大数据基本操作课程笔记(5)
课程目标
1、安装JDK
2、安装Hadoop
3、安装Eclipse
4、安装winutils
5、安装Hadoop插件
课前环境
在同一网络下有maser,slave1,slave2三个linux服务器,并完成了hadoop集群配置。
所需文件
安装JDK
运行
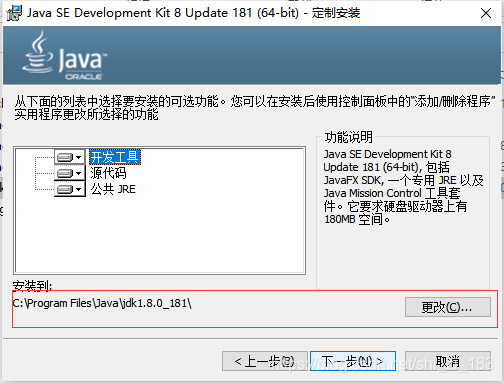
jdk-8u181-windows-x64
更改安装路径
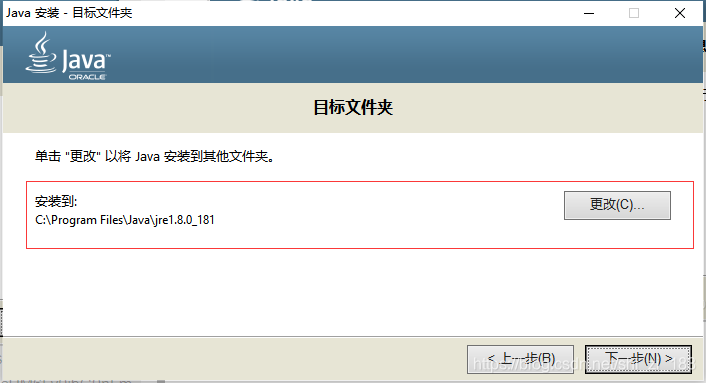
JDK安装完成后会自动跳出Jre安装
安装Hadoop
我们希望在eclipse脱机调试Map/Reduce代码,所以我们需要在windows下安装hadoop环境。
解压hadoop-3.3.0.tar
移动至安装目录即可

添加HADOOP_HOME
我们需要让Map/Reduce知道本地的hadoop路径所以需要将HADOOP路径引入环境变量
安装Eclipse
解压eclipse-jee-neon-3-win32-x86_64移动至安装目录即可

我的电脑右击->属性->高级系统设置

添加HADOOP_HOME

将HADOOP_HOME添加进PATH

安装winutils hadoop.dll
map/reduce程序以来winutils和hadoop库文件,我们需要将文件放置在system32和hadoop bin目录下
D:\hadoop-3.3.0\bin

C:\Windows\System32
安装hadoop插件
我们要使用eclipse链接hadoop需要相应jar包,这个包要放入eclipse拓展包目录中。

放入
D:\eclipse\dropins
打开eclipse
修改默认工作目录
window-> Show View -> Other
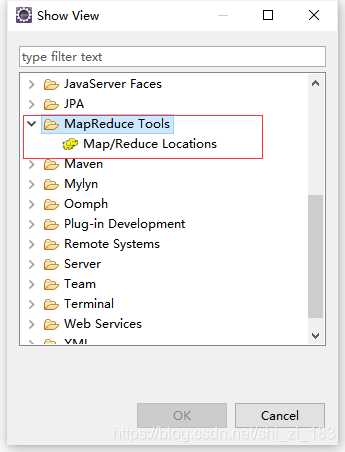
将窗口加入

