Python 多线程操作
Python 多线程操作
什么是线程:
线程(Thread)也叫轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位。线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。
举个简单的例子来理解下:
假定有一 7 * 24 小时不停工的工厂,由于其电力有限,一次仅供一个车间使用,当一个车间在生产时,其他车间停工。在这里我们可以理解这个工厂相当于操作系统,供电设备相当于 CPU,一个车间相当于一个进程。
一个车间里,可以有很多工人。他们协同完成一个任务。车间的空间是工人们共享的,这里一个工人就相当于一个线程,一个进程可以包括多个线程。比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
有时候资源有限,比如有些房间最多只能容纳一个人,当一个人占用的时候,其他人就不能进去,只能等待。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫”互斥锁”(Mutual exclusion,缩写 Mutex ),防止多个线程同时读写某一块内存区域。
还有些房间,可以同时容纳 n 个人,比如厨房。也就是说,如果人数大于 n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。这时的解决方法,就是在门口挂 n 把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做”信号量”( Semaphore ),用来保证多个线程不会互相冲突。
不难看出, mutex 是 semaphore 的一种特殊情况(n=1时)。也就是说,完全可以用后者替代前者。但是,因为 mutex 较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种设计。
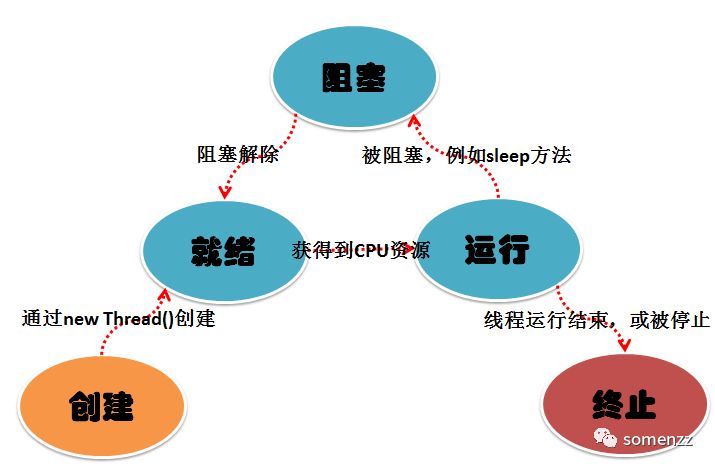
线程有 就绪、阻塞、运行 三种基本状态。
就绪状态是指线程具备运行的所有条件,逻辑上可以运行,在等待处理机;
运行状态是指线程占有处理机正在运行;
阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。
三种状态的相互转化如下图所示:
多线程的优势
那么,问题来了,多线程和单线程相比有什么优势呢?
优势是明显的,可以提高资源利用率,让程序响应更快。单线程是按顺序执行,例如有一单线程程序执行如下操作:
5秒读取文件A
3秒处理文件A
5秒读取文件B
3秒处理文件B
则需要 16s 完成,如果开启两个线程来执行,则如下所示:
5秒读取文件A
5秒读取文件B + 3秒处理文件A
3秒处理文件B
则需要 13s 完成。
Python 中的多线程之 GIL
说到 Python 中的多线程,一个绕不过去的话题就是全局锁 GIL(Global interpreter lock)。GIL 限制了同一时刻只能有一个线程运行,无法发挥多核 CPU 的优势。首先需要明确的一点是 GIL 并不是 Python 的特性,它是在实现 Python 解析器(CPython)时所引入的一个概念。就好比 C++ 是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++ ,Visual C++等。Python 也一样,同样一段代码可以通过 CPython,PyPy,Psyco 等不同的 Python 执行环境来执行。像其中的 JPython 就没有GIL。然而因为 CPython 是大部分环境下默认的 Python 执行环境。所以在很多人的概念里 CPython 就是 Python,也就想当然的把 GIL 归结为 Python 语言的缺陷。所以这里要先明确一点:GIL 并不是 Python 的特性,Python 完全可以不依赖于 GIL。
GIL 本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。在一个 Python 的进程内,不仅有主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的,多个线程先访问到解释器的代码,即拿到执行权限,然后将 target 的代码交给解释器的代码去执行,
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据 100,可能线程 1 执行 x=100 的同时,而垃圾回收执行的是回收 100 的操作,解决这种问题没有什么高明的方法,就是加锁处理,即 GIL。
因此,有了 GIL 的存在,同一时刻同一进程中只有一个线程被执行,那么有人可能要问了:进程可以利用多核,而 Python 的多线程 却无法利用多核优势,Python 的多线程是不是没用了?
