Oracle中的优化器--CBO和RBO
Oracle中的优化器--CBO和RBO
Oracle数据库中的优化器又叫查询优化器(Query Optimizer)。它是SQL分析和执行的优化工具,它负责生成、制定SQL的执行计划。Oracle的优化器有两种,基于规则的优化器(RBO)与基于代价的优化器(CBO)
RBO: Rule-Based Optimization 基于规则的优化器
CBO: Cost-Based Optimization 基于代价的优化器
RBO自ORACLE 6以来被采用,一直沿用至ORACLE 9i. ORACLE 10g开始,ORACLE已经彻底丢弃了RBO,它有着一套严格的使用规则,只要你按照它去写SQL语句,无论数据表中的内容怎样,也不会影响到你的“执行计划”,也就是说RBO对数据不“敏感”;它根据ORACLE指定的优先顺序规则,对指定的表进行执行计划的选择。比如在规则中,索引的优先级大于全表扫描;RBO是根据可用的访问路径以及访问路径等级来选择执行计划,在RBO中,SQL的写法往往会影响执行计划,它要求开发人员非常了解RBO的各项细则,菜鸟写出来的SQL脚本性能可能非常差。随着RBO的被遗弃,渐渐不为人所知。也许只有老一辈的DBA对其了解得比较深入。关于RBO的访问路径,官方文档做了详细介绍:
RBO Path 1: Single Row by Rowid
RBO Path 2: Single Row by Cluster Join
RBO Path 3: Single Row by Hash Cluster Key with Unique or Primary Key
RBO Path 4: Single Row by Unique or Primary Key
RBO Path 5: Clustered Join
RBO Path 6: Hash Cluster Key
RBO Path 7: Indexed Cluster Key
RBO Path 8: Composite Index
RBO Path 9: Single-Column Indexes
RBO Path 10: Bounded Range Search on Indexed Columns
RBO Path 11: Unbounded Range Search on Indexed Columns
RBO Path 12: Sort Merge Join
RBO Path 13: MAX or MIN of Indexed Column
RBO Path 14: ORDER BY on Indexed Column
RBO Path 15: Full Table Scan
CBO是一种比RBO更加合理、可靠的优化器,它是从ORACLE 8中开始引入,但到ORACLE 9i 中才逐渐成熟,在ORACLE 10g中完全取代RBO, CBO是计算各种可能“执行计划”的“代价”,即COST,从中选用COST最低的执行方案,作为实际运行方案。它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择。如果对一次执行SQL时发现涉及对象(表、索引等)没有被分析、统计过,那么ORACLE会采用一种叫做动态采样的技术,动态的收集表和索引上的一些数据信息。
关于RBO与CBO,我有个形象的比喻:大数据时代到来以前,做生意或许凭借多年累计下来的经验(RBO)就能够很好的做出决策,跟随市场变化。但是大数据时代,如果做生意还是靠以前凭经验做决策,而不是靠大数据、数据分析、数据挖掘做决策,那么就有可能做出错误的决策。这也就是越来越多的公司对BI、数据挖掘越来越重视的缘故,像电商、游戏、电信等行业都已经大规模的应用,以前在一家游戏公司数据库部门做BI分析,挖掘潜在消费用户简直无所不及。至今映像颇深。
CBO与RBO的优劣
CBO优于RBO是因为RBO是一种呆板、过时的优化器,它只认规则,对数据不敏感。毕竟规则是死的,数据是变化的,这样生成的执行计划往往是不可靠的,不是最优的,CBO由于RBO可以从很多方面体现。下面请看一个例子,此案例来自于《让Oracle跑得更快》。
SQL> create table test as select 1 id ,object_name from dba_objects;
Table created.
SQL> create index idx_test on test(id);
Index created.
SQL> update test set id=100 where rownum =1;
1 row updated.
SQL> select id, count(1) from test group by id;
ID COUNT(1)
---------- ----------
100 1
1 50314
从上面可以看出,该测试表的数据分布极其不均衡,ID=100的记录只有一条,而ID=1的记录有50314条。我们先看看RBO下两条SQL的执行计划.
SQL> select /*+ rule */ * from test where id =100;
Execution Plan
----------------------------------------------------------
Plan hash value: 2473784974
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST |
|* 2 | INDEX RANGE SCAN | IDX_TEST |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=100)Note
-----
- rule based optimizer used (consider using cbo)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
588 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL> select /*+ rule */ * from test where id=1;
50314 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2473784974
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST |
|* 2 | INDEX RANGE SCAN | IDX_TEST |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=1)Note
-----
- rule based optimizer used (consider using cbo)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
7012 consistent gets
97 physical reads
0 redo size
2243353 bytes sent via SQL*Net to client
37363 bytes received via SQL*Net from client
3356 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
50314 rows processed
从执行计划可以看出,RBO的执行计划让人有点失望,对于ID=1,几乎所有的数据全部符合谓词条件,走索引只能增加额外的开销(因为ORACLE首先要访问索引数据块,在索引上找到了对应的键值,然后按照键值上的ROWID再去访问表中相应数据),既然我们几乎要访问所有表中的数据,那么全表扫描自然是最优的选择。而RBO选择了错误的执行计划。可以对比一下CBO下SQL的执行计划,显然它对数据敏感,执行计划及时的根据数据量做了调整,当查询条件为1时,它走全表扫描;当查询条件为100时,它走区间索引扫描。如下所示:
SQL> select * from test where id=1;
50314 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1357081020
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 49075 | 3786K| 52 (2)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| TEST | 49075 | 3786K| 52 (2)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=1)Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
32 recursive calls
0 db block gets
3644 consistent gets
0 physical reads
0 redo size
1689175 bytes sent via SQL*Net to client
37363 bytes received via SQL*Net from client
3356 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
50314 rows processed
SQL> select * from test where id =100;
Execution Plan
----------------------------------------------------------
Plan hash value: 2473784974
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 79 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 79 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST | 1 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=100)Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
9 recursive calls
0 db block gets
73 consistent gets
0 physical reads
0 redo size
588 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
仅此一项就可以看出为什么ORACLE极力推荐使用CBO,从ORACLE 10g开始不支持RBO的缘故。所谓长江后浪推前浪,前浪死在沙滩上。
CBO知识点的总结
CBO优化器根据SQL语句生成一组可能被使用的执行计划,估算出每个执行计划的代价,并调用计划生成器(Plan Generator)生成执行计划,比较执行计划的代价,最终选择选择一个代价最小的执行计划。查询优化器由查询转换器(Query Transform)、代价估算器(Estimator)和计划生成器(Plan Generator)组成。
CBO优化器组件
CBO由以下组件构成:
· 查询转化器(Query Transformer)
查询转换器的作用就是等价改变查询语句的形式,以便产生更好的执行计划。它决定是否重写用户的查询(包括视图合并、谓词推进、非嵌套子查询/子查询反嵌套、物化视图重写),以生成更好的查询计划。
The input to the query transformer is a parsed query, which is represented by a set of
query blocks. The query blocks are nested or interrelated to each other. The form of the
query determines how the query blocks are interrelated to each other. The main
objective of the query transformer is to determine if it is advantageous to change the
form of the query so that it enables generation of a better query plan. Several different
query transformation techniques are employed by the query transformer, including:
■ View Merging
■ Predicate Pushing
■ Subquery Unnesting
■ Query Rewrite with Materialized Views
Any combination of these transformations can be applied to a given query.
· 代价评估器(Estimator)
评估器通过复杂的算法结合来统计信息的三个值来评估各个执行计划的总体成本:选择性(Selectivity)、基数(Cardinality)、成本(Cost)
计划生成器会考虑可能的访问路径(Access Path)、关联方法和关联顺序,生成不同的执行计划,让查询优化器从这些计划中选择出执行代价最小的一个计划。
· 计划生成器(Plan Generator)
计划生成器就是生成大量的执行计划,然后选择其总体代价或总体成本最低的一个执行计划。
由于不同的访问路径、连接方式和连接顺序可以组合,虽然以不同的方式访问和处理数据,但是可以产生同样的结果
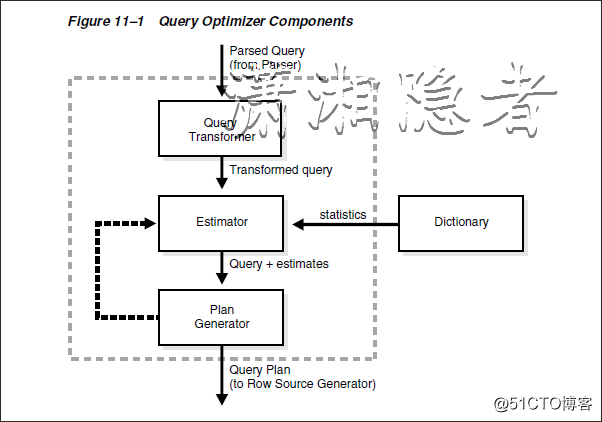
下图是我自己为了加深理解,用工具画的图
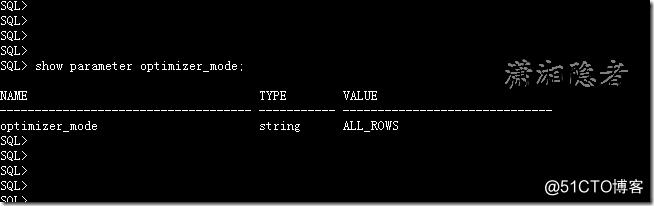
查看ORACLE优化器
SQL> show parameter optimizer_mode;
NAME TYPE VALUE
--------------------------- ----------- -----------------
optimizer_mode string ALL_ROWS
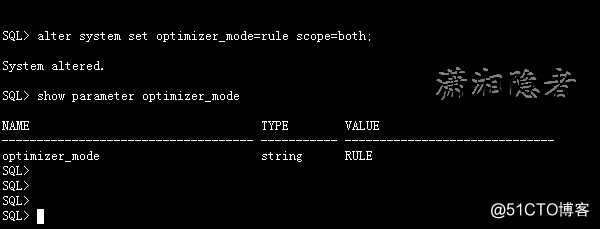
修改ORACLE优化器
ORACLE 10g 优化器可以从系统级别、会话级别、语句级别三种方式修改优化器模式,非常方便灵活。
其中optimizer_mode可以选择的值有: first_rows_n,all_rows. 其中first_rows_n又有first_rows_1000, first_rows_100, first_rows_10, first_rows_1
在Oracle 9i中,优化器模式可以选择first_rows_n,all_rows, choose, rule 等模式:
Rule: 基于规则的方式。
Choolse:指的是当一个表或或索引有统计信息,则走CBO的方式,如果表或索引没统计信息,表又不是特别的小,而且相应的列有索引时,那么就走索引,走RBO的方式。
If OPTIMIZER_MODE=CHOOSE, if statistics do not exist, and if you do not add hints to SQL statements, then SQL statements use the RBO. You can use the RBO to access both relational data and object types. If OPTIMIZER_MODE=FIRST_ROWS, FIRST_ROWS_n, or ALL_ROWS and no statistics exist, then the CBO uses default statistics. Migrate existing applications to use the cost-based approach.
