etcd学习(7)-etcd中的线性一致性实现
线性一致性
CAP
什么是CAP
在聊什么是线性一致性的时候,我们先来看看什么是CAP
CAP理论:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- 1、一致性(Consistency)
一致性表示所有客户端同时看到相同的数据,无论它们连接到哪个节点。 要做到这一点,每当数据写入一个节点时,就必须立即将其转发或复制到系统中的所有其他节点,然后写操作才被视为“成功”。
- 2、可用性(Availability)
可用性表示发出数据请求的任何客户端都会得到响应,即使一个或多个节点宕机。 可用性的另一种状态:分布式系统中的所有工作节点都返回任何请求的有效响应,而不会发生异常。
- 3、分区容错性(Partition tolerance)
分区是分布式系统中的通信中断 - 两个节点之间的丢失连接或连接临时延迟。 分区容错意味着集群必须持续工作,无论系统中的节点之间有任何数量的通信中断。
CAP的权衡
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。
AP wihtout C
允许分区下的高可用,就需要放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
CA without P
如果不会出现分区,一直性和可用性是可以同时保证的。但是我们现在的系统基本上是都是分布式的,也就是我们的服务肯定是被多台机器所提供的,所以分区就难以避免。
CP without A
如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。
线性一致性
线性一致性又叫做原子一致性,强一致性。线性一致性可以看做只有一个单核处理器,或者可以看做只有一个数据副本,并且所有操作都是原子的。在可线性化的分布式系统中,如果某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据。可以看见线性一致性和我们的CAP中的C是一致的。
举个非线性一致性的例子,比如有个秒杀活动,你和你的朋友同时去抢购一样东西,有可能他那里的库存已经没了,但是在你手机上显示还有几件,这个就违反了线性一致性,哪怕过了一会你的手机也显示库存没有,也依然是违反了。
etcd中如何实现线性一致性
线性一致性写
所有的写操作,都要经过leader节点,一旦leader被选举成功,就可以对客户端提供服务了。客户端提交每一条命令都会被按顺序记录到leader的日志中,每一条命令都包含term编号和顺序索引,然后向其他节点并行发送AppendEntries RPC用以复制命令(如果命令丢失会不断重发),当复制成功也就是大多数节点成功复制后,leader就会提交命令,即执行该命令并且将执行结果返回客户端,raft保证已经提交的命令最终也会被其他节点成功执行。具体源码参见日志同步
因为日志是顺序记录的,并且有严格的确认机制,所以可以认为写是满足线性一致性的。
由于在Raft算法中,写操作成功仅仅意味着日志达成了一致(已经落盘),而并不能确保当前状态机也已经apply了日志。状态机apply日志的行为在大多数Raft算法的实现中都是异步的,所以此时读取状态机并不能准确反应数据的状态,很可能会读到过期数据。
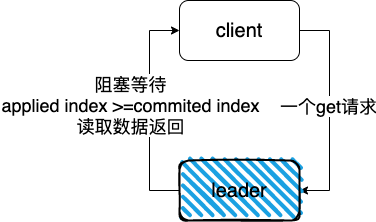
如何实现读取的线性一致性,就需要引入ReadIndex了
线性一致性读
ReadIndex算法:
每次读操作的时候记录此时集群的
commited index,当状态机的
apply index大于或等于
commited index时才读取数据并返回。由于此时状态机已经把读请求发起时的已提交日志进行了apply动作,所以此时状态机的状态就可以反应读请求发起时的状态,符合线性一致性读的要求。
Leader执行ReadIndex大致的流程如下:
- 1、记录当前的commit index,称为ReadIndex;
所有的请求都会交给leader,如果follower收到读请求,会将请求forward给leader
- 2、向 Follower 发起一次心跳,如果大多数节点回复了,那就能确定现在仍然是Leader;
确认当前leader的状态,避免当前节点状态切换,数据不能及时被同步更新
比如发生了网络分区:可参见网络分区问题
1、当前的leader被分到了小的分区中,然后大的集群中有数据更新,小的集群是无感知的,如果读的请求被定位到小的集群中,所以读取就可能读取到旧的数据。
2、小集群中的数据同样是不能被写入信息的,提交给该集群的指令对应的日志因不满足过半数的条件而无法被提交。
3、说以只有当前节点是集群中有效的leader才可以,也就是能收到大多数节点的回复信息。
- 3、等待状态机的apply index大于或等于commited index时才读取数据;
apply index大于或等于
commited index就能表示当前状态机已经把读请求发起时的已提交日志进行了apply动作,所以此时状态机的状态就可以反应读请求发起时的状态,满足一致性读;
- 4、执行读请求,将结果返回给Client。
进一步来看下etcd的源码是如何实现的呢
1、客户端的get请求
func (kv *kv) Get(ctx context.Context, key string, opts ...OpOption) (*GetResponse, error) {
r, err := kv.Do(ctx, OpGet(key, opts...))