答案当然不是。
首先明确我们线程执行的任务是什么,是做计算(计算密集型)还是做输入输出(I/O 密集型),不同地场景使用不同的方法。 多核 CPU,意味着可以有多个核并行完成计算,所以多核提升的是计算性能,但每个 CPU 一旦遇到 I/O 阻塞,仍然需要等待,所以多核对 I/O 密集型任务没什么太高提升。
下面举两个例子来说明:
例子 1 :计算密集型任务
计算密集型任务-多进程
from multiprocessing import Process
import os, time
#计算密集型任务
def work():
res = 0
for i in range(100000000):
res *= i
if __name__ == "__main__":
l = []
print("本机为",os.cpu_count(),"核 CPU") # 本机为4核
start = time.time()
for i in range(4):
p = Process(target=work) # 多进程
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print("计算密集型任务,多进程耗时 %s" % (stop - start))
运行结果如下
本机为 4 核 CPU
计算密集型任务,多进程耗时 14.901630640029907
计算密集型任务-多线程
from threading import Thread
import os, time
#计算密集型任务
def work():
res = 0
for i in range(100000000):
res *= i
if __name__ == "__main__":
l = []
print("本机为",os.cpu_count(),"核 CPU") # 本机为4核
start = time.time()
for i in range(4):
p = Thread(target=work) # 多进程
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print("计算密集型任务,多线程耗时 %s" % (stop - start))
运行结果如下
本机为 4 核 CPU
计算密集型任务,多线程耗时 23.559885025024414
例子 2:I/O 密集型任务
I/O 密集型任务-多进程
from multiprocessing import Process
import os, time
#I/0密集型任务
def work():
time.sleep(2)
print("===>", file=open("tmp.txt", "w"))
if __name__ == "__main__":
l = []
print("本机为", os.cpu_count(), "核 CPU") # 本机为4核
start = time.time()
for i in range(400):
p = Process(target=work) # 多进程
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print("I/0密集型任务,多进程耗时 %s" % (stop - start))
运行结果如下所示:
本机为 4 核 CPU
I/0密集型任务,多进程耗时 21.380212783813477
I/O 密集型任务-多线程
from threading import Thread
import os, time
#I/0密集型任务
def work():
time.sleep(2)
print("===>", file=open("tmp.txt", "w"))
if __name__ == "__main__":
l = []
print("本机为", os.cpu_count(), "核 CPU") # 本机为4核
start = time.time()
for i in range(400):
p = Thread(target=work) # 多线程
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print("I/0密集型任务,多线程耗时 %s" % (stop - start))
运行结果如下所示:
本机为 4 核 CPU
I/0密集型任务,多线程耗时 2.1127078533172607
结论:在 Python 中,对于计算密集型任务,多进程占优势,对于 I/O 密集型任务,多线程占优势。
当然对运行一个程序来说,随着 CPU 的增多执行效率肯定会有所提高,这是因为一个程序基本上不会是纯计算或者纯 I/O,所以我们只能相对的去看一个程序到底是计算密集型还是 I/O 密集型。
Python 多线程之使用方法
Python 提供多线程编程的模块有以下几个:
_thread
threading
Queue
multiprocessing
下面一一介绍
_thread 模块提供了低级别的基本功能来支持多线程功能,提供简单的锁来确保同步,推荐使用 threading 模块。
threading 模块对 _thread 进行了封装,提供了更高级别,功能更强,更易于使用的线程管理的功能,对线程的支持更为完善,绝大多数情况下,只需要使用 threading 这个高级模块就够了。
使用 threading 进行多线程操作:
方法一:是创建 threading.Thread 实例,调用其 start() 方法
import time
import threading
def task_thread(counter):
print(f'线程名称:{threading.current_thread().name} 参数:{counter} 开始时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
num = counter
while num:
time.sleep(3)
num -= 1
print(f'线程名称:{threading.current_thread().name} 参数:{counter} 结束时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
