任务调度神器 airflow 之初体验
airflow 是 apache下孵化项目,是纯 Python 编写的一款非常优雅的开源调度平台。github 上有 8971 个星,是非常受欢迎的调度工具。airflow 使用 DAG (有向无环图) 来定义工作流,配置作业依赖关系非常方便,豪不夸张地说:方便程度简直甩其他任务调度工具一条街。
airflow 有着以下天然优势:
1. 灵活易用,airflow 本身是 Python 编写的,且工作流的定义也是 Python 编写,有了 Python 胶水的特性,没有什么任务是调度不了的,有了开源的代码,没有什么问题是无法解决的,你完全可以修改源码来满足个性化的需求,而且更重要的是代码都是 —human-readable 。
2. 功能强大,自带的 Operators 都有15+,也就是说本身已经支持 15 种不同类型的作业,而且还是可自定义 Operators,什么 shell 脚本,python,mysql,oracle,hive等等,无论不传统数据库平台还是大数据平台,统统不在话下,对官方提供的不满足,完全可以自己编写 Operators。
3. 优雅,作业的定义很简单明了, 基于 jinja 模板引擎很容易做到脚本命令参数化,web 界面更是也非常 —human-readable ,谁用谁知道。
4. 极易扩展,提供各种基类供扩展, 还有多种执行器可供选择,其中 CeleryExcutor 使用了消息队列来编排多个工作节点(worker), 可分布式部署多个 worker ,airflow 可以做到无限扩展。
5. 丰富的命令工具,你甚至都不用打开浏览器,直接在终端敲命令就能完成测试,部署,运行,清理,重跑,追数等任务,想想那些靠着在界面上不知道点击多少次才能部署一个小小的作业时,真觉得 airflow 真的太友好了。
airflow 是免费的,我们可以将一些常做的巡检任务,定时脚本(如 crontab ),ETL处理,监控等任务放在 airflow 上集中管理,甚至都不用再写监控脚本,作业出错会自动发送日志到指定人员邮箱,低成本高效率地解决生产问题。但是由于中文文档太少,大多不够全全,因此想快速上手并不十分容易。首先要具备一定的 Python 知识,反复阅读官方文档,理解调度原理。本系列分享由浅入深,逐步细化,尝试为你揭开 airflow 的面纱。
组成部分
从一个使用者的角度来看,调度工作都有以下功能:
1. 系统配置($AIRFLOW_HOME/airflow.cfg)
2. 作业管理($AIRFLOW_HOME/dags/xxxx.py)
3. 运行监控(webserver)
4. 报警(邮件或短信)
5. 日志查看(webserver 或 $AIRFLOW_HOME/logs/*)
6. 跑批耗时分析(webserver)
7. 后台调度服务(scheduler)
除了短信需要自己实现,其他功能 airflow 都有,而且在 airflow 的 webserver 上我们可以直接配置数据库连接来写 sql 查询,做更加灵活的统计分析。
除了以上的组成部分,我们还需要知道一些概念
一些概念:
DAG
Linux 的 crontab 和 windows 的任务计划,他们可以配置定时任务或间隔任务,但不能配置作业之前的依赖关系。airflow 中 DAG 就是管理作业依赖关系的。DAG 的英文 directed acyclic graphs 即有向无环图,下图 1 便是一个简单的 DAG
图 1: DAG 示例
在 airflow 中这种 DAG 是通过编写 Python 代码来实现的,DAG 的编写非常简单,官方提供了很多的例子,在安装完成后,启动 webserver 即可看到 DAG 样例的源码(其实定义了 DAG 对象的 python 程序),稍做修改即可成为自己的 DAG 。上图 1 中 DAG 中的依赖关系通过下述三行代码即可完成:
是不是非常简洁,并且是 —human-readable。
操作符-Operators
DAG 定义一个作业流,Operators 则定义了实际需要执行的作业。airflow 提供了许多 Operators 来指定我们需要执行的作业:
BashOperator - 执行 bash 命令或脚本。
SSHOperator - 执行远程 bash 命令或脚本(原理同 paramiko 模块)。
