神策数据陈宁:前端国际化技术需求及模型实现
 本文根据神策数据资深前端研发工程师陈宁《前端国际化》的直播整理而成,主要包含以下内容:
本文根据神策数据资深前端研发工程师陈宁《前端国际化》的直播整理而成,主要包含以下内容:
· 国际化概述
· 国际化技术需求
· 国际化技术模型
· 国际化技术模型实现
一、国际化概述
国际化是做框架,帮助快速实施本地化。框架的设计实现决定了进行本地化的效率与质量。那什么是本地化?本地化就是在特定语言文化下,使产品能服务当地客户的使用习惯。
在很多有海外业务的公司里,会有一个专门的国际化部门,或者在当地有一个团队来维护公司产品服务的海外推广和海外交付,海外推广需要打磨产品的国际化质量,在海外客户访问产品时,能给他们提供符合客户语言文化背景的服务;海外交付除了提供优质的服务,还需要在有相关本地化问题的时候,进行快速优化交付。
国际化本质的需求就是效率和质量。效率是横向支持本地化的效率,质量是实施本地化的质量。
国际化在历史中是如何演进的呢?
人力阶段:早期,IT 产品形态不复杂,较少海外需求,国际化往往都是研发人员自己通过修改代码来维护本地化资源。
工具阶段:随着全球化持续推进,随着IT 发展产品形态愈发复杂,几乎所有产品都需要做国际化,为了提高效率,研发会使用脚本来进行批量处理本地化资源,并约定好和产品、外部翻译的工作流程。
