游戏AI领域,机器人技术的研究与应用
游戏AI的种类和演变过程
NPC驱动
游戏中的人工智能主要指的是NPC(无用户角色)。游戏的杂兵是低级NPC,都是事先编好行进路线,用事件驱动其出现或生效。单机游戏群战中的配合型NPC则是中级NPC,比如仙剑中的队友,他们由一定事先编好的策略驱动,有一定的事先设定的应变能力,但是一般场景都会比较单一,确定。

网游中的高级团战英雄相当于高级NPC,有着复杂且变化多样的场景,动作丰富且评价模式也相对复杂。最后就是特高级NPC,一般都是高级益智玩具类型,比如带有博弈心态的扑克,带有套路计算的麻将,带有长久盘面考虑功能的象棋和围棋等。
人工智能的差距
我们现在之所以对人工智能感兴趣,是因为它能够应用在很多的领域,比如图形、音频、游戏等,能够代替大量繁重的人工。现在的人工智能其实和以前所谈的人工智能是有着一定差异的,之前人们认为的人工智能其实更多的是自动化。但近两年随着计算能力的提升,神经网络已经可以和自动化进行结合了。
神经网络之所以受到广泛关注,其中有一点很重要——处理能力很强。旧式的游戏AI,在二维的空间中能采取的行动并不多,处理的维度也不够多,一般几个或者十几个维度就能描述客观空间中的事件。棋牌类AI则相对复杂些,因为处理的维度已经达到了几十个,比如上世纪诞生的深蓝机器人,它所使用的技术其实就是数字搜索。当时采用这种蛮力计算的方式还能够解决问题,但随着计算量的逐步增大瓶颈也会随之出现。所以有人想到从算法层面去解决这方面的困境。
高级人工智能的套路
高级人工智能的套路目前来说比较成熟的有三种:经典统计、神经网络、强化学习。
经典统计有个很典型的应用场景——棋牌类游戏,比如德州扑克中就可以根据手牌和池子中的牌大概的判断出获胜的概率,这里使用的就是简单统计的方法。经典统计其实并没有涉及人工智能,开发者完全可以通过自己写的程序来实现。
卷积网络
神经网路其实和函数有些相似,函数是对给到的x进行一系列运算然后输出y。神经网路相当于多层函数的嵌套,输入的x先经过一层函数运算,然后输出的值再经由另一层神经网络或者函数运算,直到经过最后一层运算输出y。理想情况下如果神经网络足够智能,那么输出的应该是最优的y。这里的关键在于x应该经过怎样的计算,例如对于最简单的y=ax+b函数,如果a、b未知就无法获得y。
其实可以在神经网络中先随机给出系数,这样每次x输入后都会有不同的y输出。通过迭代计算每次都对a、b进行更新,一旦输出的y符合期望,那么a、b也就能够随之得到确定。这是一个反向解方程的过程,在已知x和y的情况下求a和b。这种方式也被称为卷积网络。
