Dokcer核心技术
前言
Docker容器技术相信大家或多或少都听说过吧,现在可谓是红极一时。它的优势主要有以下几点:
- 不需要再启动内核,所以应用扩缩容时可以秒速启动。
- 资源利用率高,直接使用宿主机内核调度资源,性能损失小。
- 一键启动所有依赖服务,镜像一次编译,随处使用。测试和生产环境高度一致。
- 应用的运行环境和宿主机环境无关,完全由镜像控制,一台物理机上部署多种环境的镜像测试。
- 实现了持续的交付和部署。
但是我们在学习一样东西时不能仅仅停留于表面的命令,更重要的是深入进去理解,Docker的核心技术主要基于Linux的
namespace,
cgroup和
Union Fs文件系统,以及Docker自身的网络。
今天的这篇文章主要是介绍Docker的核心技术namespace,cgroup,Union FS(docker的网络后续会出),总结一下这段时间的学习。
Namespace
Linux Namespace是Linux Kernel提供的资源隔离方案:
- 系统可以为进程分配不同的namespace,每个进程都会有自己的namespace
- 并保证不同的namespace资源独立分配,进程彼此隔离,即不同的namespace下的进程互不干扰
为了隔离不同的资源,Linux Kernel提供了六种不同类型的namespace:
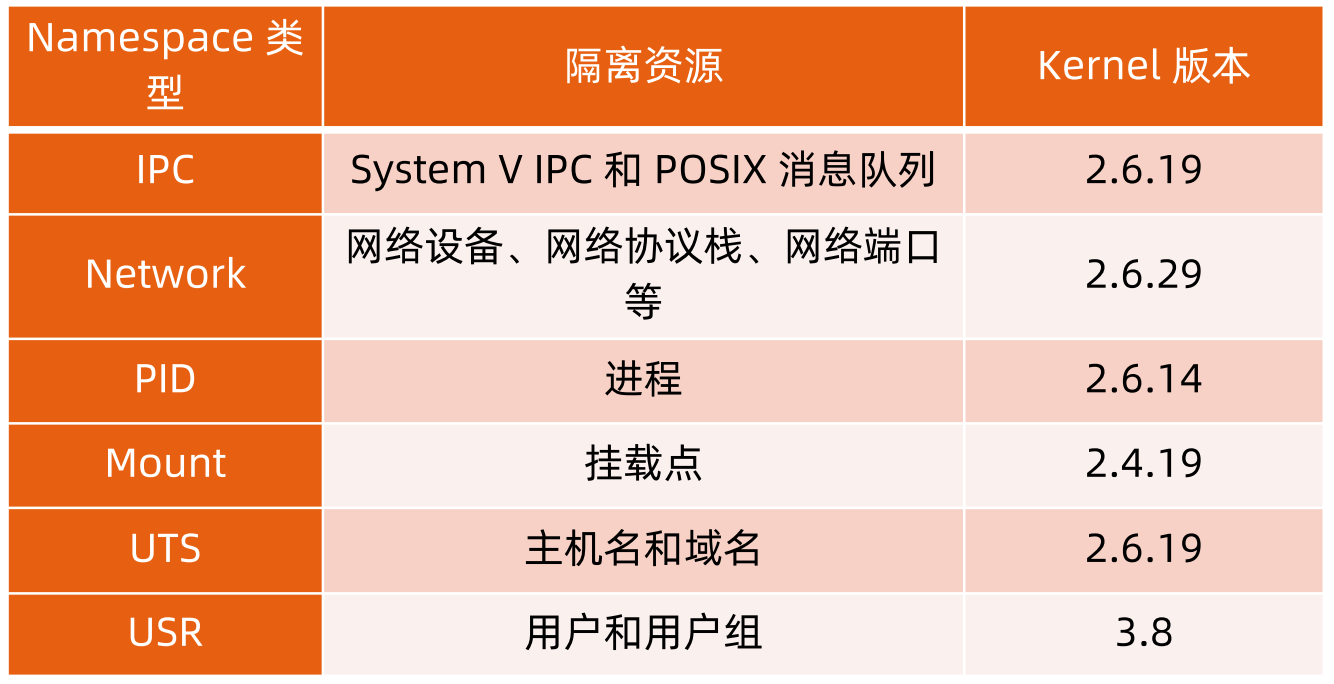
**注:**UTS全称:UNIX Time Sharing UNIX分时操作系统
Linux对namespace的实现
既然namespace和进程相关,那么我们可以在
task_struct结构体中看到包含和namespace相关联的变量。
## \kernel\msm-4.4\include\linux\sched.h
struct task_struct { // 当然task_struct中还包含关于进程的其他信息 比如进程状态等
...
/* namespaces */
struct nsproxy *nsproxy;
...
}
其中
nsproxy结构体包含了关于各种命名空间实现
# \kernel\msm-4.4\include\linux\nsproxy.h
/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* The pid namespace is an exception -- it's accessed using
* task_active_pid_ns. The pid namespace here is the
* namespace that children will use.
*
* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
*
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied.
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
};
extern struct nsproxy init_nsproxy; // init_nsproxy是对除了.mnt_ns之外的namespace进行系统初始化
Linux对namespace的操作方法
主要是三个命令:
clone,
setns,
unshare
clone
// linux中轻量级的进程是由clone()函数创建的 /* fn 当一个新进程通过clone创建时,它通过调用fn所指向的函数开始执行 child_stack 为子进程分配的堆栈空间 flags 在创建新进程的系统调用时可以通过flags参数指定需要新建的namespace类型 CLONE_NEWIPC 对应IPC命名空间 CLONE_NEWNET 对应NET命名空间 CLONE_NEWNS 对应Mount命名空间 CLONE_NEWPID 对应PID命名空间 CLONE_NEWUSER 对应User命名空间 CLONE_NEWUTS 对应UTS命名空间 CLONE_NEWCGROUP 对应cgroup命名空间,使进程有一个独立的cgroup控制组,始于Linux 4.6 */ int clone(int (*fn)(void *), void *child_stack, int flags, void *arg)
clone创建一个新的进程加入到新的命名空间中,不会影响当前进程,而且clone创建的子进程可以共享父进程的虚拟空间地址,文件描述符,信号处理表等。
注:
(1) clone和fork的调用方式很不相同,clone调用需要传入一个函数int (*fn)(void *),该函数在子进程中执行。
(2)clone和fork最大不同在于clone不再复制父进程的栈空间,而是自己创建一个新的。 (void *child_stack,)也就是第二个参数,需要分配栈指针的空间大小,所以它不再是继承或者复制,而是全新的创造。
setns
/* fd 指向/proc/[pid]/ns命名空间的文件描述符 nstype 对应命名空间的flags 如果为0表示允许进入任何一个命名空间 */ int setns(int fd, int nstype) // 举例 int fd = pidfd_open(1234, 0); setns(fd, CLONE_NEWUSER | CLONE_NEWNET | CLONE_NEWUTS);
调用某个线程(单线程即进程)加入指定的namespace
unshare
int unshare(int flags)
可以将调用进程移动到新的namespace,是当前进程退出当前的命名空间,进入新的命名空间。注意与clone()的区别。
关于namespace常用的操作
查看当前系统的 namespace:
lsns –t <type>
[root@aliyun ns]# lsns -t mnt NS TYPE NPROCS PID USER COMMAND 4026531840 mnt 88 1 root /usr/lib/systemd/systemd --system --deserialize 17 4026531856 mnt 1 13 root kdevtmpfs 4026532151 mnt 1 541 chrony /usr/sbin/chronyd
查看某进程的 namespace:
ll /proc/<pid>/ns/
