2021年 全网最细大数据学习笔记(三):Hadoop 集群的搭建与配置
文章目录
- 一、学前必备知识
- 二、使用 Centos7 进行 Hadoop 集群的搭建与配置
- 1、Hadoop 集群详解
- 2、搭建集群前的准备工作
- 3、配置 Hadoop 集群
- 4、启动并关闭 Hadoop 集群
- 5、查看 Hadoop 集群的基本信息
- 6、在 Hadoop 集群中运行程序
一、学前必备知识
二、使用 Centos7 进行 Hadoop 集群的搭建与配置
1、Hadoop 集群详解
Hadoop 集群中可以有成百上千个节点,但各个节点的角色,也就是说各节点的分工是怎样的呢?可以从三个角度对 Hadoop 集群节点进行分类,分别为:
- 基本角色划分:Hadoop 集群,可以分为两大类角色:Master 和 slave,即主人和奴隶。
- 从 HDFS 的角度划分:将节点划分为一个 NameNode 和若干个 DataNode。其中 NameNode 作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;DataNode 管理存储的数据。
- 从YARN (MapReduce2) 的角度划分:将节点划分为一个 Resource Manager 和若干个 Node Manager。Resource Manager 负责所有资源的监控、分配和管理。Node Manager 负责每一个节点的维护。
注意:如果从 MapReduce 角度划分的话,可以将节点分为一个 JobTracker 和若干个 TaskTracker。主节点上的 JobTracker 负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点上的 TaskTracker 仅负责由主节点指派的任务。当一个 Job 被提交时,JobTracker 接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控 TaskTracker 的执行。
Hadoop 集群示意图如下图所示:
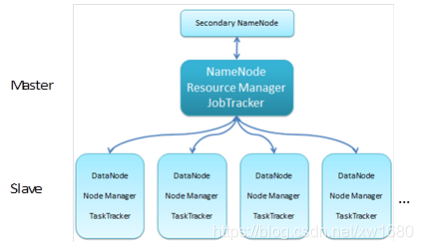
