Redis-初见
[TOC]
启动and连接
启动 用的是配置文件启动
redis-server .../redis.conf
redis-cli -p 6379
[root@LJT redis]# redis-server redis.conf [root@LJT redis]# redis-cli -p 6379 127.0.0.1:6379> exit [root@LJT redis]# pwd /www/server/redis 用的是宝塔,默认在www用户下
关机
SHUTDOWN
JRedis
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.2.0</version> </dependency>
宝塔
我用的aliyun的www 宝塔的 redis 位置
cd /www/server/redis
Redis.conf
单位 配置文件对大小写不敏感 # 1k => 1000 bytes # 1kb => 1024 bytes # 1m => 1000000 bytes # 1mb => 1024*1024 bytes # 1g => 1000000000 bytes # 1gb => 1024*1024*1024 bytes ………… 包含 # include /path/to/local.conf # include /path/to/other.conf ………… bind 127.0.0.1 绑定的ip protected-mode yes 保护模式 port 6379 端口 ################################# GENERAL ##################################### daemonize yes 守护进程方式运行,默认no pidfile /www/server/redis/redis.pid 如果以后台方式运行,要指定pid # Specify the server verbosity level. # This can be one of: # debug (a lot of information, useful for development/testing) # verbose (many rarely useful info, but not a mess like the debug level) # notice (moderately verbose, what you want in production probably)默认,生产环境 # warning (only very important / critical messages are logged) loglevel notice logfile "/www/server/redis/redis.log" 位置 # dbid is a number between 0 and 'databases'-1 databases 16 默认16个数据库 持久化,redis是内存数据库,断电即失 save 900 1 如果900s内至少有一个key修改,进行持久化操作 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes 持久化出错,是否继续工作 rdbcompression yes 是否压缩 rdb 文件,要消耗一定的cpu资源 rdbchecksum yes 保存 rdb 文件 是否要校验 dbfilename dump.rdb rdb 文件保存目录 ################################# REPLICATION ################################# ################################# SECURITY ################################# # requirepass foobared 设置密码 ################################### CLIENTS #################################### # maxclients 10000 最大的连接数 ############################## MEMORY MANAGEMENT################################ # maxmemory <bytes> 最大的容量 # maxmemory-policy noeviction 内存满了怎么处理 ############################## APPEND ONLY MODE ############################### aof的配置 appendonly no 默认不开启,默认rdb够用了 appendfilename "appendonly.aof" 持久化的文件的名字 # appendfsync always 每次都要 sync appendfsync everysec 每秒执行一次 sync 可能会丢失一秒的数据 # appendfsync no 不执行,操作系统自己同步数据
RDB
Redis DataBase redis 的持久化
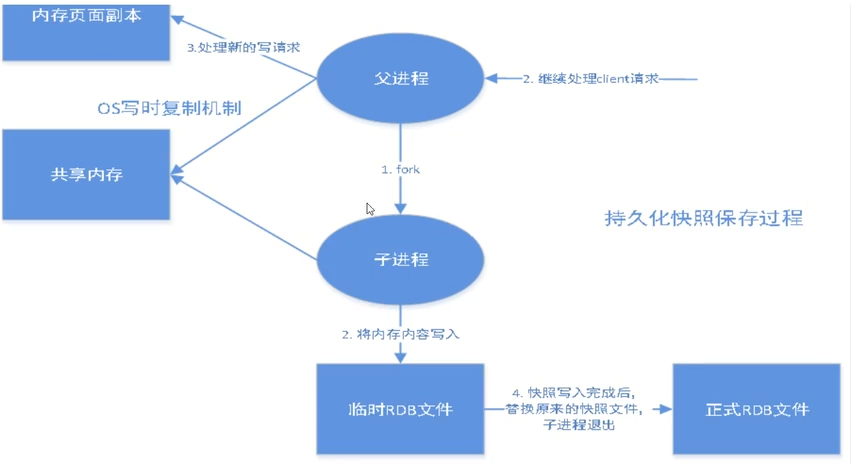
保存的是dump.rdb
持久化,redis是内存数据库,断电即失 save 900 1 如果900s内至少有一个key修改,进行持久化操作 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes 持久化出错,是否继续工作 rdbcompression yes 是否压缩 rdb 文件,要消耗一定的cpu资源 rdbchecksum yes 保存 rdb 文件 是否要校验 dbfilename dump.rdb rdb 文件保存目录
- save规则满足了 就自动的执行了
- 执行flushall
- 退出redis
这个时候是会有 dump.rdb。
怎么恢复RDB文件?
