redis 简单整理——哨兵原理[三十一]
前言
简单介绍一下哨兵的原理。
正文
- 一套合理的监控机制是Sentinel节点判定节点不可达的重要保证,Redis Sentinel通过三个定时监控任务完成对各个节点发现和监控:
1)每隔10秒,每个Sentinel节点会向主节点和从节点发送info命令获取 最新的拓扑结构。
例如下面就是在一个主节点上执行info replication的结果片段

Sentinel节点通过对上述结果进行解析就可以找到相应的从节点。
这个定时任务的作用具体可以表现在三个方面:
·通过向主节点执行info命令,获取从节点的信息,这也是为什么 Sentinel节点不需要显式配置监控从节点。
·当有新的从节点加入时都可以立刻感知出来。
·节点不可达或者故障转移后,可以通过info命令实时更新节点拓扑信息。
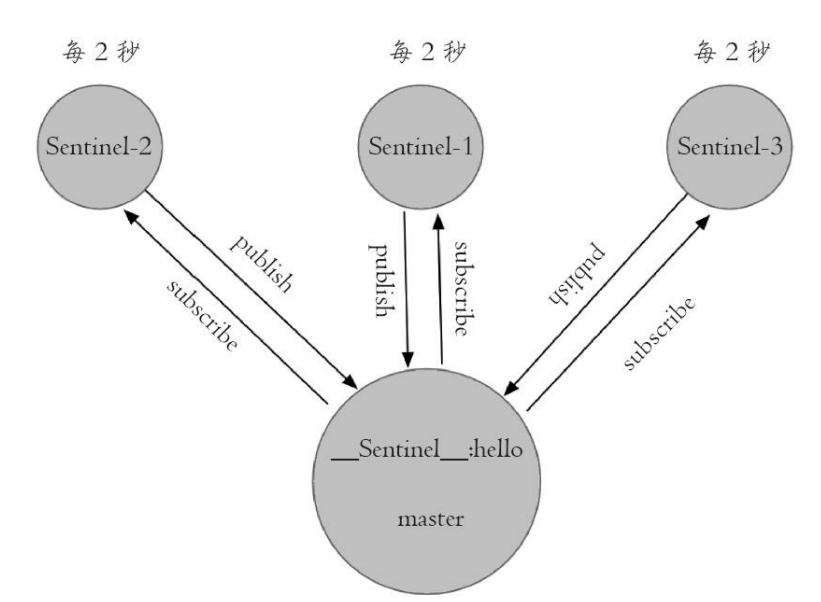
2)每隔2秒,每个Sentinel节点会向Redis数据节点的__sentinel__:hello 频道上发送该Sentinel节点对于主节点的判断以及当前Sentinel节点的信息
同时每个Sentinel节点也会订阅该频道,来了解其他 Sentinel节点以及它们对主节点的判断,所以这个定时任务可以完成以下两个工作:
·发现新的Sentinel节点:通过订阅主节点的__sentinel__:hello了解其他 的Sentinel节点信息,如果是新加入的Sentinel节点,将该Sentinel节点信息保 存起来,并与该Sentinel节点创建连接。
·Sentinel节点之间交换主节点的状态,作为后面客观下线以及领导者选举的依据。
Sentinel节点publish的消息格式如下:

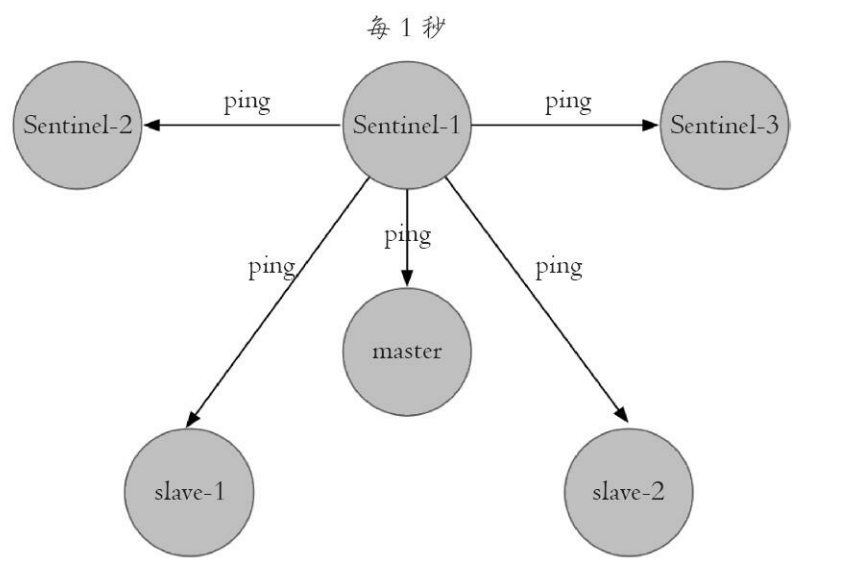
3)每隔1秒,每个Sentinel节点会向主节点、从节点、其余Sentinel节点 发送一条ping命令做一次心跳检测,来确认这些节点当前是否可达。
通过上面的定时任务,Sentinel节点对主节点、从节点、其余 Sentinel节点都建立起连接,实现了对每个节点的监控,这个定时任务是节 点失败判定的重要依据。
主观下线和客观下线:
上一小节介绍的第三个定时任务,每个Sentinel节点会每隔1秒对主节 点、从节点、其他Sentinel节点发送ping命令做心跳检测,当这些节点超过 down-after-milliseconds没有进行有效回复,Sentinel节点就会对该节点做失败 判定,这个行为叫做主观下线。从字面意思也可以很容易看出主观下线是当 前Sentinel节点的一家之言,存在误判的可能。

客观下线:
当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel is- master-down-by-addr命令向其他Sentinel节点询问对主节点的判断,当超过 个数,Sentinel节点认为主节点确实有问题,这时该Sentinel节点会 做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分 Sentinel节点都对主节点的下线做了同意的判定,那么这个判定就是客观 的。
从节点、Sentinel节点在主观下线后,没有后续的故障转移操作。
这里有必要对sentinel is-master-down-by-addr命令做一个介绍,它的使用 方法如下:
·ip:主节点IP。
·port:主节点端口。
·current_epoch:当前配置纪元。
·runid:此参数有两种类型,不同类型决定了此API作用的不同。 当runid等于“*”时,作用是Sentinel节点直接交换对主节点下线的判定。
当runid等于当前Sentinel节点的runid时,作用是当前Sentinel节点希望目 标Sentinel节点同意自己成为领导者的请求,有关Sentinel领导者选举,后面 会进行介绍。

