攻城掠地-微服务篇(Spring boot详解)
什么是微服务
a. 微服务是⼀种架构⻛格,也是⼀种服务;
b. 微服务的颗粒⽐较⼩,⼀个⼤型复杂软件应⽤由多个微服务组成,⽐如Netflix⽬前由500多个的微服务组成;
c. 它采⽤UNIX设计的哲学,每种服务只做⼀件事,是⼀种松耦合的能够被独⽴开发和部署的⽆状态化服务(独⽴扩展、
升级和可替换)。
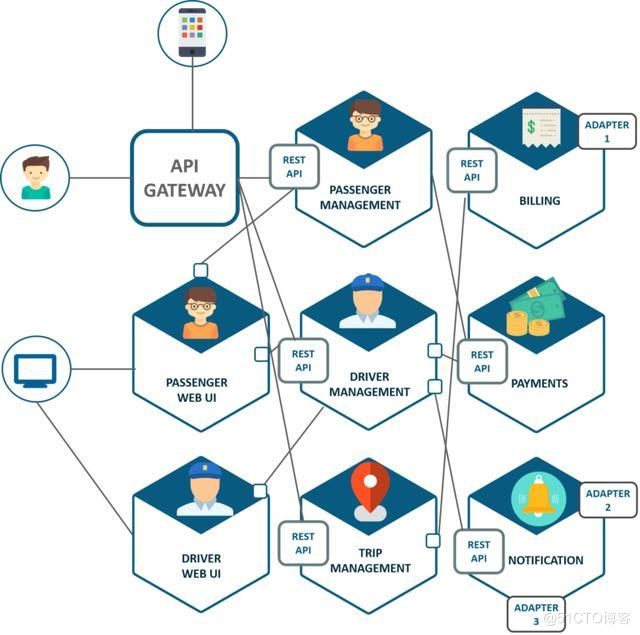
微服务之间是如何独⽴通讯的
a. Dubbo 使⽤的是 RPC 通信,⼆进制传输,占⽤带宽⼩;
b. Spring Cloud 使⽤的是 HTTP RESTFul ⽅式。
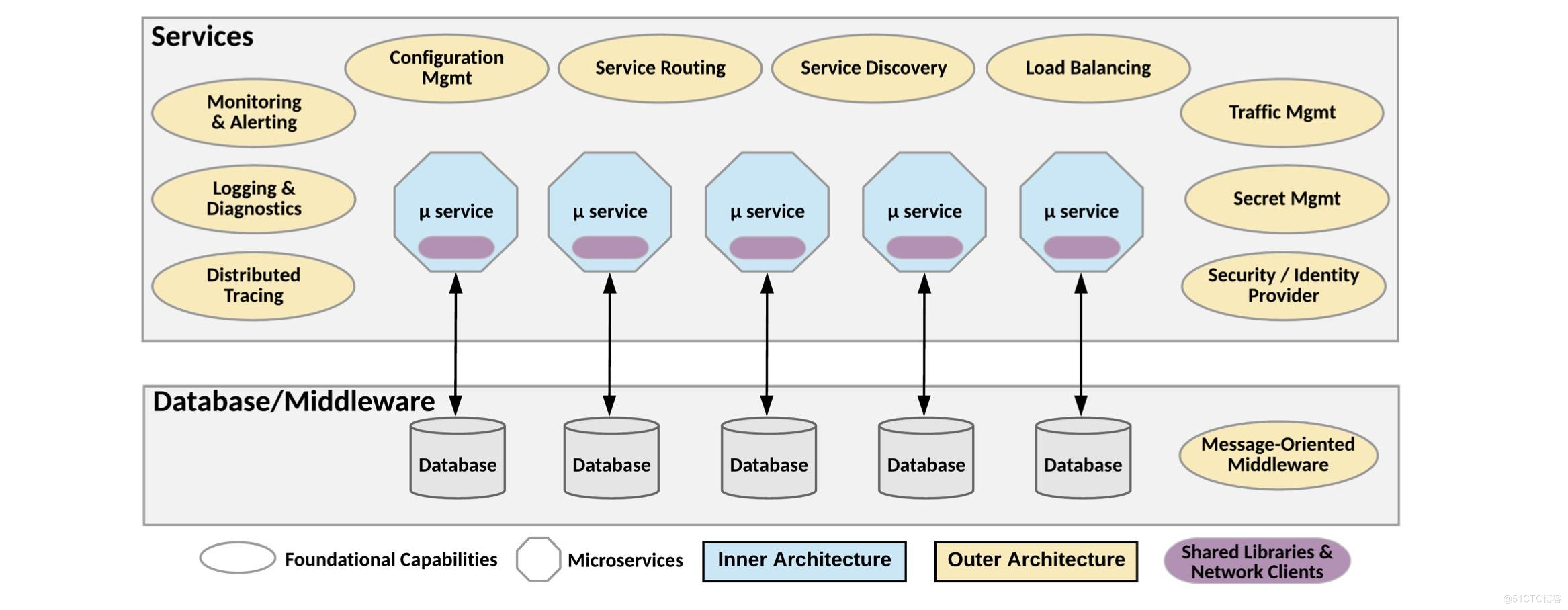
springcloud和dubbo有哪些区别
a. Dubbo具有调度、发现、监控、治理等功能,⽀持相当丰富的服务治理能⼒。Dubbo架构下,注册中⼼对等集群,并
会缓存服务列表已被数据库失效时继续提供发现功能,本身的服务发现结构有很强的可⽤性与健壮性,⾜够⽀持⾼访问
量的⽹站。
b. 虽然Dubbo ⽀持短连接⼤数据量的服务提供模式,但绝⼤多数情况下都是使⽤⻓连接⼩数据量的模式提供服务使⽤
的。所以,对于类似于电商等同步调⽤场景多并且能⽀撑搭建Dubbo 这套⽐较复杂环境的成本的产品⽽⾔,Dubbo 确实
是⼀个可以考虑的选择。但如果产品业务中由于后台业务逻辑复杂、时间⻓⽽导致异步逻辑⽐较多的话,可能Dubbo 并
不合适。同时,对于⼈⼿不⾜的初创产品⽽⾔,这么重的架构维护起来也不是很⽅便。
c. Spring Cloud由众多⼦项⽬组成,如Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Consul 等,提供了搭
建分布式系统及微服务常⽤的⼯具,如配置管理、服务发现、断路器、智能路由、微代理、控制总线、⼀次性token、全
局锁、选主、分布式会话和集群状态等,满⾜了构建微服务所需的所有解决⽅案。⽐如使⽤Spring Cloud Config 可以实
现统⼀配置中⼼,对配置进⾏统⼀管理;使⽤Spring Cloud Netflix 可以实现Netflix 组件的功能 - 服务发现(Eureka)、
智能路由(Zuul)、客户端负载均衡(Ribbon)。
d. dubbo的开发难度较⼤,原因是dubbo的jar包依赖问题很多⼤型⼯程⽆法解决。
e. Dubbo 提供了各种 Filter,对于上述中“⽆”的要素,可以通过扩展 Filter 来完善。
springboot和springcloud认识
a. Spring Boot 是 Spring 的⼀套快速配置脚⼿架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是⼀个基于
