聚类模型评价(python实现)
2021-03-23 20:44
645 查看
概述
评价指标分为外部指标和内部指标两种,外部指标指评价过程中需要借助数据真实情况进行对比分析的指标,内部指标指不需要其他数据就可进行评估的指标。下表中列出了几个常用评价指标的相关情况:
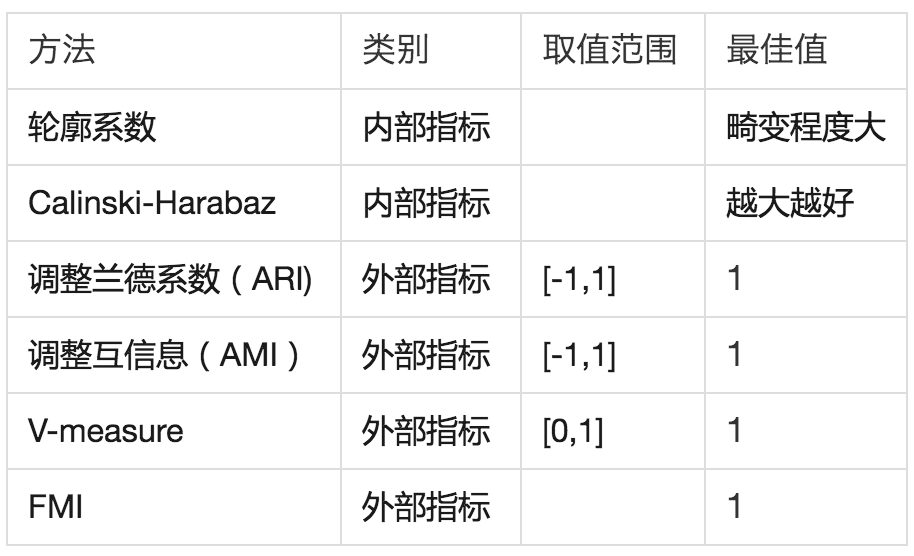
2
2
Python实现
- 轮廓系数(Silhouette Coefficient)
轮廓系数可以用来选择合适的聚类数目。根据折线图可直观的找到系数变化幅度最大的点,认为发生畸变幅度最大的点就是最好的聚类数目。
from sklearn.metrics import silhouette_score data2 = data1.sample(n=2000,random_state=123,axis=0) silhouettescore=[] for i in range(2,8): kmeans=KMeans(n_clusters=i,random_state=123).fit(data2.iloc[:,1:4]) score=silhouette_score(data2.iloc[:,1:4],kmeans.labels_) silhouettescore.append(score) plt.figure(figsize=(10,6)) plt.plot(range(2,8),silhouettescore,linewidth=1.5,linestyle='-') plt.show()
数目在2到3时畸变程度越大,因此选择2类较好。
Calinski-Harabaz 指数
Calinski-Harabaz指数也可以用来选择最佳聚类数目,且运算速度远高于轮廓系数,因此个人更喜欢这个方法。内部数据的协方差越小,类别之间的协方差越大时,Calinski-Harabasz分数越高。
from sklearn.metrics import calinski_harabaz_scorefor i in range(2,7): kmeans=KMeans(n_clusters=i,random_state=123).fit(data2.iloc[:,1:4]) score=calinski_harabaz_score(data2.iloc[:,1:4],kmeans.labels_) print('聚类%d簇的calinski_harabaz分数为:%f'%(i,score))#聚类2簇的calinski_harabaz分数为:3535.009345#聚类3簇的calinski_harabaz分数为:3153.860287#聚类4簇的calinski_harabaz分数为:3356.551740#聚类5簇的calinski_harabaz分数为:3145.500663#聚类6簇的calinski_harabaz分数为:3186.529313可见,分为两类的值最高,结论与上面的轮廓系数判断方法一致。
调整兰德系数(Adjusted Rand index,ARI)
从兰德系数开始,为外部指标。兰德系数用来衡量两个分布的吻合程度,取值范围[-1,1],数值越接近于1越好,并且在聚类结果随机产生时,指标接近于0。为方便演示,省去聚类过程,直接用样例数据展示实现方法。
from sklearn.metrics import adjusted_rand_scorelabels_true = [0, 0, 1, 1, 0, 1]labels_pred = [0, 0, 1, 1, 1, 2]ari=adjusted_rand_score(labels_true, labels_pred) print('兰德系数为:%f'%(ari))#兰德系数为:0.117647- 互信息(Adjusted Mutual Information,AMI)
互信息也是用来衡量两个分布的吻合程度,取值范围[-1,1],值越大聚类效果与真实情况越吻合。
from sklearn.metrics import adjusted_mutual_info_scorelabels_true = [0, 0, 1, 1, 0, 1]labels_pred = [0, 0, 1, 1, 1, 2]ami=adjusted_mutual_info_score(labels_true, labels_pred) print('互信息为:%f'%(ami))#互信息为:0.225042- V-measure