return r.get, toErr(ctx, err)
}
// OpGet returns "get" operation based on given key and operation options.
func OpGet(key string, opts ...OpOption) Op {
// WithPrefix and WithFromKey are not supported together
if IsOptsWithPrefix(opts) && IsOptsWithFromKey(opts) {
panic("`WithPrefix` and `WithFromKey` cannot be set at the same time, choose one")
}
ret := Op{t: tRange, key: []byte(key)}
ret.applyOpts(opts)
return ret
}
func (kv *kv) Do(ctx context.Context, op Op) (OpResponse, error) {
var err error
switch op.t {
case tRange:
var resp *pb.RangeResponse
resp, err = kv.remote.Range(ctx, op.toRangeRequest(), kv.callOpts...)
if err == nil {
return OpResponse{get: (*GetResponse)(resp)}, nil
}
...
}
return OpResponse{}, toErr(ctx, err)
}
func (c *kVClient) Range(ctx context.Context, in *RangeRequest, opts ...grpc.CallOption) (*RangeResponse, error) {
out := new(RangeResponse)
err := c.cc.Invoke(ctx, "/etcdserverpb.KV/Range", in, out, opts...)
if err != nil {
return nil, err
}
return out, nil
}
service KV {
// Range gets the keys in the range from the key-value store.
rpc Range(RangeRequest) returns (RangeResponse) {
option (google.api.http) = {
post: "/v3/kv/range"
body: "*"
};
}
}
可以看到get的请求最终通过通过rpc发送到Range
2、服务端响应读取请求
// etcd/server/etcdserver/v3_server.go
func (s *EtcdServer) Range(ctx context.Context, r *pb.RangeRequest) (*pb.RangeResponse, error) {
...
// 判断是否需要serializable read
// Serializable为true表示需要serializable read
// serializable read 会直接读取当前节点的数据返回给客户端,它并不能保证返回给客户端的数据是最新的
// Serializable为false表示需要linearizable read
// Linearizable Read 需要阻塞等待直到读到最新的数据
if !r.Serializable {
err = s.linearizableReadNotify(ctx)
trace.Step("agreement among raft nodes before linearized reading")
if err != nil {
return nil, err
}
}
...
return resp, err
}
// etcd/server/etcdserver/v3_server.go
func (s *EtcdServer) linearizableReadNotify(ctx context.Context) error {
s.readMu.RLock()
nc := s.readNotifier
s.readMu.RUnlock()
// linearizableReadLoop会阻塞监听readwaitc
// 这边写入一个空结构体到readwaitc中,linearizableReadLoop就会开始结束阻塞开始工作
select {
case s.readwaitc <- struct{}{}:
default:
}
// wait for read state notification
select {
case <-nc.c:
return nc.err
case <-ctx.Done():
return ctx.Err()
case <-s.done:
return ErrStopped
}
}
// start会启动一个linearizableReadLoop
func (s *EtcdServer) Start() {
...
s.GoAttach(s.linearizableReadLoop)
...
}
// etcd/server/etcdserver/v3_server.go
func (s *EtcdServer) linearizableReadLoop() {
for {
requestId := s.reqIDGen.Next()
leaderChangedNotifier := s.LeaderChangedNotify()
select {
case <-leaderChangedNotifier:
continue
// 在client发起一次Linearizable Read的时候,会向readwaitc写入一个空的结构体作为信号
case <-s.readwaitc:
case <-s.stopping:
return
}
...
// 处理不同的消息
// 这里会监听readwaitc,等待MsgReadIndex信息的处理结果
// 同时获取当前已提交的日志索引
confirmedIndex, err := s.requestCurrentIndex(leaderChangedNotifier, requestId)
if isStopped(err) {
return
}
if err != nil {
nr.notify(err)
continue
}
...
// 此处是重点
// 等待 apply index >= read index
if appliedIndex < confirmedIndex {
select {
case <-s.applyWait.Wait(confirmedIndex):
case <-s.stopping:
return
}
}
// 发出可以进行读取状态机的信号
nr.notify(nil)
...