右键新建链接
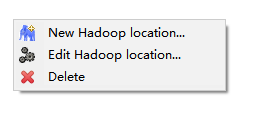
new Hadoop location
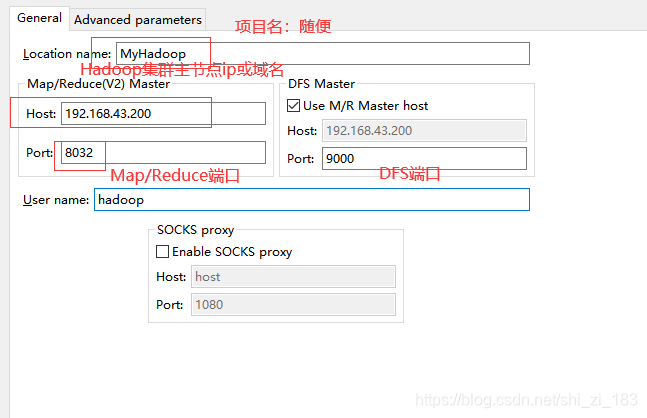
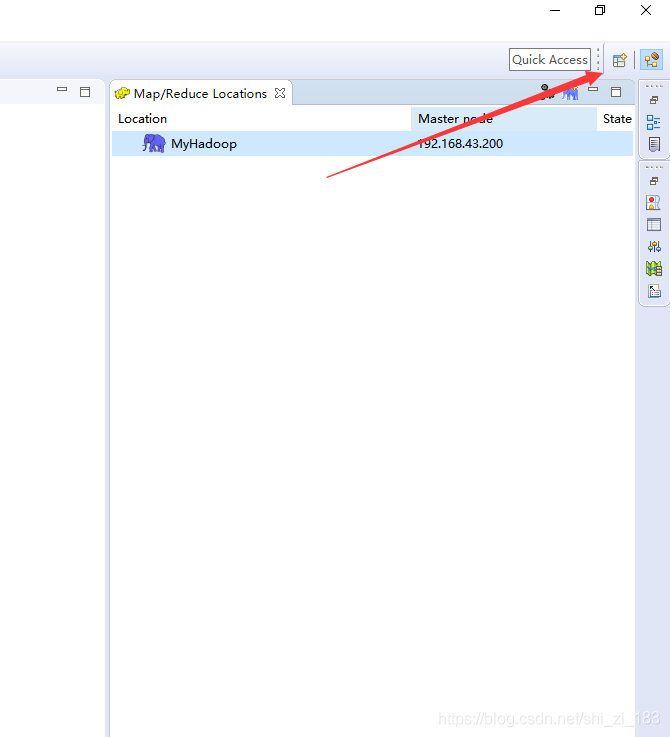