sentinel is-master-down-by-addr 127.0.0.1 6379 0 *
返回结果包含三个参数,如下所示:
·down_state:目标Sentinel节点对于主节点的下线判断,1是下线,0是 在线。
·leader_runid:当leader_runid等于“*”时,代表返回结果是用来做主节点 是否不可达,当leader_runid等于具体的runid,代表目标节点同意runid成为 领导者。
·leader_epoch:领导者纪元。
假如Sentinel节点对于主节点已经做了客观下线,那么是不是就可以立 即进行故障转移了?当然不是,实际上故障转移的工作只需要一个Sentinel 节点来完成即可,所以Sentinel节点之间会做一个领导者选举的工作,选出 一个Sentinel节点作为领导者进行故障转移的工作。Redis使用了Raft算法实 现领导者选举,因为Raft算法相对比较抽象和复杂,以及篇幅所限,所以这 里给出一个Redis Sentinel进行领导者选举的大致思路:
1)每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观 下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令, 要求将自己设置为领导者。 2)收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝。 3)如果该Sentinel节点发现自己的票数已经大于等于max(quorum, num(sentinels)/2+1),那么它将成为领导者。 4)如果此过程没有选举出领导者,将进入下一次选举。
1)s1(sentinel-1)最先完成了客观下线,它会向s2(sentinel-2)和 s3(sentinel-3)发送sentinel is-master-down-by-addr命令,s2和s3同意选其为 领导者。
2)s1此时已经拿到2张投票,满足了大于等于max(quorum, num(sentinels)/2+1)=2的条件,所以此时s1成为领导者。
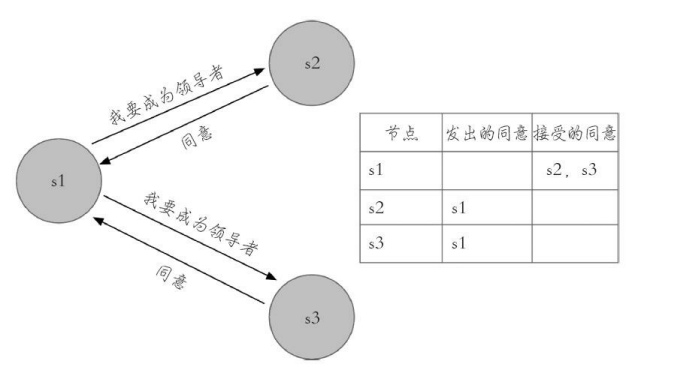
由于每个Sentinel节点只有一票,所以当s2向s1和s3索要投票时,只能获 取一票,而s3由于最后完成主观下线,当s3向s1和s2索要投票时一票都得不 到。
实际上Redis Sentinel实现会更简单一些,因为一旦有一个Sentinel节点获 得了max(quorum,num(sentinels)/2+1)的票数,其他Sentinel节点再去确 认已经没有意义了,因为每个Sentinel节点只有一票。
领导者选举出的Sentinel节点负责故障转移,具体步骤如下:
1)在从节点列表中选出一个节点作为新的主节点,选择方法如下:
a)过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节 点ping响应、与主节点失联超过down-after-milliseconds*10秒。
b)选择slave-priority(从节点优先级)最高的从节点列表,如果存在则 返回,不存在则继续。
c)选择复制偏移量最大的从节点(复制的最完整),如果存在则返 回,不存在则继续。
d)选择runid最小的从节点。
2)Sentinel领导者节点会对第一步选出来的从节点执行slaveof no one命 令让其成为主节点。
3)Sentinel领导者节点会向剩余的从节点发送命令,让它们成为新主节 点的从节点,复制规则和parallel-syncs参数有关。
4)Sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关 注,当其恢复后命令它去复制新的主节点。
结
本来下一节是集群,但是没有用到过集群,故而不整理了。下一节缓存设计。

- 【整理】Hibernate分页原理简单分析
- Redis(开发与运维):44---Sentinel之(哨兵实现原理:三个定时监控任务、主观下线和客观下线、领导者节点选举、故障转移)
- Redis哨兵原理,我忍你很久了!
- Redis主从原理及哨兵模式
- Redis问题简单整理
- iis运行机制 交互原理 简单整理
- redis哨兵(sentinel)原理
- redis-sentinel-哨兵集群-简单部署
- Redis之-哨兵模式原理
- 架构师养成记--33.Redis哨兵、redis简单事务
- Redis 高可用篇:你管这叫 Sentinel 哨兵集群原理
- redis-复制原理-哨兵模式
- Redis 主从安装与哨兵(简单配置)
- redis读写分离(主从关系)和哨兵模式简单描述(高可用性)
- 24 redis哨兵的多个核心底层原理的深入解析(包含slave选举算法)
- [置顶] 搭建一个简单的redis-sentinel(哨兵机制)集群
- Redis集群 - redis主从配置初步:简单主从切换(哨兵模式)
- redis-Sentinel哨兵原理与实战
- 深入Redis主从高可用方案:哨兵机制核心原理
- redis分片缺点及特点,redis主从,哨兵原理,哨兵特点,redis集群及失效情况,redis配置文件