if __name__ == '__main__':
print(f'主线程开始时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
#初始化3个线程,传递不同的参数
t1 = threading.Thread(target=task_thread, args=(3,))
t2 = threading.Thread(target=task_thread, args=(2,))
t3 = threading.Thread(target=task_thread, args=(1,))
#开启三个线程
t1.start()
t2.start()
t3.start()
#等待运行结束
t1.join()
t2.join()
t3.join()
print(f'主线程结束时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
运行结果如下所示
主线程开始时间:2018-07-06 23:03:46
线程名称:Thread-1 参数:3 开始时间:2018-07-06 23:03:46
线程名称:Thread-2 参数:2 开始时间:2018-07-06 23:03:46
线程名称:Thread-3 参数:1 开始时间:2018-07-06 23:03:46
线程名称:Thread-3 参数:1 结束时间:2018-07-06 23:03:49
线程名称:Thread-2 参数:2 结束时间:2018-07-06 23:03:52
线程名称:Thread-1 参数:3 结束时间:2018-07-06 23:03:55
主线程结束时间:2018-07-06 23:03:55
方法二:继承 Thread 类,在子类中重写 run() 和 init() 方法
import time
import threading
class MyThread(threading.Thread):
def __init__(self, counter):
super().__init__()
self.counter = counter
def run(self):
print(
f'线程名称:{threading.current_thread().name} 参数:{self.counter} 开始时间:{time.strftime("%Y-%m-%d %H:%M:%S")}'
)
counter = self.counter
while counter:
time.sleep(3)
counter -= 1
print(
f'线程名称:{threading.current_thread().name} 参数:{self.counter} 结束时间:{time.strftime("%Y-%m-%d %H:%M:%S")}'
)
if __name__ == "__main__":
print(f'主线程开始时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
# 初始化3个线程,传递不同的参数
t1 = MyThread(3)
t2 = MyThread(2)
t3 = MyThread(1)
# 开启三个线程
t1.start()
t2.start()
t3.start()
# 等待运行结束
t1.join()
t2.join()
t3.join()
print(f'主线程结束时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
运行结果如下,与方法一的运行结果一致
主线程开始时间:2018-07-06 23:34:16
线程名称:Thread-1 参数:3 开始时间:2018-07-06 23:34:16
线程名称:Thread-2 参数:2 开始时间:2018-07-06 23:34:16
线程名称:Thread-3 参数:1 开始时间:2018-07-06 23:34:16
线程名称:Thread-3 参数:1 结束时间:2018-07-06 23:34:19
线程名称:Thread-2 参数:2 结束时间:2018-07-06 23:34:22
线程名称:Thread-1 参数:3 结束时间:2018-07-06 23:34:25
主线程结束时间:2018-07-06 23:34:25
如果继承 Thread 类,想调用外部传入函数,代码如下所示
import time
import threading
def task_thread(counter):
print(f'线程名称:{threading.current_thread().name} 参数:{counter} 开始时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
num = counter
while num:
time.sleep(3)
num -= 1
print(f'线程名称:{threading.current_thread().name} 参数:{counter} 结束时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
class MyThread(threading.Thread):
def __init__(self, target, args):
super().__init__()
self.target = target
self.args = args
def run(self):
self.target(*self.args)
if __name__ == "__main__":
print(f'主线程开始时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
# 初始化3个线程,传递不同的参数
t1 = MyThread(target=task_thread,args=(3,))
t2 = MyThread(target=task_thread,args=(2,))
t3 = MyThread(target=task_thread,args=(1,))