First Rows:它与Choose方式是类似的,所不同的是当一个表有统计信息时,它将是以最快的方式返回查询的最先的几行,从总体上减少了响应时间。
All Rows: 10g中的默认值,也就是我们所说的Cost的方式,当一个表有统计信息时,它将以最快的方式返回表的所有的行,从总体上提高查询的吞吐
虽然Oracle 10g中不再支持RBO,Oracle 10g官方文档关于optimizer_mode参数的只有first_rows和all_rows.但是依然可以设置 optimizer_mode为rule或choose,估计是ORACLE为了过渡或向下兼容考虑。如下所示。
系统级别
SQL> alter system set optimizer_mode=rule scope=both;
System altered.
SQL> show parameter optimizer_mode
NAME TYPE VALUE
-------------------------------- ----------- -----------------------
optimizer_mode string RULE
会话级别
会话级别修改优化器模式,只对当前会话有效,其它会话依然使用系统优化器模式。
SQL> alter session set optimizer_mode=first_rows_100;
Session altered.
语句级别
语句级别通过使用提示hints来实现。
SQL> select /*+ rule */ * from dba_objects where rownum <= 10;
第1章 Oracle里的优化器
到目前为止,Oracle数据库是市场占有率最高(接近50%),使用范围最广的关系型数据库(RDBMS),这意味着有太多太多的系统都是构建在Oracle数据库上的。而我们大家都知道,对于使用关系型数据库的应用系统而言,SQL语句的好坏会直接影响系统的性能,很多系统性能很差最后发现都是因为SQL写得很烂的缘故。实际上,一条写得很烂的SQL语句就能拖垮整个应用,极端情况下,一条写得很烂的SQL语句甚至会导致数据库服务器失去响应或者使整个数据库Hang住,去Google一下吧,这样的例子有很多!
怎样避免在Oracle数据库中写出很烂的SQL?或者说应该如何在Oracle数据库中做SQL优化?这个问题真的很不好回答,且容我慢慢道来。
对所有的关系型数据库而言,优化器无疑是其中最核心的部分,因为优化器负责解析SQL,而我们又都是通过SQL来访问存储在关系型数据库中的数据的,所以优化器的好坏会直接决定该关系型数据库的强弱。从另外一个方面来说,正是因为优化器负责解析SQL,所以要想做好SQL优化就必须了解优化器,而且最好是能全面、深入的了解,这是做好SQL优化基础中的基础。
Oracle数据库里的优化器以其复杂、强悍而闻名于世,本章会详细介绍与Oracle数据库里优化器相关的基础知识,目的是希望通过这一章的介绍,让大家对Oracle数据库里的优化器有一个全局、概要性的认识,打好基础,为阅读后续章节扫清障碍。
1.1 什么是Oracle里的优化器
优化器(Optimizer)是Oracle数据库中内置的一个核心子系统,你也可以把它理解成是Oracle数据库中的一个核心模块或者一个核心功能组件。优化器的目的是按照一定的判断原则来得到它认为的目标SQL在当前情形下最高效的执行路径(Access Path),也就是说,优化器的目的就是为了得到目标SQL的执行计划(关于执行计划,会在"第2章 Oracle里的执行计划"中详细描述)。
依据选择执行计划时所用的判断原则,Oracle数据库里的优化器又分为RBO和CBO这两种类型。RBO是Rule-Based Optimizer的缩写,直译过来就是"基于规则的优化器";相对应的,CBO是Cost-Based Optimizer的缩写,直译过来就是"基于成本的优化器"。
在得到目标SQL的执行计划时,RBO所用的判断原则为一组内置的规则,这些规则是硬编码在Oracle数据库的代码中的,RBO会根据这些规则从目标SQL诸多可能的执行路径中选择一条来作为其执行计划;而CBO所用的判断原则为成本,CBO会从目标SQL诸多可能的执行路径中选择成本值最小的一条来作为其执行计划,各个执行路径的成本值是根据目标SQL语句所涉及的表、索引、列等相关对象的统计信息计算出来的(关于统计信息,会在"第5章 Oracle里的统计信息"中详细描述)。
Oracle数据库里SQL语句的执行过程可以用图1-1来表示。
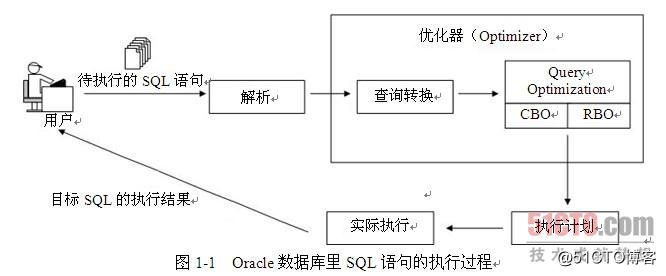
关于图1-1,会在"第4章 Oracle里的查询转换"中详细说明,这里只需要知道Oracle里优化器的输入是经过解析后(在这个解析过程中,Oracle会执行对目标SQL的语法、语义和权限检查)的目标SQL,输出是该目标SQL的执行计划就好了。
接下来,分别介绍RBO和CBO。
1.1.1 基于规则的优化器(1)
之前已经提到,基于规则的优化器(RBO)通过硬编码在Oracle数据库代码中的一系列固定的规则,来决定目标SQL的执行计划。具体来说就是这样:Oracle会在代码里事先给各种类型的执行路径定一个等级,一共有15个等级,从等级1到等级15。并且Oracle会认为等级值低的执行路径的执行效率会比等级值高的执行效率要高,也就是说在RBO的眼里,等级1所对应的执行路径的执行效率最高,等级15所对应的执行路径的执行效率最低。在决定目标SQL的执行计划时,如果可能的执行路径不止一条,则RBO就会从该SQL诸多可能的执行路径中选择一条等级值最低的执行路径来作为其执行计划。
RBO是一种适用于OLTP类型SQL语句的优化器,在这样的前提条件下,大家来猜一猜RBO的等级1和等级15所对应的执行路径分别是什么?
在Oracle数据库里,对于OLTP类型的SQL语句而言,显然通过ROWID来访问是效率最高的方式,而通过全表扫描来访问则是效率最低的方式。与之相对应的,RBO内置的等级1所对应的执行路径就是"single row by rowid(通过rowid来访问单行数据)",而等级15所对应的执行路径则是"full table scan(全表扫描)"。
RBO在Oracle中由来已久,虽然从Oracle 10g开始,RBO已不再被Oracle支持,但RBO的相关实现代码并没有从Oracle数据库的代码中移除,这意味着即使是在Oracle 11gR2中,我们依然可以通过修改优化器模式或使用RULE Hint来继续使用RBO。
和CBO相比,RBO是有其明显缺陷的。在使用RBO的情况下,执行计划一旦出了问题,很难对其做调整;另外,如果使用了RBO,则目标SQL的写法,甚至是目标SQL中所涉及的各个对象在该SQL文本中出现的先后顺序,都可能会影响RBO对于该SQL执行计划的选择。更糟糕的是,Oracle数据库中很多很好的特性、功能均不能在RBO下使用,因为它们均不被RBO所支持。
只要出现了如下的情形之一(包括但不限于这些情形),那么即便你修改了优化器模式或者使用了RULE Hint,Oracle依然不会使用RBO(而是强制使用CBO):
目标SQL中涉及的对象有IOT(Index Organized Table)。
目标SQL中涉及的对象有分区表。
使用了并行查询或者并行DML。
使用了星型连接。
使用了哈希连接。
使用了索引快速全扫描。
使用了函数索引。
……
在使用RBO的情况下,一旦RBO选择的执行计划并不是当前情形下最优的执行计划,应该如何对其做调整呢?
这种情况下我们是很难对RBO选择的执行计划做调整的,其中非常关键的一个原因就是不能使用Hint,因为如果在目标SQL中使用了Hint,就意味着自动启用了CBO,即Oracle会以CBO来解析含Hint的目标SQL。这里仅有两个例外,就是RULE Hint和DRIVING_SITE Hint,它们可以在RBO下使用并且不自动启用CBO(关于Oracle中的Hint,会在"第6章 Oracle里的Hint"详细说明)。
那么,是不是在使用RBO的情况下就没办法对执行计划做调整了?