Spring Boot实现的云应⽤开发⼯具;
b. Spring Boot专注于快速、⽅便集成的单个微服务个体,Spring Cloud关注全局的服务治理框架;
c. Spring Boot使⽤了默认⼤于配置的理念,很多集成⽅案已经帮你选择好了,能不配置就不配置;
d. Spring Cloud很⼤的⼀部分是基于Spring Boot来实现,可以不基于Spring Boot吗?不可以。
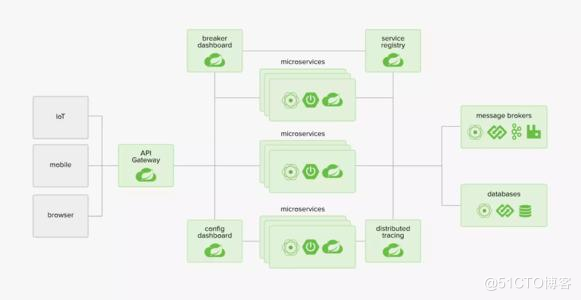
什么是服务熔断,什么是服务降级
a. 服务熔断:
i. 如果检查出来频繁超时,就把consumer调⽤provider的请求,直接短路掉,不实际调⽤,⽽是直接返回⼀个mock
的值。
b. 服务降级:
i. consumer 端:consumer 如果发现某个provider出现异常情况,⽐如,经常超时(可能是熔断引起的降级),数据错
误,这时,consumer可以采取⼀定的策略,降级provider的逻辑,基本的有直接返回固定的数据。
- provider 端:当provider 发现流量激增的时候,为了保护⾃身的稳定性,也可能考虑降级服务。
⽐如,1,直接给consumer返回固定数据,2,需要实时写⼊数据库的,先缓存到队列⾥,异步写⼊数据库。
微服务的优缺点
a. 优点:
i. 单⼀职责:每个微服务仅负责⾃⼰业务领域的功能;
ii. ⾃治:⼀个微服务就是⼀个独⽴的实体,它可以独⽴部署、升级,服务与服务之间通过REST等形式的标准接⼝进
⾏通信,并且⼀个微服务实例可以被替换成另⼀种实现,⽽对其它的微服务不产⽣影响。
iii. 逻辑清晰:微服务单⼀职责特性使微服务看起来逻辑清晰,易于维护。
iv. 简化部署:单系统中修改⼀处需要部署整个系统,⽽微服务中修改⼀处可单独部署⼀个服务。
v. 可扩展:应对系统业务增⻓的⽅法通常采⽤横向(Scale out)或纵向(Scale up)的⽅向进⾏扩展。分布式系统
中通常要采⽤Scale out的⽅式进⾏扩展。
vi. 灵活组合:
vii. 技术异构:不同的服务之间,可以根据⾃⼰的业务特点选择不通的技术架构,如数据库等。
b. 缺点:
i. 复杂度⾼:
- 服务调⽤要考虑被调⽤⽅故障、过载、消息丢失等各种异常情况,代码逻辑更加复杂;
- 对于微服务间的事务性操作,因为不同的微服务采⽤了不同的数据库,将⽆法利⽤数据库本身的事务机制保
证⼀致性,需要引⼊⼆阶段提交等技术。
ii. 运维复杂:系统由多个独⽴运⾏的微服务构成,需要⼀个设计良好的监控系统对各个微服务的运⾏状态进⾏监
控。运维⼈员需要对系统有细致的了解才对够更好的运维系统。
iii. 通信延迟:微服务之间调⽤会有时间损耗,造成通信延迟。
使用中遇到的坑!
a. 超时:确保Hystrix超时时间配置为⻓于配置的Ribbon超时时间
