『动善时』JMeter基础 — 34、JMeter接口关联【XPath提取器】详解
[toc]
1、XPath提取器介绍
有些WEB项目是前后端不分离的,接口返回的内容不是Json格式的数据,而返回的是一个HTML页面。并且有些参数是隐藏在HTML页面里面的,需要从HTML页面中提取出这些隐藏参数,这个时候就会用到XPath提取器组件。
XPath提取器组件常用于接口返回值为HTML或XML格式数据的时候,进行数据的提取。
XPath提取器组件在后置处理器元件中,后置处理器主要的作用,在请求结束或者返回响应结果时发挥作用。
2、XPath提取器界面详解
添加XPath提取器组件操作:
选中“取样器”右键 —> 添加 —> 后置处理器 —> XPath提取器。
界面如下图所示:
下面是XPath提取器组件的详细说明:
- 名称:XPath提取器组件的自定义名称,见名知意最好。
- 注释:即添加一些备注信息,对该XPath提取器组件的简短说明,以便后期回顾时查看。
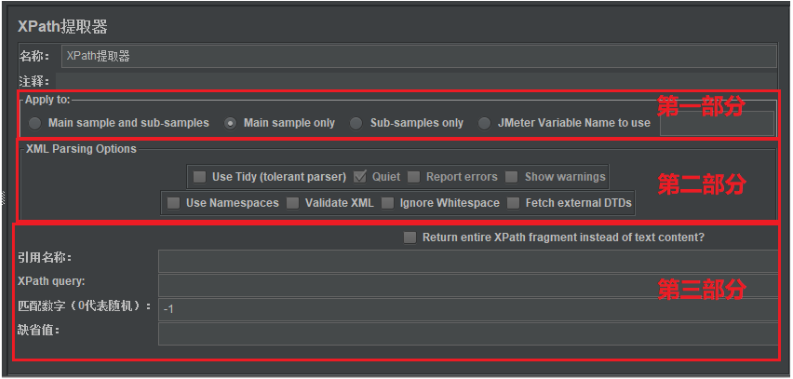
(1)Apply to
:作用范围(返回内容的取值范围)
Main sample and sub-samples
:作用于父节点的取样器及对应子节点的取样器。Main sample only
:仅作用于父节点的取样器。Sub-samples only
:仅作用于子节点的取样器。JMeter Variable Name to use
:作用于JMeter变量(输入框内可输入JMeter的变量名称),从指定变量中提取需要的值。
(2)XML Parsing Options
:要解析的XML参数
Use Tidy (tolerant parser)
:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式,则取消选中。Quiet
:表示只显示需要的HTML页面。Report errors
:表示显示响应报错。Show warnings
:表示显示警告。Use Namespaces
:如果启用该选项,后续的XML解析器将使用命名空间来分辨。Validate XML