PythonOperator - 执行 Python 函数。
EmailOperator - 发送 Email。
HTTPOperator - 发送一个 HTTP 请求。
MySqlOperator, SqliteOperator, PostgresOperator, MsSqlOperator, OracleOperator, JdbcOperator, 等. - 执行 SQL 任务。
DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator 你懂得。
除了以上这些 Operators 还可以方便的自定义 Operators 满足个性化的任务需求。后续会介绍如何使用这些 Operators 敬请关注。
时区-timezone
airflow 1.9 之前的版本使用本地时区来定义任务开始日期,scheduler_interval 中 crontab 表达式中的定时也是依据本地时区为准,但 airflow 1.9 及后续新版本将默认使用 UTC 时区来确保 airflow 调度的独立性,以避免不同机器使用不同时区导致运行错乱。如果调度的任务集中在一个时区上,或不同机器,但使用同一时区时,需要对任务的开始时间及 cron 表达式进行时区转换,或直接使用本地时区。目前 1.9 的稳定版本还不支持时区配置,后续版本会加入时区配置,以满足使用本地时区的需求。
web服务器-webserver
webserver 是 airflow 的界面展示,可显示 DAG 视图,控制作业的启停,清除作业状态重跑,数据统计,查看日志,管理用户及数据连接等。不运行 webserver 并不影响 airflow 作业的调度。
调度器-schduler
调度器 schduler 负责读取 DAG 文件,计算其调度时间,当满足触发条件时则开启一个执行器的实例来运行相应的作业,必须持续运行,不运行则作业不会跑批。
工作节点-worker
当执行器为 CeleryExecutor 时,需要开启一个 worker。
执行器-Executor
执行器有 SequentialExecutor, LocalExecutor, CeleryExecutor
SequentialExecutor 为顺序执行器,默认使用 sqlite 作为知识库,由于 sqlite 数据库的原因,任务之间不支持并发执行,常用于测试环境,无需要额外配置。
LocalExecutor 为本执行器,不能使用 sqlite 作为知识库,可以使用 mysql,postgress,db2,oracle 等各种主流数据库,任务之间支持并发执行,常用于生产环境,需要配置数据库连接 url。
CeleryExecutor 为 Celery 执行器,需要安装 Celery ,Celery 是基于消息队列的分布式异步任务调度工具。需要额外启动工作节点-worker。使用 CeleryExecutor 可将作业运行在远程节点上。
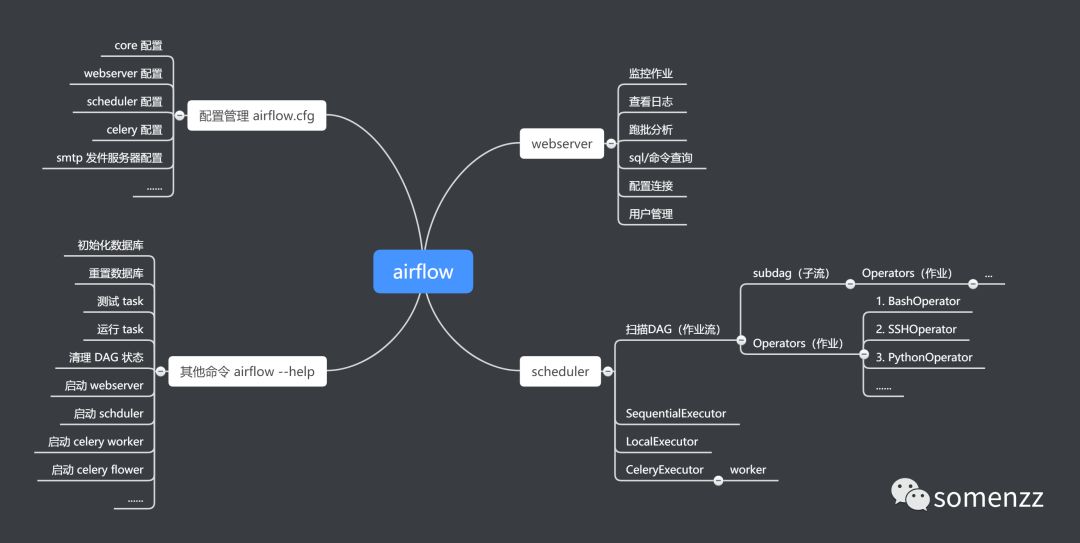
以一张思维导图总结今天的内容:

- 企业级任务调度框架Quartz(8) 线程在Quartz里的意义(2)
- JBoss Scheduler任务调度BUG之一
- Laravel 实现任务调度功能
- Spring quartz 任务调度(注解方式)
- java项目中使用springmvc的调度任务
- spring quartz任务调度
- java定时任务调度-Timer(1)
- 基于quartz任务调度组件的使用
- 10-Spring Boot ( 定时任务调度 )
- spring4.2.5实现调度任务的几种方式
- hadoop日志分析系统二 第一部分 利用任务调度系统定期的把web系统所产生的日志文件导入到hdfs中
- Spring任务调度实战之Timer
- SQL SERVER SQLOS的任务调度--微软亚太区数据库技术支持组 官方博客
- java任务调度Timer简单例子
- Quarzt.NET 任务调度框架
- clover分布式任务调度系统
- Quartz任务调度快速入门
- spark源码之Job执行(2)任务调度taskscheduler
- Spring quartz 任务调度(注解方式)
- SpringTask 任务调度