b. feign path:feign客户端在部署时若有contextpath应该设置 path="/***"来匹配你的服务名。
c. 版本:springboot和springcloud版本要兼容。
列举微服务技术栈
a. 服务⽹关Zuul
b. 服务注册发现Eureka+Ribbon
a. 服务配置中⼼Apollo
b. 认证授权中⼼Spring Security OAuth2
c. 服务框架Spring Boot
d. 数据总线Kafka
e. ⽇志监控ELK
f. 调⽤链监控CAT
g. Metrics监控KairosDB
h. 健康检查和告警ZMon
i. 限流熔断和流聚合Hystrix/Turbine[/ol]
- eureka和zookeeper都可以提供服务的注册与发现功能,他们的区别
a. Zookeeper保证CP
当向注册中⼼查询服务列表时,我们可以容忍注册中⼼返回的是⼏分钟以前的注册信息,但不能接受服务直接
down掉不可⽤。也就是说,服务注册功能对可⽤性的要求要⾼于⼀致性。但是zk会出现这样⼀种情况,当master节点因为⽹络故
障与其他节点失去联系时,剩余节点会重新进⾏leader选举。问题在于,选举leader的时间太⻓,30 ~ 120s, 且选举期间整个zk集
群都是不可⽤的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因⽹络问题使得zk集群失去master节点是较⼤概率会
发⽣的事,虽然服务能够最终恢复,但是漫⻓的选举时间导致的注册⻓期不可⽤是不能容忍的。
b. Eureka保证AP
Eureka看明⽩了这⼀点,因此在设计时就优先保证可⽤性。Eureka各个节点都是平等的,⼏个节点挂掉不会影响正
常节点的⼯作,剩余的节点依然可以提供注册和查询服务。⽽Eureka的客户端在向某个Eureka注册或如果发现连接失败,则会⾃
动切换⾄其它节点,只要有⼀台Eureka还在,就能保证注册服务可⽤(保证可⽤性),只不过查到的信息可能不是最新的(不保证强
⼀致性)。除此之外,Eureka还有⼀种⾃我保护机制,如果在15分钟内超过85%的节点都没有正常的⼼跳,那么Eureka就认为客户
端与注册中⼼出现了⽹络故障,此时会出现以下⼏种情况: [ol] Eureka不再从注册列表中移除因为⻓时间没收到⼼跳⽽应该过期的服务- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可⽤)
- 当⽹络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因⽹络故障导致部分节点失去联系的情况,⽽不会像zookeeper那样使整个注册服务瘫痪。
eureka服务注册与发现原理:
a. 每30s发送⼼跳检测重新进⾏租约,如果客户端不能多次更新租约,它将在90s内从服务器注册中⼼移除。