:根据页面元素模式进行检查解析。Ignore Whitespace
:忽略空白内容。Fetch external DTDs
:如果选中该项,外部将使用DTD规则来获取页面内容。
(3)第三部分内容
Return entire XPath fragment of text content
:表示是否返回文本内容的整个XPath片段。Reference Name
:定义提取值的变量名称。XPath Query
:用于提取值的XPath表达式。- 匹配数字(0代表随机):表示取值是第几个匹配结果,因为有可能XPath表达式会匹配到多个值。0表示随机,-1表示全部,1代表第一个,2代表第二个,以此类推。
Default Value
:参数的默认值。也就是取不到值时的默认值。
总结XPath提取器组件:
对所有符合条件的取样器按顺序进行取样。
例如,如果有一个主取样器和三个子取样器,每个取样器都有一个符合条件的匹配结果(总共4个)。
当设置为
Sub-samples only时,匹配数字为3,则第三个子取样器的匹配结果返回;当匹配数字为0或者负数,所有的合格的取样器都将被处理,而当匹配数字>0,一旦找到足够的匹配,比对就停止下来。
3、XPath提取器的使用
需求:
- 访问网易官网,获取title值。
- 将title值放入百度搜索框,进行搜索。
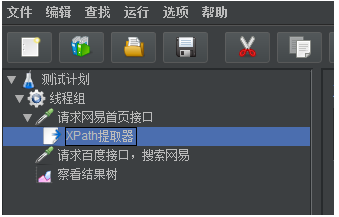
(1)测试计划内包含的元件
添加元件操作步骤:
- 创建测试计划。
- 创建线程组:
选中“测试计划”右键 —> 添加 —> 线程(用户) —> 线程组
。 - 在线程组下,添加取样器“HTTP请求”组件:
选中“线程组”右键 —> 添加 —> 取样器 —> HTTP请求
。 - 在取样器下,添加后置处理器“XPath提取器”组件:
选中“取样器”右键 —> 添加 —> 后置处理器 —> XPath提取器
。 - 在线程组下,添加监听器“察看结果树”组件:
选中“线程组”右键 —> 添加 —> 监听器 —> 察看结果树
。
提示:需要重复添加的组件这里不重复描述。
最终测试计划中的元件如下:
点击运行按钮,会提示你先保存该脚本,脚本保存完成后会直接自动运行该脚本。
