聊聊Docker监控那点事儿
张健 分布式实验室
现在有很多的开源的Docker监控方案的实现,我们可以很容易的搭建一套监控系统出来;但是如果你有定制化的需求,则需要自己去实现;那么我们该怎么实现呢?需要监控哪些指标呢?这些指标又是什么含义呢?应该怎样去收集呢?本文我们来一起探讨。
这里我不会介绍整个监控系统的架构,也不会去分别介绍存储、告警、展示、通知等等这些模块的实现,因为现在的开源的监控系统基本都包括这些,只会把重点放在Docker的指标上,所以内容会有些干。接触时间也不算太长,如果有错误的地方恳请指正。
监控范围
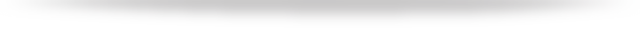
我们把需要监控的对象分为三层,分别是应用层、系统层和虚拟那一层;这里我们主要关注放在在系统层(CPU、memory、IO等等),以及虚拟层(可能包括容器的OOM,运行时间等等),所以我们主要探讨一下对于这方面的监控。
怎样监控
对于CGroup方式,就是通过CGroup的文件来读取这些指标,一般来说在/sys/fs/cgroup目录下面,例如CPU相关的指标/sys/fs/cgroup/cpuacct/docker/$CONTAINER_ID/cpuacct.stat;这里的CONTAINER_ID就是容器的ID。
对于Docker命令行,其实就是通过docker stats来获取:

和上面的命令行一样,Docker API也能实时采集上面的这些指标,有两种方式来开启开启Docker的API功能,分别是添加这样的参数DOCKER_OPTS="-H=unix:///var/run/docker.sock -H=0.0.0.0:6732"来分别开启unix sock和http,其中unix sock方式是默认的。
$ echo -ne "GET /containers/$CONTAINER_ID/stats HTTP/1.1\r\n\r\n" | sudo nc -U /var/run/docker.sock
如果开放了接口,也可以直接通过接口访问,返回是一个很长的json,里面包含了CPU、memory等方面的指标。
那么对这三种采集方式来说,哪一种是最合适的呢,从排除法来看,命令行的方式获取的指标值比较有限,只能拿到基本的CPU、memory使用状况,更详细的没有,所以这个方案只适合做一个粗略的监控,有对于有些时候的排障来说,可能并不够用;再来看看Docker API的方式,这种方式需要每次发送http请求,而且有多少container就发多少次,这个开销也是不小的,所以这个方案最简单但是我们仍然没有考虑;显而易见,最后我们选择了从CGroup文件的方式来获取,下面我们就来细细说一下需要监控哪些指标,以及怎么来采集。
系统监控
CPU
相关的性能指标
user CPU:CPU用户进程的时间百分比
system CPU:CPU执行系统调用的时间百分比
CPU util:总的CPU使用率
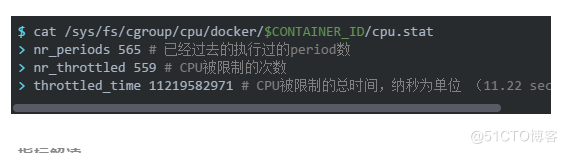
throttling (count):容器的CPU被限制的次数
throttling (time):容器的CPU使用率被限制的总时间
采集方式

在x86系统中,上面的时间是按10毫秒增加,所以上面的CPU在用户进程上消耗24.41秒,在系统调用上消耗9.85秒。

上面是单个CPU使用的时间,如果容器使用的是多核的CPU,那么下面可以获取所有CPU的总的时间:

对于Throttled,可以在cpu.stat中获取:
指标解读
我们知道在Docker中对CPU的限制方式有几种,可以通过--cpu-shares,--cpu-period和--cpu-quota,--cpuset-cpus来配置,具体细节这里不赘述。现在使用最多的方式是--cpu-period和--cpu-quota结合的方式,这时候CPU使用率的上限由两者共同决定,比如说A容器配置的--cpu-period=100000 --cpu-quota=50000,那么A容器就可以最多使用50%个CPU资源,如果配置的--cpu-quota=200000,那就可以使用200%个CPU资源。所有对采集到的CPU used的绝对值没有意义,还需要参考上限。还是这个例子--cpu-period=100000 --cpu-quota=50000,如果容器试图在0.1秒内使用超过0.05秒,则throttled就会触发,所有throttled的count和time是衡量CPU是否达到瓶颈的最直观指标。
另外,不像传统的host,Docker不需要采集CPU的nice,idle,iowait和irq时间。
内存
相关性能指标
Memory:容器的内存使用
RSS:进程除了缓存之外的内存消耗(包括栈和堆内存,等等)
Cache memory:内存中的磁盘数据缓存
Swap:swap使用总量
采集方式
下面的命令会打印出一大堆的关于内存的信息,可能比你需要的多的多:
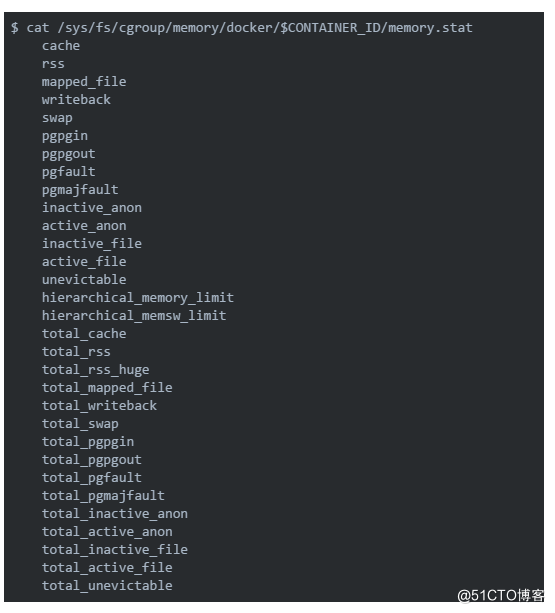
虽然上面得到的很多,但是通常我们更关心的核心指标在/sys/fs/cgroup/memory/docker/$CONTAINER_ID/的其他目录中:
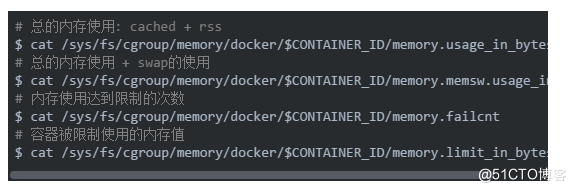
指标解读
使用的内存可以分解为:
RSS:RSS本身可以进一步分解为活动和非活动内存(active_anon和inactive_anon)。必要时,非活动的RSS内存被交换到磁盘。
Cache:反映缓存在当前内存中的磁盘上的数据。缓存可以进一步分解为活动和非活动内存(active_file,inactive_file)。 当系统需要内存时,可以首先回收非活动内存。
虽然cache这部分是可以多个容器共享的,但是在Docker中CGroup判断memory.failcnt是否加一,是根据总的内存(RSS+Cache)是否达到memory.limit来决定。所以如果监控到容器的内存使用量一直上升,需要分清是RSS还是Cache导致的增加,如果是RSS的需要看下应用是否有内存泄露,如果是Cache部分,需要看最后是否能释放。
mem failcnt发生不一定会导致容器OOM,因为有些内存被Cache用到了,OS清理掉一些Cache就没问题了。作为开发者,需要调查下, 给应用划分的Docker内存上限是否合理。因为Cache被清掉就意味着后续有文件读取操作的时候,需要将数据块从磁盘page in到Cache里,如果应用的服务性能比较依赖磁盘上的数据读取性能,就需要关注下。
另外,在调查性能或稳定性问题时可能有价值的其他指标包括page faults,可以表示分段错误或从磁盘而不是内存中获取数据(分别为pgfault和pgmajfault)。
I/O
相关性能指标
I/O serviced:I/O操作的次数
I/O service bytes:读写的byte数
在目录/sys/fs/cgroup/blkio/docker/$CONTAINER_ID/下有IO相关的指标文件,由于系统的差异,下面大部分文件里面的值都是0,在这种情况下,通常还有两个文件可以工作:blkio.throttle.io_service_bytes和blkio.throttle.io_serviced,它们分别记录了总I/O字节和操作。注意别被文件名误导,这里并不是IO throttle的指标。
这些文件里前两个数字是主要:次要设备ID,例如blkio.throttle.io_service_bytes的输出示例:

指标解读
块I/O是共享的,所以容器的I/O是没有作限制的,也就没有类似于throttle这样的指标,那么除了上面提到的容器特定的I/O指标之外,跟踪主机的队列和服务时间也是不错的选择。如果容器使用的块设备上的队列长度或服务时间不断增加,容器的I/O将受到影响。
网络
相关性能指标
Bytes:网络流量(包括接收和发送)
Packets:网络包的个数(包括接收和发送)
Error(receive):接收错误的数据包个数
Error(transmit):传输错误的数据包个数
Dropped:丢弃的包个数(包括接收和发送)
采集方式
与上面不同的是,网络相关的指标不在CGroup的文件夹下,而是采用平常进程的网络指标采集方式(毕竟Docker也是一个进程),在/proc/下获取:
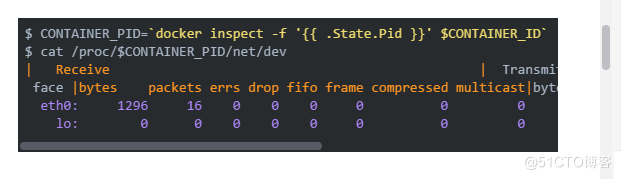
指标解读
同样,网络没有throttle这样的值,衡量时,需要结合网卡的兆数来看。
连接数
相关性能指标
established:建立的连接
close:close状态的连接
close_wait:close_wait状态的连接
time_wait:time_wait状态的连接
……
采集方式
和上面的网络的采集差不多,我们也是通过Docker的pid的方式从/proc/下面去取,具体的文件为/proc/net/tcp和/proc/net/tcp6(如果没有用tcp6可以忽略之)。
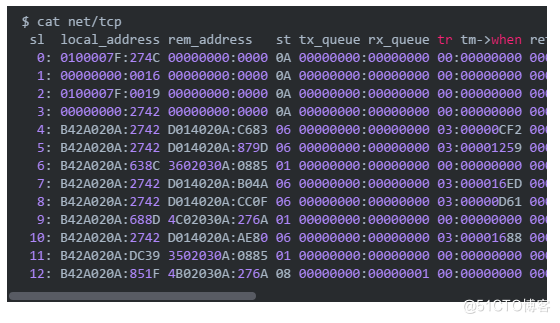
其中关注第四列,st就是连接的状态,用下面的数字来表示,具体到和连接状态的映射关系:

对照映射关系将他们加起来就可以得到对应状态的连接数了。
磁盘
相关性能指标
used:磁盘使用量
used percent:磁盘使用率
对于磁盘的采集,我们没有找到一个简便的方法,现在的做法是侵入到容器内部去采集,类似这样的命令:
`docker exec -i $CONTAINER_PID "df"|grep -v "tmpfs"`
我们来看看直接df之后的结果:
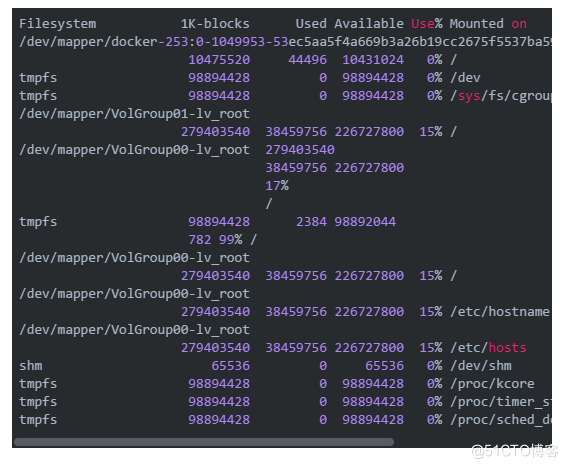
我们去掉tmpts之后,对剩下的解析,Mounted on在根目录下(/)的device mapper就是我们要的那一行,然后就可以分别得到磁盘的used,available和used percent值了。
指标解读
其实在正确的Docker使用中是不会需要采集磁盘容量的,因为我们对文件的写入应该持久化在宿主机的磁盘上。而且这种采集对资源的消耗很大,如果有需要也要酌情设置采集频率。
指标解读
对于这些不同状态的连接,可以按需去采集。
事件监控
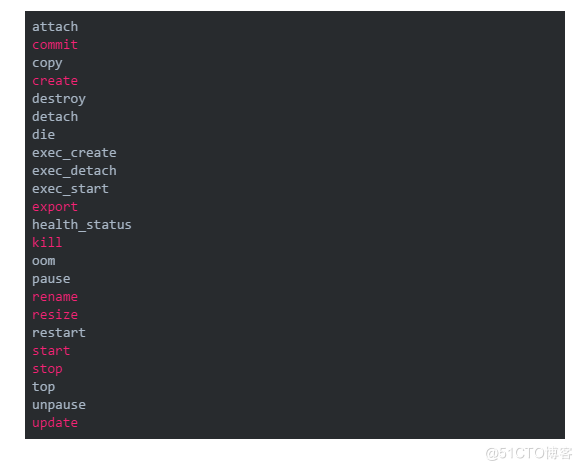
我们可以通过docker events来获取到这些事件,该命令支持一个起始时间--since,也支持按不同的条件过滤,包括容器ID,事件类型等等。
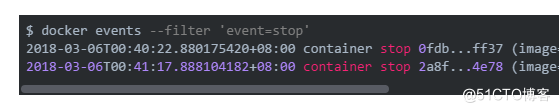
每一行就是一个事件,当然我们不会收集这些所有的事件,但一般会包括OOM,stop,destroy这些。
现成的监控方案
cAdvisor:Google开发的容器监控指标采集,还支持聚合和一些数据处理;
Telegraf:Influxdata开发的收集Agent,这是一个通用的采集Agent,当然也支持Docker,另外该公司还提供了一整套监控方案叫做TICK,也欢迎大家去踩坑;
Prometheus:现在最火的Cloud方面的监控,而且是一整套的解决方案,包括告警、存储等等;
除此之外还有一些收费的方案,例如Datadog、Sensu、Scout等等也提供了另外的选择。

- 聊聊Docker监控那点事儿
- Docker 监控实战
- (原)ubuntu下cadvisor+influxdb+grafana+supervisord监控主机和docker的containers
- Zabbix 监控 Docker容器
- OSSEC安全监控环境搭建(docker+yum)安装
- 使用docker搭建安装zabbix3.2监控平台(一)
- docker安装pmm监控mysql汇总
- 聊聊多线程那一些事儿 之 五 async.await深度剖析
- 【干货】解密监控宝Docker监控实现原理
- zabbix自动发现实现批量监控docker状态
- Weave Scope 多主机监控 - 每天5分钟玩转 Docker 容器技术(81)
- Docker实战系列——第三话–docker 监控(三)– how could we monitoring(3)?
- 八 、DockerUI与Shipyard以及InfluxDB+cAdvisor+Grafana配置监控
- docker日志监控
- 用 Sysdig 监控服务器和 Docker 容器
- zabbix监控docker容器状态【推荐】
- InfluxDB+cAdvisor+Grafana配置Docker监控
- Docker下实战zabbix三部曲之三:自定义监控项
- Docker下实战zabbix三部曲之二:监控其他机器
- 聊聊数据权限哪些事儿