平台阶段:在业务规模体量较大的公司,有多个产品需要国际化,此时设计开发出符合公司业务的国际化平台来负责国际化资源的生产维护,负责产品、外部翻译、测试的工作流程,以平台来统一国际化能力。
二、国际化技术需求
国际化框架的核心是对国际化资源的处理,包括:编写、采集、存储、维护。通过框架提高这些行为的效率。
1.编写国际化资源
这里主要解决两个问题:如何标识?如何模块化?
标识是基本要求,有了标识才能处理,而模块化就是为了能对标识进行分类,提供业务意义,提供批量处理的载体。
我们给每一个资源一个单独的 ID 进行标识,那这 ID 怎么设计呢?
神策早期的方案是通过注释来标识,如:“测试”。此时的 ID 不是显示指定的,而是通过特定的编写格式来标明。之后通过代码扫描工具,来实现对文件的批量收集和批量写入。这是一套可行的技术实现,但是效率上并不好,任何变动都需要修改代码进行发版,文案的标识没有进行模块化,不好管理。
技术社区里针对主流 UI 库,提供的对应的国际化工具:vue-il18n、react-intl。它们通过声明式的 ID 来标识资源,比如“intl(‘test’)”,通过代码扫描工具,来实现资源的收集和汇总。这些方案已经很实用了,但是依然有一些问题不能解决:英文 ID 不够直观,对于前端而言,视图中的中文文案有利于快速看明白代码结构;没有直接提供模块化。