我们也可以看一下下面这张图,图里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,Hadoop 集群是支持主从架构的,不同节点上面启动的进程默认是不一样的。
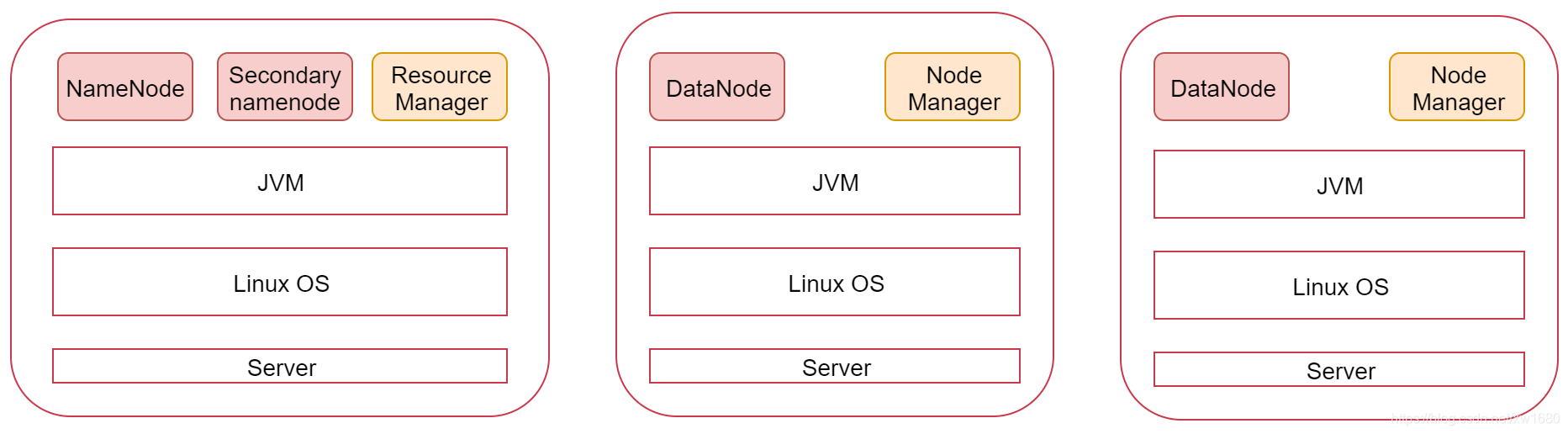
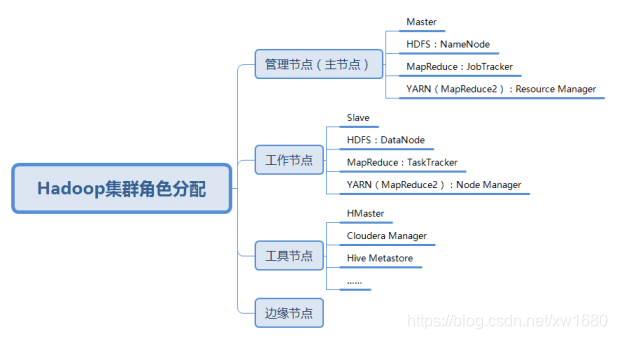
除了上面介绍的主节点(也称为管理节点) NameNode,和工作节点 DataNode 以外,Hadoop 集群中还有工具节点和边缘节点。其中,工具节点主要用于运行非管理进程的其他进程,例如 HMaster、Cloudera Manager、Hive Metastore 等。边缘节点用于集群中启动作业的客户端集群,边缘节点的数量取决于工作负载的类型和数量。综上所述,Hadoop 集群的角色种类如下图所示:
20000
2、搭建集群前的准备工作
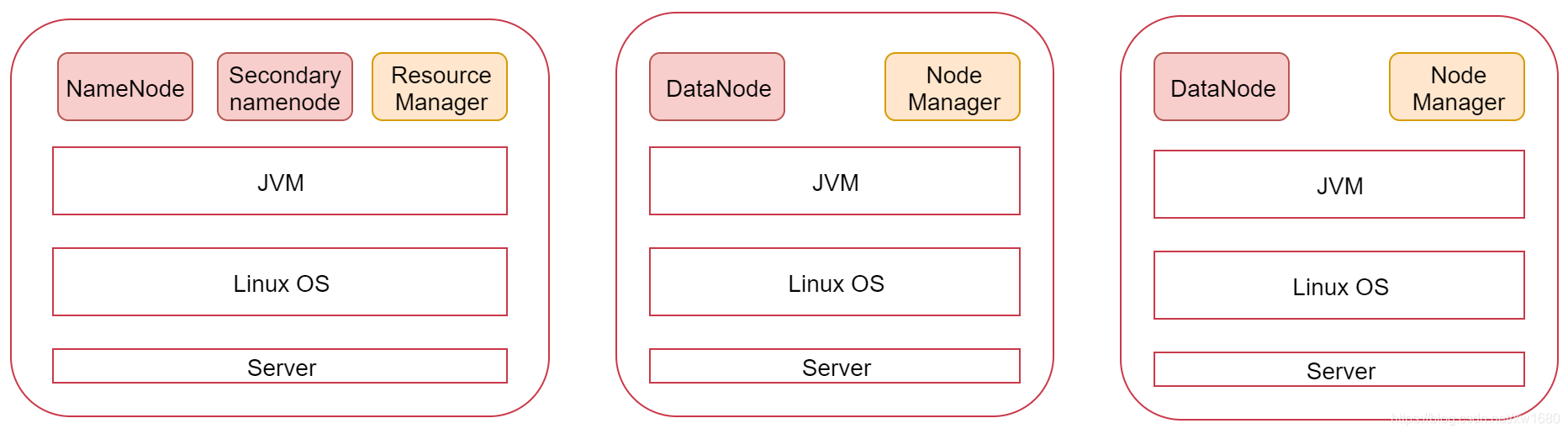
本小节根据图中的规划实现一个一主两从的 Hadoop 集群,环境准备:三个节点 bigdata01 192.168.61.100、bigdata02 192.168.61.101、bigdata03 192.168.61.102,这里的话笔者是在原有 bigdata01 的基础上克隆(通过克隆的方式创建多个节点,具体克隆的步骤在这就不再赘述了)了两台机器,分别命名为 bigdata02 和 bigdata03。接下来就要对这两台新的机器进行基础环境的配置,如:ip、hostname、firewalld、ssh 免密码登录、JDK。说明:由于笔者在 2021年 全网最细大数据学习笔记(二):Hadoop 伪分布式安装 一文中已经详细介绍了这些基础环境的配置,这里也不再赘述。
笔者现在已经具备三台 linux 机器了,里面都是全新的环境。这三台机器的 ip、hostname、firewalld、ssh免密码登录、JDK 这些基础环境已经配置 ok。这些基础环境配置好以后还没完,还有一些配置需要完善。
-
配置 /etc/hosts。因为需要在主节点远程连接两个从节点,所以需要让主节点能够识别从节点的主机名,使用主机名远程访问,默认情况下只能使用 ip 远程访问,想要使用主机名远程访问的话需要在节点的 /etc/hosts 文件中配置对应机器的 ip 和主机名信息。所以在这里我们就需要在 bigdata01 的 /etc/hosts 文件中配置下面信息,最好把当前节点信息也配置到里面,这样这个文件中的内容就通用了,可以直接拷贝到另外两个从节点。命令:vi /etc/hosts,添加下面的内容:

修改 bigdata02 的 /etc/hosts 文件:

修改 bigdata03 的 /etc/hosts 文件:

-
集群节点之间时间同步。集群只要涉及到多个节点的就需要对这些节点做时间同步,如果节点之间时间不同步相差太多,会应该集群的稳定性,甚至导致集群出问题。首先在 bigdata01 节点上操作,yum install -y ntpdate、ntpdate -u ntp.sjtu.edu.cn。把这个同步时间的操作添加到 linux 的 crontab 定时器中,每分钟执行一次:vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
查看命令的路径可以使用 which xxxx,如下:

然后在 bigdata02 和 bigdata03 节点上配置时间同步。 -
SSH 免密码登录完善。注意:针对免密码登录,目前只实现了自己免密码登录自己,最终需要实现主机点可以免密码登录到所有节点,所以还需要完善免密码登录操作。首先在 bigdata01 机器上执行下面命令,将公钥信息拷贝到两个从节点:
scp ~/.ssh/authorized_keys bigdata02:~/ scp ~/.ssh/authorized_keys bigdata03:~/
然后在 bigdata02 和 bigdata03 上执行
cat ~/authorized_keys >> ~/.ssh/authorized_keys
验证一下效果,在 bigdata01 节点上使用 ssh 远程连接两个从节点,如果不需要输入密码就表示是成功的,此时主机点可以免密码登录到所有节点。
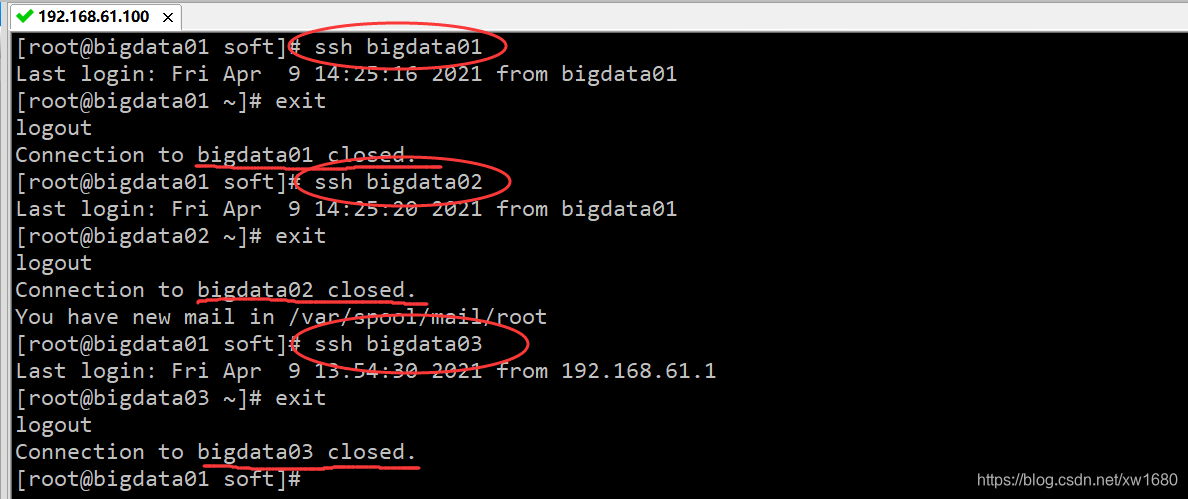
3、配置 Hadoop 集群
OK,那到这为止,集群中三个节点的基础环境就都配置完毕了,接下来就需要在这三个节点中安装 Hadoop 了。首先在 bigdata01 节点上安装。
(1) 把 hadoop-3.2.0.tar.gz 安装包上传到 linux 机器的 /data/soft 目录下。命令:
(2) 解压 hadoop 安装包。命令:tar -zxvf hadoop-3.2.0.tar.gz。配置一下环境变量 vi /etc/profile,
export JAVA_HOME=/data/soft/jdk1.8 export HADOOP_HOME=/data/soft/hadoop-3.2.0 export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
设置立即生效:source /etc/profile。
(3) 修改 hadoop 相关配置文件。进入配置文件所在目录:cd hadoop-3.2.0/etc/hadoop/、修改 hadoop-env.sh 文件,在文件末尾增加环境变量信息,命令:vi hadoop-env.sh。添加内容如下:
export JAVA_HOME=/data/soft/jdk1.8 export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
修改 core-site.xml 文件,注意 fs.defaultFS 属性中的主机名需要和主节点的主机名保持一致:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop_repo</value> </property> </configuration>
修改 hdfs-site.xml 文件,把 hdfs 中文件副本的数量设置为 2,最多为 2,因为现在集群中有两个从节点,还有 secondaryNamenode 进程所在的节点信息:
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>bigdata01:50090</value> </property> </configuration>
修改 mapred-site.xml,设置 mapreduce 使用的资源调度框架:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
修改 yarn-site.xml,设置 yarn 上支持运行的服务和环境变量白名单。注意,针对分布式集群在这个配置文件中还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点。