只要放到redis的启动目录就可以了,redis会自动检查。
优点:
- 适合大规模的数据恢复
- 对数据的完整性要求不高
缺点:
- 需要一定的时间间隔
- fork的时候会占用一定的内存空间
AOF(Append Only File)
将我们的所有的操作记录下来。
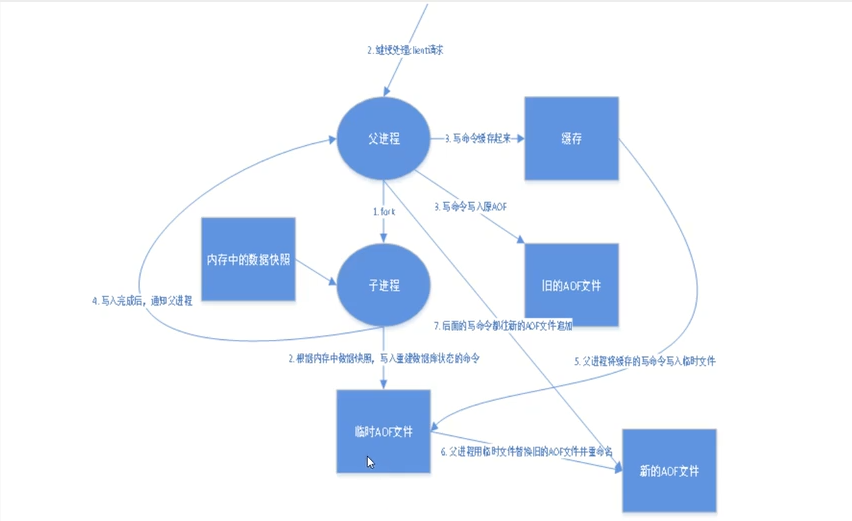
以日志的形式来记录每个写操作,将Redis执行过的所有指令记录下来(读操作不记录) , 只许追加文件但不可以改写文件, redis启动之初会读取该文件重新构建数据,换言之, redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复。
Aof保存的是appendonly.aof文件
############################## APPEND ONLY MODE ############################### aof的配置 appendonly no 默认不开启,默认rdb够用了,这里改为yes就是开启了,重启redis就生效了 appendfilename "appendonly.aof" 持久化的文件的名字 # appendfsync always 每次都要 sync appendfsync everysec 每秒执行一次 sync 可能会丢失一秒的数据 # appendfsync no 不执行,操作系统自己同步数据
vim 这个 appendonly.aof 文件,就可以看到自己的所有的操作
以日志级别记录我们的所有的写操作。
redis -check-aof
这个是会检查你的 appendonly.aof 。
redis -check-aof --fix appendonly.aof
可以用
ps -ef|grep redis
看自己的reids是否开启了。
按照默认的配置,如果aof的文件大于64m,太大了,redis 会 fork 一个新的进程将我们的文件进行重写。
aof 默认的就是文件的无限追加。
优点
- 每一次的修改都同步,文件的完整性会更好
- 每秒同步一个,可能会丢失最后一秒的数据
- 从不同步,效率最高
缺点
- 相对于数据文件来说,aof 远大于 rdb,会很慢,运行效率也更低
扩展:
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。
Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
Redis 还可以同时使用 AOF 持久化和 RDB 持久化。
在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。你甚至可以关闭持久化功能,让数据只在服务器运行时存在。
发布和订阅
通信 队列 发送者 ======== 订阅者
redis也是一种消息通信模式
redis可以订阅任意数量的频道

操作例子:
127.0.0.1:6379> SUBSCRIBE zwtjava Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "zwtjava" 3) (integer) 1 1) "message" 2) "zwtjava" 3) "hello zwt" 1) "message" 2) "zwtjava" 3) "hello redis"
127.0.0.1:6379> PUBLISH zwtjava "hello zwt" (integer) 1 127.0.0.1:6379> PUBLISH zwtjava "hello redis" (integer) 1 127.0.0.1:6379>
主从复制
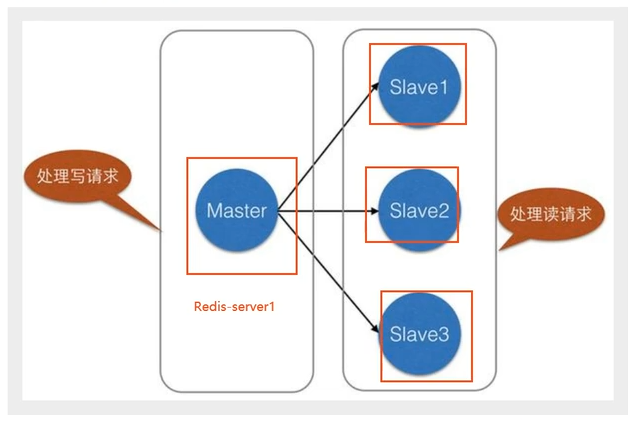
概念 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。
前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。
作用
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
高可用基石:主从复制还是哨兵和集群能够实施的基础。
为什么使用集群?
- 单台服务器难以负载大量的请求
- 单台服务器故障率高,系统崩坏概率大
- 单台服务器内存容量有限
查看当前库的信息:
[root@LJT redis]# redis-server redis.conf [root@LJT redis]# redis-cli -p 6379 127.0.0.1:6379> info replication # Replication role:master connected_slaves:0 master_failover_state:no-failover master_replid:cf011df27ae3fb7062185a64f1a1b6f660d61b10 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
一主二从
配置伪集群:
复制配置文件
