浅谈:Redis持久化机制(一)RDB篇
浅谈:Redis持久化机制(一)RDB篇
众所周知,redis是一款性能极高,基于内存的键值对NoSql数据库,官方显示,它的读效率可达到11万次每秒,写效率能达到8万次每秒,因为它基于内存以及存读效率高的特性,在市场上的应用中一般都把它作为缓存来使用,同时这也意味着它不能大量的无限制的填充数据,否则容易内存填满,导致redis会向硬盘申请虚拟内存,造成内存和外存的不断I/O,致使效率低下,甚至引起宕机,那么问题来了,既然只是当做缓存而不是为了永久存储数据,redis为什么要做持久化呢?这样做有什么意义呢?
1.为什么要做持久化
- 第一点要明确,redis作为内存数据库,宕机后就会发生数据消失,之所以要去做持久化只是为了能在重启之后快速的恢复数据,而不是存储数据;redis的持久化并不能够保证数据的完整性.
- 当然,如果要把redis当做DB用,DB数据要完整,所以需要一个完整的数据源(比如mysql),当启动时将数据源的数据全部加载到redis里面,这只适用于数据量小的不易改变的,比如:字典库。像mysql那样大量的存储数据是行不通的。
2.RDB(redis database)
说完redis持久化的原因,我们再详聊一下redis做持久化的第一种方式RDB,这种方式也是redis默认的一种持久化方式,默认是开启的。
从字面上来看,RDB也就是redis database,翻译成中文就是redis 数据库,也就是说这种持久化方式就是像数据库一样存储了数据,当然事实上也是这样的,RDB方式是通过存储快照数据来完成的,既然是快照数据,那就是说明这种方式只关注了某一刻缓存的数据状态,关注的是那一刻数据是什么,它并没有去记录这个数据变更的一系列过程。也就是说,RDB持久化方式关注的是数据存储的结果,而非是数据存储的过程。
另外,既然是快照数据,redis又要保证性能,因此要明白RDB持久化时肯定不会是实时的,肯定是隔一段时间触发一次,否则的话redis作为一个单线程处理的服务,光顾着去持久化数据了,怎么还有时间处理来自客户端的请求访问,这也就说明了由于有时间间隔,redis的RDB方式的持久化会丢失最后一次持久化后的数据,这也就表明了redis的持久化没有办法保证数据的完整性。
2.1 触发快照的方式
- 配置参数定期执行(在redis.conf中配置:save 多少秒内 数据变了多少)
save "" # 不使用RDB存储 不能主从 save 900 1 # 表示15分钟(900秒钟)内至少1个键被更改则进行快照。 save 300 10 # 表示5分钟(300秒)内至少10个键被更改则进行快照。 save 60 10000 # 表示1分钟内至少10000个键被更改则进行快照。
-
命令显式触发(save或者bgsave命令)
127.0.0.1:6379> bgsave Background saving started
- RDB是二进制压缩文件,占用空间小,便于传输。(做主从复制时传递给slaver效率也很高)