# 先查出进程id [root@aliyun proc]# docker inspect 97649934abf3 | grep -i pid "Pid": 26103, "PidMode": "", "PidsLimit": null, # 查看某进程的namespace [root@aliyun proc]# ll /proc/26103/ns total 0 lrwxrwxrwx 1 root root 0 Aug 31 15:19 ipc -> ipc:[4026532163] lrwxrwxrwx 1 root root 0 Aug 31 15:19 mnt -> mnt:[4026532161] lrwxrwxrwx 1 root root 0 Aug 31 15:17 net -> net:[4026532166] lrwxrwxrwx 1 root root 0 Aug 31 15:19 pid -> pid:[4026532164] lrwxrwxrwx 1 root root 0 Aug 31 15:19 user -> user:[4026531837] lrwxrwxrwx 1 root root 0 Aug 31 15:19 uts -> uts:[4026532162]
进入某 namespace 运行命令:
nsenter -t <pid> -n ip addr其中-t参数表示目标进程id,-n参数表示net命名空间。
nsenter相当于在setns的示例程序上做了一层封装,是我们无需指定命名空间的文件描述符,而是指定进程号即可。
nsenter可以在指定进程的命令下运行指定程序的命令,因为大多数的容器为了轻量级是不包含较为基础的命令的,这就为调试容器网络带来了很大的困扰,只能通过
docker inspect 容器id获取容器的ip,以及无法测试和其他网络的连通性(其实可以通过docker网络的管理),nsenter命令可以进入该容器的网络命名空间,使用宿主机命令调试网络。
# 在宿主机下使用ip addr查看容器中的网络信息 [root@aliyun proc]# docker inspect 97649934abf3 | grep -i pid "Pid": 26103, "PidMode": "", "PidsLimit": null, [root@aliyun proc]# nsenter -t 26103 -n ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever # 容器中的网络信息 可以发现完全相同 [root@97649934abf3 /]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
namespace练习
# 在新的network namespace中执行sleep指令 [root@aliyun proc]# unshare -fn sleep 60 # 查看sleep进程ip [root@aliyun /]# ps -ef | grep sleep root 27992 2567 0 15:47 pts/0 00:00:00 unshare -fn sleep 60 root 27993 27992 0 15:47 pts/0 00:00:00 sleep 60 root 28000 25995 0 15:47 pts/1 00:00:00 grep --color=auto sleep # 查看sleep的net namespace [root@aliyun /]# lsns -t net NS TYPE NPROCS PID USER COMMAND 4026531956 net 92 1 root /usr/lib/systemd/systemd --system --deserialize 17 4026532160 net 2 27992 root unshare -fn sleep 60 # 通过nsenter进入sleep的net namespace查看网络信息(注意操作需要在sleep进程的存活时间内完成60s) [root@aliyun /]# nsenter -t 27992 -n ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Cgroup
Cgroup(control groups)是linux下用于对一个或一组进程进行资源限制和监控的机制,可以对诸如 CPU 使用时间、内存、磁盘 I/O 等进程所需的资源进行限制。举个简单的例子,我系统中跑了一个while(true)程序,系统的cpu资源立马爆了,这时候我们可以通过cgroup对它限制cpu资源的使用。
Cgroup 在不同的系统资源管理子系统中以层级树(Hierarchy)的方式来组织管理:每个 Cgroup 都可以包含其他的子 Cgroup,因此子 Cgroup 能使用的资源除了受本 Cgroup 配置 的资源参数限制,还受到父 Cgroup 设置的资源限制。
Linux对cgroup的实现
同样我们可以在
task_struct结构体中看到cgroups相关联的变量
## \kernel\msm-4.4\include\linux\sched.h
struct task_struct {
/* Control Group info protected by css_set_lock: */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
struct list_head cg_list;
}
struct css_set {
/*
* Set of subsystem states, one for each subsystem. This array is
* immutable after creation apart from the init_css_set during
* subsystem registration (at boot time).
*/
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
}
Cgroup下的子系统
在
/sys/fs/cgroup下我们可以看到cgroup所包含的子系统:
- blkio:这个子系统设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及 USB 等等;
- cpu:这个子系统使用调度程序为 cgroup 任务提供 CPU 的访问;
- cpuacct:产生 cgroup 任务的 CPU 资源报告;
- cpuset:如果是多核心的CPU,这个子系统会为 cgroup 任务分配单独的 CPU 和内存;
- devices:允许或拒绝 cgroup 任务对设备的访问;
- freezer:暂停和恢复 cgroup 任务;
- memory:设置每个 cgroup 的内存限制以及产生内存资源报告;
- net_cls:标记每个网络包以供 cgroup 方便使用;
- ns:名称空间子系统;
- pid: 进程标识子系统。
比较重要和常用的就是cpu子系统和memory子系统
CPU子系统
cpu子系统中的主要内容如下
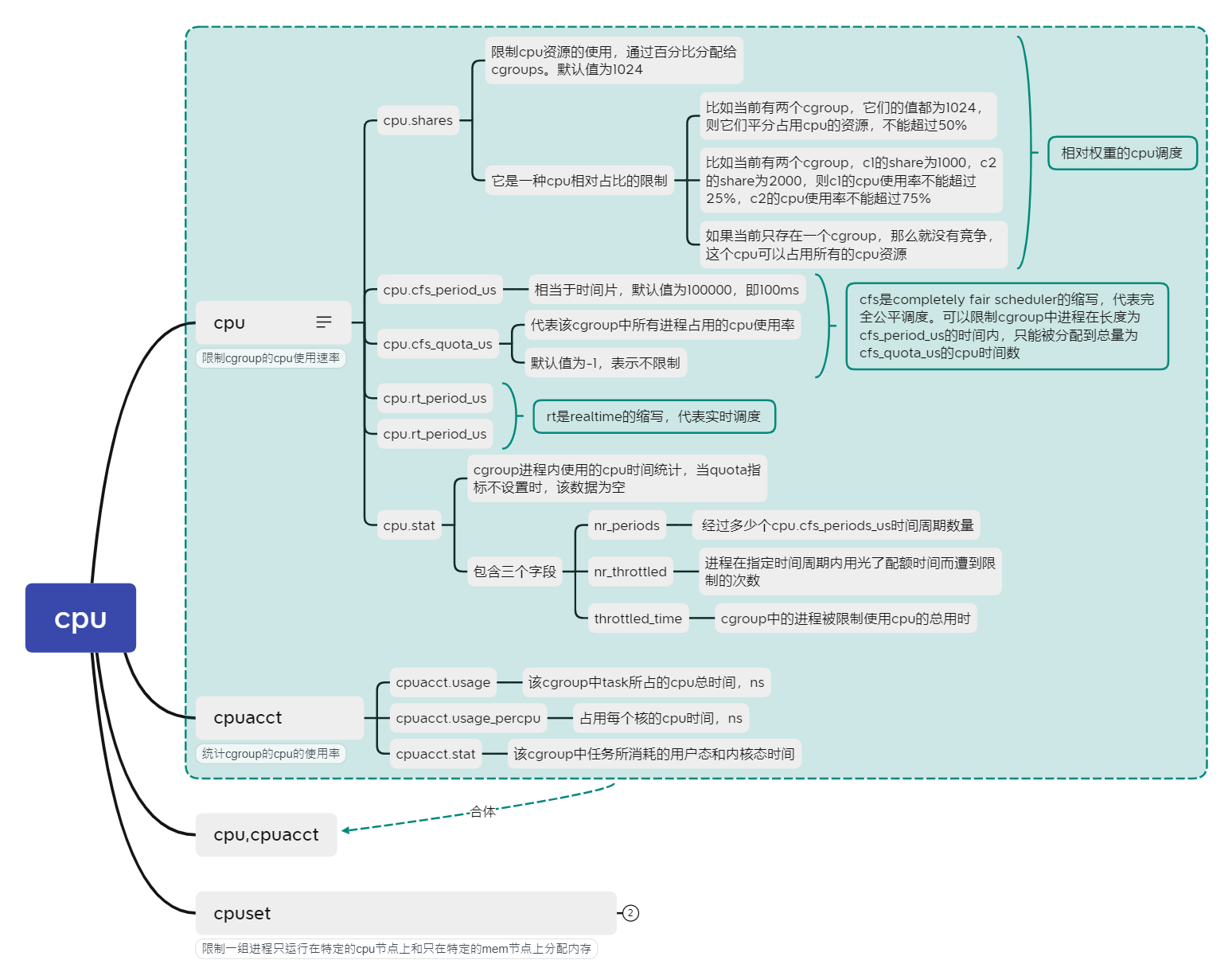
Go语言演示cgroup对cpu的限制
编写一个test.go测试文件并运行
package main
func main(){
i := 0
go func(){
for {
i++
}
}()
for {
i++
}
}
使用
top查看cpu在没有限制下的占用率,可以看到test文件占到90%多的cpu资源