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata01</value> </property> </configuration>
修改 workers文件,增加所有从节点的主机名,一个一行,vi workers

修改启动脚本,修改 start-dfs.sh,stop-dfs.sh 这两个脚本文件,命令:cd /data/soft/hadoop-3.2.0/sbin,vi start-dfs.sh,vi stop-dfs.sh 在文件前面增加如下内容:
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
修改 start-yarn.sh,stop-yarn.sh 这两个脚本文件,在文件前面增加如下内容:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
(4) 把 bigdata01 节点上将修改好配置的安装包拷贝到其他两个从节点:
cd /data/soft/ scp -rq hadoop-3.2.0 bigdata02:/data/soft/ scp -rq hadoop-3.2.0 bigdata03:/data/soft/
(5) 在 bigdata01 节点上格式化 HDFS:
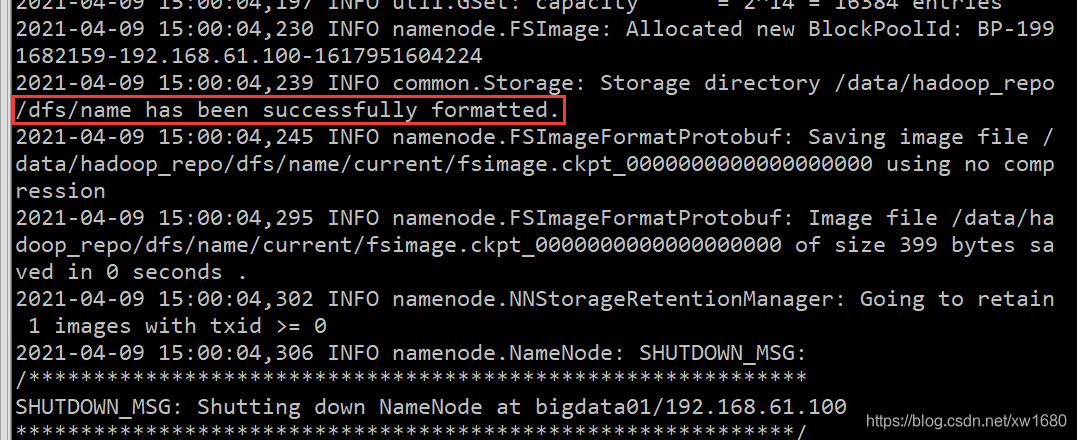
cd /data/soft/hadoop-3.2.0 bin/hdfs namenode -format
如果在后面的日志信息中能看到这一行,则说明 namenode 格式化成功。
4、启动并关闭 Hadoop 集群
1、启动 Hadoop 集群
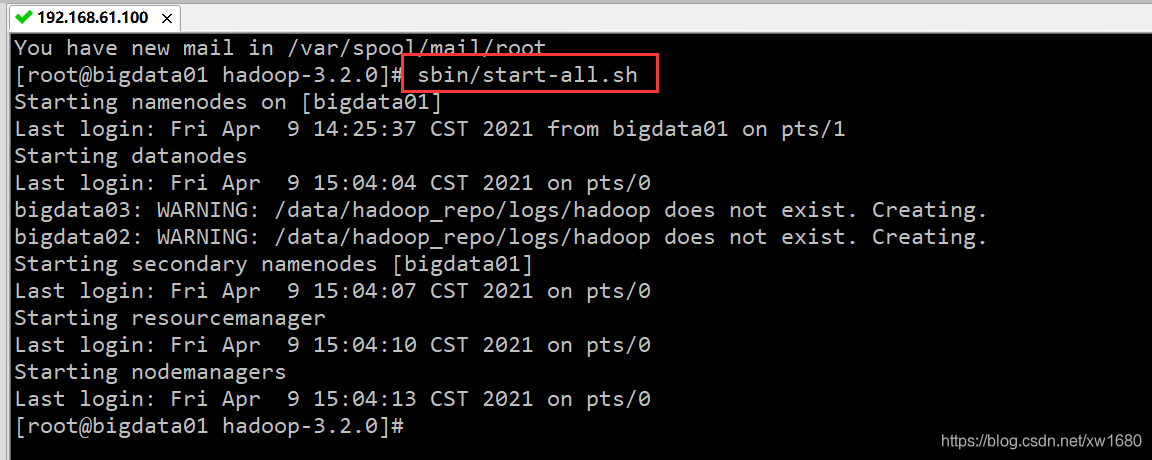
启动 Hadoop 集群的命令可以分为 start-dfs.sh 和 start-yarn.sh 分别用以启动 HDFS 文件系统和 YARN,或者直接使用 start-all.sh 命令。下面通过 start-all.sh 命令启动 Hadoop 集群,结果如下图所示:
2、关闭 Hadoop 集群
