实战SQL优化之340行从7分15s到24s的优化历程

花费了我将近一天半的工作时间,在几近放弃的情况下完成的一个逆袭,我也算是拼了一把。
环境:阿里云 ECS 11.2.0.1 ADG Oracle
环境分析
前几天优化了一条SQL搞定以后,以为晚上日终批量报表没有问题了,然后昨天想着检查一下,看awr报告,截取晚上1点到2点的时间段,赫然映入眼帘。SQL换了,四条完全类似的SQL语句,有300多行,着实吓了一条,和开发了解到,这四条SQL其实差不多算是一条SQL,只是最后取模的的值分为1,2,3,4,所以运行了4次,可是每一次都将近400s,
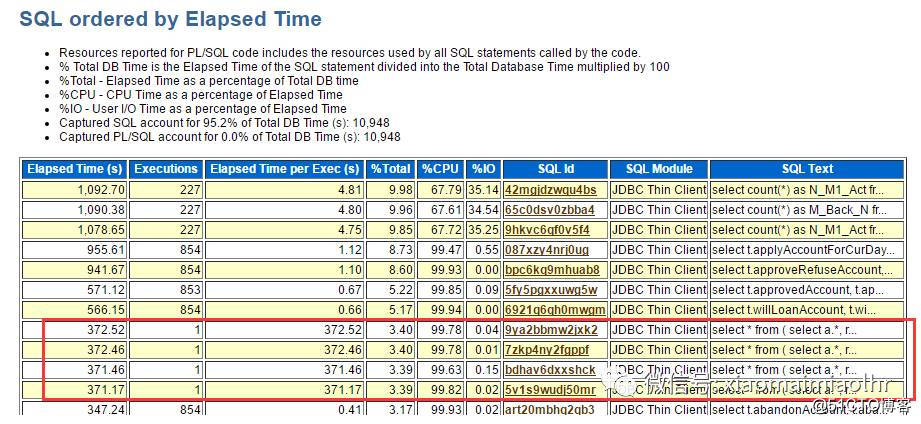
然后就手动的执行了其中的一条语句,取得是模为2的为例进行执行如下:
(由于语句有340行,太长,这里截取片段)
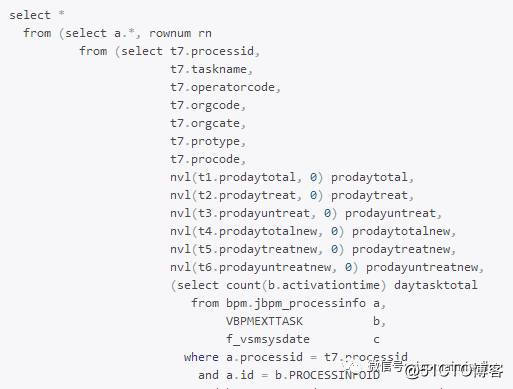


语句大概类似这样的一个结构。
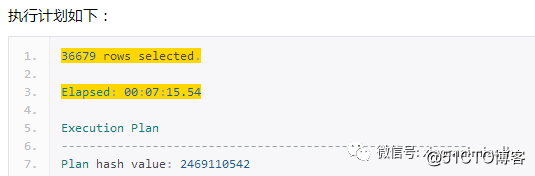
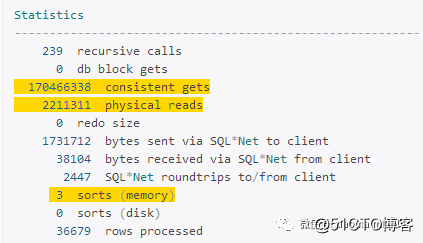
分析来看,总共要得到37000条左右的数据,逻辑读1.7亿,物理读220w,3次内存排序,耗时7分15s;
从执行计划上看,SQL语句多次回表,并且其中还有一些超过400w的表,并且都是全表扫描。然后我们来分析一下SQL语句和执行计划,从执行计划看是不是觉得此起彼伏挺有规律的,然后看看眼瞎的那条300多行的SQL语句,7个标量子查询和t1到t6的6张结果集表,都有很相同的部分,7个标量子查询查的数据都是count(b.activationtime),只不过是因为条件不同,所得到的值不同而已,t1 - t6 的6张结果集表的语句同样查询的结果集字段都是一样的,只不过也是因为条件的不同而不同罢了。
