断开的那一方,就好像说:“对面的,我这边都处理完了,你就断开吧,我也不接收你发送来的数据了”
第四次:主动断开方收到对端的FIN包之后,回复ACK,同时等待TIME_WAIT时间。
面试官:那TIME_WAIT是干什么的吗?还有TIME_WAIT具体是多长时间?
小扎:TIME_WAIT是主动断开方关闭后最后进入的一种状态,TIME_WAIT是2MSL,其中一个MSL是报文最大的生命周期。
面试官:那这里为什么要两个MSL?
小扎:这个是这样的,在主动断开方发送最后一个ACK之后,万一这个ACK消耗了一个MSL的时间,但是还没到达对端,那么整个连接就没有被正确断开,这时对端会发起重试,也就是对端会再发一个FIN包,所以2MSL就是主动断开方最后一次发送ACK的时间+对端重发FIN包的时间,保证了一去一回的最短时间。
redis
面试官:平时缓存用的多吗?
小扎:还行,会用一些。
面试官:你们用什么做缓存的?
小扎:redis
面试官:那先说说redis支持哪些类型?
小扎:string、list、set、zset、hash
面试官:string的底层是什么数据结构?
小扎:sds动态字符串,比如当我们执行
set key value的时候, key对应一个sds结构, value也对应一个sds结构。它的结构大致如下:
struct sdshdr {
int len;
int free;
char buf[];
};
free代表sds还剩多少空间,len代表字符串长度,buf就是真正存储的值。
面试官:那这样的设计有什么好处呢?
小扎:主要就是为了避免key不停的修改导致不停的申请内存的开销,sds每次在空间不足的时候,会申请更多的空间,一般就是2倍,这样当下次变更的时候,如果还有剩余的空间,就不用像系统申请内存。
面试官:平时用redis做消息队列吗?
小扎:用的少,一些对数据安全要求不那么严格的场景会用一些,因为redis的list无法保证数据不丢失。
面试官:那如果不考虑丢失的情况,在使用了list做消息队列的时候,还有哪些要考虑的吗?
小扎:最好不要和业务redis共用一个集群,因为万一消息队列出现问题,比如消费者挂了,那么在消息量很大的情况下,就会导致内存直线上线,可能会影响其他业务。
面试官:说说redis的持久化方式
小扎:redis主要有rdb和aof两种持久化方案,rdb存储的是二进制格式,恢复快,aof存储的是执行的语句。
面试官:既然aof存储的是执行的语句,那会不会导致aof越来越大,比如我执行了100次的
incr num,那其实它是不是就等同于
set num 100呢?
小扎:aof是会越来越大的,对同一个key变更多少次,就记录多少条,为了解决这个问题,aof会在文件大到一定程度的时候,开始重写,就比如你说的100次的incr可以用一次的set代替。
面试官:那这个是如何重写的呢?直接分析现有的aof文件吗?
小扎:不是的,其实没必要分析现有的aof,而是直接读库扫描,比如会从0号库开始扫,把扫到的数据重新写入一个新的aof文件中,比如对于string类型的数据,直接记录一条set key value即可,而不用考虑这个key中途变更了多少次,当然不是所有的数据都可以用一条命令代替,比如sadd,每次最多只能add 64个,如果超过64个就要分批了。
sadd key 1 2 ... 64 sadd key 65 66 ... ...
面试官:那在重写的过程中,新的命令怎么办?直接写新的aof吗?
小扎:不是的,重写需要一定的时间,所以在重写完成之前还是得用老的aof,所以新命令还是会写入老aof,同时也会写入一个重写缓冲区,在重写完毕之后,再把重写缓冲区的数据写入新的aof文件中,即rename新的aof,原子的覆盖老的aof。
面试官:等等~,“重写完毕之后,再把重写缓冲区的数据写入新的aof文件中”,这里我点疑问,缓冲区写入文件这个过程如果还有新的命令请求怎么办?
小扎:我具体说下,这里是这样的,首先重写是子进程来处理的,在重写完毕之后,子进程会告诉主进程,主进程在收到通知后会阻塞,这时是不会有新的命令写入的。
linux
面试官:那你说说什么是孤儿进程,什么是僵尸进程吧
小扎:(这人真是什么都问~),好的,孤儿进程就是一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程,孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。僵尸进程就是一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
面试官:如何查看一个端口占用情况?
小扎:用lsof -i
面试官:如何查看cpu的负载?
小扎:用top命令
面试官:如何查看当前磁盘负载情况?