}
}
总结:
服务端对于读的操作,如果是Linearizable Read,也就是线性一致性的读,最终会通过linearizableReadLoop,监听readwaitc来触发,阻塞直到
apply index >= read index,最终发送可以读取的信息。
3、raft中如何处理一个读的请求
linearizableReadLoop收到readwaitc,最终会调用sendReadIndex
// etcd/server/etcdserver/v3_server.go
func (s *EtcdServer) sendReadIndex(requestIndex uint64) error {
...
err := s.r.ReadIndex(cctx, ctxToSend)
...
return nil
}
// etcd/raft/node.go
func (n *node) ReadIndex(ctx context.Context, rctx []byte) error {
return n.step(ctx, pb.Message{Type: pb.MsgReadIndex, Entries: []pb.Entry{{Data: rctx}}})
}
通过MsgReadIndex的消息来发送读的请求
如果follower收到了客户端的MsgReadIndex类型的消息,因为客户端不能处理只读请求,需要将消息转发到leader节点进行处理;
如果是leader收到了MsgReadIndex;
1、如果消息来自客户端,直接写入到readStates,start函数会将readStates中最后的一个放到readStateC,通知上游的处理结果;
2、如果消息来自follower,通过消息MsgReadIndexResp回复follower的响应结果,同时follower也是会将readStates中最后的一个放到readStateC,通知上游的处理结果;
上面的linearizableReadLoop监听readStateC,当收到请求,获取当前leader已经提交的日志索引,然后等待直到状态机已应用索引 (applied index) 大于等于 Leader 的已提交索引时 (committed Index),然后去通知读请求,数据已赶上 Leader,就可以去状态机中访问数据了,处理数据返回给客户端
我们知道ReadIndex算法中,leader节点需要,向follower节点发起心跳,确认自己的leader地位,具体的就是通过ReadOnly来实现,下面会一一介绍到
如果follower收到只读的消息
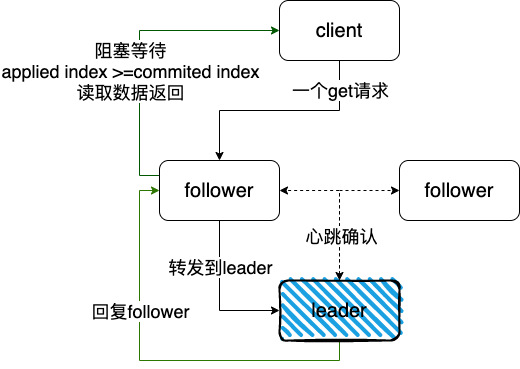
follower会将消息转发到leader
// etcd/raft/raft.go
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
...
case pb.MsgReadIndex:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping index reading msg", r.id, r.Term)
return nil
}
// 目标为leader
m.To = r.lead
// 转发信息
r.send(m)
}
...
return nil
}
再来看下leader是如何处理的
// etcd/raft/raft.go
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
case pb.MsgReadIndex:
...
sendMsgReadIndexResponse(r, m)
return nil
}
return nil
}
// raft结构体中的readOnly作用是批量处理只读请求,只读请求有两种模式,分别是ReadOnlySafe和ReadOnlyLeaseBased
// ReadOnlySafe是ETCD作者推荐的模式,因为这种模式不受节点之间时钟差异和网络分区的影响
// 线性一致性读用的就是ReadOnlySafe
func sendMsgReadIndexResponse(r *raft, m pb.Message) {
switch r.readOnly.option {
// If more than the local vote is needed, go through a full broadcast.
case ReadOnlySafe:
// 清空readOnly中指定消息ID及之前的所有记录
// 开启leader向follower的确认机制
r.readOnly.addRequest(r.raftLog.committed, m)
// recvAck通知只读结构raft状态机已收到对附加只读请求上下文的心跳信号的确认。
// 也就是记录下只读的请求
r.readOnly.recvAck(r.id, m.Entries[0].Data)
// leader 节点向其他节点发起广播
r.bcastHeartbeatWithCtx(m.Entries[0].Data)
case ReadOnlyLeaseBased:
if resp := r.responseToReadIndexReq(m, r.raftLog.committed); resp.To != None {
r.send(resp)
}
}
}
这里省略follower对leader节点的心跳回应,直接看leader对心跳回执的信息处理
func stepLeader(r *raft, m pb.Message) error {
// All other message types require a progress for m.From (pr).
