【博客大赛】论python中器的组合
python中有几种特殊的对象,如可迭代对象、生成器、迭代器、装饰器等等,特别是生成器这些可以说是python中的门面担当,应用好这些特性的话,可以给我们的项目带来本质上的提升,装逼不说,这构筑的是代码护城河,祖传代码别人再也不敢动。熟悉特性的概念在和面试官交流的过程中也是挺吃香的不是吗?现在这么卷了,面试官也很少会问到迭代啊、递归啊什么的,反过来说,在社招面试被问到了这种看起来挺浅薄的问题,可能就是挂的节奏了:)嘿嘿,真的,毕竟面试是要有相对应的面试时间的,总要有水题来刷时间啊┑( ̄Д  ̄)┍
三者关系
可迭代对象、迭代器和生成器这三个概念很容易混淆,前两者通常不会区分的很明显,只是用法上有区别。生成器在某种概念下可以看做是特殊的迭代器,它比迭代实现上更加简洁。三者关系如图:
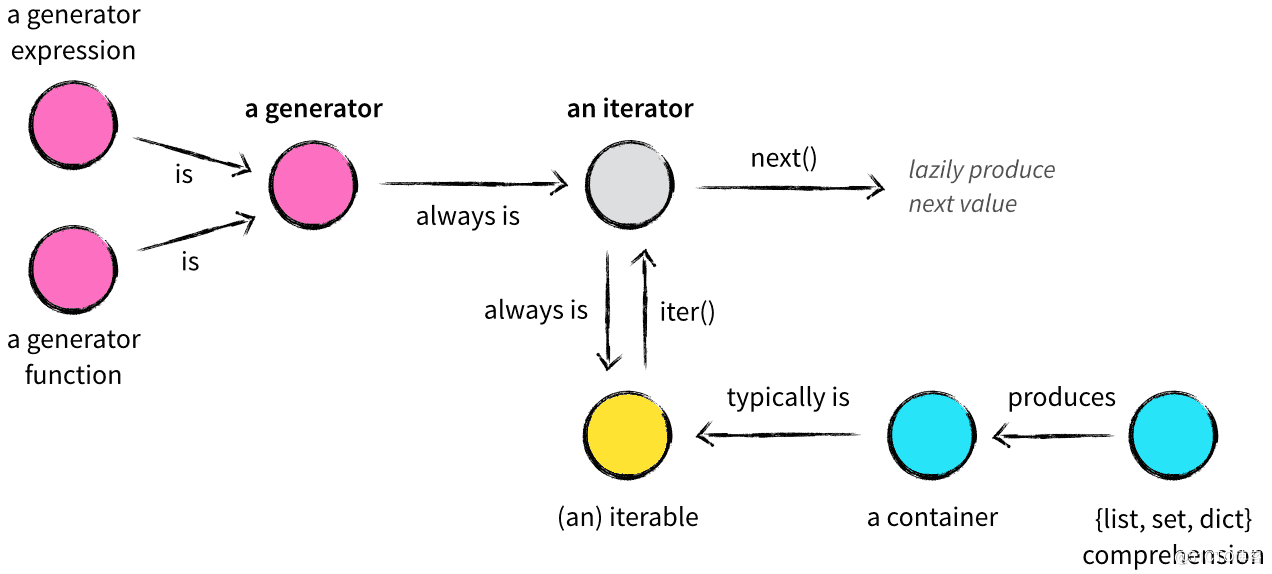
可迭代对象
可迭代对象
Iterable Object,简单的来理解就是可以使用
for或者
while来循环遍历的对象。比如常见的
list、
set、
dict等,可以用以下方法来测试对象是否是可迭代
>>> from collections import Iterable
>>> isinstance('yerik', Iterable) # str是否可迭代
True
>>> isinstance([5, 2, 0], Iterable) # list是否可迭代
True
>>> isinstance(520, Iterable) # 整数是否可迭代
False
本质
可迭代对象的本质就是可以向我们提供一个迭代器帮助我们对其进行迭代遍历使用。 可迭代对象通过
__iteration__提供一个迭代器,在迭代一个可迭代对象的时候,实际上就是先获取该对象提供的迭代器,然后通过这个迭代器来以此获取对象中的每一个数据,这也是一个具备
__iter__方法的对象,就是一个可迭代对象的原因。
from collections import Iterable class ListIter(object): def __init__(self): self.container = list() def add(self, item): self.container.append(item) # 可以通过注释以下两行代码来感受可迭代对象检测的原理 def __iter__(self): pass if __name__ == '__main__': listiter = ListIter() print(isinstance(listiter, Iterable))
通过对可迭代对象使用
iter()函数获取此可迭代对象的迭代器,然后对取到的迭代器不断使用
next()函数来获取下一条数据。
iter()函数实际上就是调用了可迭代对象的
__iter__方法。
迭代器
迭代器是用来记录每次迭代访问到的位置,当对迭代器使用
next()函数的时候,迭代器会返回他所记录位置的下一个位置的数据。实际上,在使用
next()函数的时候,调用的就是迭代器对象的
__next__方法。python3 要求迭代器本身也是可迭代对象,所以还要为迭代器对象实现
__iter__方法,而
__iter__方法要返回一个迭代器,迭代器本身正是一个迭代器,所以迭代器的
__iter__方法返回自身即可.
对所有的可迭代对象调用
dir()方法时,会发现他们都默认实现了
__iter__方法。我们可以通过
iter(object)来创建一个迭代器。
>>> x = [8 ,8 ,8] >>> dir(x) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] >>> y = iter(x) >>> type(x) <class 'list'> >>> type(y) <class 'list_iterator'>