b. 注册信息和更新会被复制到其他Eureka 节点,来⾃任何区域的客户端可以查找到注册中⼼信息,每30s发⽣⼀次复制
来定位他们的服务,并进⾏远程调⽤。
c. 客户端还可以缓存⼀些服务实例信息,所以即使Eureka全挂掉,客户端也是可以定位到服务地址的。
dubbo服务注册与发现原理
调⽤关系说明:
- 服务容器负责启动,加载,运⾏服务提供者。
- 服务提供者在启动时,向注册中⼼注册⾃⼰提供的服务。
- 服务消费者在启动时,向注册中⼼订阅⾃⼰所需的服务。
- 注册中⼼返回服务提供者地址列表给消费者,如果有变更,注册中⼼将基于⻓连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选⼀台提供者进⾏调⽤,如果调⽤失败,再选另⼀台调⽤。
- 服务消费者和提供者,在内存中累计调⽤次数和调⽤时间,定时每分钟发送⼀次统计数据到监控中⼼。
限流:
1、http限流:我们使⽤nginx的limitzone来完成:
1 //这个表示使⽤ip进⾏限流 zone名称为req_one 分配了10m 空间使⽤漏桶算法 每秒钟允许1个请求
2 limit_req_zone $binary_remote_addr zone=req_one:10m rate=1r/s;
3 //这边burst表示可以瞬间超过20个请求 由于没有noDelay参数因此需要排队 如果超过这20个那么直接返回503
4 limit_req zone=req_three burst=20;
2、dubbo限流:dubbo提供了多个和请求相关的filter:ActiveLimitFilter ExecuteLimitFilter TPSLimiterFilter1. ActiveLimitFilter: 1 @Activate(group = Constants.CONSUMER, value = Constants.ACTIVES_KEY)作⽤于客户端,主要作⽤是控制客户端⽅法的并发度;
当超过了指定的active值之后该请求将等待前⾯的请求完成【何时结束呢?依赖于该⽅法的timeout 如果
没有设置timeout的话可能就是多个请求⼀直被阻塞然后等待随机唤醒。
- ExecuteLimitFilter:
1 @Activate(group = Constants.PROVIDER, value = Constants.EXECUTES_KEY)
作⽤于服务端,⼀旦超出指定的数⽬直接报错 其实是指在服务端的并⾏度【需要注意这些都是指的是在
单台服务上⽽不是整个服务集群】- TPSLimiterFilter:
1 @Activate(group = Constants.PROVIDER, value = Constants.TPS_LIMIT_RATE_KEY)
作⽤于服务端,控制⼀段时间内的请求数;