以上两种代表了两类编写方式:结构式标识、声明式 ID 标识,可以明显的看出,声明式的 ID 会更好一些。在这个基础上,还需要解决:文案直观、模块化的问题。既然中文更直观,能不能直接用中文呢?最好不要,中文会有一词多译的问题。可以用声明式的简短字符 ID+ 中文注释来标识,兼容声明式 ID 和结构式的优点。注释的部分可以通过脚本来实时更新为最新的中文。
 模块化需要额外来支持,在 ID 中带有模块是一种方法,但是维护起来会容易出错,难以排查。可以通过配置文件,从脚本收集层面来后置的加入模块
模块化需要额外来支持,在 ID 中带有模块是一种方法,但是维护起来会容易出错,难以排查。可以通过配置文件,从脚本收集层面来后置的加入模块
2.采集国际化资源
在代码里编写好之后,国际化资源信息的流转不能仅以分散的代码形式存在,需要有另一个灵活的载体。因此需要将资源从代码里采集出来,获得上下文信息。
如何采集资源呢?人工维护肯定不行,量大、效率低,需要通过一些工具脚本来采集,通过增加代码扫描工具从代码里收集文案。一个比较好的思路是,通过构建过程来收集依赖,构建过程会遍历到所有有效的代码,通过 babel 这样的 ast 处理能力,可以拿到资源标识的上下文。另外也可以自己编写解析器来实现,简单的比如正则。