调用
iter()之后,创建一个
list_iterator对象,会发现增加了
__next__方法。我们不妨断言所有实现了
__iter__和
__next__两个方法的对象,都是迭代器。
>>> dir(y) ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']
迭代器是带状态的对象,它会记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。
__iter__返回迭代器自身,
__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出
StopIteration异常。
>>> next(y) 8 >>> next(y) 8 >>> next(y) 8 >>> next(y) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
for 循环的本质
我们经常会写出以下代码:
for item in obj:
实际上这行代码执行了以下4步:
- 判断
obj
是否为可迭代对象,即是否有__iter__
方法 - 在第一步成立前提下, 系统调用
iter()
函数. 得到obj
对象__iter__
方法的返回值,这个其实可以自己显式调用 __iter__
方法的返回值是一个迭代器,有__iter__
和__next__
方法for
不断的调用迭代器中__next__
方法并将值赋给item
, 当遇到Stopiteration
的异常后循环结束.
生成器
利用迭代器,可以在每次迭代获取数据,通过
next()方法时按照特定的规律进行生成,但是在实现一个迭代器时,关于当前迭代到的状态需要自己记录,进而才能根据但前状态生成下一个数据。为了达到记录当前状态,并配合
next()函数进行迭代使用,可以采用更简便的语法,即生成器,其本质上是一类特殊的迭代器。
生成器和装饰器都是python中最吸引人的两个黑科技,生成器虽没有装饰器那么常用,但在某些针对的情境下十分有效。
比如我们在创建列表的时候,可能会受到内存限制(特别是在刷题的时候),容量肯定是有限的,而且不可能全部给他一次枚举出来。这里可以使用列表生成式,但是它有一个致命的缺点就是定义即生成,非常的浪费空间和效率。如果列表元素可以按照某种算法推算出来,那我们可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的
list,从而节省大量的空间。这种一边循环一边计算的机制,称为生成器:
generator。
要创建一个
generator,最简单的方法是改造列表生成式
>>> [x*x for x in range(10)] [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> (x*x for x in range(10)) <generator object <genexpr> at 0x7f8fcc3b5e60>
还有一个方法是生成器函数,同样是通过
def定义,之后通过
yield来支持迭代器协议,所以比迭代器写起来更简单,我们甚至可以下断言道,只要在一个函数中有
yield关键字那么这个函数就不是一个函数,而是生成器
>>> def spam(): ... yield "first" ... yield "second" ... yield "3" ... yield 123 ... >>> spam <function spam at 0x7f8fd0391c80> >>> gen = spam() >>> gen <generator object spam at 0x7f8fcc3b5f68> >>> gen.__next__() 'first' >>> gen.__next__() 'second' >>> gen.__next__() '3' >>> gen.__next__() 123 >>> gen.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