这时我们仅能看到目录结构,不能进行下载和更改,因为eclipse默认使用windows用户登录Hadoop,这会导致hadoop驳回请求,所以我们需要修改他的默认用户
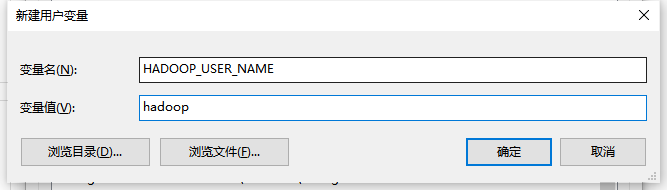
在环境变量中加入HADOOP_USER_NAME
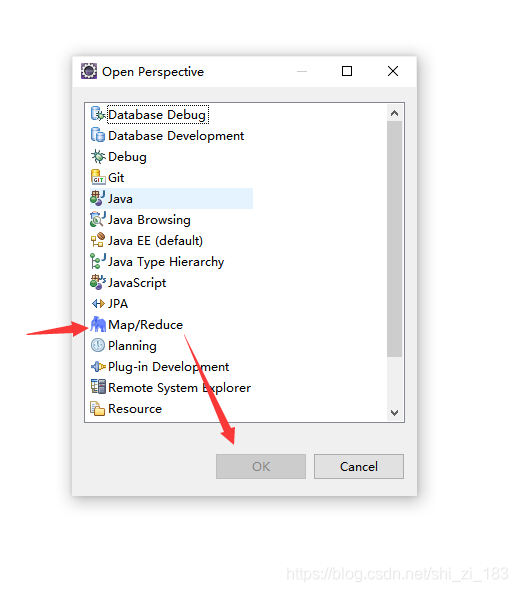
新建项目并运行验证代码
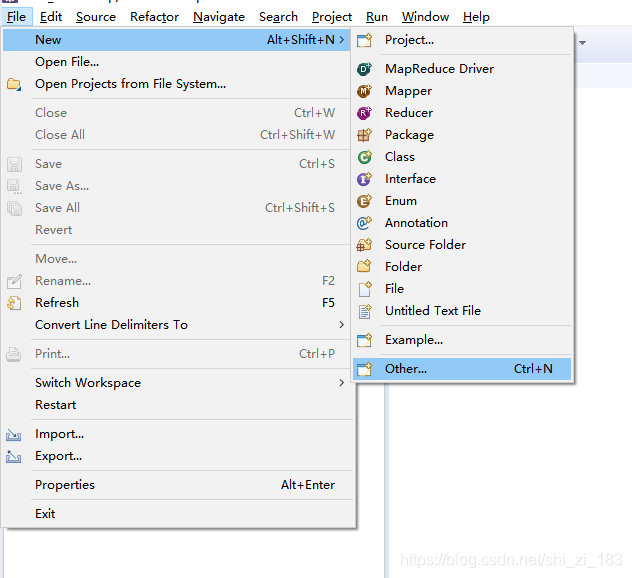
File->New->Other