小扎:用iostat命令
面试官:那你说说信号和信号量是什么区别?
小扎:信号和信号量完全是两个东西,信号是由用户、系统或者进程发送给目标进程的信息,以通知目标进程某个状态的改变或系统异常,常见的就是KILL信号,信号量是进程间通信处理同步互斥的机制,它的本质是计数器,信号量里面记录了临界资源的数目,有多少数目,信号量的值就为多少,进程对其访问都是原子操作。
算法
面试官机智的看了一下时间,心想快到饭点了,“那我们来做一道算法题吧”。
小扎:(最关键的来了,冷静~,我先深呼吸一口)好的。
面试官:(就出一道简单的吧,饿死了~),现在给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格,你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。比如prices=[7,1,5,3,6,4],那么在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5
小扎:(故作镇定~),好的,了解了(这题尼玛昨天我不是刚刚刷到吗,lucky~)
面试官:提醒下,你就不要用穷举法了,两次遍历太简单了,看看有没有其他思路。
小扎:好的,了解了(规矩我懂)
此刻的小扎使劲在脑海里回忆“找到此题的解法关在是找到规律,这个规律是什么呢”,然而此时紧张的气氛让小扎无法集中注意力,况且面试官好像很焦急的样子让整个气氛更加紧张,“咕噜~咕噜噜~~”,安静的气氛让小扎听到了面试官肚子饿的声音了,“这尼玛,这面试官肯定是要急着吃饭呀,估计留给我的时间不多了,我得赶快想”。时间一分一秒的过去了,突然在2分钟后,面试官开口了,“这尼玛要结束了吗,这才几分钟呀,阿西吧”。“给你个提示吧,最大利润是不是等于最大值减去最小值,照着这个思路想想看”,面试官说道。听到了面试官的提示之后,小扎突然想到了~。
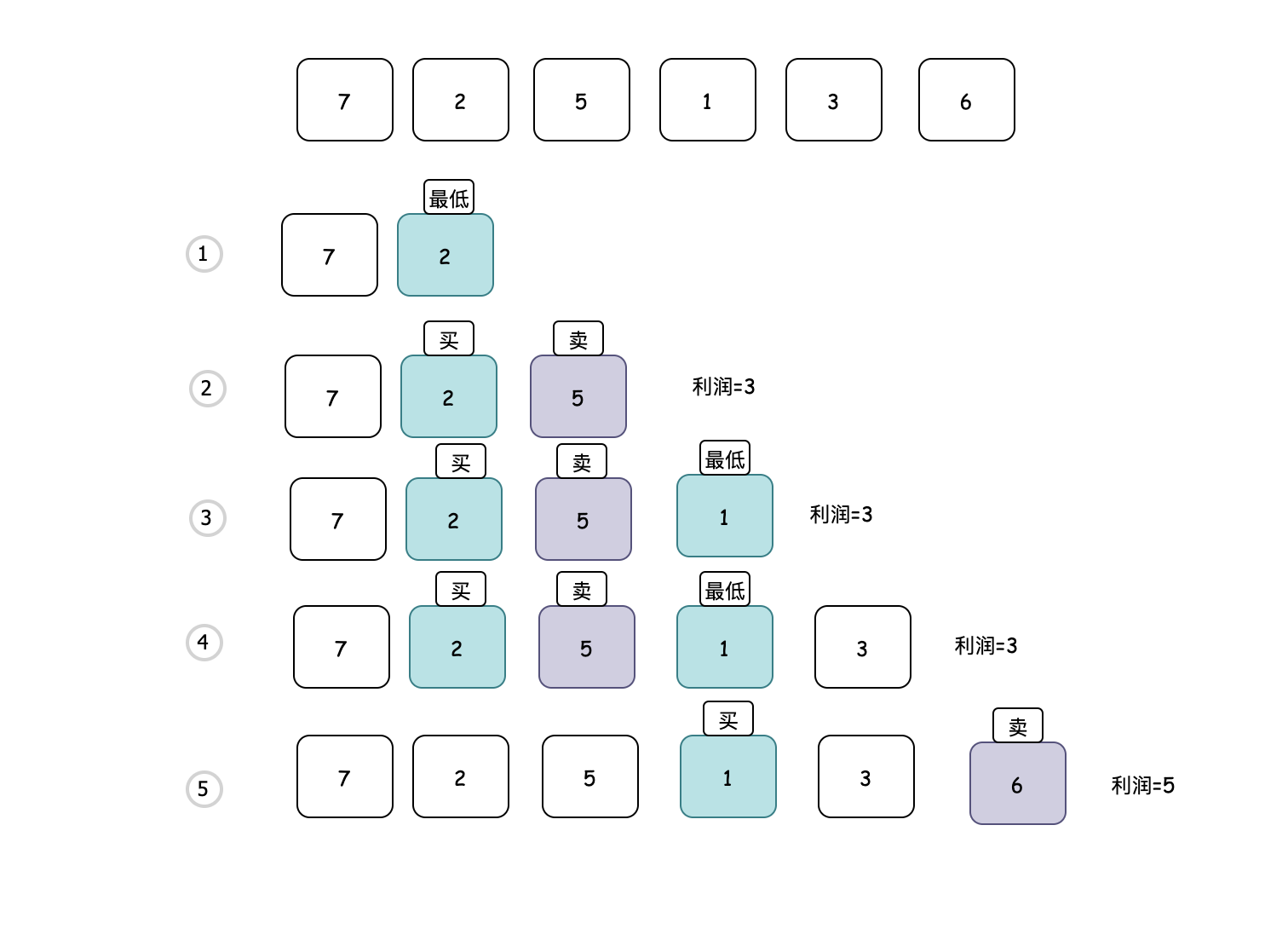
核心思想就是以最低价格买入,最高价格卖出即可得到最大利润,但是找到最低价格之后,还要看在这个最低价格之后某一天卖出,是否比前面的利润大。比如上图的第4步,虽然1是最低的,但是很明显3-1 是小于 5-2 的,所以在第4步,最大利润还是3。
那么解题的第一步就是需要一个保存最低买入价格的变量和一个保存当前最大利润的变量,然后依次遍历,只要存在当前卖出价格与最低买入价格的差值大于当前最大利润的情况,那么此时卖出获取的利润一定是最大的。
先找到最低买入价格,直接遍历判断就行
func maxProfit(prices []int) int {
minPrice := prices[0]