当然不是这样,只是这种情况下我们的调整手段会非常有限。其中的一种可行的方法就是等价改写目标SQL,比如在目标SQL的where条件中对NUMBER或DATE类型的列加上0(如果是VARCHAR2或CHAR类型,可以加上一个空字符,例如 || ''),这样就可以让原本可以走的索引现在走不了。对于包含多表连接的目标SQL而言,这种改变甚至可以影响表连接的顺序,进而就可以实现在使用RBO的情况下对该目标SQL的执行计划做调整的目的。
之前已经提到:RBO会从目标SQL诸多可能的执行路径中选择一条等级值最低的作为其执行计划,但如果出现了两条或者两条以上等级值相同的执行路径的情况,那么此时RBO会如何选择呢?很简单,此时RBO会依据目标SQL中所涉及的相关对象在数据字典缓存(Data Dictionary Cache)中的缓存顺序和目标SQL中所涉及的各个对象在目标SQL文本中出现的先后顺序来综合判断。这也就意味着我们还可以通过调整相关对象在数据字典缓存中的缓存顺序,改变目标SQL中所涉及的各个对象在该SQL文本中出现的先后顺序来调整其执行计划。
我们来看一个在使用RBO的情况下对目标SQL的执行计划做调整的实例。创建一个测试表EMP_TEMP:
- SQL> create table emp_temp as select * from emp;
- Table created
在表EMP_TEMP的列MGR和DEPTNO上分别创建两个名为IDX_MGR_TEMP和IDX_DEPTNO_TEMP的索引:
- SQL> create index idx_mgr_temp on emp_temp(mgr);
- Index created
- SQL> create index idx_deptno_temp on emp_temp(deptno);
- Index created
我们来看一下如下的范例SQL 1:
- select * from emp_temp
- where mgr > 100 and deptno > 100;
对于范例SQL 1而言,其where条件中出现了列MGR和DEPTNO,而在列MGR和DEPTNO上分别存在着索引IDX_MGR_TEMP和IDX_DEPTNO_TEMP。
现在的问题是,如果在启用RBO的情形下执行范例SQL 1,则Oracle会选择走上述两个索引中的哪一个?
1.1.1 基于规则的优化器(2)
我们来实际验证一下。在当前Session中将优化器模式修改为RULE,表示在当前Session中启用RBO:
- SQL> alter session set optimizer_mode='RULE';
- Session altered
然后执行范例SQL 1:
- SQL> set autotrace traceonly explain
- SQL> select * from emp_temp where mgr>100 and deptno>100;
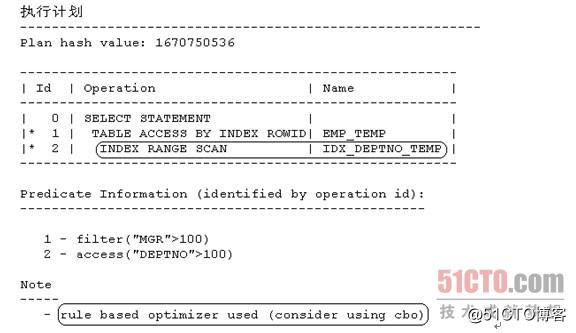
注意到Id = 2的执行步骤为"INDEX RANGE SCAN | IDX_DEPTNO_TEMP",Note部分有关键字"rule based optimizer used (consider using cbo)",这说明Oracle在执行上述范例SQL 1时使用的是RBO,且选择的是走对索引IDX_DEPTNO_TEMP的索引范围扫描。
范例SQL 1的where条件中有"mgr>100",所以RBO实际上是可以选择走列MGR上的索引IDX_MGR_TEMP的,只不过RBO这里并没有选择走该索引,而是选择走列DEPTNO上的索引IDX_DEPTNO_TEMP。
假如我们发现走索引IDX_DEPTNO_TEMP不如走索引IDX_MGR_TEMP的执行效率高,或者说我们就想让RBO选择走索引IDX_MGR_TEMP,那么应该如何做呢?
之前已经提到过:在使用RBO的情况下,可以通过等价改写目标SQL(加0或者空字符串的方式)来调整该SQL的执行计划。列DEPTNO的类型为NUMBER,所以我们可以在列DEPTNO上加0,来达到不让RBO选择走其上的索引IDX_DEPTNO_TEMP的目的。在列DEPTNO上加0后即形成了如下形式的范例SQL 2:
- select * from emp_temp
- where mgr>100 and deptno+0>100;
执行范例SQL 2:
- SQL> select * from emp_temp where mgr>100 and deptno+0>100;
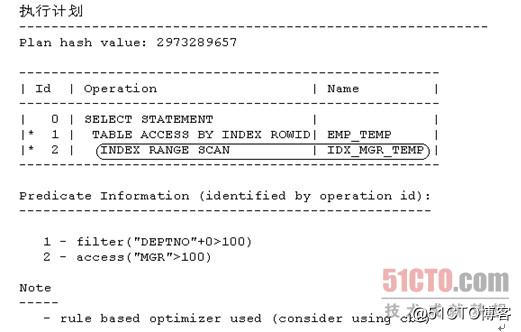
注意,此时Id = 2的执行步骤已经从之前的"INDEX RANGE SCAN | IDX_DEPTNO_TEMP"变为了现在的"INDEX RANGE SCAN | IDX_MGR_TEMP",这说明我们确实迫使RBO改变了执行计划,即我们的调整已经生效了。
之前已经提到:如果目标SQL出现了有两条或者两条以上的执行路径的等级值相同的情况,我们可以通过调整相关对象在数据字典缓存中的缓存顺序来影响RBO对于其执行计划的选择。对于范例SQL 1而言,对索引IDX_DEPTNO_TEMP走索引范围扫描和对索引IDX_MGR_TEMP走索引范围扫描的等级值显然是相同的,所以我们就可以通过调整这两个索引在数据字典缓存中的缓存顺序来改变执行计划。
刚才我们先创建索引IDX_MGR_TEMP,再创建索引IDX_DEPTNO_TEMP,所以索引IDX_MGR_TEMP和IDX_DEPTNO_TEMP在数据字典缓存中的缓存顺序是,先缓存IDX_MGR_TEMP,再缓存IDX_DEPTNO_TEMP。这种情形下RBO选择的是走对索引IDX_DEPTNO_TEMP的索引范围扫描,如果我们现在把索引IDX_MGR_TEMP先Drop掉再重新创建一次,那么就相当于是先创建索引IDX_DEPTNO_TEMP,再创建索引IDX_MGR_TEMP,也就是说此时这两个索引在数据字典缓存中的缓存顺序就刚好颠倒过来了。按照此前介绍的知识,此时RBO应该就会选择走对索引IDX_MGR_TEMP的索引范围扫描。
1.1.1 基于规则的优化器(3)
现在验证一下:
先Drop掉索引IDX_MGR_TEMP:
- SQL> drop index idx_mgr_temp;
- Index dropped
再重新创建上述索引IDX_MGR_TEMP:
- SQL> create index idx_mgr_temp on emp_temp(mgr);
- Index created
然后再次执行范例SQL 1:
- SQL> select * from emp_temp where mgr>100 and deptno>100;
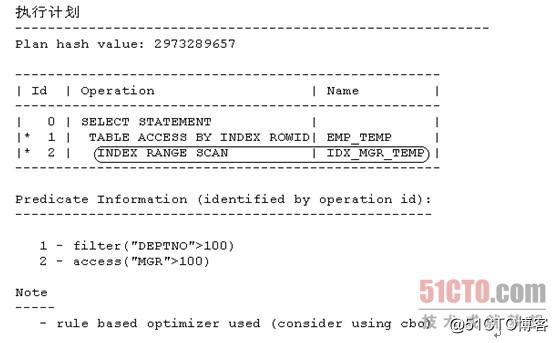
注意,Id = 2的执行步骤已经从之前的"INDEX RANGE SCAN | IDX_DEPTNO_TEMP"变为了现在的"INDEX RANGE SCAN | IDX_MGR_TEMP",说明我们确实迫使RBO改变了执行计划,这也说明当目标SQL有两条或者两条以上的执行路径的等级值相同时,我们确实可以通过调整相关对象在数据字典缓存中的缓存顺序来影响RBO对于其执行计划的选择。
我们之前还提到过:如果目标SQL出现了有两条或者两条以上的执行路径的等级值相同的情况,可以通过改变目标SQL中所涉及的各个对象在该SQL文本中出现的先后顺序来调整该目标SQL的执行计划。这通常适用于目标SQL中出现了多表连接的情形,在目标SQL出现了有两条或者两条以上的执行路径的等级值相同的前提条件下,RBO会按照从右到左的顺序来决定谁是驱动表,谁是被驱动表,进而会据此来选择执行计划,所以如果我们改变了目标SQL中所涉及的各个对象在该SQL文本中出现的先后顺序,也就改变了表连接的驱动表和被驱动表,进而就调整了该SQL的执行计划。
我们来验证一下上述结论。再创建一个测试表EMP_TEMP1:
- SQL> create table emp_temp1 as select * from emp;
- Table created
我们来看如下的范例SQL 3:
- select t1.mgr, t2.deptno
- from emp_temp t1, emp_temp1 t2
- where t1.empno = t2.empno;
对于范例SQL 3而言,表EMP_TEMP和EMP_TEMP1唯一的表连接条件为"t1.empno = t2.empno",而在表EMP_TEMP和EMP_TEMP1的字段EMPNO上均没有任何索引,按照前面介绍的知识,表EMP_TEMP1在SQL文本中的位置是在表EMP_TEMP的右边,所以此时RBO会将表EMP_TEMP1作为表连接的驱动表,而将表EMP_TEMP作为表连接的被驱动表。
执行一下范例SQL 3:
- SQL> select t1.mgr,t2.deptno from emp_temp t1,emp_temp1 t2 where t1.empno=t2.empno;
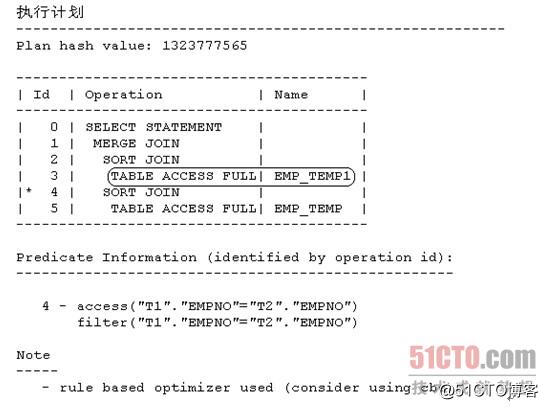
1.1.1 基于规则的优化器(4)
从上面显示的内容可以看出,现在范例SQL 3的执行计划走的是排序合并连接,且驱动表确实是表EMP_TEMP1。
注意,从严格意义上来说,排序合并连接并没有驱动表和被驱动表的概念,这里只是为了方便阐述而人为地给排序合并连接添加了上述概念。
将范例SQL 3中的表EMP_TEMP和EMP_TEMP1在该SQL的SQL文本中的位置换一下,即形成了如下形式的范例SQL 4:
- select t1.mgr, t2.deptno
- from emp_temp1 t2, emp_temp t1
- where t1.empno = t2.empno;
按照前面介绍的知识,现在如果再执行范例SQL 4的话,那么排序合并连接的驱动表应该会变成表EMP_TEMP。
我们来验证一下。执行范例SQL 4:
- SQL> select t1.mgr,t2.deptno from emp_temp1 t2,emp_temp t1 where t1.empno=t2.empno;

从上面显示的内容可以看出,现在范例SQL 4的执行计划走的也是排序合并连接,且驱动表确实已经由之前的表EMP_TEMP1变为了现在的表EMP_TEMP。这说明我们确实使RBO改变了执行计划,也说明当目标SQL有两条或者两条以上的执行路径的等级值相同时,我们确实可以通过改变目标SQL中所涉及的各个对象在该SQL文本中出现的先后顺序来影响RBO对于其执行计划的选择。
注意,这种位置的先后顺序对于目标SQL执行计划的影响是有前提条件的,那就是仅凭各条执行路径等级值的大小RBO难以选择执行计划,也就是说该目标SQL一定有两条或者两条以上执行路径的等级值相同。换句话说,如果RBO仅凭各条执行路径等级值的大小就可以选择目标SQL的执行计划,那么无论怎么调整相关对象在该SQL的SQL文本中的位置,对于该SQL最终的执行计划都不会有任何影响。
我们来验证一下上述结论。看看如下的范例SQL 5:
- select t1.mgr, t2.deptno
- from emp t1, emp_temp t2
- where t1.empno = t2.empno;
对于范例SQL 5而言,表EMP和EMP_TEMP唯一的表连接条件为"t1.empno = t2.empno"。对于表EMP而言,列EMPNO上存在主键索引PK_EMP,而对于表EMP_TEMP而言,列EMPNO上不存在任何索引。所以在使用RBO的情况下,范例SQL 5的执行路径将不再仅限于排序合并连接(RBO不支持哈希连接),也就是说RBO此时有可能可以仅凭各条执行路径等级值的大小就选择出范例SQL 5的执行计划。
执行一下范例SQL 5:
- SQL> select t1.mgr,t2.deptno from emp t1,emp_temp t2 where t1.empno=t2.empno;
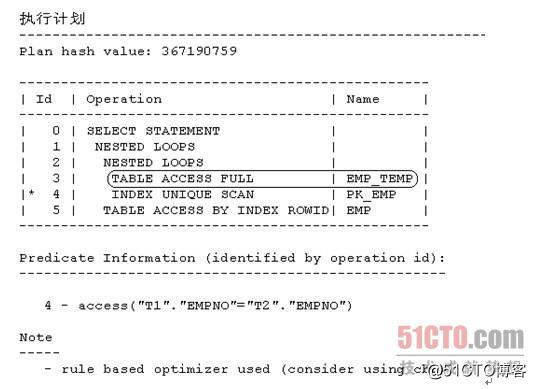
1.1.1 基于规则的优化器(5)
从上面显示的内容可以看出,现在范例SQL 5的执行计划走的是嵌套循环连接,且驱动表是表EMP_TEMP。
我们将范例SQL 5中的表EMP和EMP_TEMP在该SQL的SQL文本中的位置换一下,即形成了如下形式的范例SQL 6:
- select t1.mgr, t2.deptno
- from emp_temp t2, emp t1
- where t1.empno = t2.empno;
然后执行范例SQL 6:
- SQL> select t1.mgr,t2.deptno from emp_temp t2,emp t1 where t1.empno=t2.empno;
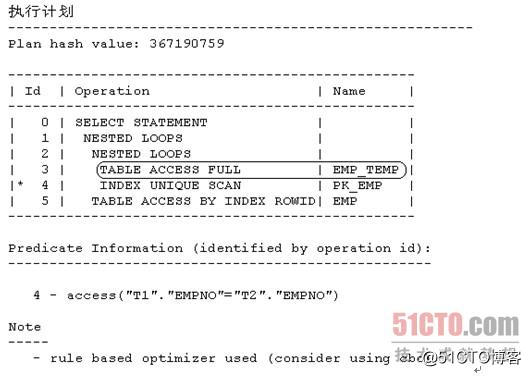
从上面显示的内容可以看出,现在范例SQL 6的执行计划走的还是嵌套循环连接,且驱动表依然是表EMP_TEMP。这就验证了我们之前提到的观点:如果RBO仅凭目标SQL各条执行路径等级值的大小就可以选择出执行计划,那么无论怎么调整相关对象在该SQL的SQL文本中的位置,对于该SQL最终的执行计划都不会有任何影响。
1.1.2 基于成本的优化器
我们在1.1.1节中已经提到:RBO是有明显缺陷的,比如Oracle数据库中很多很好的功能、特性,RBO均不支持,RBO产生的执行计划很难调整等,但这些还不是最要命的,RBO最大的问题在于它是靠硬编码在Oracle数据库代码中的一系列固定的规则来决定目标SQL的执行计划的,而并没有考虑目标SQL中所涉及的对象的实际数据量、实际数据分布等情况,这样一旦固定的规则并不适用于该SQL中所涉及的实际对象时,RBO根据固定规则产生的执行计划就很可能不是当前情况下的最优执行计划了。
我们来看如下的范例SQL 7:
- select * from emp
- where mgr=7902;
对于范例SQL 7而言,假设在表EMP的列MGR上事先存在一个名为IDX_EMP_MGR的单键值B树索引,如果我们使用RBO,则不管表EMP的数据量有多大,也不管列MGR的数据分布情况如何,Oracle在执行范例SQL 7时始终会选择走对索引IDX_EMP_MGR的索引范围扫描,并回表取得表EMP中的记录。Oracle此时是不会选择全表扫描表EMP的,因为对于RBO而言,全表扫描的等级值要高于索引范围扫描的等级值。
RBO的这种选择在表EMP的数据量不大,或者虽然表EMP的数据量很大,但满足条件"mgr=7902"的记录数很少时是没问题的。如果出现了极端的情况(比如表EMP的数据量很大,有1000万行记录,且这1000万行记录的列MGR的值均等于7902),当出现这种极端情况时,如果使用RBO,则RBO还是会选择走对索引IDX_EMP_MGR的索引范围扫描,那就有问题了!因为这相当于要以单块读顺序扫描所有的1000万行索引,然后再回表1000万次,而这显然是没有使用多块读以全表扫描方式直接扫描表EMP的执行效率高的(这里的1000万只是一个理论值,实际情况并不完全是这样,因为这里并没有考虑Index Prefetch所带来的扫描索引时可能会使用的多块读。不考虑Index Prefetch的原因是因为它的存在与否对这里的结论并不会产生本质的影响)。这里RBO会选错执行计划就是因为它并没有考虑目标SQL中所涉及的对象的实际数据量、实际数据分布等情况,所以RBO确实是有先天缺陷的。
为了解决RBO的上述先天缺陷,从Oracle 7开始,Oracle就引入了CBO。之前已经提到过,CBO在选择目标SQL的执行计划时,所用的判断原则为成本,CBO会从目标SQL诸多可能的执行路径中选择一条成本值最小的执行路径来作为其执行计划,各条执行路径的成本值是根据目标SQL语句所涉及的表、索引、列等相关对象的统计信息计算出来的。
这里的统计信息是这样的一组数据:它们存储在Oracle数据库的数据字典里,且从多个维度描述了Oracle数据库里相关对象的实际数据量、实际数据分布等详细信息(关于统计信息,会在"第5章 Oracle里的统计信息"中详细描述)。
这里的成本是指Oracle根据相关对象的统计信息计算出来的一个值,它实际上代表了Oracle根据相关统计信息估算出来的目标SQL的对应执行步骤的I/O、CPU和网络资源的消耗量,这也就意味着Oracle数据库里的成本实际上就是对执行目标SQL所要耗费的I/O、CPU和网络资源的一个估算值。