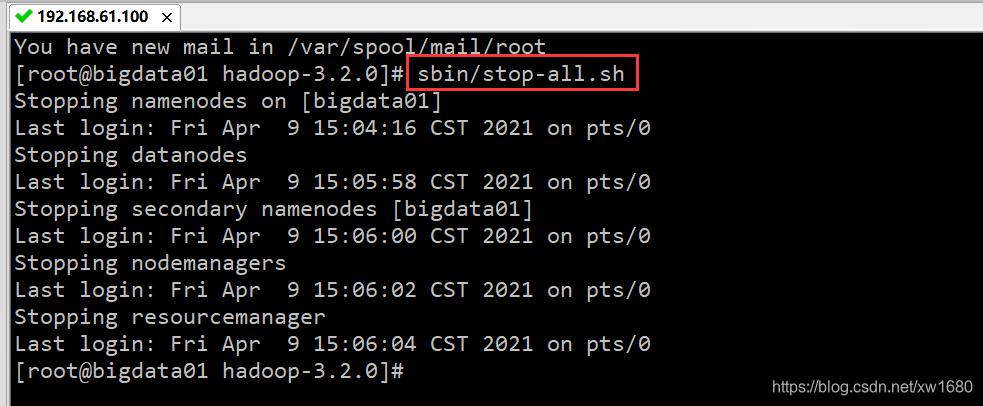
关闭 Hadoop 集群的命令为 stop-all.sh,执行结果如下图所示:
3、验证 Hadoop 集群是否启动成功
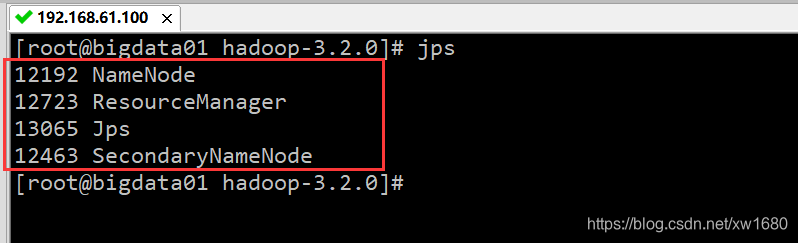
可以通过 jps 命令查看 Hadoop 是否启动成功。首先查看 bigdata01 机器,在 bigdata01 服务器执行 jps 命令后,如果显示的结果是下图所示的四个进程的名称:ResourceManager、NameNode、Jps 和SecondaryNameNode,则表示 bigdata01 服务器启动成功:
下面查看 bigdata02 服务器的 Hadoop 是否启动成功。通过 SSH 连接 bigdata02,然后查看 bigdata02 已启动的服务,结果如下图所示:
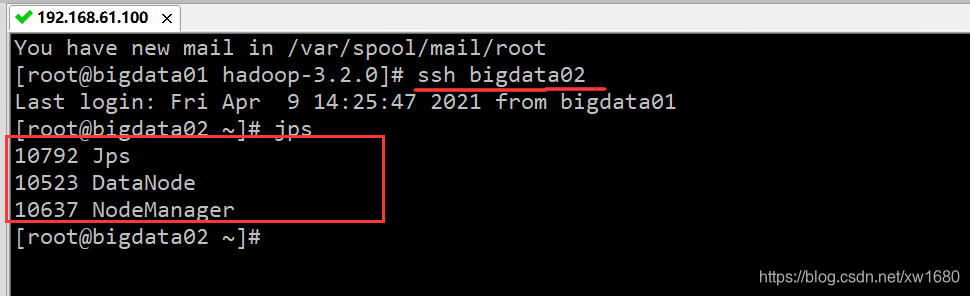
从上图中可知,bigdata02 节点开启了三个进程:NodeManager、Jps 和 DataNode,表明 bigdata02 节点启动了 Hadoop。接下来再检查一下 bigdata03。首先使用 exit 命令退出 bigdata01 与 bigdata02 的连接,然后连接 bigdata03,再使用 jps 命令查看启动进程,结果如下图所示:
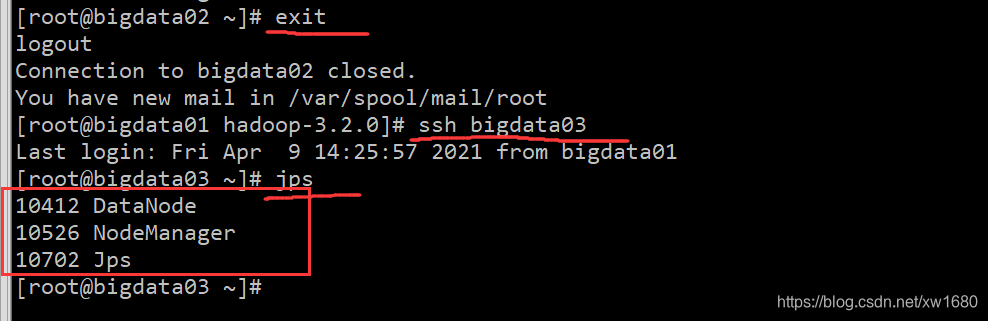
从上图中可知,bigdata03 节点同样开启了三个进程:NodeManager、Jps 和 bigdata03,表明 bigdata03 节点启动了 Hadoop。
5、查看 Hadoop 集群的基本信息
1、查询集群的 HDFS 信息
用户可以通过 HDFS 监控界面检查当前的 HDFS 与 DataNode 的运行情况。打开浏览器,在地址栏中输入:http://bigdata01:9870,按回车键即可看到 HDFS 的监控界面,如下图所示:
该界面提供了如下信息:
- Overview 记录了 NameNode 的启动时间、版本号、编译版本等一些基本信息。