那么到这里,可以很明确的表示,这个SQL写的无比的烂,等于平白无故的多扫了多次的大表,并且,进行了冗余的hash连接,导致资源消耗巨大。
其中总结出来的,不同的条件就是:
trunc(b.activationtime, 'dd') = c.BUSINESSDATE
trunc(b.completetime, 'dd') = c.BUSINESSDATE
trunc(b.completetime, 'dd') is null
b.tasktypeflag = '00'
trunc(b.activationtime, 'dd') <= c.BUSINESSDATE
标量子查询中和t7关联的条件都是相同的:
a.processid = t7.processid
b.operatorcode = t7.operatorcode
b.taskname = t7.taskname
而t1到t6的6张表来说,都类似如下:

同样也是因为如上所写的不同条件的组合导致的结果集不同,进而被简单罗列成了多张表。
然后导致,最后出现了几十条外链接的条件。类似如下形式:
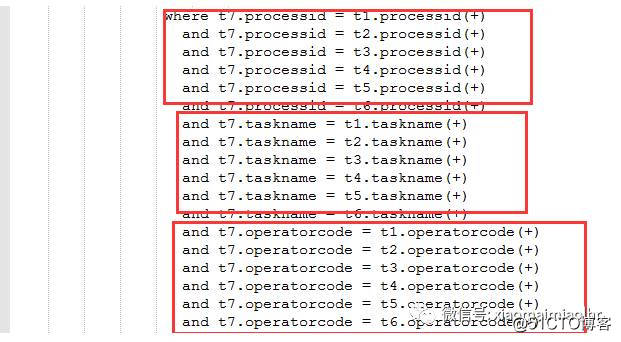
所以改写势在必行,也是唯一的方式。
第一次尝试的描述
所以就之前的分析思想,进行了第一次改写,但是虽然有了减少回表,减少冗余表连接的思想以及集合的思想在内,但是并没有实质性的改变,只是简单的将数据t1到t6表的集合放到了一起,然而标量子查询因为无法从一个集合衍生出如原标量查询出的结果集,导致无法修改标量子查询,所以修改后的结果收效甚微,修改如下:

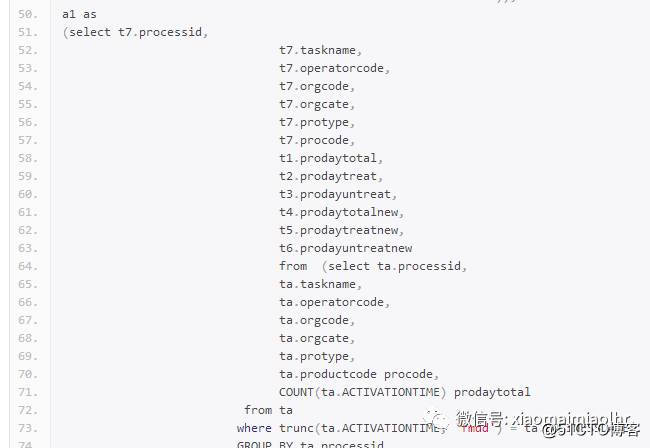

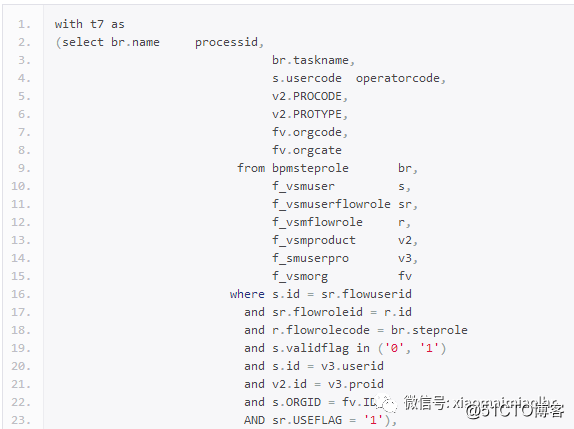
这里简单介绍就是将t7表,已经t1-t6表的公共部分拿出来写成了with as语句,然后将外联接的查询全部拿了出来做呈了with as查询,进行的改写形式。