监督型学习的卷积网络有着收敛速度快、泛化能力好、应用场景广等优点。缺点是需要大量正样本及人类干预,也就是需要质量较高的样本,劣质样本产生的结果会非常不尽人意。它适用于变化相对有限,输入数据量偏小的游戏。
卷积网络实现AI
斗地主游戏相信大家都很熟悉,要想在该游戏中实现机器人,通过手工编写if else是可行的,但也可以使用卷积网络来完成。这个神经网络中的输入值为扫描到的各轮出牌和手牌,输出值y为每局获胜的玩家每轮打出的牌。
基本上搭建如上图所示的三层网络就能实现想要的结果,30万局牌大概10分钟就能够训练完成。图中左边的向量表示的就是牌面的信息:
第一行:代表玩家现在的手牌状态;
第二行:代表玩家上轮出牌记录;
第三行:代表上家上轮出牌记录;
第四行:代表下家上轮出牌记录;
第五行:代表玩家的所有出牌记录;
第六行:代表上家的所有出牌记录;
第七行:代表下家的所有出牌记录;
该模型训练完成之后,和人对战的时候,地主身份的胜率是50%左右,农民身份的胜率为40%。
DQN实现AI原理
接下来我们讨论下深度学习和强化学习的结合,首先来看下强化学习。机器人作为主观体需要认知世界,而一般训练机器人的时候目标是固定的,要人为的将目标的信息传递给机器人,这些信息就叫做奖励。同时机器人还要能够获取和认知环境信息,然后输出动作到环境中,最后机器人会获得一个奖励值。奖励值是一种超参数,是用来判断行为的正确性的依据。因此必须要人为设定超参数的值,才能够对机器人的行为结果进行判断,以促进机器人的进化。
马尔可夫决策过程
机器人在这一过程中会不断和客观世界发生动作,接收到各种奖励。这里输入的环境就是x,输出的动作则是y。
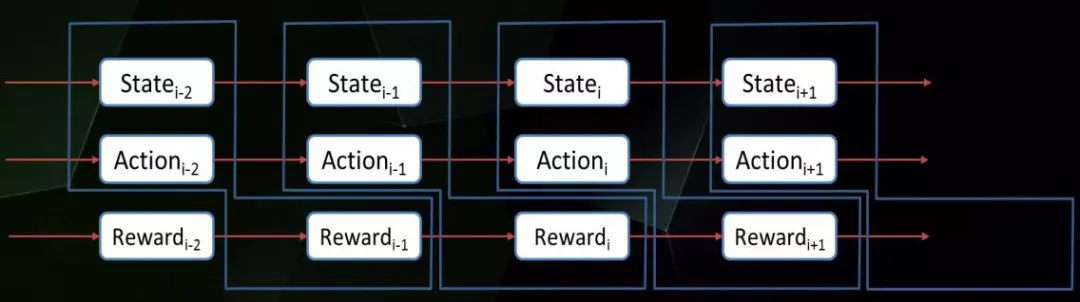
展开来看就是上图这样的形式,随着时间的推移,当前的状态、动作、奖励值都会被统计下来。
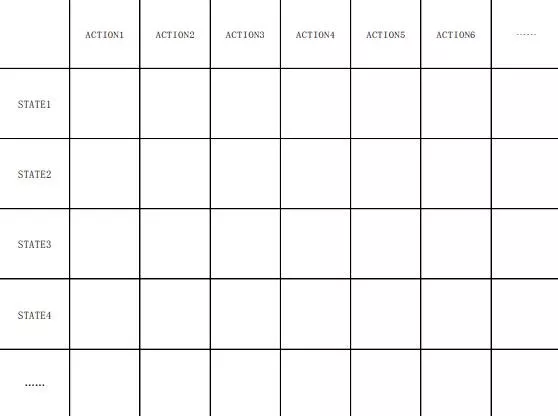
在获取到大量的信息数据之后,就能形成如上图所示的表格,空格中填入的是Reward(奖励值)。显而易见这种情况下完全可以根据表格判断出某个状态下的最优动作。
动态决策
上面的做法其实是存在缺陷的,它虽然能够在某一瞬间获得数值最大的奖励,但无法预判到该行动对下一瞬间的影响,有可能下一瞬间的奖励值是最小的。
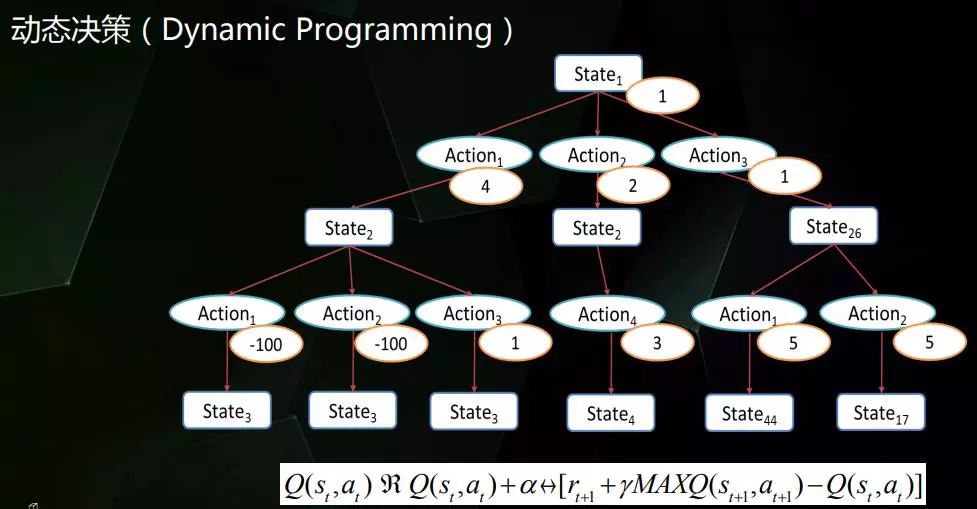
这种情况下就需要采用动态决策,最终形成的是如上图所示的树状结构。先在某个状态下采取不同的行动形成不同的状态,然后在这些状态中再采取不同的行动。图中标记的那些数值表示的就是奖励值,通过统计奖励值就可以获得最优的路线。