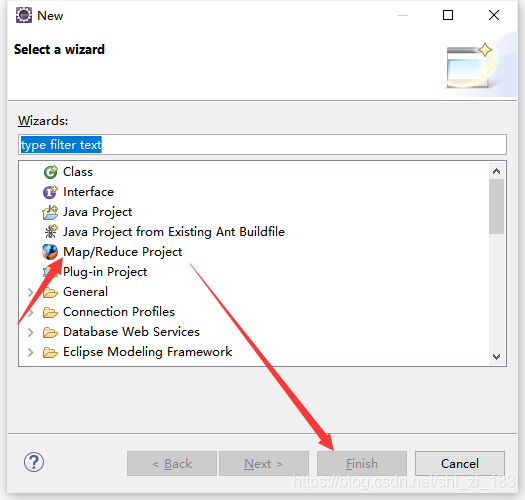
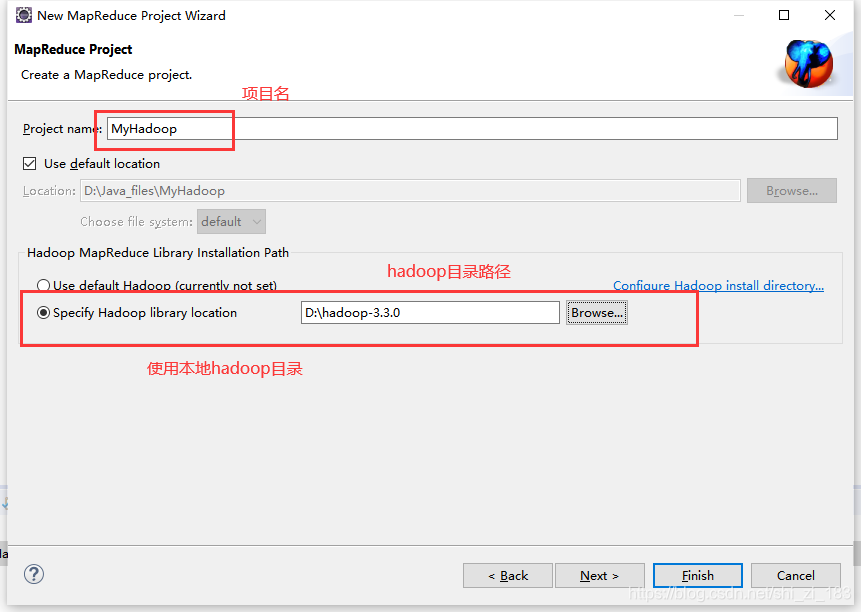
在项目下新建包
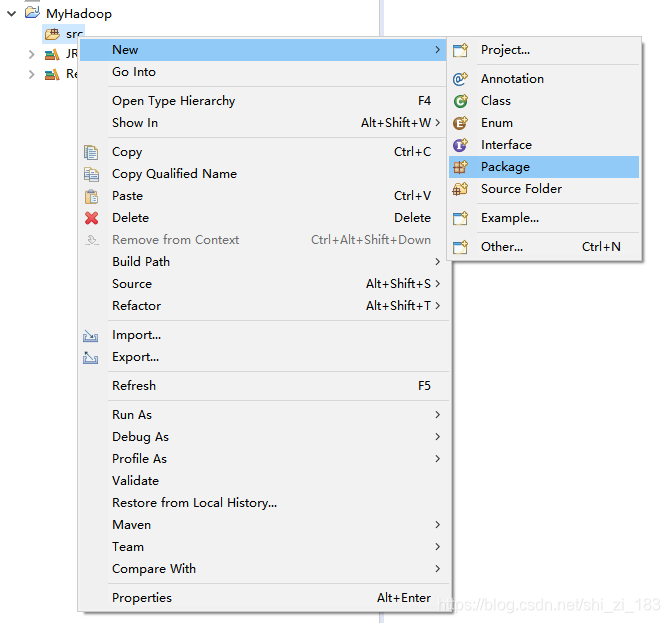
在包里新建一个测试文件
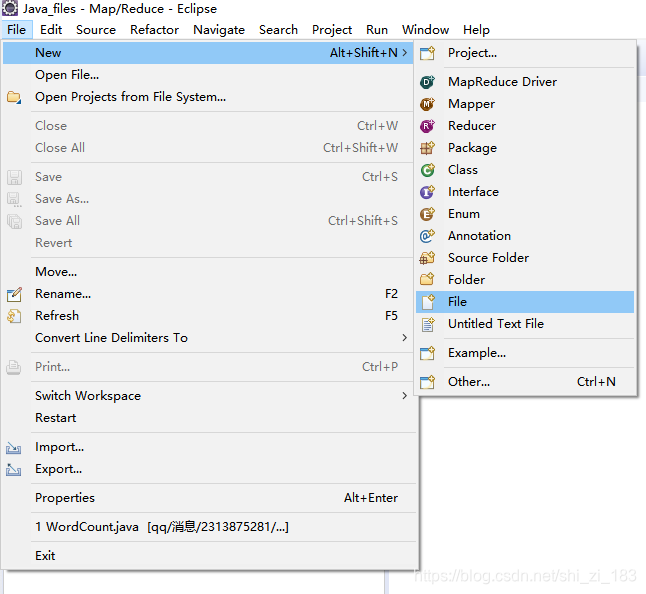
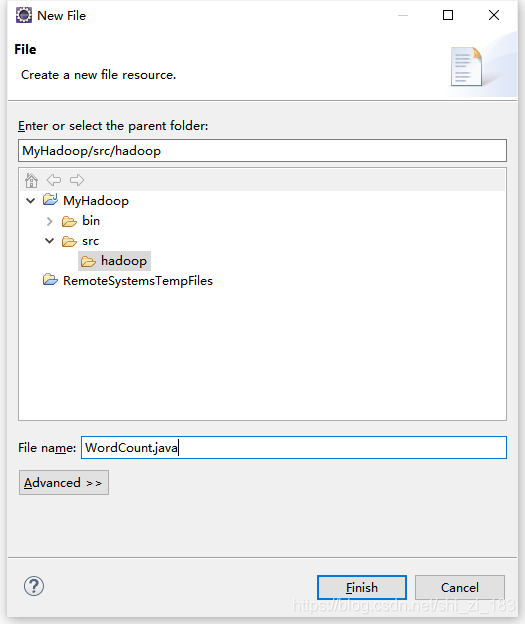
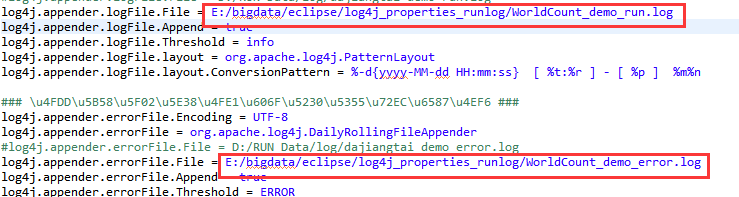
在src下新建一个配置文件