当然一般都是通过
for来使用的,这样不用关心
StopIteration的异常
>>> for it in spam(): ... print(it) ... first second 3 123
更进一步的是将生成器和迭代器进行组合,这里是通过
iter()来实现
>>> for it in iter(spam()): ... print(it) ... first second 3 123
本质上就是在进行函数调用的时候,返回一个生成器对象。使用
next()调用的时候,遇到
yield就返回,记录此时的函数调用位置,下次调用
next()时,从断点处开始。
说实话有的时候,迭代器和生成器很难区分,毕竟
generator是比
Iterator更加简单的实现方式。官方文档写到
Python’s generators provide a convenient way to implement the iterator protocol.
因此完全可以像使用
iterator一样使用
generator,当然除了定义。毕竟定义一个
iterator,需要分别实现
__iter__()方法和
__next__()方法,但
generator只需要一个小小的
yield。
此外
generator还有
send()和
close()方法,都是只能在
next()调用之后,生成器出去挂起状态时才能使用的。
总的来说生成器在Python中是一个非常强大的编程结构,可以用更少地中间变量写流式代码,相比其它容器对象它更能节省内存和CPU,当然它可以用更少的代码来实现相似的功能。现在就可以动手重构你的代码了,但凡看到类似:
def something(): res = list() for ... in iter(...): res.append(x) return res
都可以用生成器函数来替换:
def iter_something(): for ... in iter(...): yield x
python 是支持协程的,也就是微线程,就是通过
generator来实现的。配合
generator我们可以自定义函数的调用层次关系从而自己来调度线程。
实战
通过两个经典例子来真实感受一下迭代器与生成器的妙用
斐波那契数列
用 普通函数,迭代器和生成器来实现斐波那契数列,区分三种
输出数列的前N个数
普通函数
这个其实就是内循环,没啥好说的,经过
max次循环完成输出
def fab(max): n,a,b = 0,0,1 L = [] while n < max: L.append(b) a,b = b,a+b n += 1 return L
Iterator方法
为了节省内存,和处于未知输出的考虑,使用迭代器来改善代码。
class fab(object):
'''
Iterator to produce Fibonacci
'''
def __init__(self,max):
self.max = max
self.n = 0
self.a = 0
self.b = 1
def __iter__(self):
return self
def __next__(self):
if self.n < self.max:
r = self.b
self.a,self.b = self.b,self.a + self.b
self.n += 1
return r
raise StopIteration('Done')
迭代器什么都好,就是写起来不简洁。所以用 yield 来改写第三版。
Generator
def fab(max): n,a,b = 0,0,1 while n < max: yield b a,b = b,a+b n += 1