# 开启三个线程
t1.start()
t2.start()
t3.start()
# 等待运行结束
t1.join()
t2.join()
t3.join()
print(f'主线程结束时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
这样就和方法一是相通的,实例化自定义的线程类,运行结果不变。
线程同步之 Lock (互斥锁):
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,这个时候就需需要使用互斥锁来进步同步。如下所示的代码,在三个线程对共同变量 num 进行 100 万次加减操作之后,其 num 的结果不为 0,
import time, threading
num = 0
def task_thread(n):
global num
for i in range(1000000):
num = num + n
num = num - n
t1 = threading.Thread(target=task_thread, args=(6,))
t2 = threading.Thread(target=task_thread, args=(17,))
t3 = threading.Thread(target=task_thread, args=(11,))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(num)
运行结果如下:
-19
之所以会出现不为 0 的情况,因为修改 num 需要多条语句,当一个线程正在执行 num+n 时,另一个线程正在执行 num-m ,从而导致之前的线程执行 num-n 时 num 的值已不是之前的值,从而导致最终的结果不为 0 。
为了保证数据的正确性,需要使用互斥锁对多个线程进行同步,限制当一个线程正在访问数据时,其他只能等待,直到前一线程释放锁。使用 threading.Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
import time, threading
num = 0
lock = threading.Lock()
def task_thread(n):
global num
# 获取锁,用于线程同步
lock.acquire()
for i in range(1000000):
num = num + n
num = num - n
#释放锁,开启下一个线程
lock.release()
t1 = threading.Thread(target=task_thread, args=(6,))
t2 = threading.Thread(target=task_thread, args=(17,))
t3 = threading.Thread(target=task_thread, args=(11,))
t1.start(); t2.start(); t3.start()
t1.join(); t2.join(); t3.join()
print(num)
运行结果
0
线程同步之 Semaphore(信号量)
互斥锁同时只允许一个线程访问共享数据,而信号量是同时允许一定数量的线程访问共享数据,比如银行柜台有 5 个窗口,则允许同时有 5 个人办理业务,后面的人只能等待前面有了办完业务后才可以进入柜台办理。
未例代码如下:
import threading
import time
# 同时只有5个人办理业务
semaphore = threading.BoundedSemaphore(5)
# 模拟银行业务办理
def yewubanli(name):
semaphore.acquire()
time.sleep(3)
print(f"{time.strftime('%Y-%m-%d %H:%M:%S')} {name} 正在办理业务")
semaphore.release()
thread_list = []
for i in range(12):
t = threading.Thread(target=yewubanli, args=(i,))
thread_list.append(t)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
# while threading.active_count() != 1:
# time.sleep(1)
运行结果如下所示
2018-07-08 12:33:57 4 正在办理业务
2018-07-08 12:33:57 1 正在办理业务
2018-07-08 12:33:57 3 正在办理业务
2018-07-08 12:33:57 0 正在办理业务
2018-07-08 12:33:57 2 正在办理业务
2018-07-08 12:34:00 7 正在办理业务
2018-07-08 12:34:00 5 正在办理业务
2018-07-08 12:34:00 6 正在办理业务
2018-07-08 12:34:00 9 正在办理业务
2018-07-08 12:34:00 8 正在办理业务
2018-07-08 12:34:03 11 正在办理业务
2018-07-08 12:34:03 10 正在办理业务
可以看出,同一时刻只有 5 个人正在办理业务,即同一时刻只有5个线程获得资源运行。
线程同步之 Condition
条件对象能让一个线程 A 停下来,等待其他线程 B ,线程 B 满足了某个条件后通知(notify)线程 A 继续运行。线程首先获取一个条件变量锁,如果条件不足,则该线程等待(wait)并释放条件变量锁,如果满足就执行线程,也可以通知其他状态为 wait 的线程。其他处于 wait 状态的线程接到通知后会重新判断条件。
下面为一个有趣的例子
import threading
class Boy(threading.Thread):
def __init__(self, cond, name):
super(Boy, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
print(self.name + ": 嫁给我吧!?")
