浅谈redis的RDB持久化机制
文章目录
1、RDB简介
Redis有两种持久化形式,一种是RDB快照模式(snapshot),另一种是AOF(Append-Only-file)。
RDB是将当前的数据集快照写入磁盘, Redis 重启动时, 可以通过载入 RDB 文件来还原数据库的状态。假如Redis没有持久化机制,可不可以,可以!当成纯内存使用,禁止所有持久化机制,追求高性能。
RDB 功能最核心的是
rdbSave和
rdbLoad两个函数,
rdbSave用于生成 RDB 文件到磁盘, 而
rdbLoad则用于将 RDB 文件中的数据重新载入到内存中。
在
rdbsave将快照写入RDB文件的时候,如果文件已经存在,则新的RDB文件会将已有的文件覆盖。
2、如何触发
RDB是怎么工作的?只要安装好resdis可以了么?当然不是!!!
RDB有两种方式可以触发RDB持久化,这里说的RDB持久化,指的是一次将当前的数据集快照写入磁盘的操作。分别是
通过执行命令手动触发和
通过配置redis.conf文件自动触发。
2.1 手动触发
手动触发redis有两个指令,分别是
save和
bgsave。
save
: 该线程会阻塞当前redis服务器,执行save指令期间,redis不能处理其他的命令,直到RDB持久化完成。如果RDB文件较大,会产生比较大的影响,生产上谨慎使用。bgsave
:为了解决save
命令存在的痛点,bgsave
会异步执行RDB持久化操作,不会影响redis处理其他的请求。Redis服务器会通过fork
操作来创建一个子进程,专门处理此次的RDB持久化操作,完成后自动结束。Redis只会在fork
过程中发生阻塞,而且时间较短,当然,fork
时间也会随着数据量变大而变长,需要占用的内存也会加倍。
save和
bgsave命令都会调用上面说的
rdbsave方法,只是方式不一样。
2.2 自动触发
需要配置
redis.conf文件:
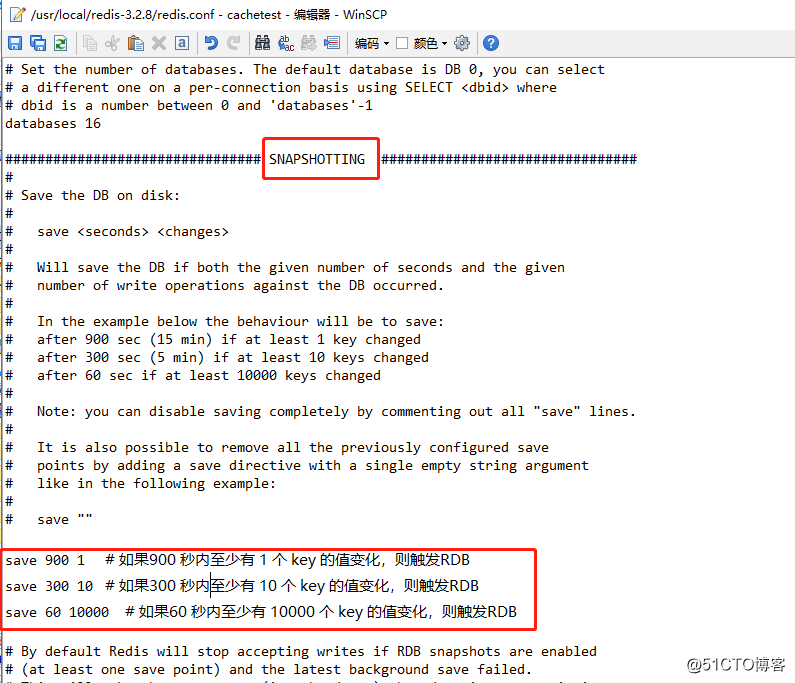
save 900 1 # 如果900 秒内至少有 1 个 key 的值变化,则触发RDB save 300 10 # 如果300 秒内至少有 10 个 key 的值变化,则触发RDB save 60 10000 # 如果60 秒内至少有 10000 个 key 的值变化,则触发RDB
如何关闭自动触发?
只需要注释掉上面的代码,或者直接用空字符串即可。
save ""
如果使用命令行操作就是
redis-cli config set save " "
2.2.1 自动保存的原理
为什么配置了就可以了?底层的机制是什么?
