FlinkSQL使用自定义UDTF函数行转列-IK分词器
2021-06-19 04:11
1306 查看
一、背景说明
本文基于IK分词器,自定义一个UDTF(Table Functions),实现类似Hive的explode行转列的效果,以此来简明开发过程。
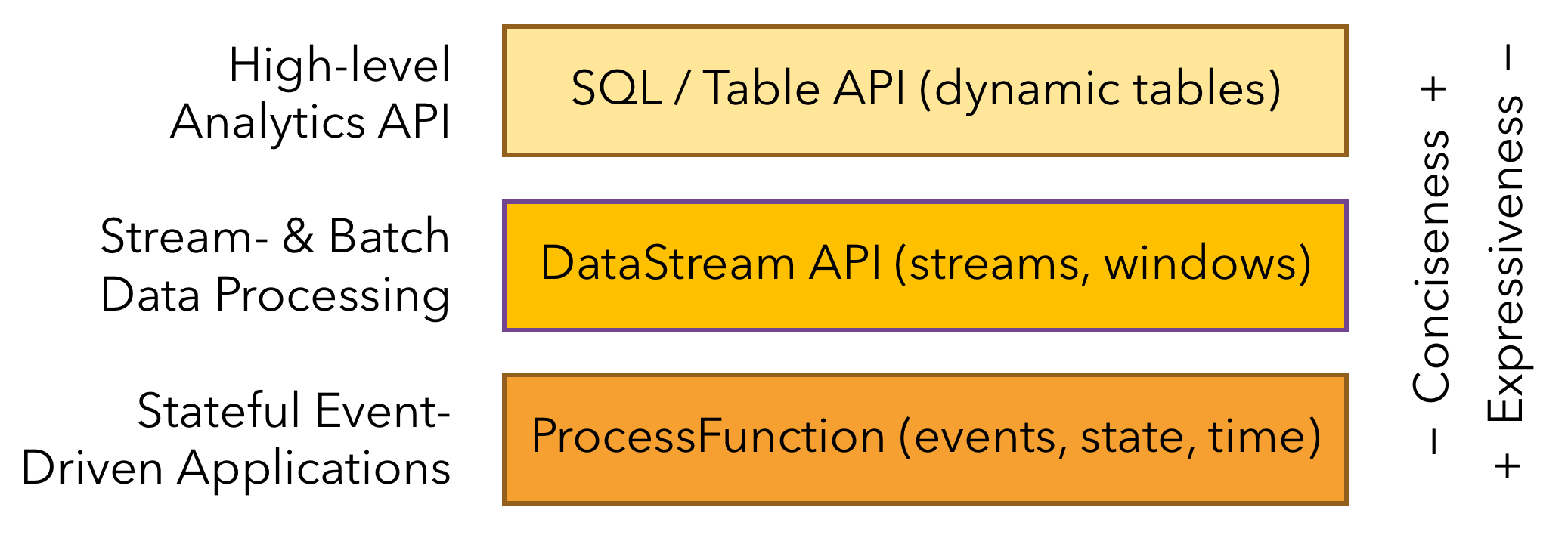
如下图Flink三层API接口中,Table API的接口位于最顶层也是最易用的一层,可以套用SQL语法进行代码编写,对于有SQL基础的能很快上手,但是不足之处在于灵活度有限,自有函数不能满足使用的时候,需要通过自定义函数实现,类似Hive的UDF/UDTF/UDAF自定义函数,在Flink也可以称之为Scalar Functions/Table Functions/Aggregate Functions。
二、效果预览
Kafka端建立生产者发送json片段:

IDEA侧消费数据处理后效果:

如上所示,形成类似Hive的exploed炸裂函数实现行转列的效果,当然也可以不用IK分词器,直接按空格进行split实现逻辑是一样的。
三、代码过程
由于Flink一般在流式环境使用,故这里数据源使用Kafka,并建立动态表的形式实现,以更好的贴近实际的业务环境。
- 工具类:
package com.test.UDTF;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
/**
* @author: Rango
* @create: 2021-05-04 16:50
* @description: 建立函数,继承TableFunction并建立eval方法
**/
@FunctionHint(output = @DataTypeHint("ROW<word STRING>"))
public class KeywordUDTF extends TableFunction<Row> {
//按官方文档说明,须按eval命名
public void eval(String value){
List<String> stringList = analyze(value);
for (String s : stringList) {
Row row = new Row(1);
row.setField(0,s);
collect(row);
}
}
//自定义分词方式
public List<String> analyze(String text){
//字符串转文件流
StringReader sr = new StringReader(text);
//建立分词器对象
IKSegmenter ik = new IKSegmenter(sr,true);
//ik分词后对象为Lexeme
Lexeme lex = null;
//分词后转入列表
List<String> keywordList = new ArrayList<>();
while(true){
try {
if ((lex = ik.next())!=null){
keywordList.add(lex.getLexemeText());
}else{
break;
}
} catch(IOException e) {
e.printStackTrace();
}
}return keywordList;
}
}
- 实现类
package com.test.UDTF;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSetting
56c
s;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author: Rango
* @create: 2021-05-04 17:11
* @description:
**/
public class KeywordStatsApp {
public static void main(String[] args) throws Exception {
//建立环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
//注册函数
tableEnv.createTemporaryFunction("ik_analyze", KeywordUDTF.class);
//建立动态表
tableEnv.executeSql("CREATE TABLE wordtable (" +
"word STRING" +
") WITH ('connector' = 'kafka'," +
"'topic' = 'keywordtest'," +
"'properties.bootstrap.servers' = 'hadoop102:9092'," +
"'properties.group.id' = 'keyword_stats_app'," +
"'format' = 'json')");
//未切分效果
Table wordTable = tableEnv.sqlQuery("select word from wordtable");
//利用自定义函数对文本进行分切,切分后计为1,方便后续统计使用
Table wordTable1 = tableEnv.sqlQuery("sel
ad8
ect splitword,1 ct from wordtable," +
"LATERAL TABLE(ik_analyze(word)) as T(splitword)");
tableEnv.toAppendStream(wordTable, Row.class).print("原格式>>>");
tableEnv.toAppendStream(wordTable1, Row.class).print("使用UDTF函数效果>>>");
env.execute();
}
}
- 补充下依赖
<properties>
<java.version>1.8</java.version>
<flink.version>1.12.0</flink.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
学习交流,有任何问题还请随时评论指出交流。

相关文章推荐
- Linq to Sql中使用自定义枚举类型的奇怪问题
- Ms_SQL 使用自定义函数须注意
- 5、flink常见函数使用及自定义转换函数
- 在sql-insert中使用自定义的存储过程
- 利用自定义的SQL语句生成类代替实体类的使用
- Flink 1.9 实战:使用 SQL 读取 Kafka 并写入 MySQL
- 和hibernate结合使用的sql split自定义函数
- sql 使用触发器自定义动态自增值
- 使用addScala将SQLQuery自定义查询映射到pojo中
- mybatis generator的使用及自定义sql最佳实践
- Flink SQL-Client 的使用
- 多线程的SqlBulkCopy批量导入、事务和SqlBulkCopy使用的数据集中自定义映射字段的注意事项
- 使用addScala将SQLQuery自定义查询映射到pojo中
- 使用Java反射(Reflect)、自定义注解(Customer Annotation)生成简单SQL语句
- 使用自定义注解生成简单查询sql语句
- PowerDesign 使用 用户自定义字段类型 domain 后 生成物理模型图 生成的sql脚本 类型 替换问题
- rails 使用自定义SQL
- 使用flink Table &Sql api来构建批量和流式应用(1)Table的基本概念
- Mybatis plus之条件构造器及无法使用lambda做自定义sql查询问题
- MyBatis-Plus自定义sql使用条件构造器和分页查询