3.资源国际化存储
我们采集到资源以后,在脚本运行时,资源信息以内存的形式存在,内存输出后,可以以文件的形式存在。如果以文件为载体,可以很好在研发、测试、翻译之间进行信息传递,但是会有传递的效率和操作成本,文件需要通过聊天工具转发,存在于聊天工具的聊天记录里,文件的内容生效,需要被写回到代码里。这些都是成本,降低成本才能带来效率。
相比于文件,一个固定的中转点会是效率更高的事情,如果要这个中转节点的使用成本低,那一个国际化资源维护功能的 Web 项目就是必须的,资源从代码进入到资源维护服务,资源也从维护服务注入到代码的运行时。这中间通过固定 API 来完成交互。
4.资源国际化维护
维护是基于存储的,在使用资源服务存储国际化资源以后,也会提升对应的维护效率,维护的地点是固定的,相比于文件是更优解。
维护的过程包括:增加一门语言、批量翻译、单点翻译、更改文案等。这中间,资源的翻译是重点,提高资源的翻译效率能进一步提高国际化效率。资源的翻译效率取决于翻译官的能力,但我们也可以提供一些额外信息辅助翻译,比如:机器翻译、专业词库、翻译记忆、交叉翻译、翻译确认等。
三、国际化技术模型
针对上一章的分解内容,可以直接给出国际化的技术模型。
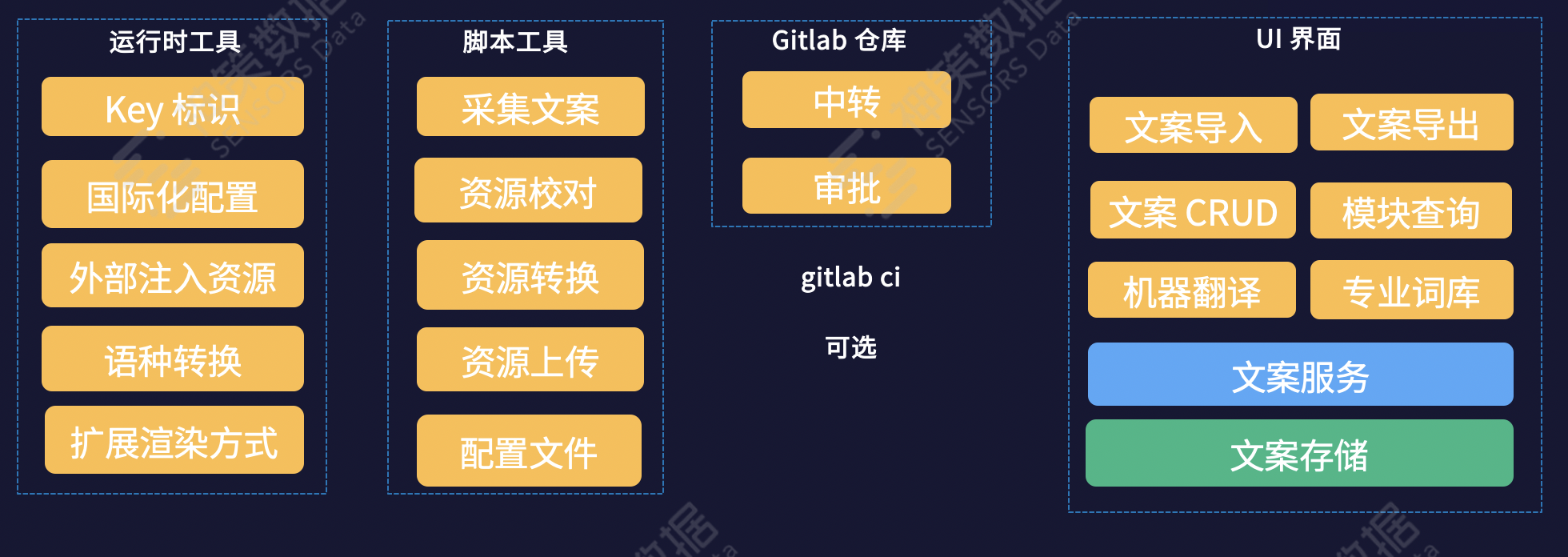
1.运行时