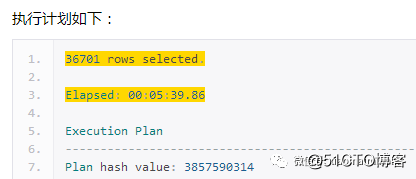
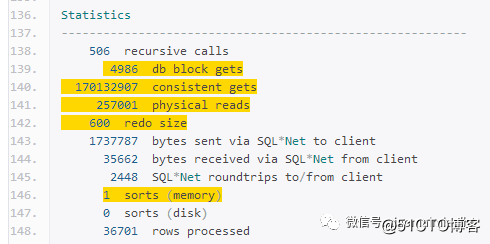
我们看到时间从7分15s降到了5分39s,逻辑读没有什么变化依然1.7亿,物理读25w下降近10倍,内存排序从3次到1次,要说有效果也是有的,但是依然很慢啊。然后就再思考原因,其实这里的第一次修改之后好处是,将t1-t6这6张表,进行了一次合并排序,然后再根据条件的不同再组合出这6张表,这就减少了一些回表的资源消耗,但是标量那里的资源消耗依然没有减少,因为标量查询压根就没有改过。
之所以没有进行修改,之前也提到了,按照我这种集合思路来看,修改之后,好像是可以进行集合一次再根据条件的不同组合进行得到不一样的值,但是事实证明得到的结果对应列所在行的数据全部都一样,也就是说这种方式是不行的。
第二次修改的尝试
然后我就开始考虑第二种思路:
大致思路如下:
然后我们将标量的查询拿出来和t1-t6这6张表的语句拿出来看的话,发现,t1-t6的子查询当中包含有标量子查询的一些部分表和条件。而标量子查询中部分条件是和t7表做的关联,而t1,t3,t4,t6四张表其实和合为一张表,然后把不同的条件所得到的count(b.activationtime)值,都放到同一个子查询当中,作为列,类似t2,t5也是一样的效果,然后就可以把6次回表变成2次。
再来看标量子查询,其实还是一样针对trunc(b.activationtime, 'dd') <= c.BUSINESSDATE条件的不动,还是标量子查询,因为它和前边的6个标量子查询不太一样。而对于这6个标量子查询来说,还是按顺序1,3,4,6类似,2,5类似,也可以这样进行关联,同样也是为了将多次回表减少。
这里采用的技术就是,针对count来说,可以在子查询中使用decode,case when语句,来根据条件设置默认值,我这里设置条件为真为1,条件为假为0,然后sum集合,其得到的效果和count是一致的。