在cgroup cpu子系统中建立文件夹,并使用cgroup进行限制
[root@aliyun test]# mkdir /sys/fs/cgroup/cpu/test [root@aliyun test]# cd /sys/fs/cgroup/cpu/test [root@aliyun test]# ls cgroup.clone_children cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us notify_on_release cgroup.event_control cpuacct.usage cpu.cfs_quota_us cpu.shares tasks cgroup.procs cpuacct.usage_percpu cpu.rt_period_us cpu.stat # 将cpu.cfs_quota_us的值设置为2000 cpu.cfs_period_us时间片默认的值还是为100000,可以将test.go执行的进程对cpu的利用率降低到2%左右 [root@aliyun test]# ehco 2000 > cpu.cfs_quota_us # 将test的进程id加入到cgroup.procs中 [root@aliyun test]# ehco 31944 > cgroup.procs
此时再用top查看进程资源信息就可以看到test测试文件对cpu的占用资源瞬间下降到2%作用,效果明显!

注:
关于 tasks 和 cgroup.procs,网上很多文章将 cgroup 的 Task 简单解释为 OS 进程,这其实不够准确,更精确地说,cgroup.procs 文件中的 PID 列表才是我们通常意义上的进程列表,而 tasks 文件中包含的 PID 实际上可以是 Linux 轻量级进程(Light-Weight-Process,LWP) 的 PID,而由于 Linux pthread 库的线程实际上轻量级进程实现的。简单来说:Linux 进程主线程 PID = 进程 PID,而其它线程的 PID (LWP PID)则是独立分配的
当要向某个 Cgroup 加入 Thread 时,将Thread PID 写入 tasks 或 cgroup.procs 即可,cgroup.procs 会自动变更为该 task 所属的 Proc PID。如果要加入 Proc 时,则只能写入到 cgroup.procs 文件,tasks 文件会自动更新为该 Proc 下所有的 Thread PID,通过tasks,我们可以实现线程级别的管理。
Memory子系统
cgroup的memory子系统全称为 Memory Resource Controller ,它能够限制cgroup中所有任务的使用的内存和交换内存进行限制,并且采取control措施:当OOM时,是否要kill进程。
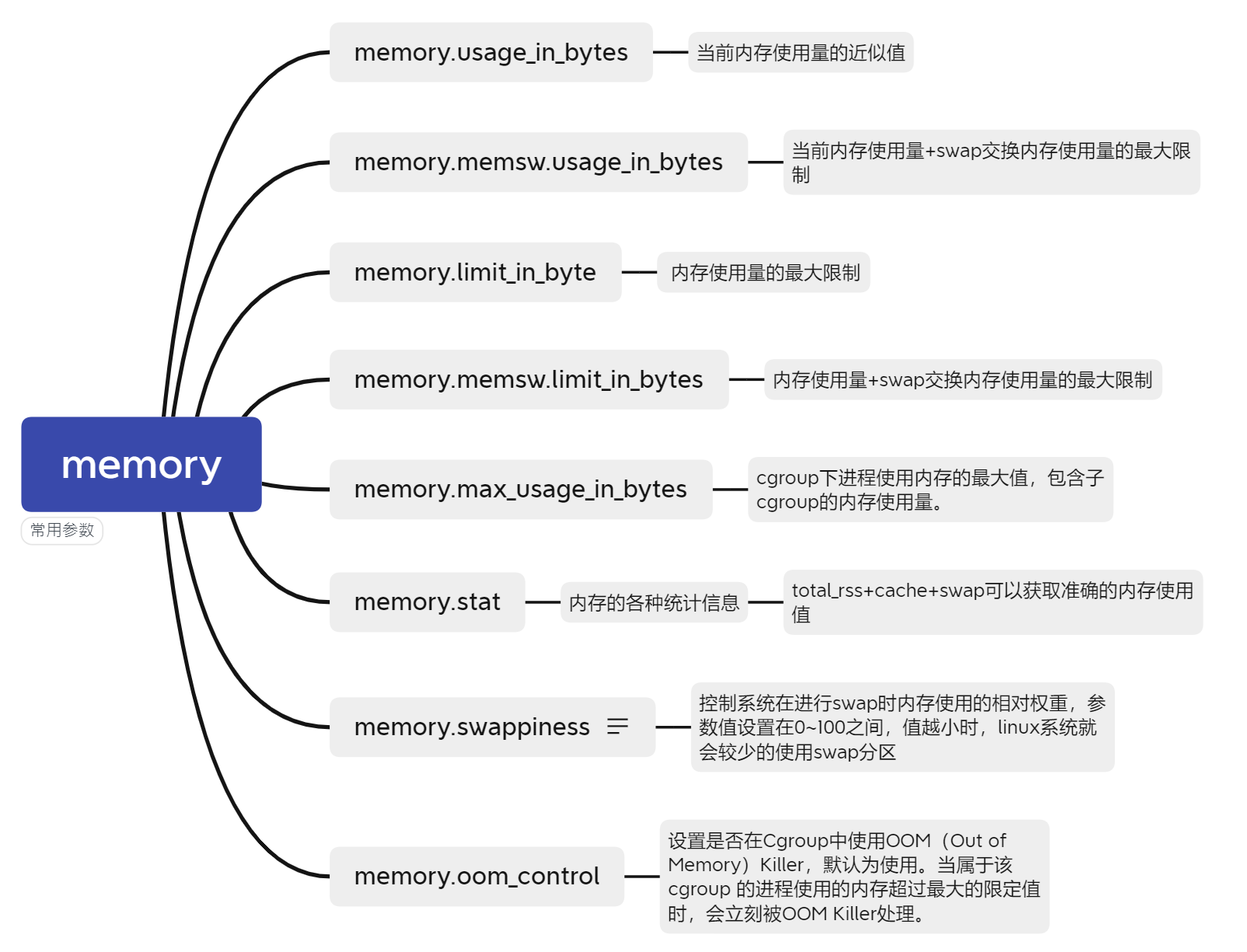
Go语言演示cgroup对memory的限制
编写一个mem.go文件
package main
// 参考《自动动手写Docker》
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path"
"strconv"
"syscall"
)
const CgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
func main() {
if os.Args[0] == "/proc/self/exe" {
fmt.Println("---------- 2 ------------")
fmt.Printf("Current pid: %d\n", syscall.Getpid())
// 创建stress子进程,施加内存压力
allocMemSize := "99m" //
fmt.Printf("allocMemSize: %v\n", allocMemSize)
stressCmd := fmt.Sprintf("stress --vm-bytes %s --vm-keep -m 1", allocMemSize)
cmd := exec.Command("sh", "-c", stressCmd)
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Printf("stress run error: %v", err)
os.Exit(-1)
}
}
fmt.Println("---------- 1 ------------")
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWNS | syscall.CLONE_NEWPID,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// 启动子进程
if err := cmd.Start(); err != nil {
fmt.Printf("/proc/self/exe start error: %v", err)
os.Exit(-1)
}
cmdPid := cmd.Process.Pid
fmt.Printf("cmdPid: %d\n", cmdPid)
// 创建子cgroup
memoryGroup := path.Join(CgroupMemoryHierarchyMount, "test_memory_limit")
os.Mkdir(memoryGroup, 0755)
// 设定内存限制
ioutil.WriteFile(path.Join(memoryGroup, "memory.limit_in_bytes"),
[]byte("100m"), 0644)
// 将进程加入cgroup
ioutil.WriteFile(path.Join(memoryGroup, "tasks"),
[]byte(strconv.Itoa(cmdPid)), 0644)
cmd.Process.Wait()
}
函数解读(在启动时,stress占99M内存,cgroup限制最多使用100M内存)
- 一开始我们使用
go run mem.go
或者go build .
运行时,并不满足if os.Args[0] == "/proc/self/exe"
的条件,所以跳过。 - 然后函数
cmd := exec.Command("/proc/self/exe")创建了一个/proc/self/exe的子进程 - 在
/sys/fs/cgroup/memory/
创建test_memory_limit
文件,设置内存限制为100M - 把子进程加入到task文件中
- 等待子进程结束
- 子进程其实还是当前的程序,不过它的名字为
proc/self/exe
,符合最初的if语句判断,之后会创建stress子进程,然后运行stress。
启动
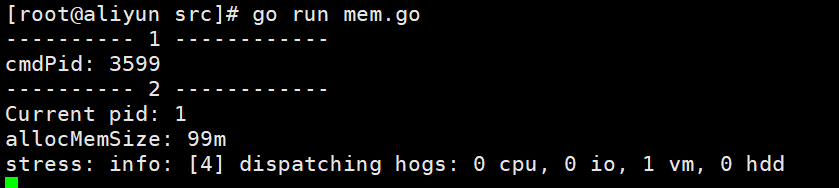
下面进入test_memory_limit目录查看内存最大限制和task,发现内存最大限制与我们设计的一样。
[root@aliyun test_memory_limit]# cat memory.limit_in_bytes 104857600 // 刚好为100M [root@aliyun test_memory_limit]# cat cgroups.proc 3599 // proc/self/exe进程 3602 3603 // stress进程
可以通过top查看资源占有率