提示:提取器一定要添加在你指定的某个请求下面,作为他的子请求,否则提取不到指定的数据!
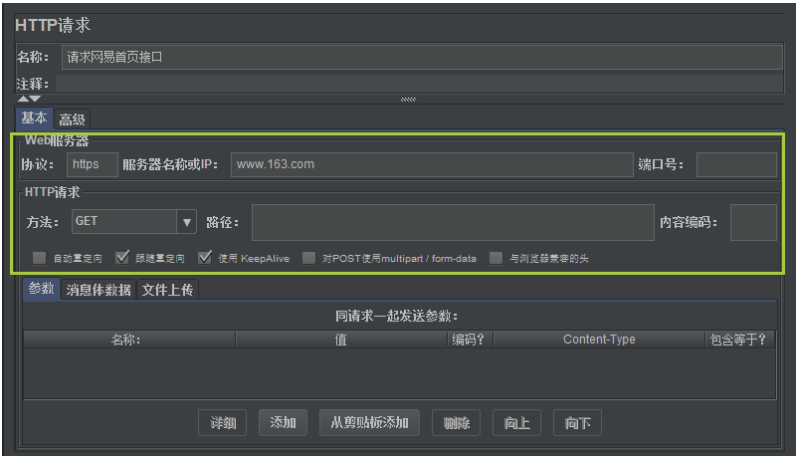
(2)网易首页请求界面内容
非常简单的Get请求,之前说了很多次了,这里就不做解释了。
界面内容如下图所示:
(3)XPath提取器界面内容
我们在编辑XPath提取器组件之前,一般先请求一下需要提取返回数据的接口。
因为我们需要先查看一下需要提取的数据在什么位置,如下图所示:
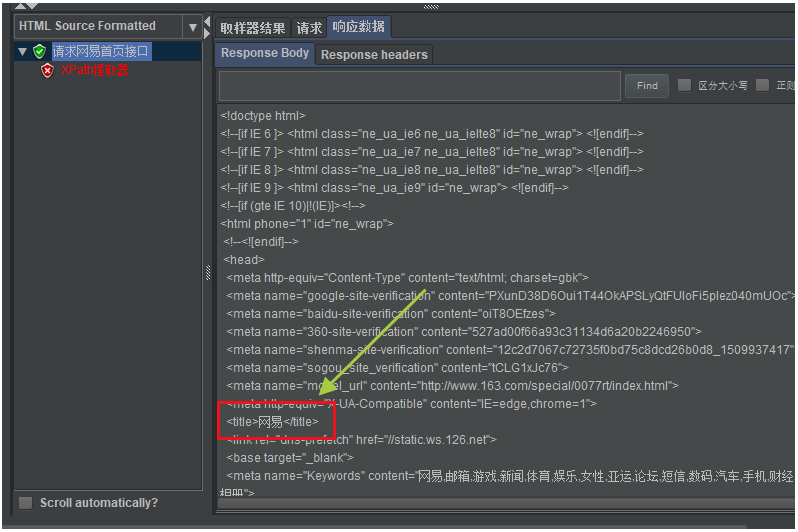
然后选择
XPath Tester视图模式,先手动编写XPath表达式,看看是否能够取到需要的数据。
如下图所示:
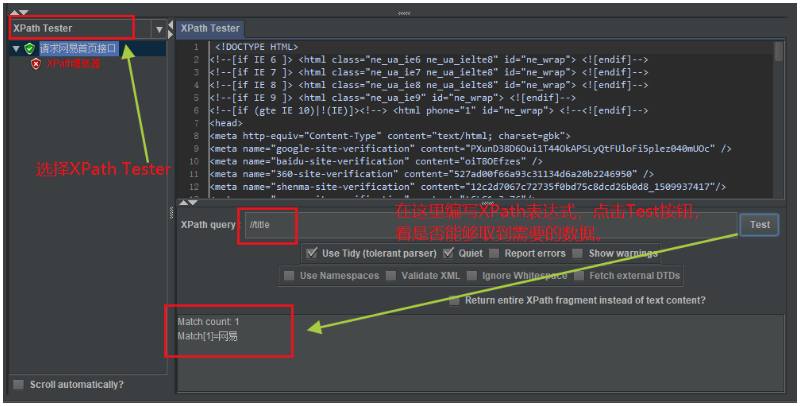
注意两点:
- 选择
XPath Tester
模式进行XPath表达式的编写验证。 - 如果是在HTML页面源码中提取数据,
Use Tidy (tolerant parser)
选择一定要勾选,否则会报错。
之后我们就可以编写XPath提取器组件界面了,如下:
编写引用名称、XPath表达式、匹配数据选择,还有
Use Tidy选项一定要勾选,否则不能取到数据。
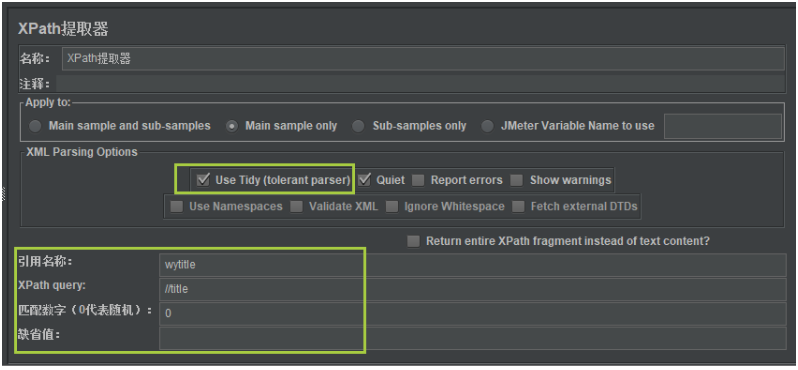
XPath提取器组件提取出来的数据,会存储在线程变量中,供其他后续接口使用。
关于XPath表示的写法,可以看Selenium相关的文章,里面有详细的写法。
(4)百度首页请求界面内容
填写接口的基本请求信息,然后把XPath提取器提取出来的数据,作为参数化变量应用到请求中。
如下图所示:
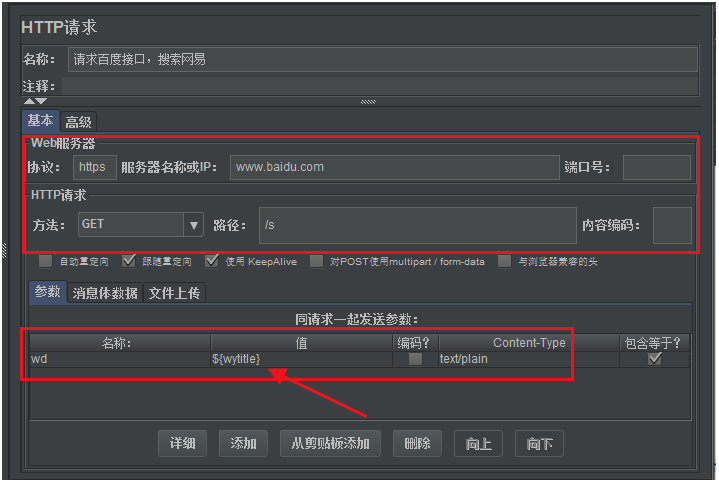
提示:如果此时直接执行该脚本,请求百度搜索网易的接口会执行,但是没有返回数据的,因为百度拒绝你的访问,我们需要设置请求头
User-Agent属性,来模拟是一个浏览器访问,如User-Agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400,这样百度就不会拒绝访问了。