redis有一个周期操作函数
serverCron,默认是每100毫秒就会执行一次,只要服务器在运行,这个函数也就一直在工作,检查save设置的条件是否有被满足,这个是
serverCron函数的其中一个功能,如果满足,就会执行
bgsave。基本所有的RDB操作都是默认使用
bgsave,而不是
save。
除了上面说的save参数之外,我们来看看其他的和RDB相关的配置
save 900 1
[ul]配置触发RDB持久化的条件
stop-writes-on-bgsave-error yes默认是yes,这个配置意思是如果启动RDB持久化,那么如果后台保存数据失败,redis是否会停止接受数据。这蛮好的,能起到告警的作用,如果redis持久化有问题了,能够反映到redis本身的读写上来。
rdbcompression yes
- 默认是yes,也就是对rab快照到磁盘的内容,是不是要启动压缩,压缩会默认使用LZF算法压缩。压缩的好处是:快照会比较小,占用空间小。不压缩的好处是:节省CPU资源,毕竟压缩是需要消耗CPU的计算型任务。
rdbchecksum yes
- 由于RDB的版本5在文件的末尾放置了一个CRC64校验和。这使得格式更能抵抗破坏,但是在保存和加载RDB文件时,要付出大约10%的性能代价,所以可以禁用它以获得最大的性能。禁用校验和后创建的RDB文件的校验和为零,这将告诉加载代码跳过校验。
dbfilename dump.rdb
- 设置快照的文件名
dir ./
- 设置快照的存放的目录,注意是目录而不是文件,默认和当前的配置文件是反正同一个目录。
说起自动保存,我们需要从源码解读,redis的
server.h中有一个结构体数组
redisServer,里面有一个配置
struct saveparam *saveparams; /* Save points array for RDB */
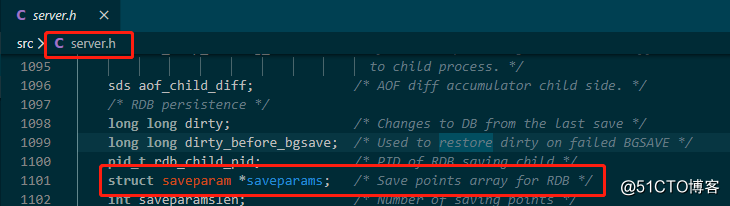
struct redisServer {
...
struct saveparam *saveparams; //记录了save保存触发条件点的数组
long long dirty; //修改的次数
time_t lastsave; //上一次执行保存的时间
...
};这个
saveparam结构体有两个属性,一个是秒数,一个是修改数:
struct saveparam {
time_t seconds;
int changes;
};除此之外,还有两个属性比较重要,也是在
redisServer中:
- dirty:记录了上次执行save或者bgsave命令之后,到现在,一共发生了多少次修改
- lastsave:UNIX的时间戳,保存了最后一次执行保存命令的时间。
我们来看看这段检查代码,也在redis.c
中
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
int j;
......
/* 检查正在进行中的后台保存或AOF重写是否已终止。 */
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
ldbPendingChildren())
{
int statloc;
pid_t pid;
// 查看这个进程是否正常返回信号
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
if (pid == -1) {
// 异常处理
serverLog(LL_WARNING,"wait3() returned an error: %s. "
"rdb_child_pid = %d, aof_child_pid = %d",
strerror(errno),
(int) server.rdb_child_pid,
(int) server.aof_child_pid);
} else if (pid == server.rdb_child_pid) {
//成功持久化 RDB 文件,调用方法用心的RDB文件覆盖旧的RDB文件
backgroundSaveDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else if (pid == server.aof_child_pid) {
// 成功执行 AOF,替换现有的 AOF文件
backgroundRewriteDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else {
if (!ldbRemoveChild(pid)) {
serverLog(LL_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long)pid);
}
}
updateDictResizePolicy();
closeChildInfoPipe();
}
} else {
/* 如果没有后台保存/重写正在进行中,检查是否我们现在必须保存/重写。*/
for (j = 0; j < server.saveparamslen; j++) {
//计算距离上次执行保存操作多少秒
struct saveparam *sp = server.saveparams+j;
/* 如果我们达到了给定的更改量,并且最新的bgsave是成功的,或者在出现错误的情况下,至少CONFIG_BGSAVE_RETRY_DELAY秒已经过去,那么就进行保存。*/
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DEL
8000
AY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
// 启动bgsave
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
......
}rdbSaveBackground函数在哪里呢?怎么实现的,我们看看
rdb.c文件中。
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
long long start;
// 如果已经有aof或者rdb持久化任务,那么child_pid就不是-1,会直接返回
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
//bgsave之前的dirty数保存起来
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
//打开子进程信息管道
openChildInfoPipe();
// 记录RDB开始的时间
start = ustime();
// fork一个子进程
if ((childpid = fork()) == 0) {
//如果fork()的结果childpid为0,即当前进程为fork的子进程,那么接下来调用rdbSave()进程持久化;
int retval;
/* Child */
closeListeningSockets(0);
redisSetProcTitle("redis-rdb-bgsave");
// 真正在子进程里调用rdbsave
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty(-1);
if (private_dirty) {
serverLog(LL_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
server.child_info_data.cow_size = private_dirty;
sendChildInfo(CHILD_INFO_TYPE_RDB);
}
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* 父进程 */
// 更新fork进程需要消耗的时间
server.stat_fork_time = ustime()-start;
// 更新fork速率:G/秒,zmalloc_used_memory()的单位是字节,所以通过除以(1024*1024*1024),得到GB信息,fork_time:fork时间是微妙,所以得乘以1000000,得到每秒钟fork多少GB的速率;
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
// fork子进程出错
closeChildInfoPipe();
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %d",childpid);
// 最后需要记录redisServer中的变量值
server.rdb_save_time_start = time(NULL);
server.rdb_child_pid = childpid;
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
updateDictResizePolicy();
return C_OK;
}
return C_OK; /* unreached */
}3、删除rdb文件能不能恢复?