对前端而言,运行时会是一个前端模块,模块会导出一些能力,这些能力汇总为两类:标识资源、完成语言切换。

2.标识资源
通过国际化运行时模块导出的 API,来对代码中的资源进行标识,API 包括单个标识和批量标识,标识要支持模板字符串的写法,可以在运行时动态生成文案 。
3.转换资源
进行资源转换的前提是,拥有资源,因此需要具备资源注入的 API ,通过这个 API 完成国际化资源的注入,资源可以来自于一个网络请求。
在拥有资源后,需要具备一些转化能力,包括基础的字符串转换,单位、时间、颜色转换等。
在进行转换时,需要知道目标语言。
上述的内存可以通过一个统一的“设置配置”API 来完成。
4.翻译上下文环境
针对资源的标识,前端可以进行渲染扩展,这可以为国际化提供一个关键能力:在产品界面上完成国际化修改,这个能力对于国际化校验而言是必须的,实际的产品功能界面中可以提供完善的上下文,这对于批量翻译不是必须的,但是对于翻译校对非常重要,能帮助提高翻译质量。
 那如何实现呢?
那如何实现呢?
本质上是面向资源标识编写组件,完成扩展,运行时转化的过程输入是资源标识,输出是字符串,但是对于前端,可以扩展输出为一个前端组件,在组件内可以完成更多的能力,就比如和资源服务器的交互。