cgroup.procs下为cgroup
test_memory_list中的进程,这些是真实的进程,可以通过
pstree -p查看
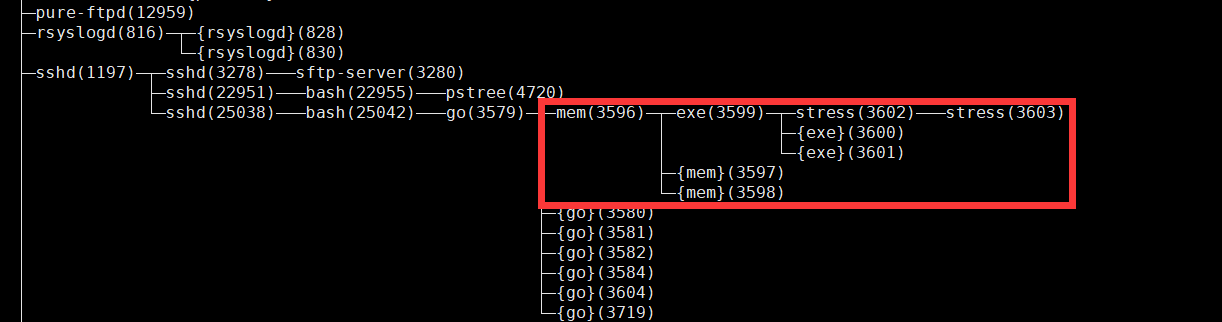
下面看看将stress的内存超过100M的限制,是否会OOM掉。
修改代码,将内存设置为110M,再运行
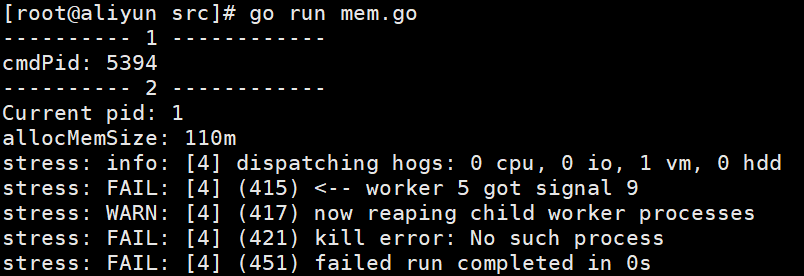
可以发现整个进程直接被KILL -9杀掉了。这就是cgroup对于memory的限制。
Docker演示cgroup限制cpu和memory
# 启动一个nginx镜像 docker run -d --cpu-shares 513 --cpus 0.2 --memory 1024M --memory-swap 1234M --memory-swappiness 7 -p 8081:80 nginx # 参数解析 -d docker容器在后台运行· --cpu-shares 513 表示相对分配的配额 --cpus 0.2 其实就是通过cpu.cfs_period_us和cpu.cfs_quota_us的比率来限制对cpu资源的利用率 --memory 1024 其实就是memory.limit_in_byte --memory-swap 1234M 其实就是memory.memsw.limit_in_byte --memory-swappiness 7 其实就是memory.swappiness -p 8081:80(暴露在外的宿主机端口:nginx端口) # 查看容器id f4437f9db69d
下面我们进入cgroup下cpu子系统中可以发现有一个docker文件,进入docker文件中可以看到以刚才容器id命名的文件夹