默认情况下取得tps.interval字段表示请求间隔 如果⽆法找到则使⽤60s 根据tps字段表示允许调⽤次数。
使⽤AtomicInteger表示允许调⽤的次数 每次调⽤减少1次当结果⼩于0之后返回不允许调⽤
3、springcloud限流:
1、我们可以通过semaphore.maxConcurrentRequests,coreSize,maxQueueSize和queueSizeRejectionThreshold设
置信号量模式下的最⼤并发量、线程池⼤⼩、缓冲区⼤⼩和缓冲区降级阈值。
1 #不设置缓冲区,当请求数超过coreSize时直接降级
2 hystrix.threadpool.userThreadPool.maxQueueSize=-1
3 #超时时间⼤于我们的timeout接⼝返回时间
4 hystrix.command.userCommandKey.execution.isolation.thread.timeoutInMilliseconds=15000
这个时候我们连续多次请求/user/command/timeout接⼝,在第⼀个请求还没有成功返回时,查看输出⽇志可以
发现只有第⼀个请求正常的进⼊到user-service的接⼝中,其它请求会直接返回降级信息。这样我们就实现了对服务请求的限流。
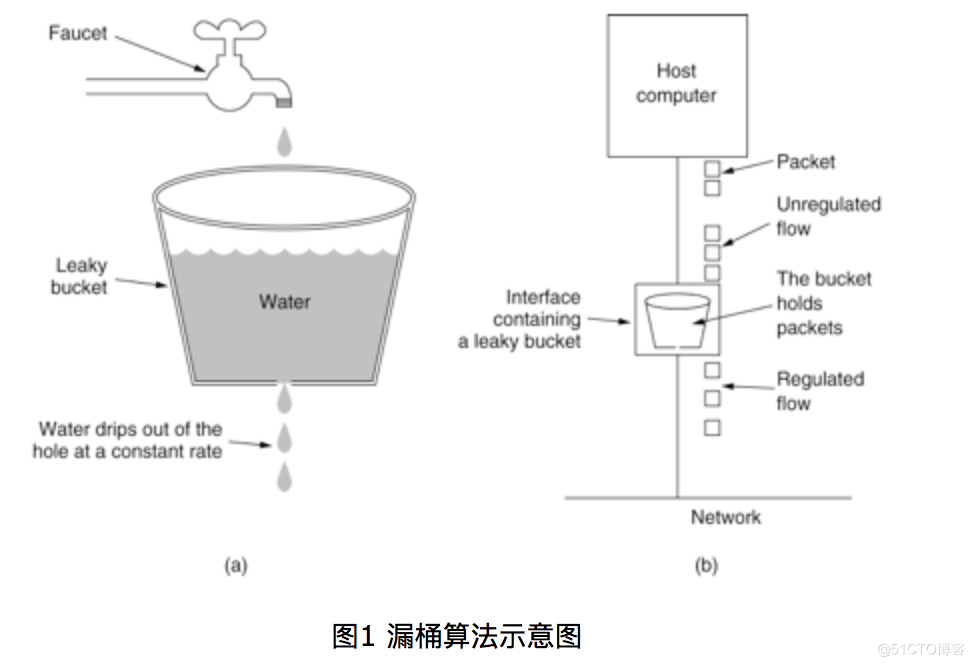
2、漏桶算法:⽔(请求)先进⼊到漏桶⾥,漏桶以⼀定的速度出⽔,当⽔流⼊速度过⼤会直接溢出,可以看出漏桶算
法能强⾏限制数据的传输速率。
⾓⾊说明
Provider 暴露服务的服务提供⽅
Consumer 调⽤远程服务的服务消费⽅
Registry 服务注册与发现的注册中⼼
Monitor 统计服务的调⽤次调和调⽤时间的监控中⼼
Container 服务运 8000 ⾏容器
3、令牌桶算法:除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就
不合适了,令牌桶算法更为适合。如图2所示,令牌桶算法的原理是系统会以⼀个恒定的速度往桶⾥放⼊令牌,⽽如果请求需要被处
理,则需要先从桶⾥获取⼀个令牌,当桶⾥没有令牌可取时,则拒绝服务。
4、redis计数器限流;
springcloud核⼼组件及其作⽤,以及springcloud⼯作原理:
springcloud由以下⼏个核⼼组件构成:
Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka
Server拉取注册表,从⽽知道其他服务在哪⾥
Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从⼀个服务的多台机器中选择⼀台
Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求