self.cond.notify() # 唤醒一个挂起的线程,让hanmeimei表态
self.cond.wait() # 释放内部所占用的琐,同时线程被挂起,直至接收到通知被唤醒或超时,等待hanmeimei回答
print(self.name + ": 我单下跪,送上戒指!")
self.cond.notify()
self.cond.wait()
print(self.name + ": Li太太,你的选择太明治了。")
self.cond.release()
class Girl(threading.Thread):
def __init__(self, cond, name):
super(Girl, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
self.cond.wait() # 等待Lilei求婚
print(self.name + ": 没有情调,不够浪漫,不答应")
self.cond.notify()
self.cond.wait()
print(self.name + ": 好吧,答应你了")
self.cond.notify()
self.cond.release()
cond = threading.Condition()
boy = Boy(cond, "LiLei")
girl = Girl(cond, "HanMeiMei")
girl.start()
boy.start()
运行结果如下:
LiLei: 嫁给我吧!? HanMeiMei: 没有情调,不够浪漫,不答应 LiLei: 我单下跪,送上戒指! HanMeiMei: 好吧,答应你了 LiLei: Li太太,你的选择太明治了。
线程同步之 Event
事件用于线程间通信。一个线程发出一个信号,其他一个或多个线程等待,调用 event 对象的 wait 方法,线程则会阻塞等待,直到别的线程 set 之后,才会被唤醒。上面求婚哥的例子使用 Event 代码如下:
import threading, time
class Boy(threading.Thread):
def __init__(self, cond, name):
super(Boy, self).__init__()
self.cond = cond
self.name = name
def run(self):
print(self.name + ": 嫁给我吧!?")
self.cond.set() # 唤醒一个挂起的线程,让hanmeimei表态
time.sleep(0.5)
self.cond.wait()
print(self.name + ": 我单下跪,送上戒指!")
self.cond.set()
time.sleep(0.5)
self.cond.wait()
self.cond.clear()
print(self.name + ": Li太太,你的选择太明治了。")
class Girl(threading.Thread):
def __init__(self, cond, name):
super(Girl, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.wait() # 等待Lilei求婚
self.cond.clear()
print(self.name + ": 没有情调,不够浪漫,不答应")
self.cond.set()
time.sleep(0.5)
self.cond.wait()
print(self.name + ": 好吧,答应你了")
self.cond.set()
cond = threading.Event()
boy = Boy(cond, "LiLei")
girl = Girl(cond, "HanMeiMei")
boy.start()
girl.start()
运行结果如下:
LiLei: 嫁给我吧!? HanMeiMei: 没有情调,不够浪漫,不答应 HanMeiMei: 好吧,答应你了 LiLei: 我单下跪,送上戒指! LiLei: Li太太,你的选择太明治了
3. 线程优先级队列(queue)
Python 的 queue 模块中提供了同步的、线程安全的队列类,包括先进先出队列 Queue,后进先出队列 LifoQueue,和优先级队列 PriorityQueue。这些队列都实现了锁原语,可以直接使用来实现线程间的同步。
举一个简单的例子,假如有一小冰箱用来存放冷饮,假如该小冰箱只能放 5 个冷饮,A 不停地往冰箱放冷饮,B 不停地从冰箱取冷饮,A 和 B 的放取速度可能不一致,如何保持他们的同步呢? 这里队列就派上了用场。
先看代码
import threading,time
import queue
#先进先出
q = queue.Queue(maxsize=5)
#q = queue.LifoQueue(maxsize=3)
#q = queue.PriorityQueue(maxsize=3)
def ProducerA():
count = 1
while True:
q.put(f"冷饮 {count}")
print(f"A 放入:[冷饮 {count}]")