进入该文件夹下,可以发现与我们之前的test.go案例非常一致。
刚刚docker启动时配置的参数
--cpu-shares 513能在
cpu.shares文件中体现
而参数
--cpus 0.2就是
cpu.cfs_quota_us和
cpu.cfs_period_us的比率。

同理进入cgroup下memory子系统中也可以发现一个docker文件,与之对应也有一个容器id命名的文件夹
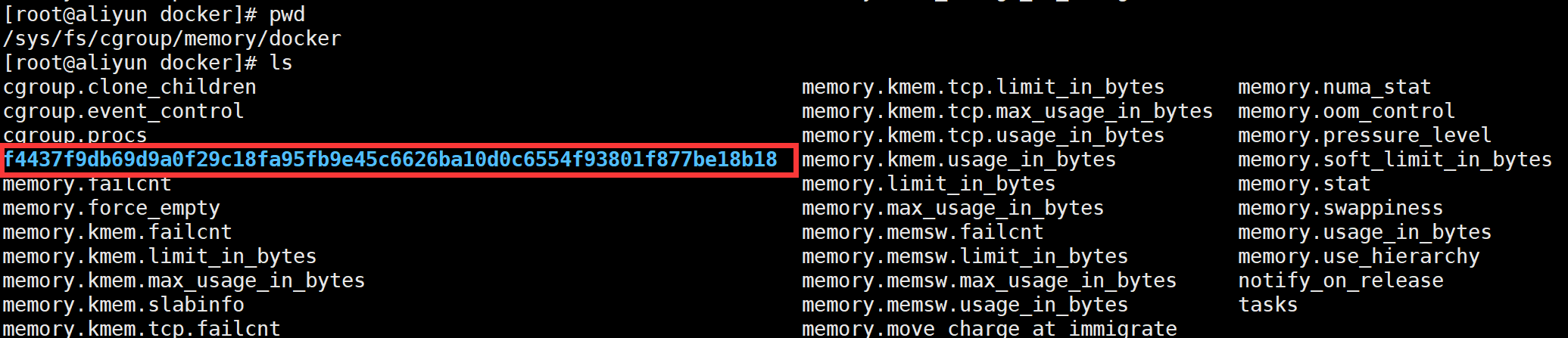
进入该文件夹下,查看与docker参数相对于的配置信息
docker启动时配置的参数
--memory 1024能在
memory.limit_in_bytes中体现
而参数
--memory-swap 1234M能在
memory.memsw.limit_in_byte中体现
参数
--memory-swappiness 7能在
memory.swappiness中体现