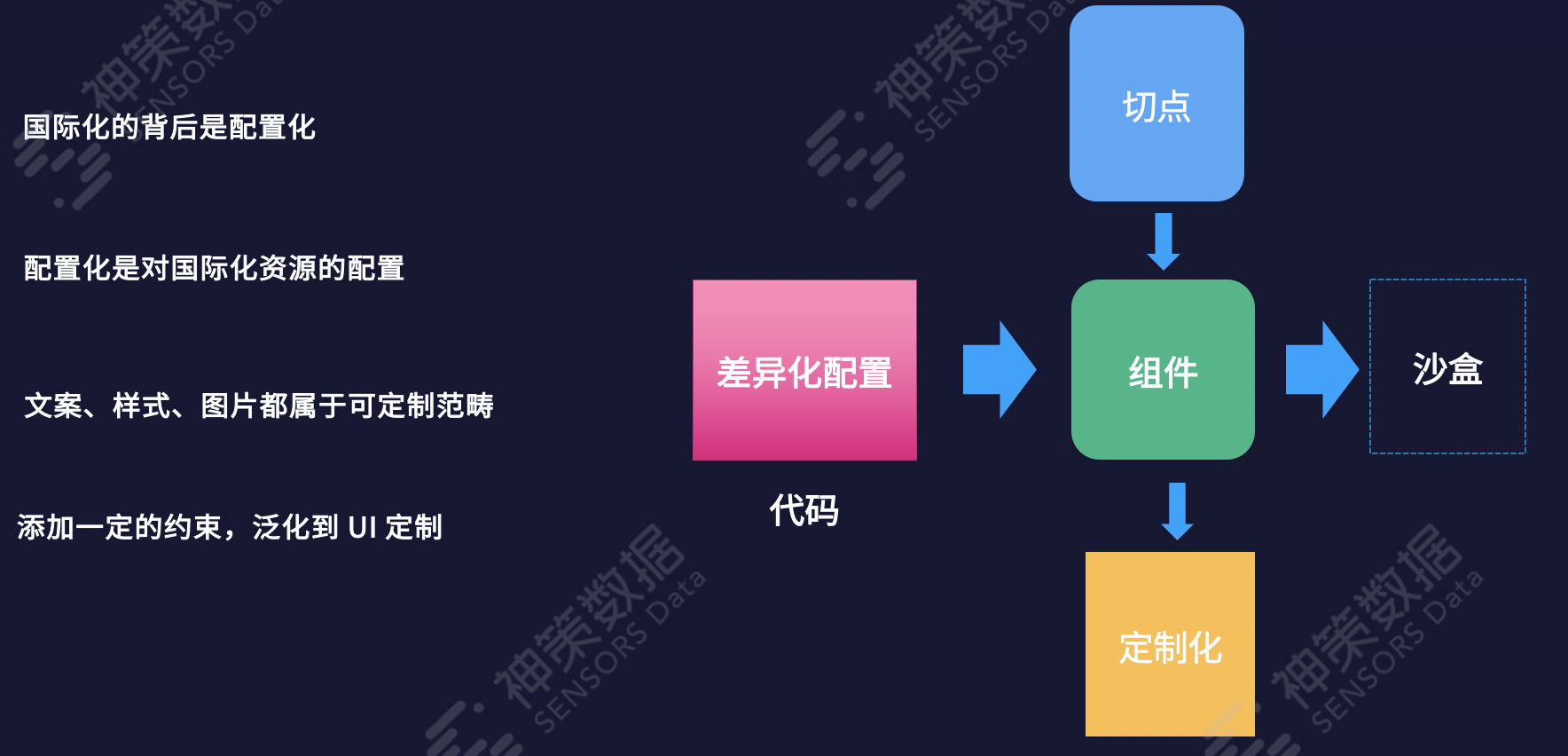 国际化背后是配置化,添加一定的约束后,配置化可以泛化到前端界面的局部定制。
国际化背后是配置化,添加一定的约束后,配置化可以泛化到前端界面的局部定制。
5.脚本工具集
脚本工具的能力是关联代码和国际化资源服务。一条操作路径是:资源采集、模块化、上传到文案服务。另一条资源路径是,本地调试,从资源服务器读取翻译,写成文件到本地,本地依赖。
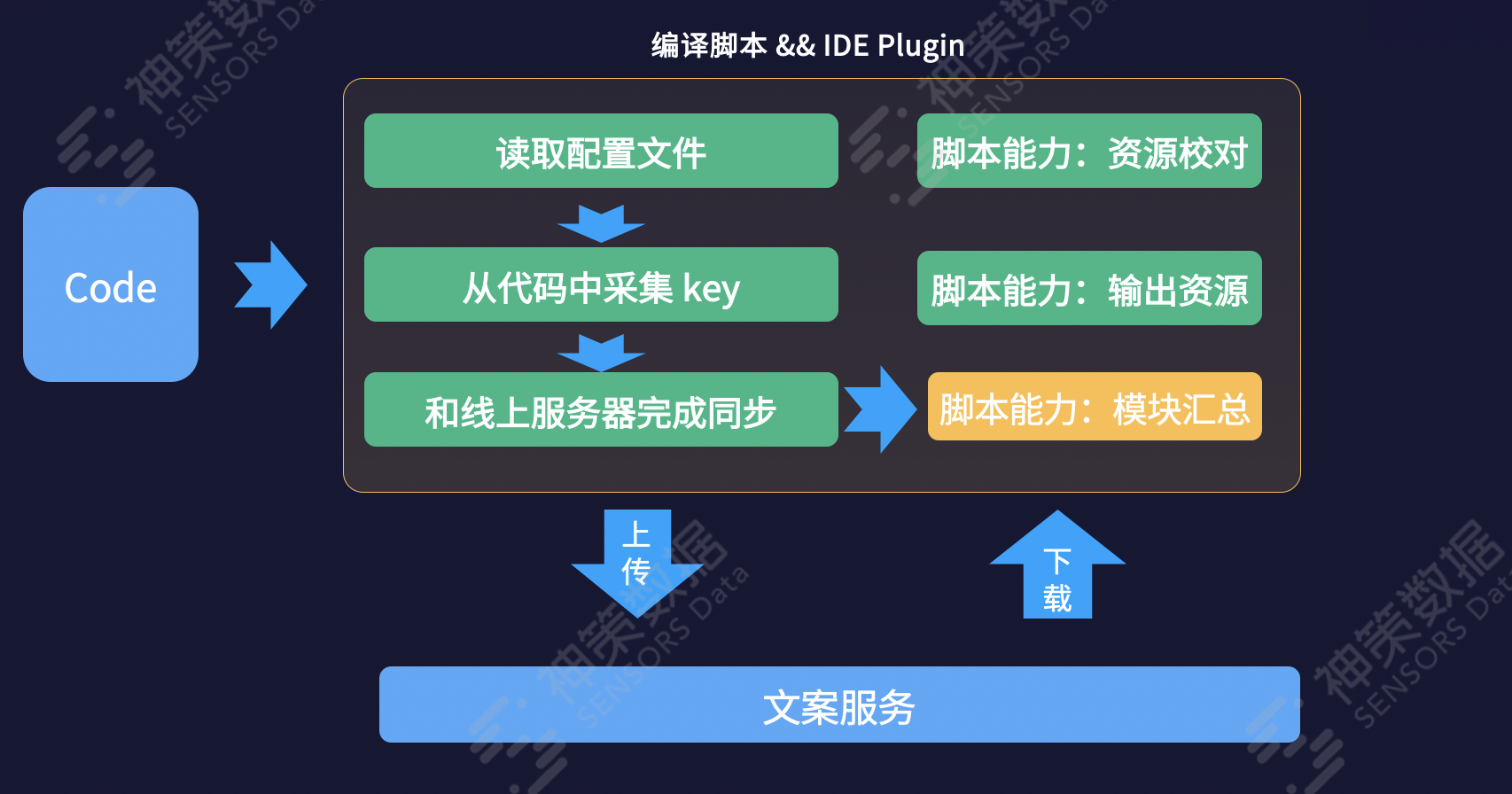 脚本工具可以以 cli 的形式存在,也可以以 IDE Plugin 形式存在。
脚本工具可以以 cli 的形式存在,也可以以 IDE Plugin 形式存在。
6.国际化资源服务
 国际化资源服务是一个单独的平台,用来作为固定的操作中心,让各个角色上来操作。
国际化资源服务是一个单独的平台,用来作为固定的操作中心,让各个角色上来操作。
平台的功能模块包括:资源的 CRUD,资源的查询(模块、版本)、机器翻译、专业词库、翻译记忆等。
下层也提供对应的 httpAPI 来给到第三方调用。
三、国际化技术模型实现
1.神策国际化技术全景
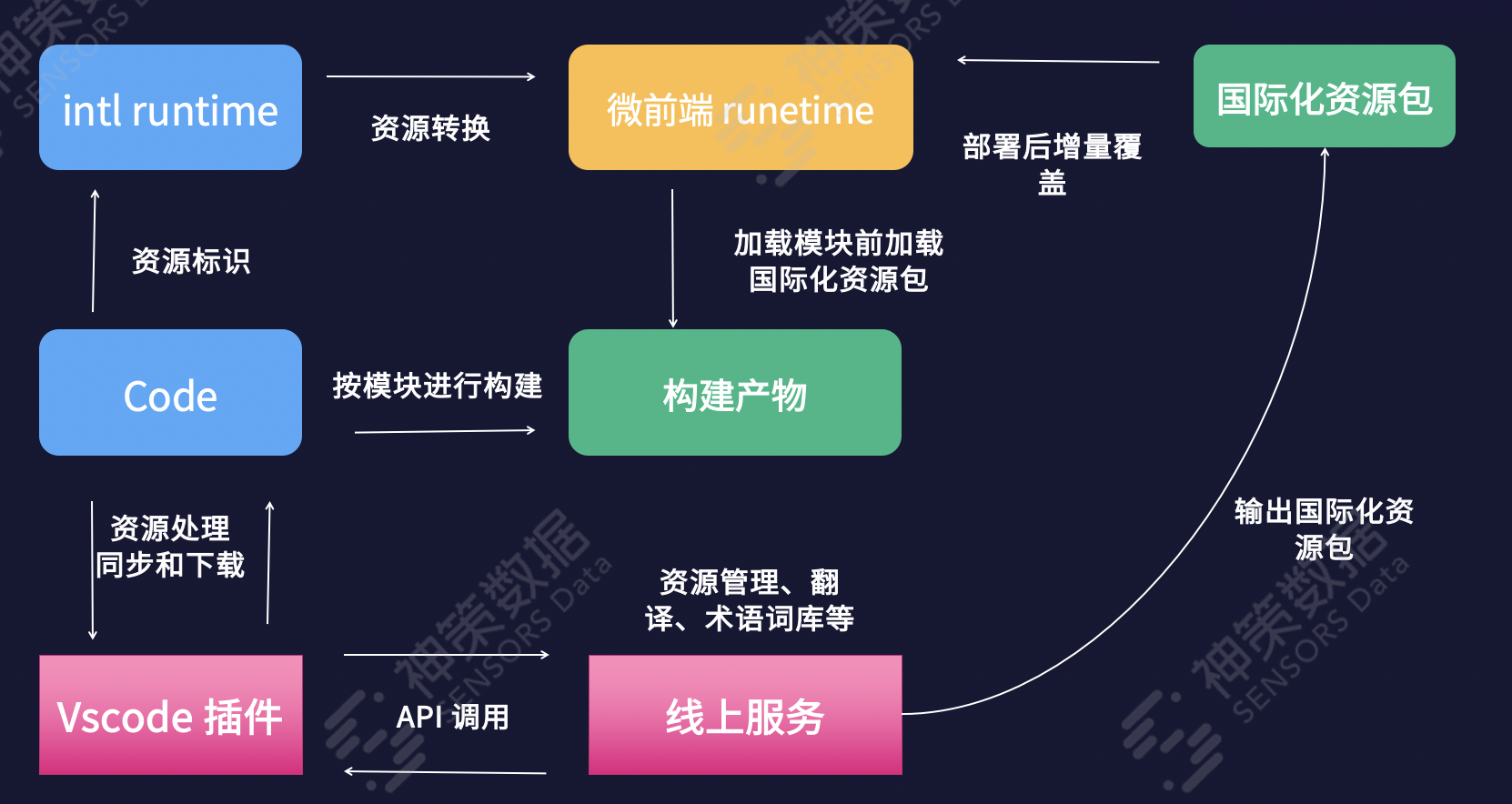 如上图,神策开发了图中的几个功能模块:
如上图,神策开发了图中的几个功能模块:
Intl runtime:用来做资源标识、资源转换、渲染扩展。
Vscode 插件:用来集成国际化脚本,完成资源采集、资源模块化、资源上传,本地翻译同步等。
线上服务:完成资源的管理、机器翻译、专业词库能力,也具备按模块输出资源包的能力。
微前端框架:调用 intl runtime,加载资源、目标语言等;也负责外置国际化资源包的加载,实现无发版更新国际化。
神策因为是私有化部署,因此并没有将自己的服务在外网部署。
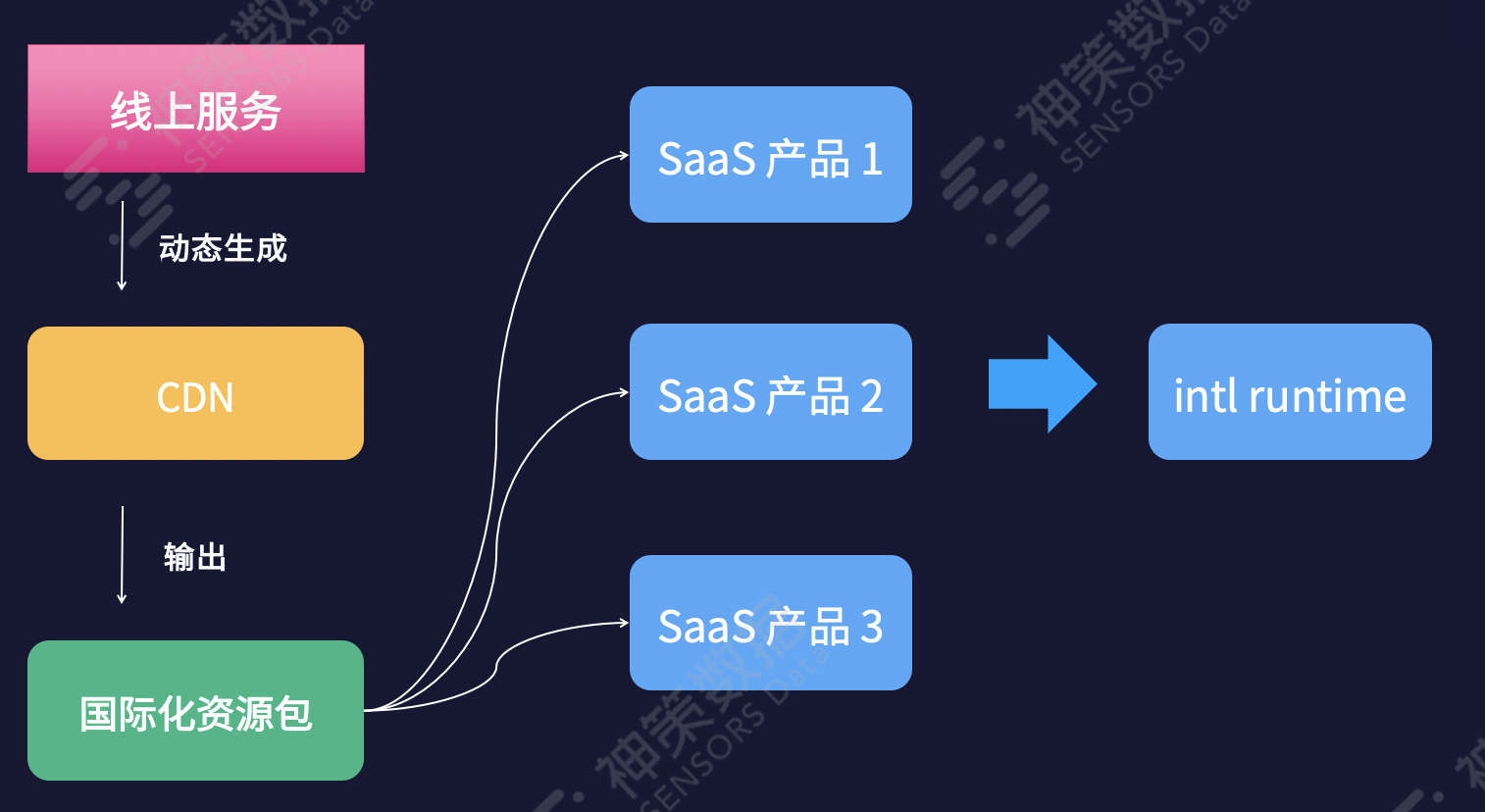
2.SaaS 形式部署资源服务
对于可以访问外网的 Web 产品,可以将自己的资源服务部署到外网,将资源的获取做成 CDN,让自己的产品进行访问,如下图:
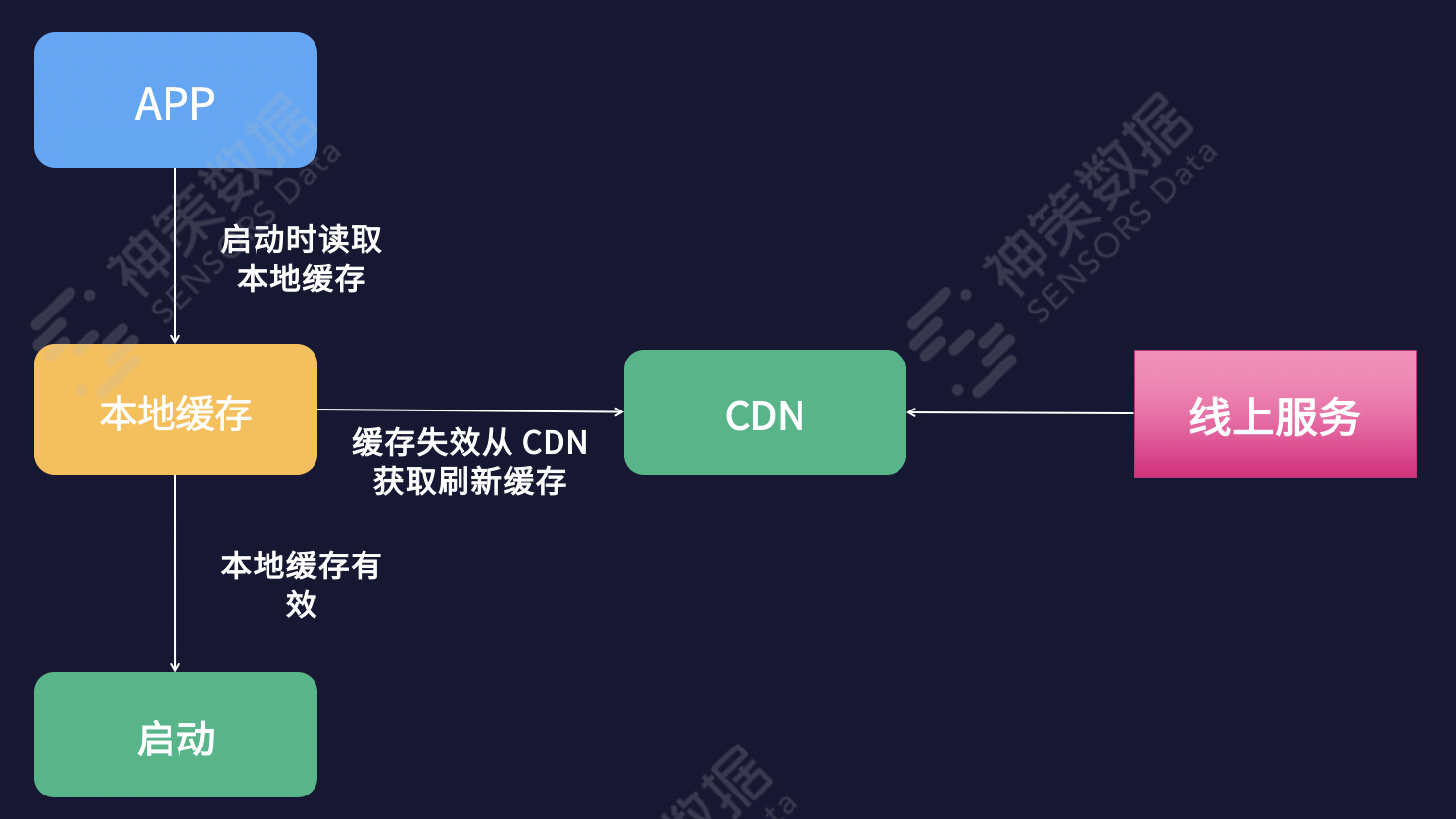
 对于 APP 的赋能,一样通过 CDN,不过 APP 的本地缓存可以减少 CDN 请求。
对于 APP 的赋能,一样通过 CDN,不过 APP 的本地缓存可以减少 CDN 请求。

- 基于jQuery.i18n实现web前端的国际化
- 网页前端的Tribon三维模型展示技术分析
- SP服务商Java短信平台的软件模型和实现(吴宏杰,赵雷,杨季文,苏州大学计算机科学和技术学院)
- Java006--飞机大战项目需求分析和技术实现(附完整代码)
- 使用 jQuery.i18n.properties 实现 Web 前端的国际化
- 聊聊线程技术与线程实现模型
- 使用 jQuery.i18n.properties 实现 Web 前端的国际化
- 使用 jQuery.i18n.properties 实现 Web 前端的国际化
- 从零开始实现Unity光照模型_01_标准光照模型与漫反射_技术美术基础学习记录
- 阿里云OSS文件存储之图片上传技术———前端实现代码
- 如何快速确定需求的技术实现方案
- 利用jQuery.i18n实现web前端的国际化
- iOS前端与后台交互技术实现及技术细节
- 配合dedecms内容模型实现后台输入栏目id前端输出文章列表
- 使用 jQuery.i18n.properties 实现 Web 前端的国际化
- Asp.net项目基于jQuery.i18n.properties 实现前端页面的资源国际化
- 【我的第一个App——私人通讯录】项目需求、实现技术点总结
- jQuery.i18n.properties实现前端国际化
- 【tornado】系列项目(二)基于领域驱动模型的区域后台管理+前端easyui实现
- Entity Framework技术系列之8:使用Entity Framework技术实现RBAC模型