Oracle在执行目标SQL时需要耗费I/O和CPU,这很容易理解,但这里的网络资源消耗是指什么?实际上,这里的网络资源消耗适用于那些使用了dblink的分布式目标SQL,CBO在解析该类SQL时知道在实际执行它们时所需要的数据并不全部在本地数据库中(需要去远程数据库中取数据),所以此时的网络资源消耗就会被CBO考虑在内。这里需要注意的是,Oracle会把解析这种分布式目标SQL所需要考虑的网络资源消耗折算成对等的I/O资源消耗,所以实际上你可以认为Oracle数据库里的成本仅仅依赖于执行目标SQL时所需要耗费的I/O和CPU资源。另外需要注意的是,在Oracle未引入系统统计信息之前,CBO所计算的成本值实际上全部是基于I/O来估算的,只有在Oracle引入了系统统计信息之后,CBO所计算的成本值才真正依赖于目标SQL的I/O和CPU消耗(关于系统统计信息,会在"第5章 Oracle里的统计信息"中详细描述)。
从上述对CBO的介绍中我们可以看出:CBO会从目标SQL诸多可能的执行路径中选择一条成本值最小的执行路径来作为其执行计划,这也就意味着CBO会认为那些消耗系统I/O和CPU资源最少的执行路径就是当前情况下的最佳选择。注意,这里的"消耗系统I/O和CPU资源"(即成本)的计算方法会随着优化器模式的不同而不同,这一点在"1.2.1 优化器的模式"中会详细说明。
CBO在解析目标SQL时,首先会对目标SQL执行查询转换(关于查询转换,我们会在"第4章 Oracle里的查询转换"中详细说明);接下来,CBO会计算执行完查询转换这一步后得到的等价改写SQL的诸多可能的执行路径的成本,然后从上述诸多可能的执行路径中选择成本值最小的一条来作为原目标SQL的执行计划;在得到了目标SQL的执行计划后,接下来Oracle就会根据此执行计划去实际执行该SQL,并将执行结果返回给用户。这里需要说明的是,Oracle在对一条执行路径计算成本时,并不一定会从头到尾完整计算完,只要Oracle在计算过程中发现算出来的部分成本值已经大于之前保存下来的到目前为止的最小成本值,就会马上中止对当前执行路径成本值的计算,并转而开始计算下一条新的执行路径的成本。这个过程会一直持续下去,直到目标SQL的各个可能的执行路径全部计算完毕或已达到预先定义好的待计算的执行路径数量的阈值。
接下来,介绍与CBO相关的一些基本概念。
1.1.2.1 集的势
Cardinality是CBO特有的概念,直译过来就是"集的势",它是指指定集合所包含的记录数,说白了就是指定结果集的行数。这个指定结果集是与目标SQL执行计划的某个具体执行步骤相对应的,也就是说Cardinality实际上表示对目标SQL的某个具体执行步骤的执行结果所包含记录数的估算。当然,如果是针对整个目标SQL,那么此时的Cardinality就表示对该SQL最终执行结果所包含记录数的估算。
Cardinality和成本值的估算是息息相关的,因为Oracle得到指定结果集所需要耗费的I/O资源可以近似看作随着该结果集所包含记录数的递增而递增,所以某个执行步骤所对应的Cardinality的值越大,那么它所对应的成本值往往也就越大,这个执行步骤所在执行路径的总成本值也就会越大。
1.1.2.2 可选择率(1)
可选择率(Selectivity)也是CBO特有的概念,它是指施加指定谓词条件后返回结果集的记录数占未施加任何谓词条件的原始结果集的记录数的比率。
可选择率可以用如下的公式来表示:

从上述计算可选择率的公式可以看出,可选择率的取值范围显然是0~1,它的值越小,就表明可选择性越好。毫无疑问,可选择率为1时的可选择性是最差的。
可选择率和成本值的估算也是息息相关的,因为可选择率的值越大,就意味着返回结果集的Cardinality的值就越大,所以估算出来的成本值也就会越大。
实际上,CBO就是用可选择率来估算对应结果集的Cardinality的,上述关于可选择率的计算公式等价转换后就可以用来估算Cardinality的值。这里我们用"Original Cardinality"来表示未施加任何谓词条件的原始结果集的记录数,用"Computed Cardinality"来表示施加指定谓词条件后返回结果集的记录数,CBO用来估算Cardinality的公式如下:
- Computed Cardinality = Original Cardinality * Selectivity
虽然看起来可选择率的计算公式很简单,但实际上它的具体计算过程还是很复杂的,每一种具体情况都会有不同的计算公式。其中最简单的情况是对目标列做等值查询时可选择率的计算。在目标列上没有直方图且没有NULL值的情况下,用目标列做等值查询的可选择率是用如下公式来计算的:

我们现在再回过头来看1.1.2节中提到的范例SQL 7:
- select * from emp
- where mgr=7902;
对于范例SQL 7,我们来看一下CBO会如何计算列MGR的可选择率和该SQL返回结果集的Cardinality。
先把列MGR修改为NOT NULL:
- SQL> alter table emp modify (mgr not null);
- Table altered
然后在列MGR上创建一个名为IDX_EMP_MGR的单键值B树索引:
- SQL> create index idx_emp_mgr on emp(mgr);
- Index created
表EMP的记录数现在为13:
- SQL> select count(*) from emp;
- COUNT(*)
- ----------
- 13
列MGR的distinct值的数量也为13:
- SQL> select count(distinct mgr) from emp;
- COUNT(DISTINCTMGR)
- ------------------
- 13
现在使用DBMS_STATS包来对表EMP、表EMP的所有列、表EMP上的所有索引收集一下统计信息(注意,这里没有收集直方图统计信息,关于DBMS_STATS包的用法,我们会在"第5章 Oracle里的统计信息"中详细说明):
- SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT',tabname => 'EMP',estimate_percent => 100,cascade => true, method_opt=>'for all columns size 1',no_invalidate => false);
- PL/SQL procedure successfully completed
接着执行范例SQL 7:
- SQL> set linesize 800
- SQL> set pagesize 900
- SQL> set autotrace traceonly
- SQL> select * from emp where mgr=7902;
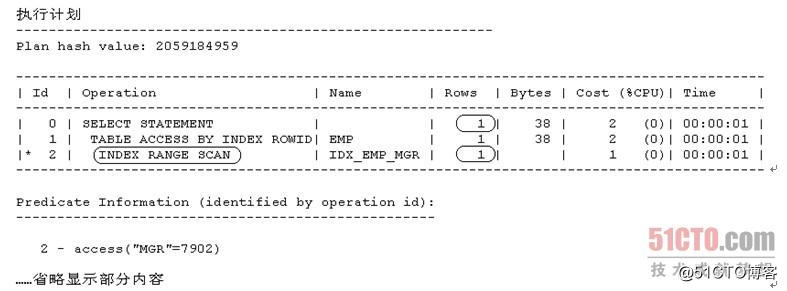
1.1.2.2 可选择率(2)
从Oracle 10g开始,Oracle在解析目标SQL时就会默认使用CBO。注意到上述执行计划的显示内容中有列Rows和列Cost (%CPU),这说明Oracle在解析范例SQL 7时确实使用的是CBO。这里列Rows记录的就是上述执行计划中的每一个执行步骤所对应的Cardinality的值,列Cost (%CPU) 记录的就是上述执行计划中的每一个执行步骤所对应的成本值。
从上面显示的内容可以看出,现在范例SQL 7的执行计划走的是对索引IDX_EMP_MGR的索引范围扫描。注意,Id = 2的执行步骤所对应的列Rows的值为1,这说明CBO评估出来以驱动查询条件"access("MGR"=7902)"去访问索引IDX_EMP_MGR时返回结果集的Cardinality的值是1;另外,Id = 0的执行步骤所对应的列Rows的值也为1,这说明CBO评估出来的范例SQL 7的最终执行结果所对应的Cardinality的值也是1。
这两个值CBO是如何算出来的呢?