[root@LJT redis]# cp redis.conf redis79.conf [root@LJT redis]# cp redis.conf redis80.conf [root@LJT redis]# cp redis.conf redis81.conf [root@LJT redis]# ll total 436 -rw-rw-r-- 1 redis redis 28118 Jun 1 22:03 00-RELEASENOTES -rw-rw-r-- 1 redis redis 51 Jun 1 22:03 BUGS -rw-rw-r-- 1 redis redis 5026 Jun 1 22:03 CONDUCT -rw-rw-r-- 1 redis redis 3384 Jun 1 22:03 CONTRIBUTING -rw-rw-r-- 1 redis redis 1487 Jun 1 22:03 COPYING drwxrwxr-x 7 redis redis 4096 Jul 12 10:40 deps -rw-r--r-- 1 root root 104 Jul 21 16:30 dump.rdb -rw-rw-r-- 1 redis redis 11 Jun 1 22:03 INSTALL -rw-rw-r-- 1 redis redis 151 Jun 1 22:03 Makefile -rw-rw-r-- 1 redis redis 6888 Jun 1 22:03 MANIFESTO -rw-rw-r-- 1 redis redis 21567 Jun 1 22:03 README.md -rw-r--r-- 1 root root 61859 Jul 21 16:32 redis79.conf -rw-r--r-- 1 root root 61859 Jul 21 16:32 redis80.conf -rw-r--r-- 1 root root 61859 Jul 21 16:32 redis81.conf -rw-rw-r-- 1 redis redis 61859 Jul 21 10:50 redis.conf -rw-r--r-- 1 redis redis 15057 Jul 21 16:30 redis.log -rwxrwxr-x 1 redis redis 275 Jun 1 22:03 runtest -rwxrwxr-x 1 redis redis 279 Jun 1 22:03 runtest-cluster -rwxrwxr-x 1 redis redis 1046 Jun 1 22:03 runtest-moduleapi -rwxrwxr-x 1 redis redis 281 Jun 1 22:03 runtest-sentinel -rw-rw-r-- 1 redis redis 13768 Jun 1 22:03 sentinel.conf drwxrwxr-x 3 redis redis 12288 Jul 12 17:32 src -rw-r--r-- 1 root root 5 Jul 12 10:42 start.pl drwxrwxr-x 11 redis redis 4096 Jun 1 22:03 tests -rw-rw-r-- 1 redis redis 3055 Jun 1 22:03 TLS.md drwxrwxr-x 9 redis redis 4096 Jun 1 22:03 utils -rw-r--r-- 1 root root 5 Jul 12 10:45 version_check.pl -rw-r--r-- 1 root root 6 Jul 12 10:42 version.pl [root@LJT redis]#
修改对应的配置文件
-rw-r--r-- 1 root root 61859 Jul 21 16:32 redis80.conf port 6380 daemonize yes 开启服务 logfile "/www/server/redis/redis80.log" dbfilename dump80.rdb 大概就是这样几个地方
连接三台主机,都是master,默认都是master,我们一般只用配置从机就可以。
主(79)从(80,81)
127.0.0.1:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=42,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=42,lag=1 master_failover_state:no-failover master_replid:4c97ee0b19fef1a3f8e4f2f97ec15b20c01d61b1 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:42 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:42 127.0.0.1:6379>
SLAVEOF 127.0.0.1 6379