使用下面来输出
for a in fab(8): print(a)
看起来很简洁,而且有了迭代器的特性。
更进一步
这个是将迭代器和生成器结合起来使用,这个只需要进行一个小小的改动就有的成效
for a in iter(fab(8)): print(a)
树上的应用
斐波那契数列可以说是所有程序猿入门必经的练习,那么对于树的遍历也是非常实用的小窍门,不妨看下leetcode的897. 递增顺序搜索树这道题,按中序遍历将其重新排列为一棵递增顺序搜索树,使树中最左边的节点成为树的根节点,并且每个节点没有左子节点,只有一个右子节点。
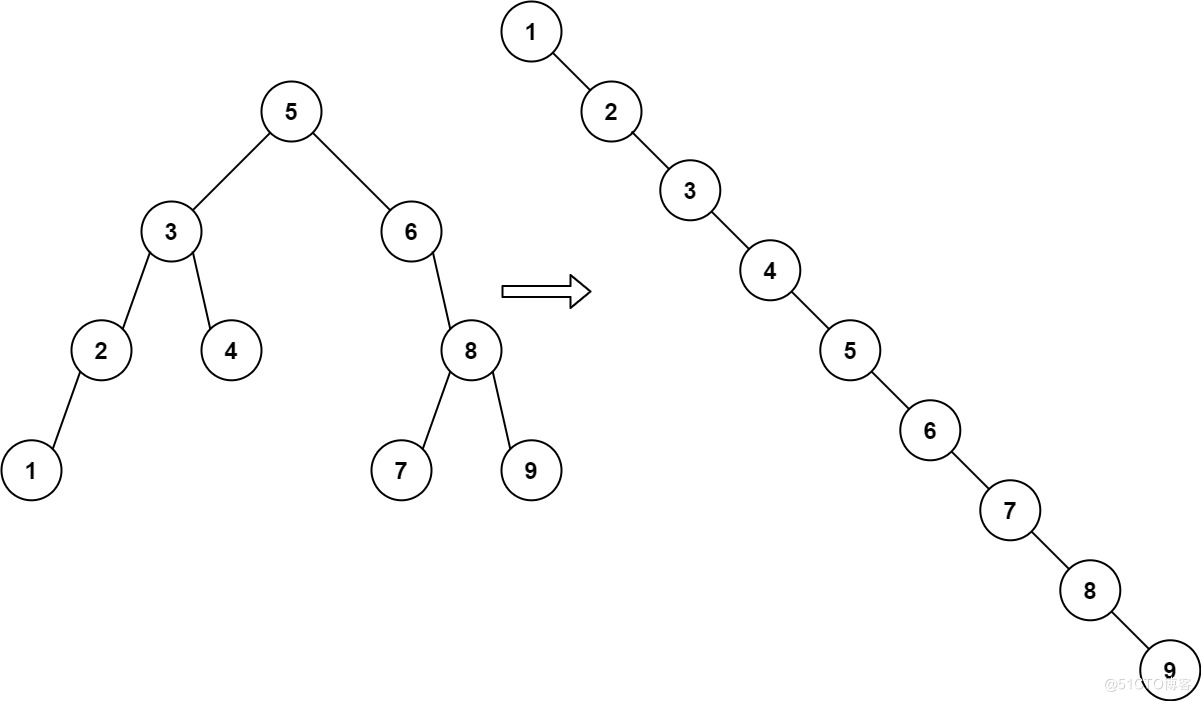
我们用上迭代器与生成器的组合之后得到题解
def increasingBST(self, root: TreeNode) -> TreeNode: def dfs(node: TreeNode): if node: yield from dfs(node.left) yield node.val yield from dfs(node.right) ans = cur = TreeNode() for v in iter(dfs(root)): cur.right = TreeNode(v) cur = cur.right return ans.right
装饰器
装饰器
Decorator是python中最吸引人的特性,其本质上还是一个函数,它可以让已有的函数不做任何改动的情况下增加功能。
非常适合有切面需求的场景,比如权限校验,日志记录和性能测试等等。比如想要执行某个函数前记录日志或者记录时间来统计性能,又不想改动这个函数,就可以通过装饰器来实现。
不用装饰器,我们会这样来实现在函数执行前插入日志
def test():
print('i am tester')
def test():
print('tester is running')
print('i am test')
虽然这样写是满足了需求,但是改动了原有的代码,如果有其他的函数也需要插入日志的话,就需要改写所有的函数,不能复用代码,为了实现代码复用的需求,可以这么改进
def use_logg(func):
logging.warn("%s is running" % func.__name__)
func()
def test():
print('i am tester')
use_log(teat) #将函数作为参数传入
这样写的确可以复用插入的日志,缺点就是显示的封装原来的函数,其实我们更加希望透明的做这件事。用装饰器来写
bar = use_log(bar)def use_log(func):
def wrapper(*args,**kwargs):
logging.warn('%s is running' % func.__name___)
return func(*args,**kwargs)
return wrapper
def test():
print('I am tester')
tester = use_log(test)
tester()
use_log()就是装饰器,它把真正我们想要执行的函数
test()封装在里面,返回一个封装了加入代码的新函数,看起来就像是
test()被装饰了一样。这个例子中的切面就是函数进入的时候,在这个时候,我们插入了一句记录日志的代码。这样写还是不够透明,通过
@语法糖来起到
tester = use_log(test)的作用。
bar = use_log(bar)def use_log(func):
def wrapper(*args,**kwargs):
logging.warn('%s is running' % func.__name___)
return func(*args,**kwargs)
return wrapper
@use_log
def test():