pr := r.prs.Progress[m.From]
if pr == nil {
r.logger.Debugf("%x no progress available for %x", r.id, m.From)
return nil
}
switch m.Type {
case pb.MsgHeartbeatResp:
...
if r.readOnly.option != ReadOnlySafe || len(m.Context) == 0 {
return nil
}
// 判断leader有没有收到大多数节点的确认
// 也就是ReadIndex算法中,leader节点得到follower的确认,证明自己目前还是Leader
if r.prs.Voters.VoteResult(r.readOnly.recvAck(m.From, m.Context)) != quorum.VoteWon {
return nil
}
// 收到了响应节点超过半数,会清空readOnly中指定消息ID及之前的所有记录
rss := r.readOnly.advance(m)
// 返回follower的心跳回执
for _, rs := range rss {
if resp := r.responseToReadIndexReq(rs.req, rs.index); resp.To != None {
r.send(resp)
}
}
}
return nil
}
// responseToReadIndexReq 为 `req` 构造一个响应。如果`req`来自对等方
// 本身,将返回一个空值。
func (r *raft) responseToReadIndexReq(req pb.Message, readIndex uint64) pb.Message {
// 通过from来判断该消息是否是follower节点转发到leader中的
...
// 如果是其他follower节点转发到leader节点的MsgReadIndex消息
// leader会回向follower节点返回响应的MsgReadIndexResp消息,follower会响应给client
return pb.Message{
Type: pb.MsgReadIndexResp,
To: req.From,
Index: readIndex,
Entries: req.Entries,
}
}
然后follower收到响应,将MsgReadIndex消息中的已提交位置和消息id封装成ReadState实例,添加到readStates
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgReadIndexResp:
if len(m.Entries) != 1 {
r.logger.Errorf("%x invalid format of MsgReadIndexResp from %x, entries count: %d", r.id, m.From, len(m.Entries))
return nil
}
// 将MsgReadIndex消息中的已提交位置和消息id封装成ReadState实例,添加到readStates
// raft 模块也有一个 for-loop 的 goroutine,来读取该数组,并对MsgReadIndex进行响应
r.readStates = append(r.readStates, ReadState{Index: m.Index, RequestCtx: m.Entries[0].Data})
}
return nil
}
raft 模块有一个for-loop的goroutine,来读取该数组,并对MsgReadIndex进行响应,将ReadStates中的最后一项将写入到readStateC中,通知监听readStateC的linearizableReadLoop函数的结果。
// etcd/server/etcdserver/raft.goetcd/raft/node.go
func (r *raftNode) start(rh *raftReadyHandler) {
internalTimeout := time.Second
go func() {
defer r.onStop()
islead := false
for {
select {
case rd := <-r.Ready():
...
if len(rd.ReadStates) != 0 {
select {
// ReadStates中最后意向将会被写入到readStateC中
// linearizableReadLoop会监听readStateC,获取MsgReadIndex的处理信息
case r.readStateC <- rd.ReadStates[len(rd.ReadStates)-1]:
case <-time.After(internalTimeout):
r.lg.Warn("timed out sending read state", zap.Duration("timeout", internalTimeout))
case <-r.stopped:
return
}
}
...
}
}
}()
}
如果leader收到只读请求
func stepLeader(r *raft, m pb.Message) error {
// All other message types require a progress for m.From (pr).
pr := r.prs.Progress[m.From]
if pr == nil {
r.logger.Debugf("%x no progress available for %x", r.id, m.From)
return nil
}
switch m.Type {
case pb.MsgReadIndex:
// 表示当前只有一个节点,当前节点就是leader
if r.prs.IsSingleton() {
if resp := r.responseToReadIndexReq(m, r.raftLog.committed); resp.To != None {
r.send(resp)
}
return nil
}
...
return nil
}
return nil
}
// responseToReadIndexReq 为 `req` 构造一个响应。如果`req`来自对等方
// 本身,将返回一个空值。
func (r *raft) responseToReadIndexReq(req pb.Message, readIndex uint64) pb.Message {
// 通过from来判断该消息是否是follower节点转发到leader中的
// 如果是客户端直接发到leader节点的消息,将MsgReadIndex消息中的已提交位置和消息id封装成ReadState实例,添加到readStates
// raft 模块也有一个 for-loop 的 goroutine,来读取该数组,并对MsgReadIndex进行响应
if req.From == None || req.From == r.id {
r.readStates = append(r.readStates, ReadState{
Index: readIndex,
RequestCtx: req.Entries[0].Data,
})
return pb.Message{}
}
...