先说结论,结论是如果只开启了RDB持久化
首先我们写入了两对
set hello world set hello2 world
突然想看rdb文件,心血来潮啊这是,
直接打开,完蛋,有很多乱码,大概能看到redis版本,以及刚刚写进去的那两个键值对。

于是乎使用神器Vs Code,下载一个插件,hexdump,打开文件之后,对准文件右键,
show hexdump,好家伙,出来了。里面其实也是差不多,可以看到个大概。
Offset: 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
00000000: 52 45 44 49 53 30 30 30 37 FA 09 72 65 64 69 73 REDIS0007z.redis
00000010: 2D 76 65 72 05 33 2E 32 2E 38 FA 0A 72 65 64 69 -ver.3.2.8z.redi
00000020: 73 2D 62 69 74 73 C0 40 FA 05 63 74 69 6D 65 C2 s-bits@@z.ctimeB
00000030: 9C BD A5 5E FA 08 75 73 65 64 2D 6D 65 6D C2 08 .=%^z.used-memB.
00000040: 3B 0C 00 FE 00 FB 02 00 00 05 68 65 6C 6C 6F 05 ;..~.{....hello.
00000050: 77 6F 72 6C 64 00 06 68 65 6C 6C 6F 32 06 77 6F world..hello2.wo
00000060: 72 6C 64 32 FF C0 E6 1E 14 9F CB 5F 15 rld2.@f...K_.我们先看看redis的进程是什么?
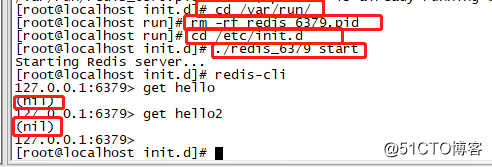
ps -ef | grep redis root 953 1 0 16:34 ? 00:00:02 /usr/local/bin/redis-server 127.0.0.1:6379 root 1297 1241 0 16:54 pts/0 00:00:00 grep --color=auto redis root 1300 1241 0 16:55 pts/0 00:00:00 grep --color=auto redis
上面可以看到server的是953,我们先快速删除掉rdb文件,然后快速使用kill -9杀死redis进程

关闭这个进程了,但是这个时候我们去重启redis会遇到一个问题,那就是pid文件没有删掉,会提示
/var/run/redis_6379.pid exists, process is already running or crashed.
我们必须手动去删除pid的文件,再手动重启redis,会发现所有的数据都丢失了。
4、RDB的优点和缺点
4.1 优点
(1)RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备份,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说Amazon的云服务上去,在国内可以是阿里云的ODPS分布式存储上,以预定好的备份策略来定期备份redis中的数据。
(2)RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可。
(3)相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis进程,更加快速。因为AOF存放的是指令日志,所以数据恢复的时候需要回放每一个操作,也就是执行所有之前的过程来进行数据恢复。RDB是直接将数据加载到内存中。
4.2 缺点
(1)如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据。RDB不适合做第一优先的恢复方案,可能数据恢复地比较多。也就是说从最后一次备份开始到出现故障那一段时间,所有的数据修改都会丢失。
(2)RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。所以一般不能让RDB的间隔太长,这样每次生产的RDB文件太大了,会对性能有一定影响。
此文章仅代表自己(本菜鸟)学习积累记录,或者学习笔记,如有侵权,请联系作者删除。人无完人,文章也一样,文笔稚嫩,在下不才,勿喷,如果有错误之处,还望指出,感激不尽~
技术之路不在一时,山高水长,纵使缓慢,驰而不息。
公众号:秦怀杂货店


- Redis入门之浅谈rdb持久化机制
- (六)高并发redis学习笔记:redis的RDB持久化机制配置以及数据恢复的实验
- redis持久化机制之RDB(一)
- 谈谈Redis中两种常用持久化机制RDB和AOF
- Redis提供的持久化机制(RDB和AOF)【转载】
- Redis提供的持久化机制(RDB和AOF)
- Redis两种持久化机制(RDB,AOF)
- Redis的两种持久化机制RDB和AOF
- Redis提供的持久化机制(RDB和AOF)
- 【redis源码分析】RDB持久化机制
- Redis——持久化机制(RDB和AOF)
- Redis系列(三):Redis的持久化机制(RDB、AOF)
- 详细解释Redis中两种持久化机制RDB和AOF
- (五)Redis的持久化机制,RDB与AOF原理分析
- Redis--RDB机制和AOF机制持久化以及数据备份
- Redis提供的持久化机制(RDB和AOF)
- 25 图解分析redis的RDB和AOF两种持久化机制的工作原理
- Redis提供的持久化机制(RDB和AOF)
- Redis入门之浅谈aof持久化机制
- Redis 持久化方式 - RDB 和 AOF 配置及 rewrite 机制