Hystrix:发起请求是通过Hystrix的线程池来⾛的,不同的服务⾛不同的线程池,实现了不同服务调⽤的隔离,避免了服
务雪崩的问题
Zuul:如果前端、移动端要调⽤后端系统,统⼀从Zuul⽹关进⼊,由Zuul⽹关转发请求给对应的服务
eureka的缺点:
某个服务不可⽤时,各个Eureka Client不能及时的知道,需要1~3个⼼跳周期才能感知,但是,由于基于Netflix的服
务调⽤端都会使⽤Hystrix来容错和降级,当服务调⽤不可⽤时Hystrix也能及时感知到,通过熔断机制来降级服务调⽤,
因此弥补了基于客户端服务发现的时效性的缺点。
eureka缓存机制:
a. 第⼀层缓存:readOnlyCacheMap,本质上是ConcurrentHashMap:这是⼀个JVM的CurrentHashMap只读缓存,这
个主要是为了供客户端获取注册信息时使⽤,其缓存更新,依赖于定时器的更新,通过和readWriteCacheMap 的值做对
⽐,如果数据不⼀致,则以readWriteCacheMap 的数据为准。readOnlyCacheMap 缓存更新的定时器时间间隔,默认为
30秒
b. 第⼆层缓存:readWriteCacheMap,本质上是Guava缓存:此处存放的是最终的缓存, 当服务下线,过期,注册,状
态变更,都会来清除这个缓存⾥⾯的数据。 然后通过CacheLoader进⾏缓存加载,在进⾏readWriteCacheMap.get(key)
的时候,⾸先看这个缓存⾥⾯有没有该数据,如果没有则通过CacheLoader的load⽅法去加载,加载成功之后将数据放
⼊缓存,同时返回数据。 readWriteCacheMap 缓存过期时间,默认为 180 秒 。
c. 缓存机制:设置了⼀个每30秒执⾏⼀次的定时任务,定时去服务端获取注册信息。获取之后,存⼊本地内存。
熔断的原理,以及如何恢复?
a. 服务的健康状况 = 请求失败数 / 请求总数.
熔断器开关由关闭到打开的状态转换是通过当前服务健康状况和设定阈值⽐较决定的.
i. 当熔断器开关关闭时, 请求被允许通过熔断器. 如果当前健康状况⾼于设定阈值, 开关继续保持关闭. 如果当前健康
状况低于设定阈值, 开关则切换为打开状态.
ii. 当熔断器开关打开时, 请求被禁⽌通过.
iii. 当熔断器开关处于打开状态, 经过⼀段时间后, 熔断器会⾃动进⼊半开状态, 这时熔断器只允许⼀个请求通过. 当该
请求调⽤成功时, 熔断器恢复到关闭状态. 若该请求失败, 熔断器继续保持打开状态, 接下来的请求被禁⽌通过.
熔断器的开关能保证服务调⽤者在调⽤异常服务时, 快速返回结果, 避免⼤量的同步等待. 并且熔断器能在⼀段时间后
继续侦测请求执⾏结果, 提供恢复服务调⽤的可能.
服务雪崩?
a. 简介:服务雪崩效应是⼀种因 服务提供者 的不可⽤导致 服务调⽤者 的不可⽤,并将不可⽤ 逐渐放⼤ 的过程.