}
如果当前只有一个节点,那么当前的节点也是leader节点,所有的只读请求,将会发送到leader,leader直接对信息进行处理
如何从状态机中访问数据了,就需要了解下MVCC了
MVCC
Multiversion concurrency control简称MVCC。这个模块是为了解决 etcd v2 不支持保存 key 的历史版本、不支持多 key 事务等问题而产生的。
它核心由内存树形索引模块 (treeIndex) 和嵌入式的 KV 持久化存储库 boltdb 组成。
那么 etcd 如何基于 boltdb 保存一个 key 的多个历史版本呢?
每次修改操作,生成一个新的版本号 (revision),以版本号为 key, value 为用户 key-value 等信息组成的结构体。boltdb 的 key 是全局递增的版本号 (revision),value 是用户 key、value 等字段组合成的结构体,然后通过 treeIndex 模块来保存用户 key 和版本号的映射关系。
treeIndex 与 boltdb 关系如下面的读事务流程图所示,从 treeIndex 中获取 key hello 的版本号,再以版本号作为 boltdb 的 key,从 boltdb 中获取其 value 信息。
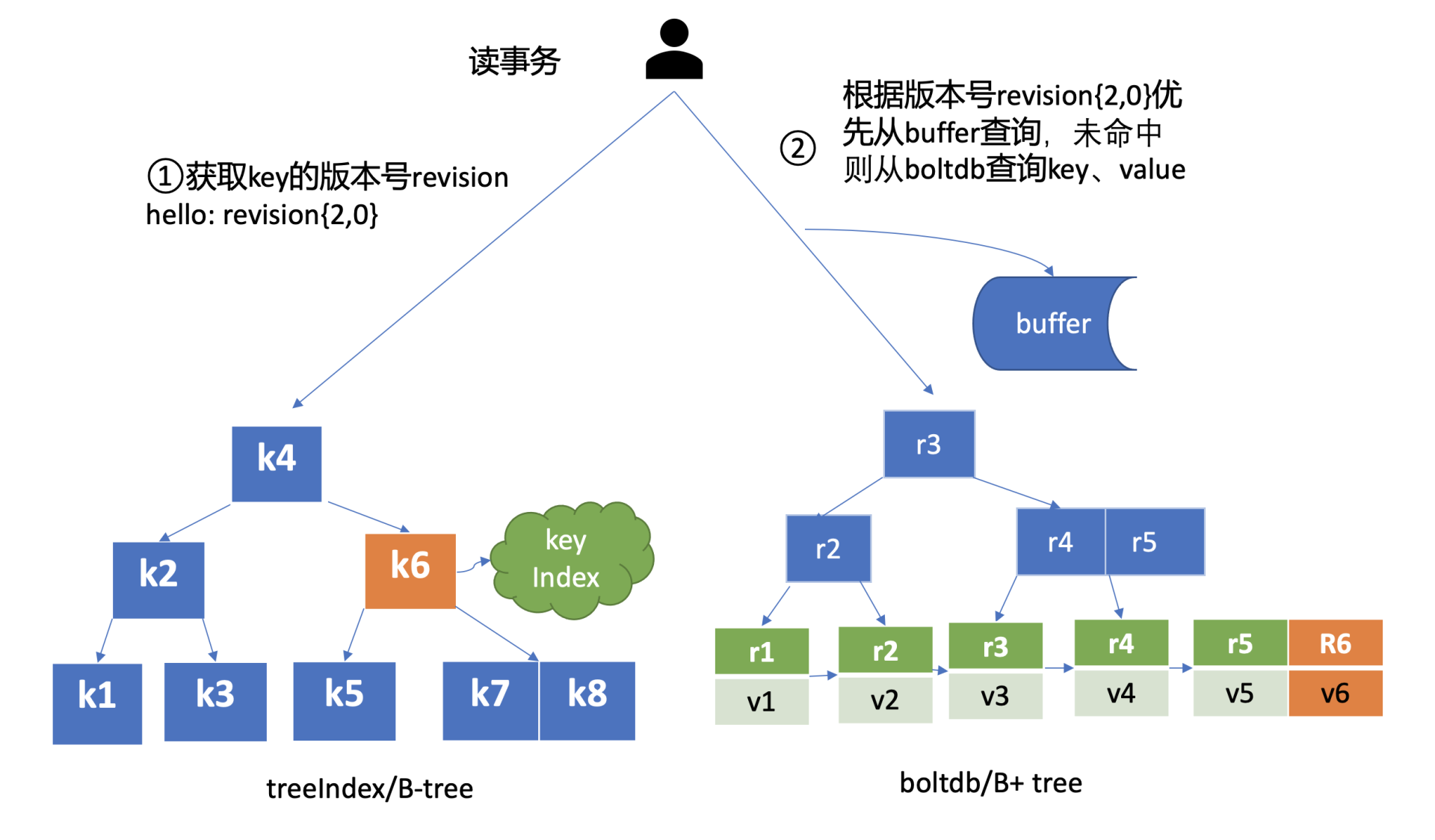
treeIndex
treeIndex 模块是基于 Google 开源的内存版 btree 库实现的
treeIndex 模块只会保存用户的 key 和相关版本号信息,用户 key 的 value 数据存储在 boltdb 里面,相比 ZooKeeper 和 etcd v2 全内存存储,etcd v3 对内存要求更低。
buffer
在获取到版本号信息后,就可从 boltdb 模块中获取用户的 key-value 数据了。不过有一点你要注意,并不是所有请求都一定要从 boltdb 获取数据。etcd 出于数据一致性、性能等考虑,在访问 boltdb 前,首先会从一个内存读事务 buffer 中,二分查找你要访问 key 是否在 buffer 里面,若命中则直接返回。
boltdb
boltdb 使用 B+ tree 来组织用户的 key-value 数据,获取 bucket key 对象后,通过 boltdb 的游标 Cursor 可快速在 B+ tree 找到 key hello 对应的 value 数据,返回给 client。
总结
etcd中对于写的请求,因为所有的写请求都是通过leader的,leader的确认机制将会保证消息复制到大多数节点中;
对于只读的请求,同样也是需要全部转发到leader节点中,通过ReadIndex算法,来实现线性一致性读;
raft执行ReadIndex大致的流程如下:
1、记录当前的commit index,称为ReadIndex;