修改语句如下:

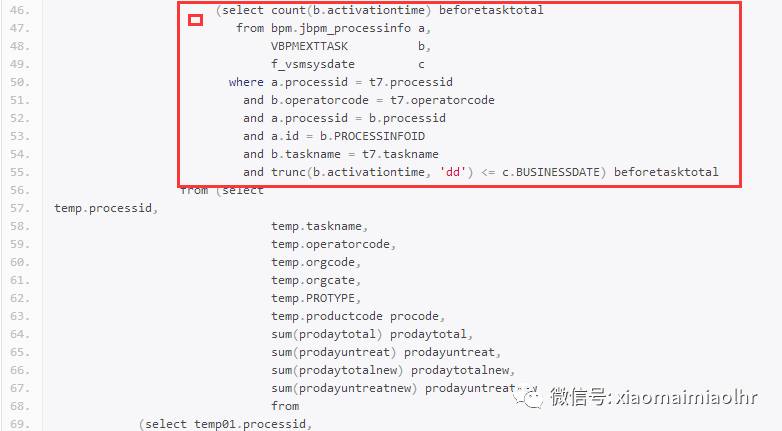
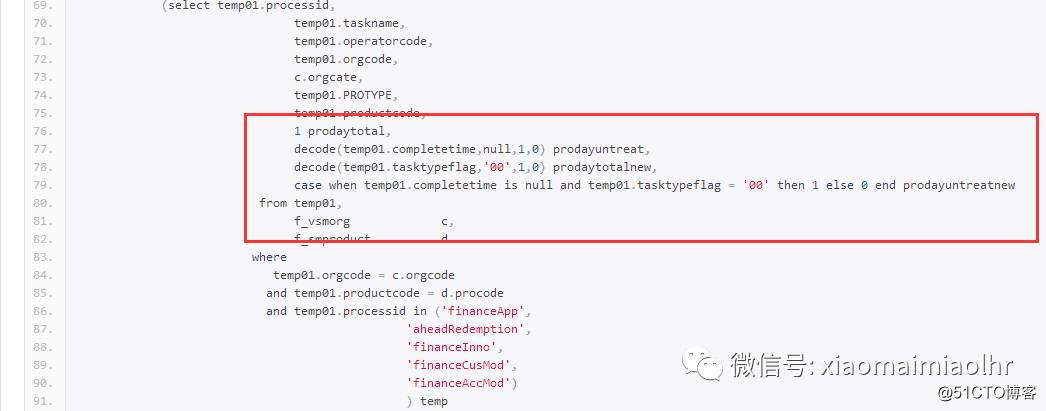
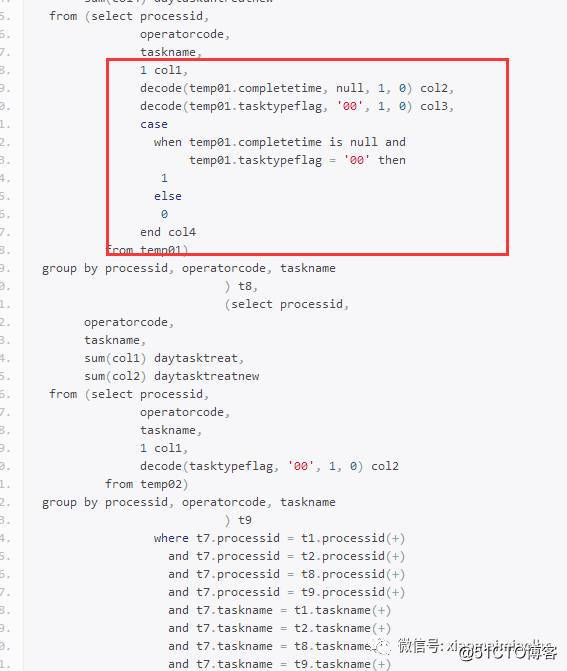
大致解释一下,就是将标量子查询中的公共部分以及t1-t6表公共部分拿出来做的一个with as,然后利用decode和case when函数做的合并,写成sql
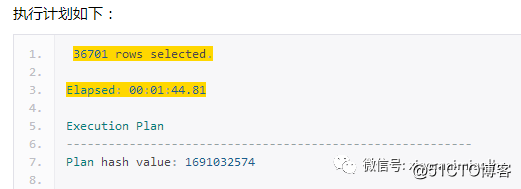
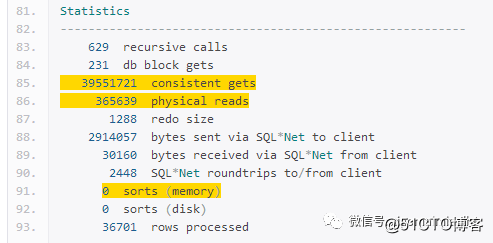
查看执行计划,时间从5分39秒到了1分44s,标量子查询的此起彼伏的规律消失,逻辑读从1.7亿降到4000w,但是物理读变成了36w,内存排序从1次变为0次。
结果来看改进不小,讲道理,查4w条数据,不到2分钟,还可以了。但是还是发现,这里还有一个标量子查询,如果也同样像前边的标量子查询提取出来呢,会是什么效果呢,原以为确实应该变化不会很大的,但是还是想尝试一下。
第三次改写尝试
将trunc(b.activationtime, 'dd') <= c.BUSINESSDATE条件的标量子查询单独提取出来,然后用t7再关联了一张表,外链接也同样关联出相关的外链接条件,语句如下:
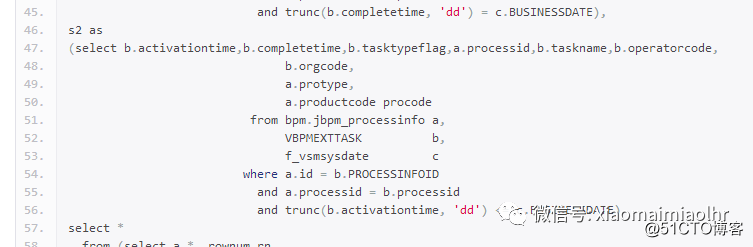
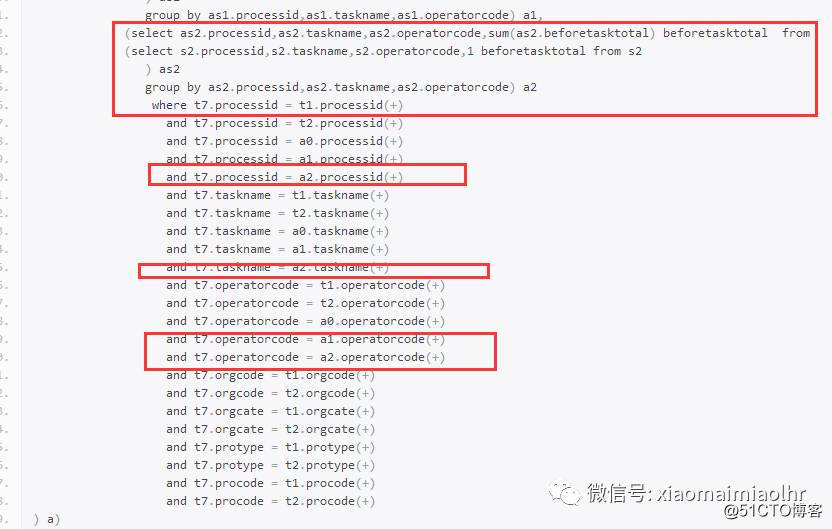
这次是在第二次改写的基础上进行的修改,修改部分如上。
从340行愣是减少到了200行。
执行计划:
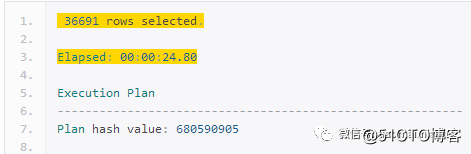