说V-measure之前要先介绍两个指标:
同质性(homogeneity):每个群集只包含单个类的成员。
完整性(completeness):给定类的所有成员都分配给同一个群集。
V-measure是两者的调和平均。V-measure取值范围为 [0,1],越大越好,但当样本量较小或聚类数据较多的情况,推荐使用AMI和ARI。
from sklearn import metricslabels_true = [0, 0, 0, 1, 1, 1]labels_pred = [0, 0, 1, 1, 2, 2]h_score=metrics.homogeneity_score(labels_true, labels_pred)c_score=metrics.completeness_score(labels_true, labels_pred) V_measure=metrics.v_measure_score(labels_true, labels_pred) print('h_score为:%f \nc_score为:%f \nV_measure为:%f'%(h_score,c_score,V_measure))#h_score为:0.666667 #c_score为:0.420620 #V_measure为:0.515804- Fowlkes-Mallows Index(FMI)
FMI是对聚类结果和真实值计算得到的召回率和精确率,进行几何平均的结果,取值范围为 [0,1],越接近1越好。
from sklearn.metrics import fowlkes_mallows_scorelabels_true = [0, 0, 0, 1, 1, 1]labels_pred = [0, 0, 1, 1, 2, 2]fmi=fowlkes_mallows_score(labels_true, labels_pred) print('FMI为:%f'%(fmi))#FMI为:0.471405一般情况下,主要是对无y值的数据进行聚类操作。如果在评价中用到外部指标,就需通过人工标注等方法获取y值,成本较高,因此内部指标的实际实用性更强。
相关文章推荐
- 作业1:关于使用python中scikit-learn(sklearn)模块,实现鸢尾花(iris)相关数据操作(数据加载、标准化处理、构建聚类模型并训练、可视化、评价模型)
- 【机器学习】聚类结果评价指标及python3代码实现
- 数学模型 机器学习 系统聚类(system clustering) Python实现
- python|6.2构建并评价聚类模型
- 聚类评价指标S_Dbw的python实现
- TopicModel主题模型 - LDA的python实现及参数选择
- Python数据挖掘课程 三.Kmeans聚类代码实现、作业及优化
- 基于用户最近邻模型的协同过滤算法的Python代码实现
- spark机器学习笔记:(七)用Spark Python构建聚类模型
- word2vec模型原理与实现 word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具. gensim包提供了word2vec的python接口. word2vec采用
- AlexNet模型实现(4. 基于Tensorflow的python实现)
- 机器学习经典算法详解及Python实现--聚类及K均值、二分K-均值聚类算法
- python实现select和epoll模型socket网络编程
- python实现RDD转成聚类输入矩阵
- 文本聚类算法之一趟聚类(One-pass Cluster)算法的python实现
- 机器学习Python实现之线性模型
- 基本的传染病模型:SI、SIS、SIR及其Python代码实现
- 最大熵模型与EM算法及python实现
- 用python简单实现类似thinkphp的针对Mysql操作的数据模型
- lda模型的python实现