- Summary 是集群信息,提供了当前集群环境的一些有用信息,从图中可知所有 DataNode 节点的基本存储信息,例如硬盘大小以及有多少被 HDFS 使用等一些数据信息,同时还标注了当前集群环境中 DataNode 的信息,对活动状态的 DataNode 也专门做了标记。
- NameNode Storage 提供了 NameNode 的信息,最后的 State 表示此节点为活动节点,可正常提供服务。
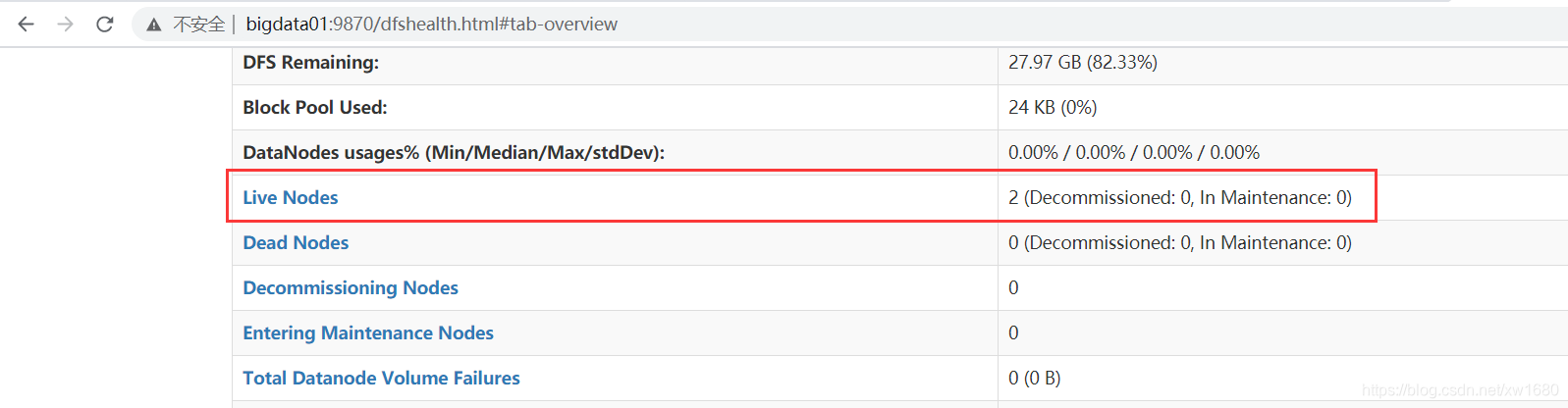
单击 Datanodes,可以查看当前启动的 DataNode 个数,如下图所示:
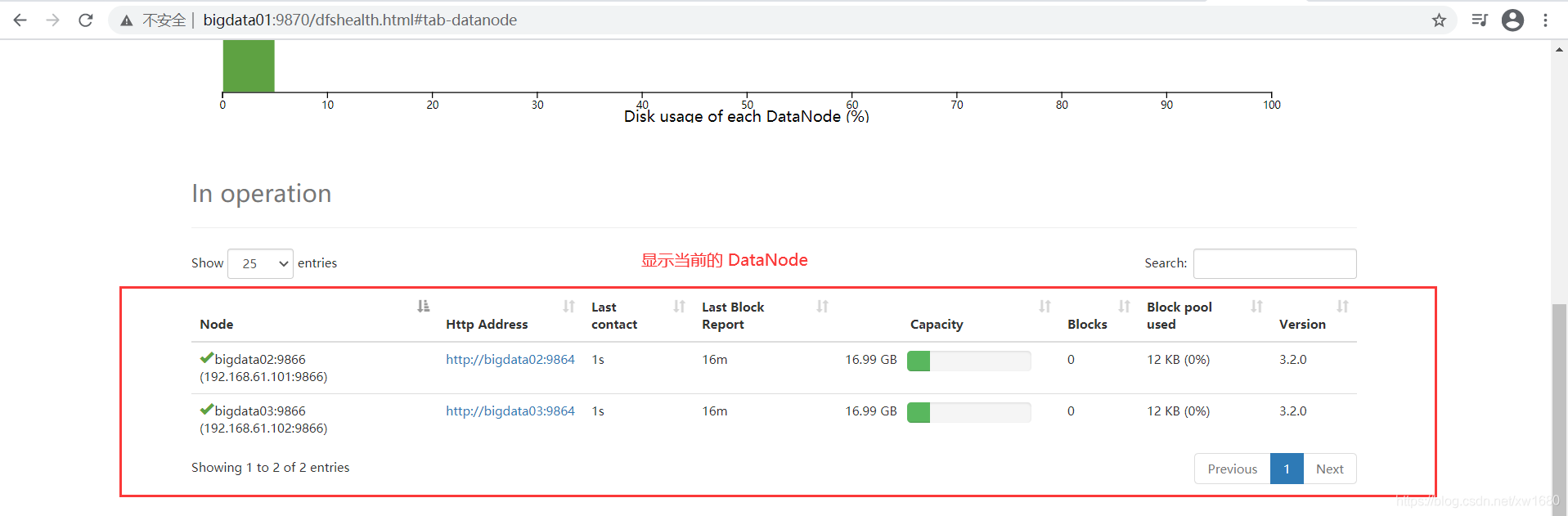
从上图中可以看到 DataNode 节点有 bigdata02 和 bigdata03 两个。
2、查询集群的 YARN 信息
通过网址 http://bigdata01:8088,可以查看到 YARN 的监控界面。打开 Master 节点的浏览器,在地址栏中输入:http://bigdata01:8088,按回车键即可看到 YARN 的监控界面,如下图所示:
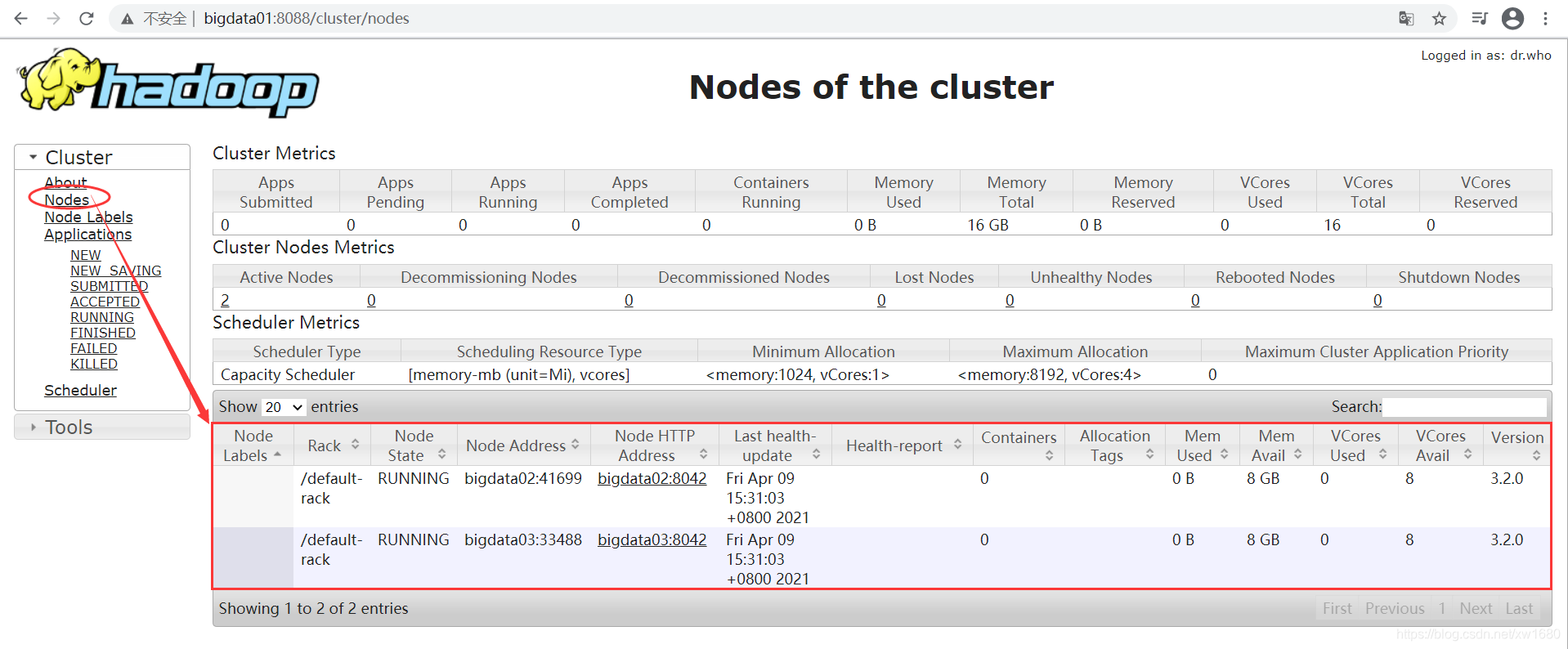
从上图中可知,当前共有 2 个节点 Nodes,分别为:bigdata02 和 bigdata03。
6、在 Hadoop 集群中运行程序
通过上面的步骤,Hadoop 集群已经安装完毕,下面通过在 Hadoop 集群上运行一个 MapReduce 程序,以帮助读者初步理解分布式计算。在 Hadoop 中自带了一些 MapReduce 示例程序,其中有一个用于计算圆周率的 Java 程序包,下面运行此程序。该 jar 包文件的位置和文件名是:
/data/soft/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar
在 bigdata01 的终端输入如下命令:
hadoop jar /data/soft/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar pi 10 10
其中,pi 是类名,后面的两个 10 都是运行参数,第一个 10 表示 Map 次数,第二个 10 表示随机生成点的次数。执行过程中出现下图所示的信息时,则表明程序正常运行:
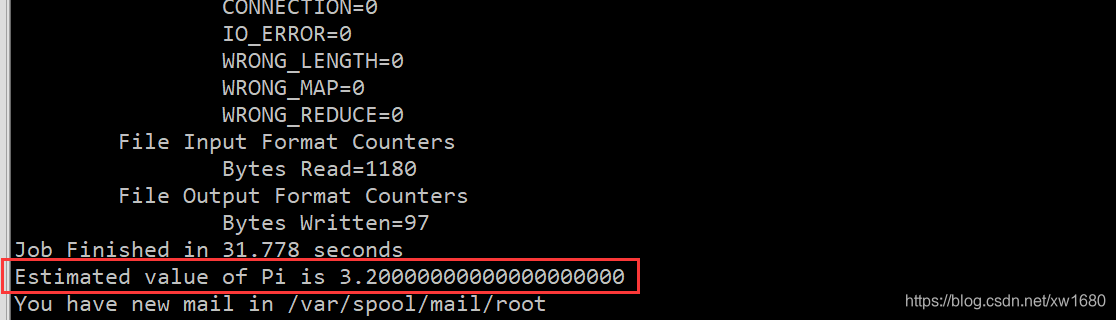
程序执行结果如下图所示,可以看到,计算出来的 pi 值近似等于 3.2。
需要注意,执行 Hadoop MapReduce 程序,是验证 Hadoop 系统是否正常启动的最后一个环节。即使通过 jps 和 Web 方式验证了 Hadoop 集群系统已经启动,并且能够查看到状态信息,也不一定意味着系统可以正常工作。例如,当防火墙没有关闭时,MapReduce 程序执行不会成功。

- Time的hadoop学习笔记之--搭建有三台主机的Hadoop集群
- 大数据hadoop入门学习之集群环境搭建集合
- 大数据Spark “蘑菇云”行动Hadoop实战速成之路第29课:Hadoop架构详解及Hadoop集群搭建、配置和测试实战
- VirtualBox+CentOs虚拟集群搭建配置hadoop2.2.0学习环境
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
- 大数据教程(一)—— Hadoop集群坏境搭建配置
- 大数据学习笔记:配置windows下的hadoop
- hadoop学习笔记<二>----hadoop集群环境的配置
- hadoop学习笔记(一):hadoop集群搭建
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
- hadoop学习笔记:从零开始搭建hadoop集群(完全分布式)
- 搭建hadoop分布式集群以及大数据开发环境(配置hdfs,yarn,mapreduce等)
- 第116讲:Hadoop集群之安装Java、创建Hadoop用户、配置SSH等实战学习笔记
- Hadoop学习笔记(十一)---hadoop集群安装及配置
- DayDayUP_大数据学习课程[1]_hadoop2.6.0完全分布式集群环境和伪分布式集群搭建
- 大数据教程(一)—— Hadoop集群坏境搭建配置
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
- hadoop学习笔记之-生产环境Hadoop大集群配置安装
- Hadoop学习笔记 5 - hdfs和yarn高可用性的搭建与配置
- Hadoop-2.6.0学习笔记(一)HA集群搭建