之前提到过:在目标列上没有直方图且没有NULL值的情况下,用目标列做等值查询的可选择率的计算公式为Selectivity = ( 1 / NUM_DISTINCT )。现在列MGR没有NULL值也没有直方图统计信息,范例SQL 7的where条件是针对列MGR的等值查询(等值查询条件为"mgr=7902"),而列MGR的distinct值的数量是13,所以此时针对列MGR做等值查询的可选择率就是1/13。另外,之前也提到Cardinality的计算公式为Computed Cardinality = Original Cardinality * Selectivity,表EMP的记录数为13,即此时Original Cardinality的值为13,那么根据Cardinality的计算公式,上述针对列MGR做等值查询的执行步骤所对应的Cardinality的值就是13 * 1/13 = 1,所以这就是CBO评估出来以驱动查询条件"access("MGR"=7902)"去访问索引IDX_EMP_MGR时返回结果集的Cardinality的值为1的原因。又因为where条件"mgr=7902"是范例SQL 7的唯一查询条件,所以范例SQL 7的最终执行结果所对应的Cardinality的值也会是1。
我们现在把列MGR的值全部修改为7,902:
- SQL> update emp set mgr=7902;
- 13 rows updated
- SQL> commit;
- Commit complete
然后重新收集一下统计信息:
- SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT',tabname => 'EMP',estimate_percent => 100,cascade => true, method_opt=>'for all columns size 1',no_invalidate => false);
- PL/SQL procedure successfully completed
接着重新执行范例SQL 7:
- SQL> select * from emp where mgr=7902;
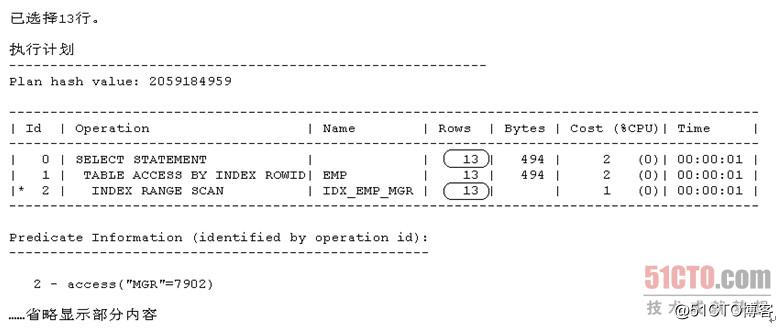
从上述显示内容可以看出,现在范例SQL 7的执行计划走的依然是对索引IDX_EMP_MGR的索引范围扫描,只不过现在CBO评估出来以驱动查询条件"access("MGR"=7902)"去访问索引IDX_EMP_MGR时返回结果集的Cardinality和最终执行结果所对应的Cardinality的值均已从之前的1变为了现在的13。
这是很容易理解的。现在表EMP总的记录数还是13,但列MGR的distinct值的数量已经从之前的13变为了1(即针对列MGR做等值查询的可选择率已经从之前的1/13变为了1),所以现在针对列MGR做等值查询的执行步骤所对应的Cardinality和最终执行结果所对应的Cardinality的值就都会是13 * 1/1 = 13。
我们现在来构造之前在1.1.2节中提到的那种极端情况(表EMP的数据量为1000万行,且这1000万行记录的列MGR的值均等于7,902)。注意,这里并不用真正往表EMP里插入1000万行记录,只需要让CBO认为表EMP的数据量为1000万行就可以了(因为CBO计算成本时完全基于目标SQL的相关对象的统计信息,所以这里我们只需要改一下表EMP和索引IDX_EMP_MGR的统计信息,就可以让CBO认为表EMP的数据量是1000万行了):
1.1.2.2 可选择率(3)
使用DBMS_STATS包将表EMP对应其数据量的统计信息修改为1000万:
- SQL> exec dbms_stats.set_table_stats(ownname => 'SCOTT',tabname => 'EMP',numrows => 10000000,no_invalidate => false);
- PL/SQL procedure successfully completed
然后再将索引IDX_EMP_MGR对应其索引叶子块数量的统计信息修改为10万:
- SQL> exec dbms_stats.set_index_stats(ownname => 'SCOTT',indname => 'IDX_EMP_MGR',numlblks => 100000,no_invalidate => false);
- PL/SQL procedure successfully completed
再次执行范例SQL 7:
- SQL> select * from emp where mgr=7902;
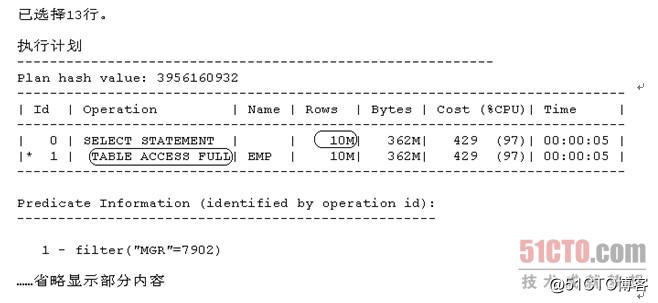
从上面显示的内容中我们可以看出,范例SQL 7的执行计划已经从之前的走对索引IDX_EMP_MGR的索引范围扫描变为了现在的对表EMP的全表扫描,并且针对列MGR做等值查询的执行步骤所对应的Cardinality和最终执行结果所对应的Cardinality的值已经从之前的13变为了现在的"10M"(即1000万)。这就契合了我们之前提到的观点:如果出现了上述这种极端的情况,CBO肯定会选择全表扫描。
这里为什么Cardinality的值会变成1000万呢?因为表EMP的记录数(即Original Cardinality)在CBO的眼里由之前的13变为了现在的1000万,而Selectivity的值还是1,所以最后CBO估算出来的Cardinality的值就从之前的13变为了现在的1000万(这里用到的计算公式还是之前提到的Computed Cardinality = Original Cardinality * Selectivity)。
现在我们再来看一下在上述这种极端情况下RBO的选择。在当前Session中将优化器模式修改为RULE,这表示在当前Session中启用RBO:
- SQL> alter session set optimizer_mode=rule;
- Session altered
然后再次执行范例SQL 7:
- SQL> select * from emp where mgr=7902;

从上面显示的内容中我们可以看出,范例SQL 7的执行计划走的还是对索引IDX_EMP_MGR的索引范围扫描,这也契合了我们之前提到的观点:如果出现了上述这种极端的情况,RBO还是会选择走对索引IDX_EMP_MGR的索引范围扫描。
从对范例SQL 7的实际执行过程我们可以得到如下结论。
(1)RBO确实是靠硬编码在Oracle数据库代码中的一系列固定的规则来决定目标SQL的执行计划的,并没有考虑目标SQL中所涉及的对象的实际数据量、实际数据分布等情况。而CBO则恰恰相反,CBO会根据反映目标SQL中相关对象的实际数据量、实际数据分布等情况的统计信息来决定其执行计划,这就意味着CBO选择的执行计划可能会随着目标SQL中所涉及的对象的统计信息的变化而变化。CBO的这种变化是颠覆性的,这意味着只要统计信息相对准确,则用CBO来解析目标SQL会比在同等条件下用RBO来解析得到正确执行计划的概率要高。
(2)Cardinality和Selectivity的值会直接影响CBO对于相关执行步骤成本值的估算,进而影响CBO对于目标SQL执行计划的选择。
1.1.2.3 可传递性(1)
可传递性(Transitivity)也是CBO特有的概念,它是CBO在图1-1的查询转换中所做的第一件事情,其含义是指CBO可能会对原目标SQL做简单的等价改写,即在原目标SQL中加上根据该SQL现有的谓词条件推算出来的新的谓词条件,这么做的目的是提供更多的执行路径给CBO做选择,进而增加得到更高效执行计划的可能性。这里需要注意的是,利用可传递性对目标SQL做简单的等价改写仅仅适用于CBO,RBO不会做这样的事情。
在Oracle里,可传递性又分为如下这三种情形。
1.简单谓词传递
比如原目标SQL中的谓词条件是"t1.c1=t2.c1 and t1.c1=10",则CBO可能会在这个谓词条件中额外地加上"t2.c1=10",即CBO可能会将原谓词条件"t1.c1=t2.c1 and t1.c1=10"修改为"t1.c1=t2.c1 and t1.c1=10 and t2.c1=10"。改写前后的谓词条件显然是等价的,因为如果t1.c1=t2.c1且t1.c1=10,那么我们就可以推算出t2.c1也等于10。
2.连接谓词传递
比如原目标SQL中的谓词条件是"t1.c1=t2.c1 and t2.c1=t3.c1",则CBO可能会在这个谓词条件中额外地加上"t1.c1=t3.c1",即CBO可能会将原谓词条件"t1.c1=t2.c1 and t2.c1=t3.c1"修改为"t1.c1=t2.c1 and t2.c1=t3.c1 and t1.c1=t3.c1",同理,这里改写前后的谓词条件也是等价的。
3.外连接谓词传递
比如原目标SQL中的谓词条件是"t1.c1=t2.c1(+) and t1.c1=10",则CBO可能会在这个谓词条件中额外加上"t2.c1(+)=10",即CBO可能会将原谓词条件"t1.c1=t2.c1(+) and t1.c1=10"修改为"t1.c1=t2.c1(+) and t1.c1=10 and t2.c1(+)=10"。关于外连接及上述SQL中关键字"(+)"的含义,我们会在"1.2.4.1.2 外连接"中详细描述。
之前已经提到过:Oracle利用可传递性对目标SQL做简单的等价改写的目的是为了提供更多的执行路径给CBO做选择,进而增加得到更高效执行计划的可能性。我们现在来看一个CBO利用可传递性对目标SQL做简单等价改写的实例:
创建两个测试表T1和T2:
- SQL> create table t1(c1 number,c2 varchar2(10));
- Table created
- SQL> create table t2(c1 number,c2 varchar2(10));
- Table created
在表T2的列C1上创建一个名为IDX_T2的索引:
- SQL> create index idx_t2 on t2(c1);
- Index created
往表T1和T2中各插入一些数据,然后我们来看如下的范例SQL 8:
- select t1.c1,t2.c2 from t1, t2
- where t1.c1 = t2.c1 and t1.c1 = 10;
上述范例SQL 8的where条件是"t1.c1 = t2.c1 and t1.c1 = 10",并没有针对表T2的列C1的简单谓词条件,所以按道理讲应该是不能走我们刚才在表T2的列C1上建的索引IDX_T2的。
但实际情况是否如此呢?我们来执行一下范例SQL 8:
- SQL> select t1.c1,t2.c2 from t1, t2
- 2 where t1.c1 = t2.c1 and t1.c1 = 10;
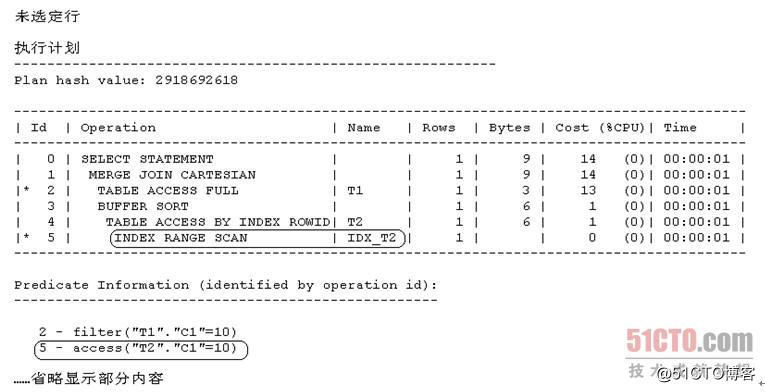
上面显示的内容中Id = 5的执行步骤为"INDEX RANGE SCAN | IDX_T2",这说明Oracle现在还是走了对索引IDX_T2的索引范围扫描。为什么Oracle能够这样做?