print('I am tester')
@use_log
def haha():
print('I am haha')
test()
haha()
这样看起来就很简洁,而且代码很容易复用。可以看成是一种智能的高级封装。
装饰器也是可以带参数的,这位装饰器提供了更大的灵活性。
def use_log(level):
def decorator(func):
def wrapper(*args, **kwargs):
if level == "warn":
logging.warn("%s is running" % func.__name__)
return func(*args)
return wrapper
return decorator
@use_log(level="warn")
def test(name='tester'):
print("i am %s" % name)
test()
实际上是对装饰器的一个函数封装,并返回一个装饰器。这里涉及到作用域的概念,可以把它看成一个带参数的闭包。当使用
@use_log(level='warn')时,会将
level的值传给装饰器的环境中。它的效果相当于
use_log(level='warn')(test),也就是一个三层的调用。
这里有一个美中不足,
decorator不会改变装饰的函数的功能,但会悄悄的改变一个
__name__的属性(还有其他一些元信息),因为
__name__是跟着函数命名走的。可以用
@functools.wraps(func)来让装饰器仍然使用
func的名字。比如
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
functools.wraps也是一个装饰器,它将原函数的元信息拷贝到装饰器环境中,从而不会被所替换的新函数覆盖掉。
有了装饰器,我们就可以剥离出大量与函数功能本身无关的代码,增加了代码的复用性。
总结
- 容器是一系列元素的集合,如str、list、set、dict、file、sockets对象都可以看作是容器,容器都可以被迭代(用在for,while等语句中),因此他们被称为可迭代对象。
- 可迭代对象实现了
__iter__
方法,该方法返回一个迭代器对象。 - 迭代器持有一个内部状态的字段,用于记录下次迭代返回值,它实现了
__next__
和__iter__
方法,迭代器不会一次性把所有元素加载到内存,而是需要的时候才生成返回结果。 - 生成器是一种特殊的迭代器,它的返回值不是通过
return
而是用yield
。 - 装饰器是一种特殊的闭包,本质上是一个函数
参考资料

- Python之数组拼接,组合,连接
- Python 继承、派生、组合、接口、抽象类
- 某互联网后台自动化组合测试框架RF+Sikuli+Python脚本
- Python(面向对象编程——继承、派生、组合、抽象类)
- python的数学函数(1)-python组合函数模块itertools
- Python 排列组合以及多维数组排序
- Python123测验6: 组合数据类型 (第6周)
- vijos - P1060盒子 (排列组合 + 大数 + python)
- Python 实现将大图切片成小图,将小图组合成大图的例子
- python面向对象编程之组合
- Python中的排列和组合
- 利用python 完成 leetcode 216 组合总和 III
- python中unicode和str的组合
- Python3之继承与组合
- 三儿的Python菜鸟历程--06--Python组合数据类型(理论笔记)
- Python使用超高效算法查找所有类似123-45-67+89=100的组合
- python中的排列组合方法-itertools模块
- Python组合数据
- python基础编程_18_比赛顺序组合
- 设计模式十二(组合模式,python语言实现)