可能有朋友已经发现了,最左边的两条路线数值其实是一样的。要解决这种情况需要用到图中下方的公式,它主要用于数值的回溯。可以看出State1和State26显然是被低估的,因为既然能够获得5这样的数据,那就证明State1还有很大的价值空间没有被发现。这时候就要将数值5回溯给State1,然后再重新进行评估。
这里对这两种执行器进行了比较。real-time的优势主要在于响应时间小。task-tracker则是支持数据重分布,SQL支持也比real-time略好,同时并发数,资源消耗可控。
神经网络
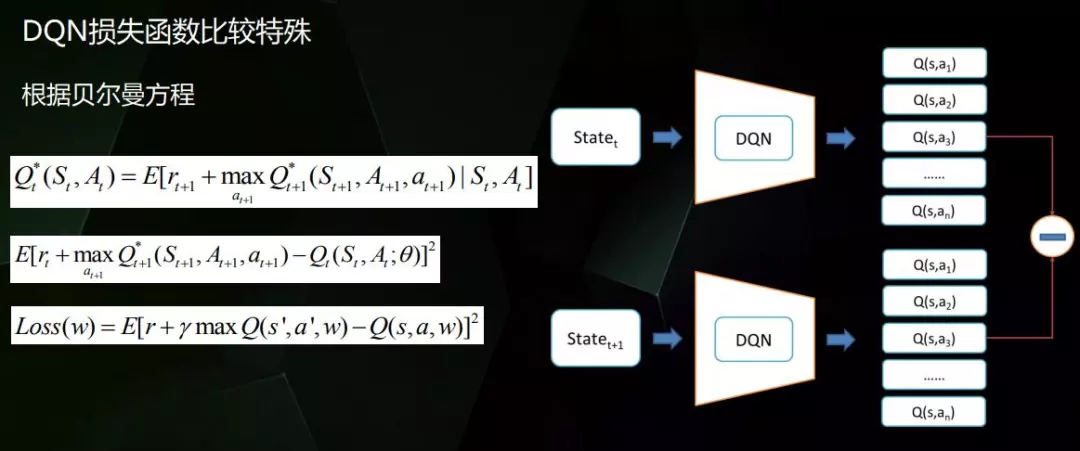
其实通过神经网络也可以解决马尔可夫决策过程中遇到的问题。神经网络的学习能力很强,在输入的X很复杂的情况下,输出的y也能很复杂,它完成了高维到高维的映射。这种方式下样本的获取成本会更低,通过机器人之间的对战能够不停的生成新的样本。
目前从训练结果来看DQN的胜率远超CNN,它的落地也意味着未来用它去做其它人工智能连续决策方面的事情有了保障。
强化学习延伸
在应用DQN的过程中我们也一直都在学习相关的新技术,下面会对这些技术做一个简要介绍。
由于值的回溯是需要时间的,这个过程中状态还是可能会被错误的低估或高估,Double DQN所要解决的就是这种情况。Dueling DQN则是分别对状态和动作进行估值。另外对于连续输出DQN是无法进行训练的,需要用到DDPG。A3C解决的是并行训练的问题,也就是并行收集样本。

- 【人工智能】AI与深度学习重点回顾,从研究到应用,这是一份2017年AI领域的最全面总结
- AI超大事件丨从研究到应用,这是一份2017年AI领域的最全面总结
- AI超大事件丨从研究到应用,这是一份2017年AI领域的最全面总结
- 除了游戏和 A 片,VR 技术的应用领域还有这些
- 基于JDBC的数据库连接池技术研究与应用
- 【AI技术生态论】甲骨文副总裁:AI 是拿来用的,不是拿来炫耀或仅在实验室中做研究的!
- 基于大数据分析的安全管理平台技术研究及应用
- 知识管理技术类型与应用领域
- IP问问:高精准(街道级别)IP地址定位技术的特点及应用领域
- 大数据库技术在與情分析领域的应用
- 基于JDBC的数据库连接池技术研究与应用
- HTML5 技术在风电、光伏等新能源领域的应用
- 抛砖引玉:我看微软.NET各子技术领域之应用前景
- 独家首发 | 加速拓展细分应用领域,珞石机器人获襄禾资本1亿元C1轮融资
- 数据库中间件技术的研究与应用
- H.264技术在视频监控领域的应用前景
- 紫外线杀菌器:TROJAN紫外线杀菌器的技术优势及应用领域
- 基于JDBC的数据库连接池技术研究与应用
- 研究 | 语音和面部识别技术能帮助AI在情商上超越人类吗
- 基于JDBC的数据库连接池技术研究与应用