通过这个命令配置主从关系
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 OK 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:5 master_sync_in_progress:0 slave_repl_offset:0 slave_priority:100 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:4c97ee0b19fef1a3f8e4f2f97ec15b20c01d61b1 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:0 127.0.0.1:6380>
这是用的命令实现的,不是永久的,永久的需要再配置文件里面实现,
配置中实现这个即可。
# replicaof <masterip> <masterport> # masterauth <master-password>
细节了解:
主机可以写,从机不能写只能读!主机中的所有信息和数据,都会自动被从机保存!
127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> 127.0.0.1:6380> get k1 "v1" 127.0.0.1:6380> 127.0.0.1:6380> set k2 v2 (error) READONLY You can't write against a read only replica.
测试:主机断开,从机依旧连接,但是没有写操作。
主机回来,恢复。
从机断了,主机的写操作ok,从机回来,不可以拿到掉线的值。
复制原理
通过测试管观察原理:
Slave启动成功连接到master后会发送一个sync命令 Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后, master将传送整个数据文件到slave ,并完成一次完全同步。 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。 增量复制: Master继续将新的所有收集到的修改命令依次传给slave ,完成同步 但是只要是重新连接master , 一次完全同步(全量复制)将被自动执行。
宕机后的手动配置主机
主节点断开,info replication
127.0.0.1:6380> SLAVEOF no one OK 127.0.0.1:6380> info replication # Replication role:master connected_slaves:0 master_failover_state:no-failover master_replid:7fc61819c4dd84b2476cc55cf827ab854177bdbf master_replid2:4c97ee0b19fef1a3f8e4f2f97ec15b20c01d61b1 master_repl_offset:3538 second_repl_offset:3539 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:3538 127.0.0.1:6380>
如果这个时候主机ok了,回来了,需要再配置。
哨兵模式
自动版的“选老大“。
主从切换技术的方法是:
当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。
这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
Redis从2.8开始正式提供 了Sentinel (哨兵)架构来解决这个问题。 谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。
其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。

然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。
各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
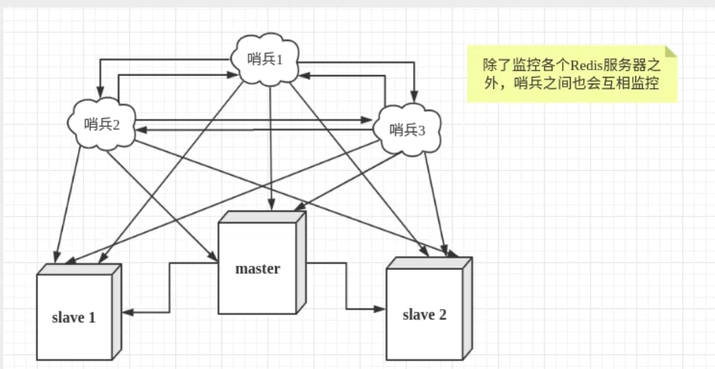
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。
当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票 ,投票的结果由一个哨兵发起,进行failover[故障转移]操作。
切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
测试:
目前是一主二从。
配置哨兵文件
sentinel monitor mymaster 127.0.0.1 6379 1
后面的这个数字1 ,代表主机挂了,slave投票看让谁接替成为主机,票数最多的就会成为主机!