注意到Id = 5的执行步骤所对应的驱动查询条件为"access("T2"."C1"=10)",这说明Oracle在访问索引IDX_T2时用的驱动查询条件是"t2.c1=10",但这个"t2.c1=10 "在范例SQL 8的原始SQL文本中并不存在。这就说明CBO此时确实利用可传递性对范例SQL 8做了简单等价改写,即CBO此时已经将范例SQL 8改写成了如下的等价形式:
- select t1.c1,t2.c2 from t1, t2
- where t1.c1 = t2.c1 and t1.c1 = 10 and t2.c1 = 10;
这样做的好处是显而易见的--正是因为上述额外多出来的谓词条件"and t2.c1 = 10",CBO在解析范例SQL 8时就多出了走索引IDX_T2和对应的执行路径这种选择,进而就增加了得到更高效执行计划的可能性。
1.1.2.4 CBO的局限性
CBO诞生的初衷是为了解决RBO的先天缺陷,并且随着Oracle数据库版本的不断进化,CBO也越来越智能,越来越强悍,但这并不意味着CBO就完美无瑕,没有任何缺陷了。这个世界上并没有完美的事情,CBO同样如此。
实际上,CBO的缺陷(或者说局限性)至少表现在如下几个方面。
1.CBO会默认目标SQL语句where条件中出现的各个列之间是独立的,没有关联关系
CBO会默认目标SQL语句where条件中出现的各个列之间是独立的,没有关联关系,并且CBO会依据这个前提条件来计算组合可选择率、Cardinality,进而来估算成本并选择执行计划。但这种前提条件并不总是正确的,在实际的应用中,目标SQL的各列之间有关联关系的情况实际上并不罕见。在这种各列之间有关联关系的情况下,如果还用之前的计算方法来计算目标SQL语句整个where条件的组合可选择率,并用它来估算返回结果集的Cardinality的话,那么估算结果可能就会和实际结果有较大的偏差,导致CBO选错执行计划。
目前可以用来缓解上述问题所带来负面影响的方法是使用动态采样或者多列统计信息,但动态采样的准确性取决于采样数据的质量和采样数据的数量,而多列统计信息并不适用于多表之间有关联关系的情形,所以这两种解决方法都不能算是完美的解决方案。关于动态采样和多列统计信息,我们会在的"5.7 动态采样"和"5.8 多列统计信息"中分别予以详细说明。
2.CBO会假设所有的目标SQL都是单独执行的,并且互不干扰
CBO会假设所有的目标SQL都是单独执行、并且是互不干扰的,但实际情况却完全不是这样。我们执行目标SQL时所需要访问的索引叶子块、数据块等可能由于之前执行的SQL而已经被缓存在Buffer Cache中,所以这次执行时也许不需要耗费物理I/O去相关的存储上读要访问的索引叶子块、数据块等,而只需要去Buffer Cache中读相关的缓存块就可以了。所以,如果此时CBO还是按照目标SQL是单独执行,不考虑缓存的方式去计算相关成本值的话,就可能会高估走相关索引的成本,进而可能会导致选错执行计划。
3.CBO对直方图统计信息有诸多限制
CBO对直方图统计信息的限制体现在如下两个方面。
(1)在Oracle 12c之前,Frequency类型的直方图所对应的Bucket的数量不能超过254,这样如果目标列的distinct值的数量超过254,Oracle就会使用Height Balanced类型的直方图。对于Height Balanced类型的直方图而言,因为Oracle不会记录所有的nonpopular value的值,所以在此情况下CBO选错执行计划的概率会比对应的直方图统计信息是Frequency类型的情形要高。
(2)在Oracle数据库里,如果针对文本型的字段收集直方图统计信息,则Oracle只会将该文本型字段的文本值的头32字节给取出来(实际上只取头15字节)并将其转换成一个浮点数,然后将该浮点数作为上述文本型字段的直方图统计信息存储在数据字典里。这种处理机制的先天缺陷就在于,对于那些超过32字节的文本型字段,只要对应记录的文本值的头32字节相同,Oracle在收集直方图统计信息的时候就会认为这些记录该字段的文本值是相同的,即使实际上它们并不相同。这种先天性的缺陷会直接影响CBO对相关文本型字段的可选择率及返回结果集的Cardinality的估算,进而就可能导致CBO选错执行计划。
我们会在第5章的"5.5.3 直方图"中对上述两个限制予以详细说明,这里不再赘述。
4.CBO在解析多表关联的目标SQL时,可能会漏选正确的执行计划
在解析多表关联的目标SQL时,虽然CBO会采取多种手段来避免漏选正确的执行计划,但是这种漏选往往难以完全避免。因为随着多表关联的目标SQL所包含表的数量的递增,各表之间可能的连接顺序会呈几何级数增长,即该SQL各种可能的执行路径的总数也会随之呈几何级数增长。
假设多表关联的目标SQL所包含表的数量为n,则该SQL各表之间可能的连接顺序的总数就是n!(n的阶乘)。这意味着包含10个表的目标SQL各表之间可能的连接顺序总数为3,628,800,包含15个表的目标SQL各表之间可能的连接顺序总数为1,307,674,368,000。
- SQL> select 10*9*8*7*6*5*4*3*2*1 from dual;
- 10*9*8*7*6*5*4*3*2*1
- --------------------
- 3628800
- SQL> select 15*14*13*12*11*10*9*8*7*6*5*4*3*2*1 from dual;
- 15*14*13*12*11*10*9*8*7*6*5*4*
- ------------------------------
- 1307674368000
包含15个表的多表关联的目标SQL在实际的应用系统中并不罕见,显然CBO在处理这种类型的目标SQL时是不可能遍历其所有可能的情形的,否则解析该SQL的时间将会变得不可接受。
在Oracle 11gR2中,CBO在解析这种多表关联的目标SQL时,所考虑的各个表连接顺序的总和会受隐含参数_OPTIMIZER_MAX_PERMUTATIONS的限制,这意味着不管目标SQL在理论上有多少种可能的连接顺序,CBO至多只会考虑其中根据_OPTIMIZER_MAX_PERMUTATIONS计算出来的有限种可能。这同时也意味着只要该目标SQL正确的执行计划并不在上述有限种可能之中,则CBO一定会漏选正确的执行计划。
虽然有上述这些局限性,但是瑕不掩瑜,CBO毫无疑问是当前情形下Oracle中解析目标SQL的不二选择,并且我们完全有理由相信随着Oracle数据库版本不断的进化,CBO也会越来越完善。
1.2 优化器的基础知识
接下来,介绍一些优化器的基础知识,这些基础知识中的绝大部分内容与优化器的类型是没有关系的,也就是说它们中的绝大部分内容不仅适用于CBO,同样也适用于RBO。
1.2.1 优化器的模式
优化器的模式用于决定在Oracle中解析目标SQL时所用优化器的类型,以及决定当使用CBO时计算成本值的侧重点。这里的"侧重点"是指当使用CBO来计算目标SQL各条执行路径的成本值时,计算成本值的方法会随着优化器模式的不同而不同。
在Oracle数据库中,优化器的模式是由参数OPTIMIZER_MODE的值来决定的,OPTIMIZER_MODE的值可能是RULE、CHOOSE、FIRST_ROWS_n(n = 1, 10, 100, 1000)、FIRST_ROWS或ALL_ROWS。
OPTIMIZER_MODE的各个可能的值的含义为如下所示。
1.RULE
RULE表示Oracle将使用RBO来解析目标SQL,此时目标SQL中所涉及的各个对象的统计信息对于RBO来说将没有任何作用。
2.CHOOSE
CHOOSE是Oracle 9i中OPTIMIZER_MODE的默认值,它表示Oracle在解析目标SQL时到底是使用RBO还是使用CBO取决于该SQL中所涉及的表对象是否有统计信息。具体来说就是:只要该SQL中所涉及的表对象中有一个有统计信息,那么Oracle在解析该SQL时就会使用CBO;如果该SQL中所涉及的所有表对象均没有统计信息,那么此时Oracle就会使用RBO。
3.FIRST_ROWS_n(n = 1, 10, 100, 1000)
这里FIRST_ROWS_n(n = 1, 10, 100, 1000)可以是FIRST_ROWS_1、FIRST_ROWS_10、FIRST_ROWS_100和FIRST_ROWS_1000中的任意一个值,其含义是指当OPTIMIZER_MODE的值为FIRST_ROWS_n(n = 1, 10, 100, 1000)时,Oracle会使用CBO来解析目标SQL,且此时CBO在计算该SQL的各条执行路径的成本值时的侧重点在于以最快的响应速度返回头n(n = 1, 10, 100, 1000)条记录。
我们在1.1.2节中提到过:CBO会从目标SQL诸多可能的执行路径中选择一条成本值最小的执行路径来作为其执行计划,这也就意味着CBO会认为那些消耗系统I/O和CPU资源最少的执行路径就是当前情形下的最佳选择。
那么当OPTIMIZER_MODE的值为FIRST_ROWS_n(n = 1, 10, 100, 1000)时,是否意味着CBO在选择执行计划时所采用的原则将不再是选择成本值最小的执行路径(即消耗系统I/O和CPU资源最少的执行路径),而是选择那些能够以最快的响应速度返回头n(n = 1, 10, 100, 1000)条记录所对应的执行路径?