b. 形成原因:
i. 服务提供者不可⽤
ii. 重试加⼤流量
iii. 服务调⽤者不可⽤
c. 采⽤策略:
i. 流量控制
ii. 改进缓存模式
iii. 服务⾃动扩容
iv. 服务调⽤者降级服务
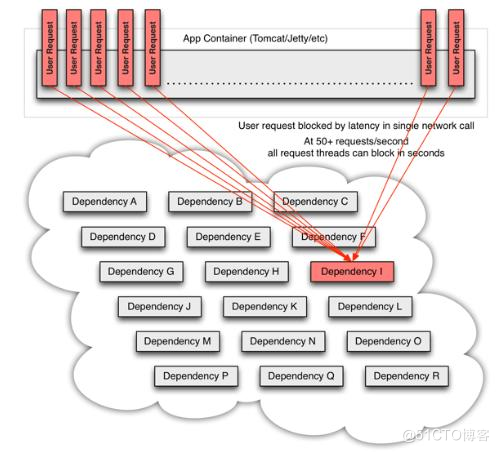
服务隔离的原理?如何处理服务雪崩的场景?
a. Hystrix通过将每个依赖服务分配独⽴的线程池进⾏资源隔离, 从⽽避免服务雪崩.
- 多个消费者调⽤同⼀接⼝,eruka默认的分配⽅式是什么?
a. RoundRobinRule:轮询策略,Ribbon以轮询的⽅式选择服务器,这个是默认值。所以示例中所启动的两个服务会被循
环访问;
b. RandomRule:随机选择,也就是说Ribbon会随机从服务器列表中选择⼀个进⾏访问;
c. BestAvailableRule:最⼤可⽤策略,即先过滤出故障服务器后,选择⼀个当前并发请求数最⼩的;
d. WeightedResponseTimeRule:带有加权的轮询策略,对各个服务器响应时间进⾏加权处理,然后在采⽤轮询的⽅式
来获取相应的服务器;
e. AvailabilityFilteringRule:可⽤过滤策略,先过滤出故障的或并发请求⼤于阈值⼀部分服务实例,然后再以线性轮询
的⽅式从过滤后的实例清单中选出⼀个;
f. ZoneAvoidanceRule:区域感知策略,先使⽤主过滤条件(区域负载器,选择最优区域)对所有实例过滤并返回过滤后
的实例清单,依次使⽤次过滤条件列表中的过滤条件对主过滤条件的结果进⾏过滤,判断最⼩过滤数(默认1)和最⼩过
滤百分⽐(默认0),最后对满⾜条件的服务器则使⽤RoundRobinRule(轮询⽅式)选择⼀个服务器实例。
接⼝限流⽅法?
a. 限制 总并发数(⽐如 数据库连接池、线程池)
b. 限制 瞬时并发数(如 nginx 的 limit_conn 模块,⽤来限制 瞬时并发连接数)
c. 限制 时间窗⼝内的平均速率(如 Guava 的 RateLimiter、nginx 的 limit_req模块,限制每秒的平均速率)
d. 限制 远程接⼝ 调⽤速率
e. 限制 MQ 的消费速率
f. 可以根据 ⽹络连接数、⽹络流量、CPU 或 内存负载 等来限流

- SpringBoot学习三:入门基本配置及注解详解
- 详解如何在Spring Boot项目使用参数校验
- Spring Boot 集成MyBatis 教程详解
- 补习系列(4)-springboot 参数校验详解
- SpringBoot非官方教程 | 第二篇:Spring Boot配置文件详解
- 在Spring Boot应用程序中使用Apache Kafka的方法步骤详解
- Springboot实现高吞吐量异步处理详解(适用于高并发场景)
- SpringBoot 2.2.2 源码详解(二):自动装配原理
- Spring Boot 案例详解
- 详解Spring Boot微服务如何集成fescar解决分布式事务问题
- 详解eclipse下创建第一个spring boot项目
- spring boot整合使用JdbcTemplate之详解!!
- SpringBoot文件上传下载和多文件上传(图文详解)
- 【系统学习SpringBoot】再遇Spring Data JPA之JPA应用详解(自定义查询及复杂查询)
- Spring Boot - 构建Spring Boot系统及相关配置详解
- springboot配置redis过程详解
- 详解SpringBoot定时任务说明
- SpringCloud和Springboot中的pom.xml文件的详解
- 详解Springboot自定义异常处理
- SpringBoot开发详解(十一) -- Redis在SpringBoot中的整合