(5)查看结果
我们可以看到再第二个请求中,拿到了第一个请求提取出来的数据“网易”。
如下图所示:
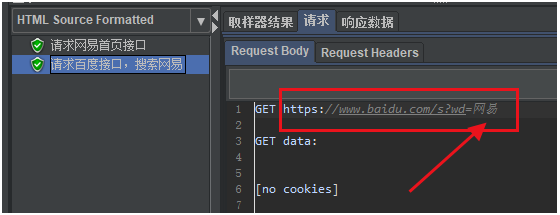
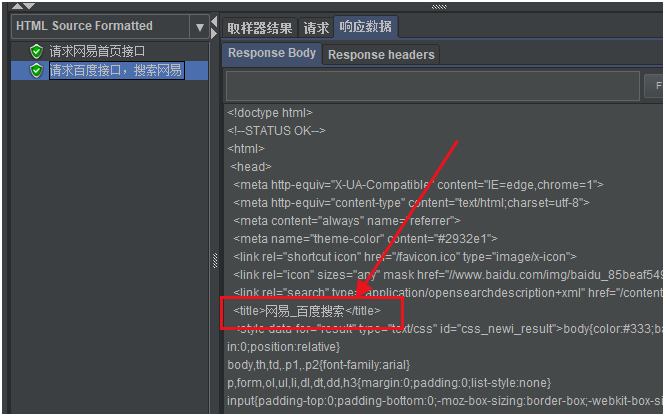
再来看看第二个请求响应的结果,可以看到有
网易_百度搜索的
title属性,说明在百度已经进行了网易搜索。
如下图所示:
提示:可以添加
Debug PostProcessor(调试后置处理器),或者Debug Sampler(调试取样器),来查看Xpath提取器中,提取出的内容是否正确。注意:正常跑用例时删除或禁用它们。
4、总结
XPath提取器通常是从网页源文件中,提取数据时用的比较多。提取完参数后,相当于把参数以
key-value的形式,存放到参数池中,以便后面的请求使用。
注意:不能超前引用。

- jmeter如何通过后置处理器提取(正则提取器、json提取器)做接口关联?
- Jmeter之接口关联
- 【微信公众平台应用开发实践】API详解--基础接口
- Java基础(八) Java修饰符及接口详解之(二) 内部类
- JMeter-接口自动化之正则表达式关联
- Jmeter(二十五)_Xpath关联
- jmeter之接口测试基础篇
- 接口测试工具-Jmeter使用笔记(五:正则表达式提取器)
- 【jmeter】关联-正则表达和xpath
- Java基础学习笔记十四 接口详解
- Java基础之封装、继承、多态、接口详解
- Jmeter系列(26)- 详解 JSON 提取器 25f4
- Jmeter系列(27)- 详解正则提取器
- 接口测试基础知识详解
- Jmeter—5 关联 响应数据传递-正则表达式提取器
- jmeter随笔(34)-WebSocket协议接口测试实战
- 【jmeter笔记】基础知识:request和response详解
- jmeter+接口测试练习+接口关联+Json提取
- python接口自动化(三十六)-封装与调用--流程类接口关联续集(详解)
- Servlet基础之ServletConfig与ServletContext接口详解