for i := 1; i < len(prices); i++ {
if prices[i] < minPrice {
minPrice = prices[i]
}
}
}
那么接下来就是算利润了,也就是找到使利润最大化的卖出价格,如果当前卖出价格比最低买入价格还低,那么就跳过,不用算利润(因为最小值减去前面任何值肯定都是负数),如果当前卖出价格比最低买入价格高,那么就和最低买入价格减一下,然后再和当前利润判断下,看看谁的利润大,因此代码最终代码应该这样的:
func maxProfit(prices []int) int {
minPrice := prices[0] //假设最低买入价格是第一个元素
maxProfit := 0 //最大利润
for i := 1; i < len(prices); i++ {
if prices[i] < minPrice {
minPrice = prices[i] //最低买入价格
} else if prices[i]-minPrice > maxProfit {
maxProfit = prices[i] - minPrice//最大利润
}
}
return maxProfit
}
“大佬,我写好了”,自信满满地小扎向面试官说到,此时的小扎骄傲无比,他此时感觉自己就是明星。

面试官看了看小扎的代码,然后说到,今天就到这吧,后面hr会和你联系的。

最后
和大家提前透露下,小扎一面已经通过了,微信搜【假装懂编程】,敬请期待小扎同学比特跳动的二面(更加残暴)


- 8月8 某公司一面
- 字节跳动前端暑期实习一面总结
- 读《我三年开发经验,从字节跳动抖音组离职后,一口气拿到15家公司offer》有感
- 一个程序员的随笔(来自跳动的比特的msn签名档)
- 字节跳动测开一面面筋
- 字节跳动大数据岗位面经(一面、二面、三面、hr面,base南京)
- 比特大陆前芯片设计师创立的公司MicroBT最快于明年IPO
- 字节跳动 前端实习 一面经验分享
- 某游戏公司php一面记录
- 字节跳动Android实习生视频面试(一面)
- 字节跳动--头条研发--一面
- 【面试】字节跳动前端一面
- 刚到的新公司 前任经理匆匆见了一面 飞鸽传书下载
- [企业薪资] 揭秘圈内互联网公司压榨员工不为人知的一面【转贴】
- 星球日报 | 比特大陆回应“吴忌寒创办新公司”系谣言;蚂蚁金服区块链公司落地上海...
- 【面经二】拼多多、字节跳动、触宝、平安证券等公司算法工程师面试问题集锦
- 字节跳动回应超十亿收购游戏公司:不属实
- 字节跳动成立演出经纪新公司,经营范围包括营业性演出等
- 3/28某广州公司一面
- 杭州某公司技术一面