- 通过主进程fork复制子进程,由子进程完成持久化的方式,这样可以最大化的保证redis的性能。但是前提条件是redis的数据量不能太大,否则fork的过程太长,容易造成阻塞。
2.2 RDB执行流程
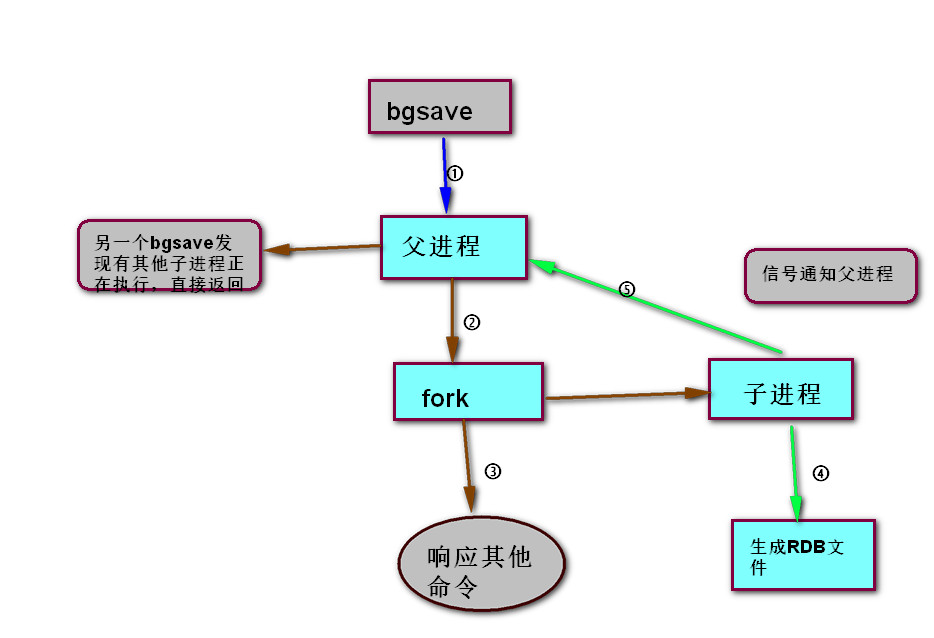
1.redis父进程首先判断,当前是否正在执行save,如果正在执行,则先返回。
2.父进程fork()复制出子进程,在这个过程中父进程是阻塞的,不再处理redis接收到的其他命令。当父进程fork结束,又可以重新处理工作。
3.子进程创建RDB文件,根据父进程的内存快照生成临时快照文件,完成后对原有的文件进行替换。始终保持RDB文件的完整性。
4.子进程生成RDB文件完成后,就响应信息给父进程,父进程更新统计信息。
2.3 RDB文件结构

1、头部5字节固定为“REDIS”字符串
2、4字节“RDB”版本号(不是Redis版本号),当前为9,填充后为0009
3、辅助字段,以key-value的形式
| 字段名 | 字段值 | 字段名 | 字段值 |
|---|---|---|---|
| redis-ver | 5.0.5 | aof-preamble | 是否开启aof |
| redis-bits | 64/32 | repl-stream-db | 主从复制 |
| ctime | 当前时间戳 | repl-id | 主从复制 |
| used-mem | 使用内存 | repl-offset | 主从复制 |
4、存储数据库号码
5、字典大小6、过期key
7、主要数据,以key-value的形式存储
8、结束标志
9、校验和,就是看文件是否损坏,或者是否被修改。
2.4 RDB的优缺点
优点:
缺点:
- 不能保证数据的完整性,会丢失最后一次fork之后的数据。例如,redis进行持久化的操作是1分钟一次,当上次持久化完成后的30秒内,新添加了5000个数据,那么redis发生宕机然后重新恢复时,那30秒的数据会丢失。

- 浅谈Redis的两种持久化机制
- Redis入门之浅谈rdb持久化机制
- Redis入门之浅谈aof持久化机制
- 浅谈redis的RDB持久化机制
- redis持久化机制
- Redis持久化机制和虚拟内存的使用
- Redis pub/sub机制在实际运用场景的缺陷&&模拟JMS消息发布订阅的持久化特性
- Redis 持久化(persistence)机制
- redis的持久化和缓存机制
- redis持久化机制
- redis的持久化机制
- NoSQL和redis简介以及redis的两种持久化机制
- 浅谈php的缓存机制之redis
- redis中持久化机制(九)
- 浅谈小白如何读懂Redis高速缓存与持久化并存及主从高可用集群 推荐
- reids的缓存机制,redis事务控制,redis分片机制,一致性hash算法,redis持久化策略,Redis内存策略,内存优化算法
- Redis持久化机制
- Redis两种存储机制(持久化)的比较
- redis持久化之RDB、AOF机制比对
- 简要说明Redis持久化机制