2、向Follower发起一次心跳,如果大多数节点回复了,那就能确定现在仍然是Leader;
3、等待状态机的apply index大于或等于commited index时才读取数据;
4、执行读请求,将结果返回给Client。
关于状态机数据的读取,首先从treeIndex获取版本号,然后在buffer是否有对应的值,没有就去boltdb查询对应的值
参考
【CAP定理】https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
【CAP定理】https://www.ibm.com/cn-zh/cloud/learn/cap-theorem
【线性一致性:什么是线性一致性?】https://zhuanlan.zhihu.com/p/42239873
【什么是数据一致性】https://github.com/javagrowing/JGrowing/blob/master/%E5%88%86%E5%B8%83%E5%BC%8F/%E8%B0%88%E8%B0%88%E6%95%B0%E6%8D%AE%E4%B8%80%E8%87%B4%E6%80%A7.md
【etcd 中线性一致性读的具体实现】https://zhengyinyong.com/post/etcd-linearizable-read-implementation/

- 数据结构学习---线性表的单链表实现
- java学习笔记4>顺序线性表的实现及其内存分配
- 学习笔记(1):视觉应用--机器学习&深度学习基础-线性回归的Keras实现03-损失函数、梯度下降和评价指标...
- 数据结构学习---线性表的链式存储实现(双向链表)
- 线性判别分析(Linear Discriminant Analysis, LDA) 学习笔记 + matlab实现
- Android学习系列(二)布局管理器之线性布局的3种实现方式
- 斯坦福CS231n 课程学习笔记--线性分类器(Assignment1代码实现)
- 数据结构学习笔记-线性表顺序存储(C语言实现)
- 《动手学深度学习》用PyCharm实现 学习笔记(2)3.2线性回归的从零开始实现
- 数据结构学习----线性表的链式表示(Java实现)
- 学习日志---线性回归实现
- 机器学习实战笔记(Python实现)-08-线性回归
- 【Java数据结构学习笔记之一】线性表的存储结构及其代码实现
- 学习笔记——线性表的动态分配顺序存储结构基本操作(C语言实现)
- 转载学习一篇线性表的java实现
- 4.2 模型之母:简单线性回归的代码实现学习笔记
- 【动手学深度学习pytorch版笔记NO.3】3.2 线性回归的从零开始实现
- 【算法学习】线性时间排序-计数排序、基数排序和桶排序详解与编程实现
- 数据结构学习笔录——线性表的实现
- 线性表学习归纳总结二:线性表顺序存储实现