修改配置文件中的eclipse目录
尝试运行
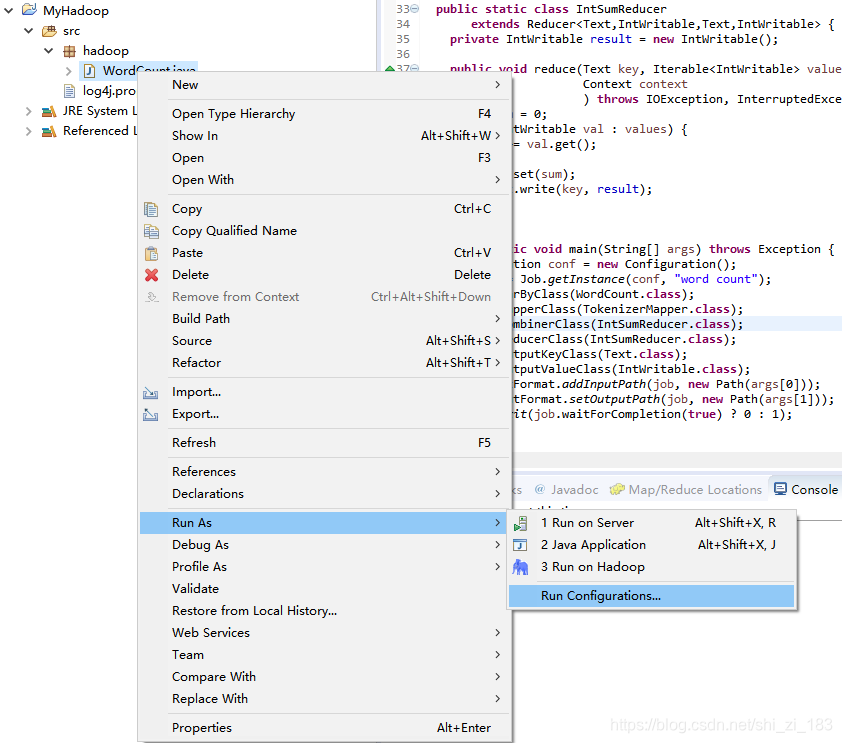
这个地方不可以直接运行因为代码中使用了main的输入参数,我们需要给出,所以更改run configration
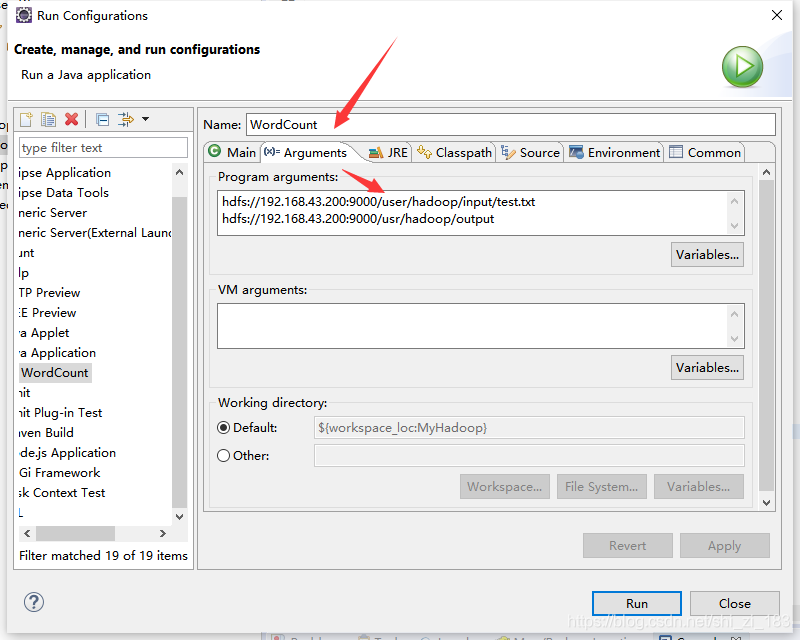
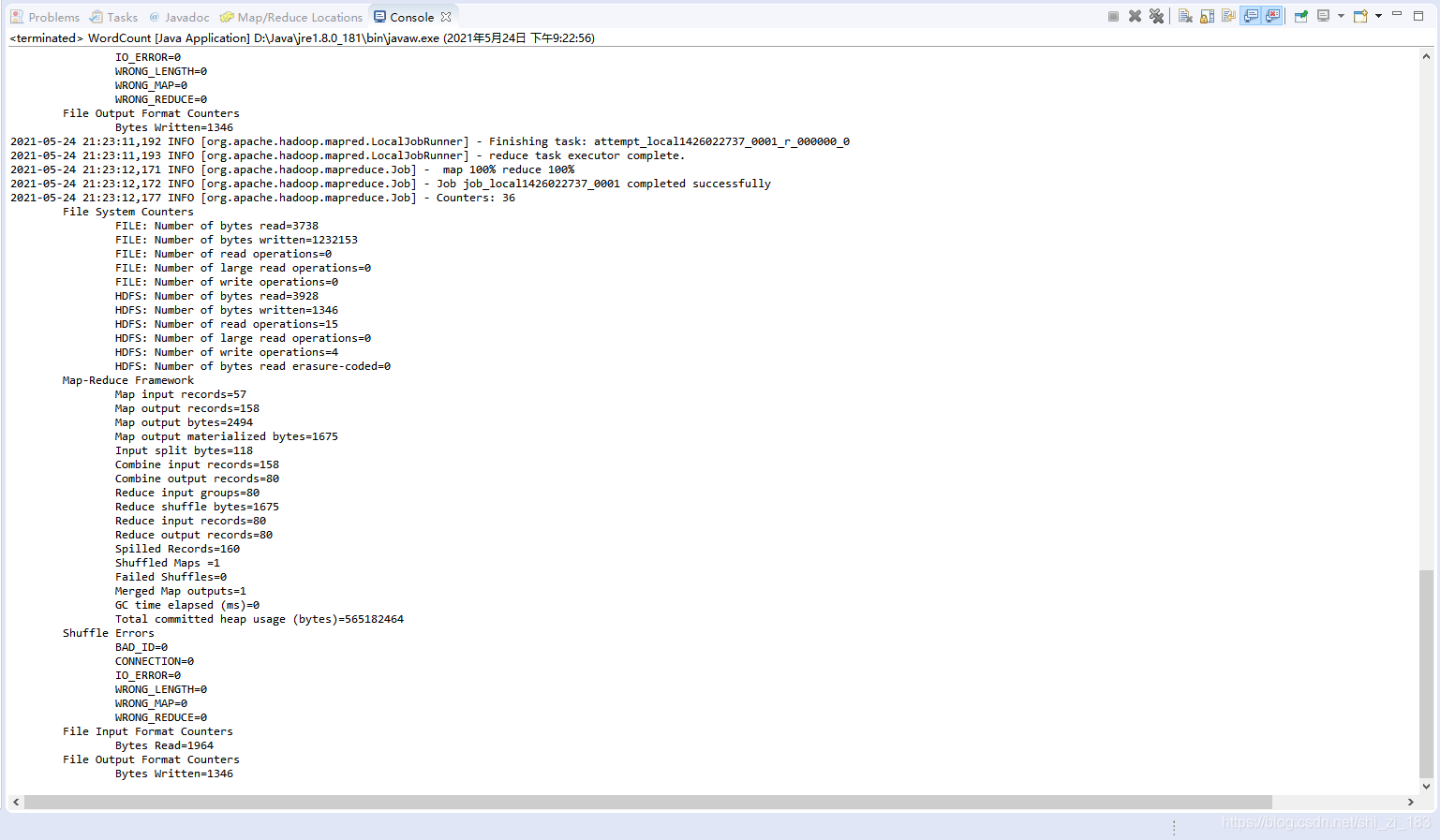
程序正确的输出了,说明我们配置成功了!!!!

- 吴恩达深度学习课程笔记之卷积神经网络基本操作详解
- 大数据IMF传奇行动绝密课程第16课:RDD实战(RDD基本操作实战及Transformation流程图)
- HIVE学习笔记:Hive CLI基本操作
- (学习笔记)MySQL基本操作语句
- 【Git】学习笔记之基本操作
- oracle笔记2--基本sql操作
- opencv3学习笔记1--图像的基本操作
- android笔记-android基本操作和数据存储
- Linux学习笔记8——基本操作讲解
- Linux学习笔记-基本操作3
- SPSS---基本操作(新手笔记一)
- 【VC++ 中使用ADO操作数据库学习笔记】_ConnectionPtr指针的基本用法
- python学习笔记01 使用重复操作创建一个列表和一些基本操作
- Linux学习笔记(三)之目录结构及文件基本操作
- 笔记:git基本操作指令
- Python学习笔记(二):基本数据类型及操作(逻辑、字符串、浮点、复数)
- linux目录结构及文件基本操作学习笔记
- python DataFrame基本操作笔记
- CCNA系列课程(3)CDP及设备基本操作
- STM32学习笔记4---串口通信的基本操作