表面上看确实是这样,但实际上Oracle采用了一种变通的办法使得CBO在选择执行计划时所采用的总原则(成本值最小)依然没有发生变化。这种变通的办法是什么呢?很简单,当OPTIMIZER_MODE的值为FIRST_ROWS_n(n = 1, 10, 100, 1000)时,Oracle会把那些能够以最快的响应速度返回头n(n = 1, 10, 100, 1000)条记录所对应的执行步骤的成本值修改成一个很小的值(远远小于默认情况下CBO对同样执行步骤所计算出的成本值)。这样Oracle就既没有违背CBO选取执行计划的总原则(成本值最小),同时又兼顾了FIRST_ROWS_n(n = 1, 10, 100, 1000)的含义。
4.FIRST_ROWS
FIRST_ROWS是一个在Oracle 9i中就已经过时的参数,它表示Oracle在解析目标SQL时会联合使用CBO和RBO。这里联合使用CBO和RBO的含义是指在大多数情况下,FIRST_ROWS还是会使用CBO来解析目标SQL,且此时CBO在计算该SQL的各条执行路径的成本值时的侧重点在于以最快的响应速度返回头几条记录(类似于FIRST_ROWS_n);但是,当出现了一些特定情况时,FIRST_ROWS转而会使用RBO中的一些内置的规则来选取执行计划而不再考虑成本。比如当OPTIMIZER_MODE的值为FIRST_ROWS时有一个内置的规则,就是如果Oracle发现能用相关的索引来避免排序,则Oracle就会选择该索引所对应的执行路径而不再考虑成本,这显然是不合理的。与之相对应的,在OPTIMIZER_MODE的值为FIRST_ROWS的情形下,你会发现索引全扫描出现的概率会比之前有所增加,这是因为走索引全扫描能够避免排序的缘故。
5.ALL_ROWS
ALL_ROWS是Oracle 10g以及后续Oracle数据库版本中OPTIMIZER_MODE的默认值,它表示Oracle会使用CBO来解析目标SQL,且此时CBO在计算该SQL的各条执行路径的成本值时的侧重点在于最佳的吞吐量(即最小的系统I/O和CPU资源的消耗量)。
之前我们在1.1.2节中已经提到过:"消耗系统I/O和CPU资源"(即成本)的计算方法会随着优化器模式的不同而不同。这里我们怎么来理解成本的计算方法会随着优化器模式的不同而不同?
实际上,成本的计算方法随着优化器模式的不同而不同,主要体现在ALL_ROWS和FIRST_ROWS_n(n = 1, 10, 100, 1000)对成本值计算方法的影响上。当优化器模式为ALL_ROWS时,CBO计算成本的侧重点在于最佳的吞吐量;而当优化器模式为FIRST_ROWS_n(n = 1, 10, 100, 1000)时,CBO计算成本的侧重点会变为以最快的响应速度返回头n(n = 1, 10, 100, 1000)条记录。这意味着同样的执行步骤,在优化器模式为ALL_ROWS时和FIRST_ROWS_n(n = 1, 10, 100, 1000)时CBO分别计算出来的成本值会存在巨大的差异,这也就意味着优化器的模式对CBO计算成本(进而对CBO选择执行计划)有着决定性的影响!我们在"1.3 优化器模式对CBO计算成本带来巨大影响的实例"中会介绍一个由于优化器模式的不当设置而导致CBO认为全表扫描一个700多万行数据的大表的成本值仅为2,进而直接导致CBO选错执行计划的实例。
1.2.2 结果集
结果集(Row Source)是指包含指定执行结果的集合。对于优化器而言(无论是RBO还是CBO),结果集和目标SQL执行计划的执行步骤相对应,一个执行步骤所产生的执行结果就是该执行步骤所对应的输出结果集。
对于目标SQL的执行计划而言,其中某个执行步骤的输出结果就是该执行步骤所对应的输出结果集,同时,该执行步骤所对应的输出结果集可能就是下一个执行步骤的输入结果集。这样一步一步执行下来,伴随的就是结果集在各个执行步骤之间的传递,等目标SQL执行计划的各个执行步骤全部执行完毕后,最后的输出结果集就是该SQL最终的执行结果。
对于RBO而言,我们在对应的执行计划中看不到对相关执行步骤所对应的结果集的描述,虽然结果集的概念对于RBO来说也同样适用。
对于CBO而言,对应执行计划中的列(Rows)反映的就是CBO对于相关执行步骤所对应输出结果集的记录数(即Cardinality)的估算值。
我们来看如下使用CBO的执行计划范例:
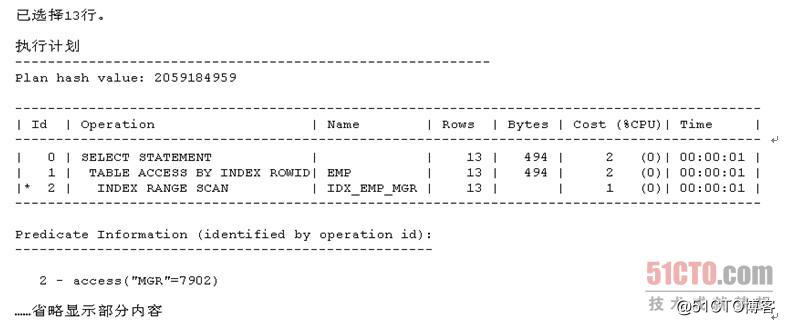
对于上述使用CBO的执行计划而言,我们将Id =1、2的执行步骤所对应的输出结果集分别记为输出结果集1和输出结果集2。这里Oracle会先执行Id = 2的执行步骤。注意到上述Id = 2的执行步骤所对应的列Rows的值为13,这说明CBO对输出结果集2的Cardinality的估算值为13。同时,输出结果集2又会作为Id = 1的执行步骤的输入结果集,注意到上述Id = 1的执行步骤所对应的列Rows的值也为13,这说明CBO对输出结果集1的Cardinality的估算值也为13。同时我们可以看到Id = 0的执行步骤为"SELECT STATEMENT",这说明输出结果集1就是上述整个目标SQL的最终执行结果。
CBO中的一些简称
The following abbreviations are used by optimizer trace.
CBQT - cost-based query transformation
JPPD - join predicate push-down
OJPPD - old-style (non-cost-based) JPPD
FPD - filter push-down
PM - predicate move-around
CVM - complex view merging
SPJ - select-project-join
SJC - set join conversion
SU - subquery unnesting
OBYE - order by elimination
OST - old style star transformation
ST - new (cbqt) star transformation
CNT - count(col) to count(*) transformation
JE - Join Elimination
JF - join factorization
SLP - select list pruning
DP - distinct placement
qb - query block
LB - leaf blocks
DK - distinct keys
LB/K - average number of leaf blocks per key
DB/K - average number of data blocks per key
CLUF - clustering factor
NDV - number of distinct values
Resp - response cost
Card - cardinality
Resc - resource cost
NL - nested loops (join)
SM - sort merge (join)
HA - hash (join)
CPUSPEED - CPU Speed
IOTFRSPEED - I/O transfer speed
IOSEEKTIM - I/O seek time
SREADTIM - average single block read time
MREADTIM - average multiblock read time
MBRC - average multiblock read count
MAXTHR - maximum I/O system throughput
SLAVETHR - average slave I/O throughput
dmeth - distribution method
1: no partitioning required
2: value partitioned
4: right is random (round-robin)
128: left is random (round-robin)
8: broadcast right and partition left
16: broadcast left and partition right
32: partition left using partitioning of right
64: partition right using partitioning of left
256: run the join in serial
0: invalid distribution method
sel - selectivity
ptn - partition

- Oracle的RBO和CBO优化
- ORACLE优化器RBO与CBO介绍总结
- Oracle的RBO和CBO详细介绍和优化模式设置方法
- Oracle的优化器-8i->9i->10g的变迁(RBO->CBO)...
- Oracle的RBO和CBO详细介绍和优化模式设置方法
- Oracle 优化器(RBO,CBO)
- Oracle 优化器:CBO 和 RBO
- Oracle的优化器:RBO/CBO,RULE/CHOOSE/FIRST_ROWS/ALL_ROWS
- Oracle的优化器的 RBO和CBO 方式
- ORACLE优化器RBO与CBO介绍总结
- Oracle优化方式之RBO&amp;CBO
- oracle的优化――RBO和CBO简介以及optimizer_mode参数说明
- ORACLE优化器RBO与CBO介绍总结
- ORACLE优化器RBO与CBO介绍总结
- 【DB.Oracle】Oracle 优化器 (RBO, CBO)
- [转]ORACLE优化器RBO与CBO的区别
- ORACLE优化器RBO与CBO介绍总结
- Oracle的优化器:RBO/CBO,RULE/CHOOSE/FIRST_ROWS/ALL_ROWS 名词解释
- Oracle Optimizer CBO RBO
- Oracle的优化器的RBO和CBO方式