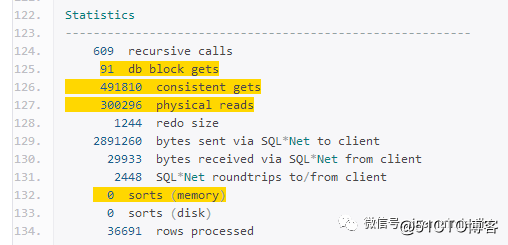
从执行计划看,1分44s到24s,逻辑读从4000w到50w,物理读30w基本没有什么大的变化,没有内存排序。
到这里基本优化完毕,24s查询出4w条数据,我也是拼了老命了。针对大表全扫描,从谓词信息看过滤条件是filter("PROCESSID" IS NOT NULL),所以也好像显得无能为力。
算了就此作罢。
测试验证正确性
最简单的办法就是到测试环境中将修改SQL查询的数据同原SQL查询的数据做minus,然后得到如下:
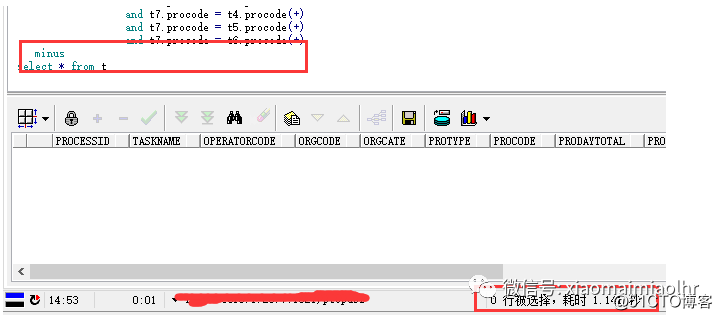
其中t表是针对修改后SQL做的临时表,验证结论正确无误。
ok!搞定收工!!!

- 与大家共享 SQL优化,编写高效SQL 实战经验
- MySQL实战(二)sql语句优化
- MS Sqlserver优化实战(解决CPU利用率高及查询操作速度慢)
- sql优化实战:从40分钟到10秒(更新统计信息)
- oracle SQL优化实战经验
- sql优化实战:从300秒+到10秒(调整参数)
- SQL优化,百万级2张表关联,从40分钟到3秒的历程
- sql优化实战:从250秒+到10秒(简化语句)
- sql优化-项目实战
- 一次Sql语句的优化实战之旅
- mysql的慢查询实战+sql优化
- sql 优化实战 从 35秒到0秒 又从0秒到25秒
- MS Sqlserver优化实战(解决CPU利用率高及查询操作速度慢)
- mysql sql语句优化实战(一、基于in的优化)
- SQL优化实战:临时表+分批提交+按日结存
- oracle 执行计划SQL优化的学习历程
- sql优化实战:从6秒+到2秒(使用索引)
- SQL优化(SQL TUNING)可大幅提升性能的实战技巧之一——让计划沿着索引跑
- SQL 实战学习及优化
- MySQL之SQL优化实战记录