以上就是对于cgroup中最重要的两个子系统
cpu子系统和
memory子系统进行分析~
Union FS
Docker镜像里面其实是一层层的文件系统,叫做Union FS(联合文件系统),UnionFS可以将几层目录挂载到一起,形成一个虚拟文件系统。(举个简单的例子:我们有两个文件夹a和b,a文件夹下又包含a1.txt a2.txt,b文件夹下又包含b1.txt b2.txt,我们通过创建一个新的文件夹c,通过Union FS就可以在c文件夹下访问到a1.txt a2.txt b1.txt b2.txt,这样就把a,b两个文件夹联合起来了)
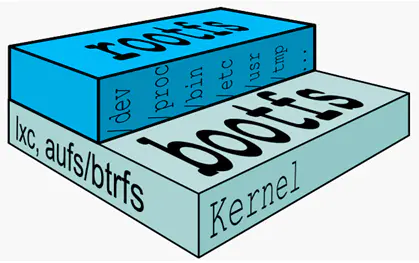
从基本看一个典型的Linux文件系统由
bootfs和
rootfs两部分组成:
**bootfs(boot file system)**主要包含bootloader和kernel,bootloader主要引导加载kernel,linux刚启动时会加载bootfs文件系统,当boot加载完成之后整个内核就都在内存中了,内存的使用权已由bootfs转交给内核,此时bootfs会被umount掉。在Docker镜像的最底层就是bootfs。
**rootfs(root file system)**在bootfs之上,包含的就是典型的Linux系统中的/dev、/proc、/bin、/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,CentOS等。
Mount命令实现联合文件系统案例
# 创建文件夹 [root@aliyun uniontest]# mkdir lower upper merge work # 在lower和upper文件下内写入文件 [root@aliyun uniontest]# echo "from lower" > lower/in_lower.txt [root@aliyun uniontest]# echo "from upper" > upper/in_upper.txt [root@aliyun uniontest]# echo "from lower" > lower/in_both.txt [root@aliyun uniontest]# echo "from upper" > upper/in_both.txt # 使用mount命令挂载 [root@aliyun uniontest]# mount -t overlay overlay -o lowerdir=lower/,upperdir=upper/,workdir=work merge # 查看联合挂载后的文件 [root@aliyun uniontest]# tree . ├── lower │ ├── in_both.txt │ └── in_lower.txt ├── merge │ ├── in_both.txt │ ├── in_lower.txt │ └── in_upper.txt ├── upper │ ├── in_both.txt │ └── in_upper.txt └── work └── work 5 directories, 7 files # 可以看到显示的是upper层 [root@aliyun uniontest]# cat merge/in_both.txt from upper
Overlay2
先来区分几个概念。
- OverlayFS 指的是 Linux 的内核驱动
- overlay/overlay2 指的是 Docker 的存储驱动。
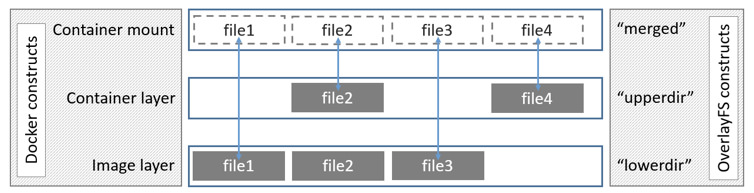
在上述图中可以看到三个层结构,即:
lowerdir、
upperdir、
merged,其中lowerdir是只读的image layer,其实就是rootfs。image layer可以分很多层,所以对应的lowerdir是可以有多个目录。而upperdir则是在lowerdir之上的一层,这层是读写层,在启动一个容器时候会进行创建,所有的对容器数据更改都发生在这里层。最后merged目录是容器的挂载点,也就是给用户暴露的统一视角。而这些目录层都保存在了/var/lib/docker/overlay2/
下面我们从下载一个容器进行分析,可以发现只有一层文件

下面进入
/var/lib/docker/overlay2中查看,可以发现确实只有一层文件

小写的
l文件夹是对这层的符号连接,只是为了减少
mount参数可能达到的限制作用

进入到
e757开头的文件夹中查看,可以发现
diff文件夹中是当前层的镜像内容,
link文件中是短名称

下面启动一个镜像后再进行查看可以发现多了两层文件


下面查看一下联合挂载的情况,我们可以看出,overlay2将
lowerdir、
upperdir、
workdir联合挂载,形成最终的
merged挂载点,其中
lowerdir是镜像只读层,
upperdir是容器可读可写层,
workdir是执行涉及修改
lowerdir执行
copy_up操作的中转层(例如,
upperdir中不存在,需要从
lowerdir中进行复制)