count +=1
time.sleep(1)
def ConsumerB():
while True:
print(f"B 取出 [{q.get()}]")
time.sleep(5)
p = threading.Thread(target=ProducerA)
c = threading.Thread(target=ConsumerB)
c.start()
p.start()
运行结果如下:
16:29:19 A 放入:[冷饮 1]
16:29:19 B 取出 [冷饮 1]
16:29:20 A 放入:[冷饮 2]
16:29:21 A 放入:[冷饮 3]
16:29:22 A 放入:[冷饮 4]
16:29:23 A 放入:[冷饮 5]
16:29:24 B 取出 [冷饮 2]
16:29:24 A 放入:[冷饮 6]
16:29:25 A 放入:[冷饮 7]
16:29:29 B 取出 [冷饮 3]
16:29:29 A 放入:[冷饮 8]
16:29:34 B 取出 [冷饮 4]
16:29:34 A 放入:[冷饮 9]
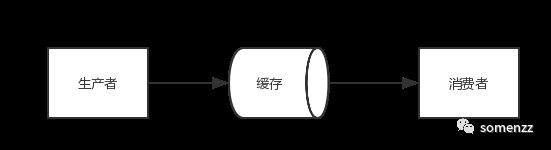
以上代码是实现生产者和消费者模型的一个最简单的例子。在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。生产者消费者模式是通过一个容器(队列)来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。生产者和消费者模式数据流向如下图所示:
4. multiprocessing
Python中线程与进程使用的同一模块 multiprocessing。使用方法也基本相同,唯一不同的是,from multiprocessing import Pool 这样导入的 Pool 表示的是进程池,from multiprocessing.dummy import Pool这样导入的 Pool表示的是线程池。这样就可以实现线程里面的并发了。
线程池实例:
from multiprocessing.dummy import Pool as ThreadPool
import time
def fun(n):
time.sleep(2)
start = time.time()
for i in range(5):
fun(i)
print("单线程顺序执行耗时:", time.time() - start)
start2 = time.time()
# 开8个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool(processes=2)
# 在线程中执行 urllib2.urlopen(url) 并返回执行结果
results2 = pool.map(fun, range(5))
pool.close()
pool.join()
print("线程池(5)并发执行耗时:", time.time() - start2)
上述代码模拟一个耗时 2 秒的任务,比较其顺序执行 5 次和线程池(并发数为 5 )执行的耗时,运行结果如下所示
单线程顺序执行耗时: 10.002546310424805
线程池(5)并发执行耗时: 2.023442268371582
显然并发执行效率更高,接近单次执行的时间。
总结
Python 多线程适合用在 I/O 密集型任务中。I/O 密集型任务较少时间用在 CPU 计算上,较多时间用在 I/O 上,如文件读写,web 请求,数据库请求 等;而对于计算密集型任务,应该使用多进程。

- 一行 Python 实现并行化 -- 日常多线程操作的新思路
- 一行 Python 实现并行化 -- 日常多线程操作的新思路 - 左手键盘,右手书 - SegmentFault
- python3的多线程操作
- 使用Python paramiko模块利用多线程实现ssh并发执行操作
- python多线程操作报错:No handlers could be found for logger "websocket"
- python 多线程遍历windows盘符下文件操作
- Python 读取键盘输入字符,多线程操作,文件操作随机处理 开发范例
- Python多线程操作之互斥锁、递归锁、信号量、事件实例详解
- 转 -- 一行 Python 实现并行化 -- 日常多线程操作的新思路
- python多线程操作实例
- 一行 Python 实现并行化 — 日常多线程操作的新思路
- Python程序中的线程操作-创建多线程
- python多线程实现代码(模拟银行服务操作流程)
- Python多线程和队列操作实例
- 一行 Python 实现并行化 — 日常多线程操作的新思路
- python 多线程遍历windows盘符下文件操作
- 一行 Python 实现并行化 -- 日常多线程操作的新思路
- python threading模块使用 以及python多线程操作的实践(使用Queue队列模块)
- 一行 Python 实现并行化 -- 日常多线程操作的新思路
- python threading模块操作多线程介绍