启动哨兵
[root@LJT redis]# redis-sentinel sentinel79.conf 20183:X 21 Jul 2021 22:41:55.113 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 20183:X 21 Jul 2021 22:41:55.113 # Redis version=6.2.4, bits=64, commit=00000000, modified=0, pid=20183, just started 20183:X 21 Jul 2021 22:41:55.113 # Configuration loaded 20183:X 21 Jul 2021 22:41:55.114 * monotonic clock: POSIX clock_gettime _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 6.2.4 (00000000/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in sentinel mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 26379 | `-._ `._ / _.-' | PID: 20183 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | https://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 20183:X 21 Jul 2021 22:41:55.120 # Sentinel ID is 236bea779a3b0737574dc5022c37d17d825b0ccb 20183:X 21 Jul 2021 22:41:55.120 # +monitor master mymaster 127.0.0.1 6379 quorum 1 #有一票 #它的俩个从节点 20183:X 21 Jul 2021 22:41:55.120 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:41:55.125 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 #关闭主节点后的日志 failover selected 20183:X 21 Jul 2021 22:42:49.558 # +sdown master mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:49.558 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1 20183:X 21 Jul 2021 22:42:49.558 # +new-epoch 1 20183:X 21 Jul 2021 22:42:49.558 # +try-failover master mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:49.565 # +vote-for-leader 236bea779a3b0737574dc5022c37d17d825b0ccb 1 20183:X 21 Jul 2021 22:42:49.565 # +elected-leader master mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:49.565 # +failover-state-select-slave master mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:49.637 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:49.637 * +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:49.720 * +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:50.053 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:50.053 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:50.113 * +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:51.102 * +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:51.102 * +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:51.157 # +failover-end master mymaster 127.0.0.1 6379 20183:X 21 Jul 2021 22:42:51.157 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380 20183:X 21 Jul 2021 22:42:51.158 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380 20183:X 21 Jul 2021 22:42:51.158 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380 20183:X 21 Jul 2021 22:43:21.239 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380 #再测试,果然 master 是 6380 127.0.0.1:6380> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6381,state=online,offset=9076,lag=0 master_failover_state:no-failover master_replid:6d563979b4c421fde3bc7a8996b88d2f02f060ee master_replid2:1645d3e978dea3fea45f2f5219077322693e61a3 master_repl_offset:9076 second_repl_offset:1585 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:9076 127.0.0.1:6380> #6379再次上线 20183:X 21 Jul 2021 22:42:51.157 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380 20183:X 21 Jul 2021 22:42:51.158 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380 20183:X 21 Jul 2021 22:42:51.158 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380 20183:X 21 Jul 2021 22:43:21.239 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380 20183:X 21 Jul 2021 22:47:03.632 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380 20183:X 21 Jul 2021 22:47:13.578 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380 #发现现在没有用,还是6380统治天下
**
优点:** 1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有 2、主从可以切换,故障可以转移,系统的可用性就会更好 3、哨兵模式就是主从模式的升级,手动到自动,更加健壮! 缺点: 1、Redis 不好啊在线扩容的,集群容量- -旦到达上限,在线扩容就十分麻烦! 2、实现哨兵模式的配置其实是很麻烦的,里面有很多选择!