根据这个挂载我们可以分析一下挂载过程:
首先
VKYIMVSFFSVOAWCBIZZQ6RNFB4
短链接对应的是8cbdc1ab4a0567cf7841b3a6326bbbec185850b56dff309a572a6cff5be7742f-init/diff
镜像配置文件夹(标记为①)4LISVLHRVBORTVPCSNCJHBMVSZ
短链接对应的是e75746dca68dcf02f7fd5dc90a5828066c4d66ab8e6719030362e546e98bdc62/diff
镜像文件夹(标记为②)且①和②都是属于lowerdir
层,只读层。查看①中的信息
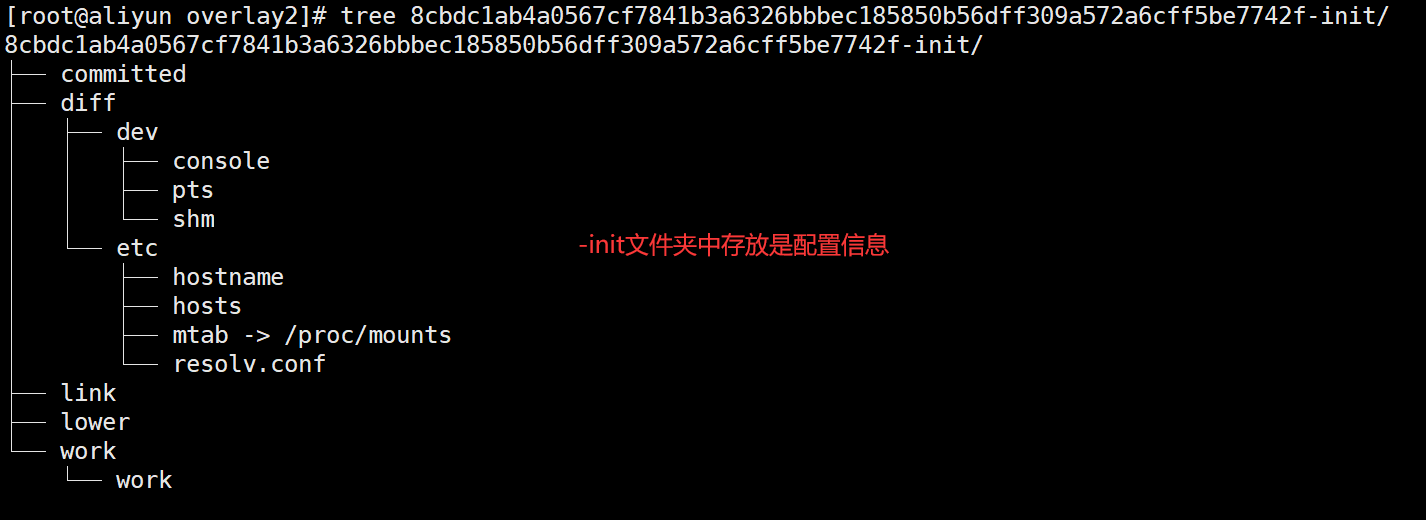
可以看到
diff文件中的内容
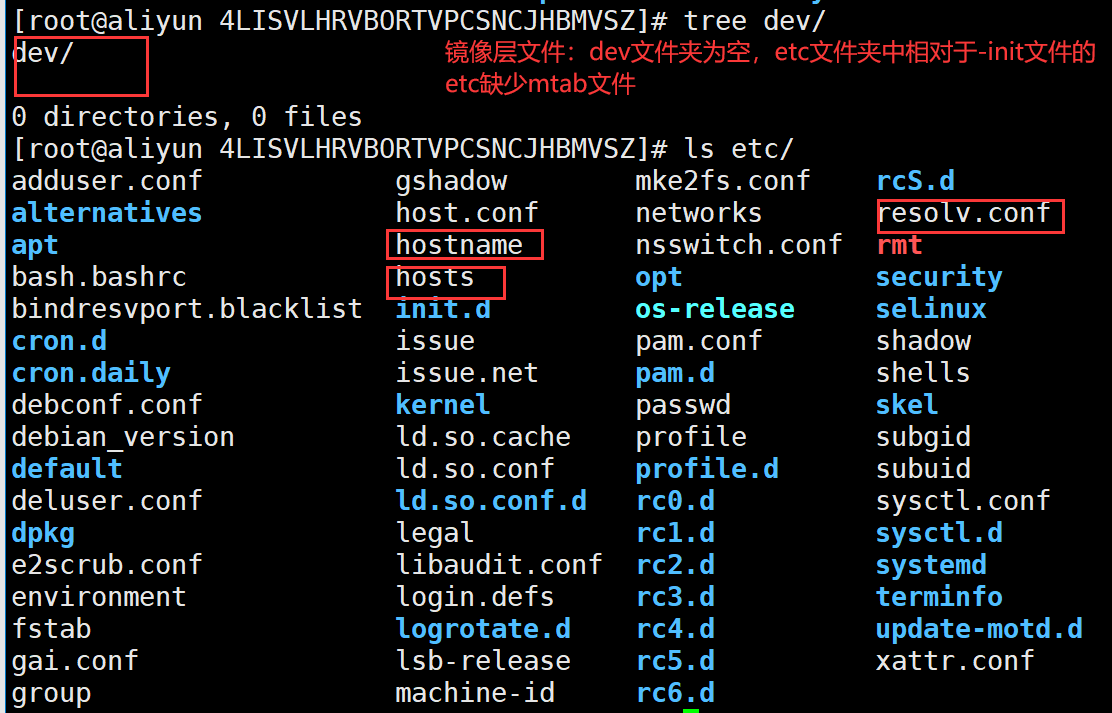
- 查看②中对应
dev
和etc
文件夹中的信息
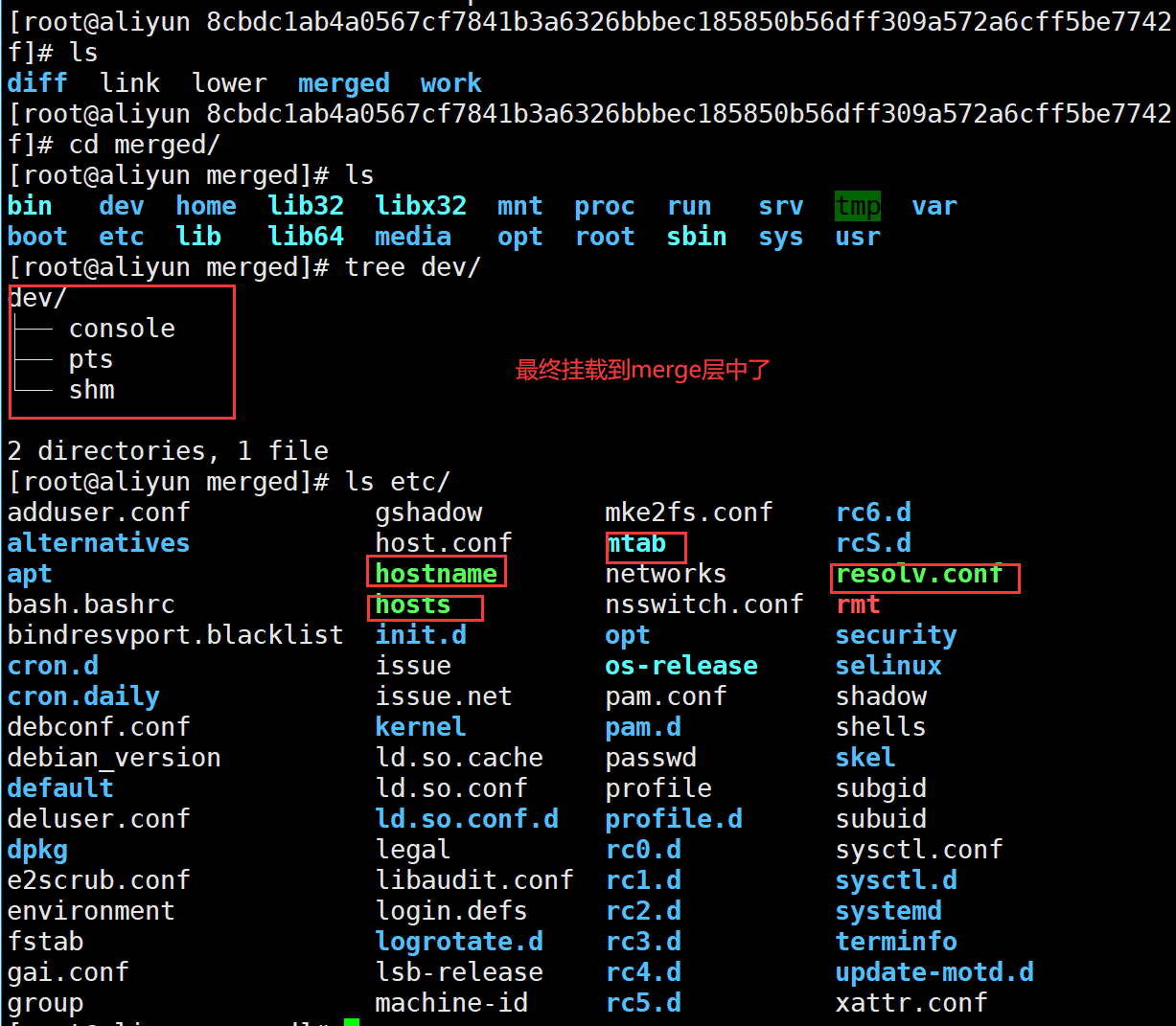
- 最后查看
upperdir
和merged
的文件
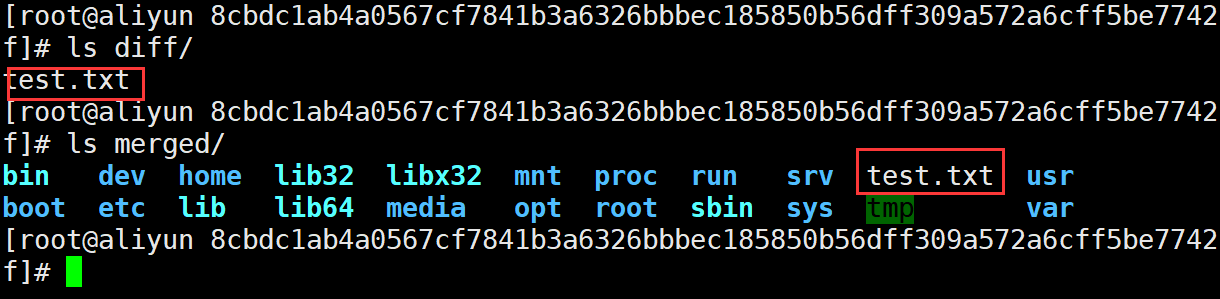
 下面我们再做个测试,进入刚刚启动的ubuntu容器中,创建一个test.txt文件
下面我们再做个测试,进入刚刚启动的ubuntu容器中,创建一个test.txt文件

接下来我们查看容器的容器的可读写层,可以在容器层本身存放内容的
diff文件夹和
merged文件夹文件中都可以看到
test.txt。而在镜像的只读层却没有看到,说明分析的是正确的。

总结
以上就是对Docker核心的三个技术进行的分析操作,花费了大概三四天的时间,不过对于个人来说还是很有收获的,以前对于这些也听过,但是了解不是很深入,这次强迫自己认真的去学习一番,希望日后都可以进入这种深入的学习。文章可能有点长~哈哈
有问题的地方,希望大家多多指正,我会加以更改的~
参考文档:
https://staight.github.io/2019/09/23/nsenter%E5%91%BD%E4%BB%A4%E7%AE%80%E4%BB%8B/
https://www.geek-share.com/detail/2685420622.html
https://wudaijun.com/2018/10/linux-cgroup/
https://lessisbetter.site/2020/09/01/cgroup-3-cpu-md/
https://lessisbetter.site/2020/08/30/cgroup-2-memory/
https://www.jianshu.com/p/274af1c0163e
https://zhuanlan.zhihu.com/p/41958018
https://www.cnblogs.com/wdliu/p/10483252.html
《趣谈Linux操作系统》 本文由博客一文多发平台 OpenWrite 发布!

- java核心技术复习笔记(三)
- 听昝辉ZAC的讲座:剖析SEO核心技术
- 什么才是核心技术?
- java 核心技术 第三章之后总结
- Spring 深入浅出核心技术 (一)
- 【下一代核心技术DevOps】:(六)Rancher集中存储及相关应用
- Java中的四个核心技术思想
- Spring核心技术(十三)——环境的抽象
- 2018最新 Spring Boot 2.0深度实践之核心技术篇
- Java核心技术(第8版)学习笔记_接口与内部类
- 大数据分析你不能不懂的6个核心技术
- Hibernate 核心技术(三)
- OpenGL核心技术之延迟着色器提升版
- Java核心技术点之内部类
- java核心技术1笔记-01
- 技术管理的核心内容 — 提高团队技能 2014-07-02 11:59 323人阅读 评论(0) 收藏
- [企业大脑智能决策中枢系统]3. 政企数字化转型的核心技术
- 测试的核心技术是什么?
- 《这就是搜索引擎-核心技术详解》简单梳理+一些知识图谱的知识
- 技术人员谈管理之项目群的核心特征