Redis 缓存 穿透 和 雪崩(面试高频,工作常用)
Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。
但同时,它也带来了一些问题。
其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。
如果对数据的一致性要求很高,那么就不能使用缓存。
另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。
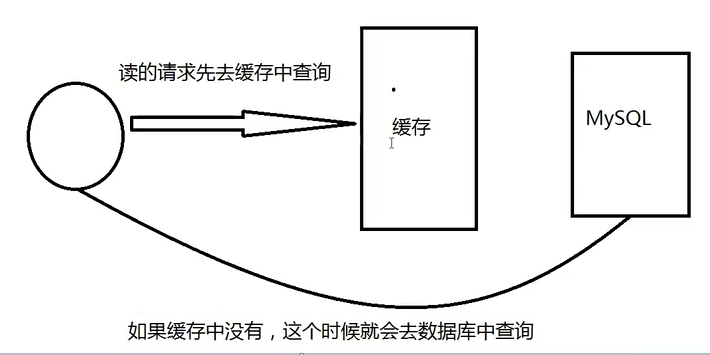
缓存穿透
缓存穿透的概念很简单,用户想要查询一个数据发现redis内存数据库没有,
也就是缓存没有命中,于是向持久层数据库查询。
发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。
这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方案
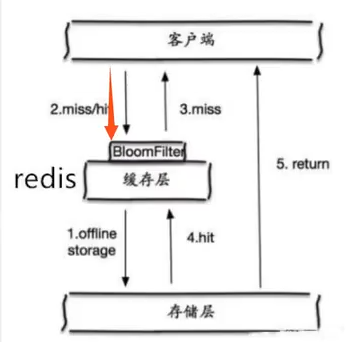
布隆过滤器
是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力。
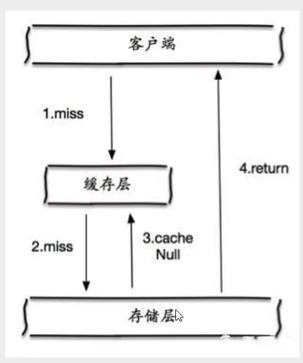
缓存空对象 当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护后端数据源。
但是这种方法会存在两个问题: 1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键。 2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
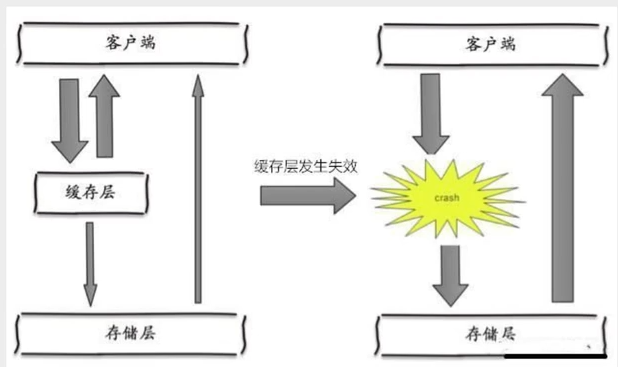
缓存雪崩
缓存雪崩,是指在某一一个时间段,缓存集中过期失效。
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来-波抢购,这波商品时间比较集中的放入了缓存,假设缓存-个小时。那么到了凌晨一点钟的时候 ,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
解决方案
redis高可用 这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis ,这样一台挂掉之 后其他的还可以继续工作,其实就是搭建的集群。(异地多活! )
限流降级 这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热 数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。
在即将发生大并发访问前手动触发加载缓存不同的key ,设置不同的过期时间,让缓存失效的时间点尽量均匀。
缓存击穿(量太大了,缓存过期)
例如:微博热搜
解决方案
设置热点不过期
加互斥锁

- Redis 起步
- Redis在新浪微博中的应用
- Redis实战应用举例
- 深入浅出Redis(二)高级特性:事务
- Redis五种数据结构
- (四)redis 主从同步数据
- Redis命令--二
- Redis Publish 频道订阅详解
- redis命令中文手册
- Redis3缓存集群(cluster)搭建
- Scrapy爬取盗墓笔记 0.2版(mongedb redis)
- Redis 基本使用命令
- Shiro与Redis集成,集群下的session共享
- Redis的运用于liunx上的使用
- redis之hash(5)
- sringboot redis五大类型用法 各种方法
- Redis在windows的安装使用
- memcache和redis区别
- 分布式缓存学习之一:Memcached, Redis, MongoDB区别
- 关于mongodb ,redis,memcache之间见不乱理还乱的关系和作用