实例:面对未知环境的MySQL性能问题,如何诊断
性能诊断的方法
几个定律
Little’s law是一个证明排队论的定律,我们可以将计算系统宏观的建模成排队系统,系统中有这样一个公式——请求量等于到达率乘响应时间。业界一般讨论的性能指标有KPS、吞吐量、响应时间等,其中关键的是响应时间(延时)的指标和变化以及对吞吐量的影响。
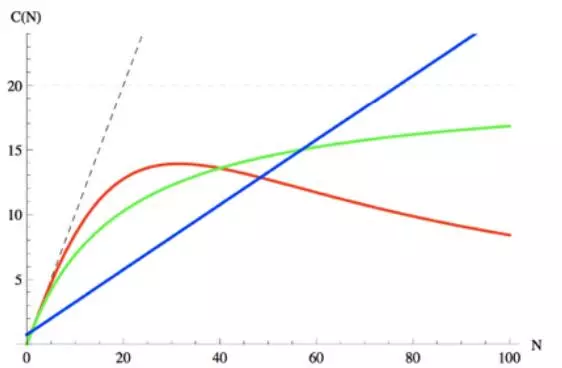
Amdahl’s Law是为了证明并行计算对性能扩展所能带来的影响。上图中的绿线就是Amdahl所计算的并发和吞吐量之间的关系,从图中可以看出整个曲线最终会趋近于一个常数,这表示后续无论系统资源和并发如何增长吞吐量都是恒定。不过真实的情况并不会这样,由此引出第三个定律——Universal Scalability Law,它指出随着资源和并发的增加性能会不升而降,图中通过红色线条表示,当到达某一时候后性能会急剧下降。因此我们在实际工作中会设法找到最优点,而不是通过不断的增加资源和并发来提升性能。
这些基础理论帮我们界定出了性能的边界,对如何提升性能有更深入的认识。
通用方法
USE方法包含三部分使用率、饱和率、错误。任何资源都可以理解为一个队列系统,这个系统中也会有使用率、饱和率,当队列饱和无法处理请求的时候会进入错误阶段,分为逻辑错误和压力过大造成的错误。
基于USE方法在进行性能分析时首先会查看系统所处阶段,比如资源没有饱和的情况下,就不用再去新增资源,而是应该找寻其他影响性能的因素;出现错误的时候,可能是因为压力过大。通过这样的方法我们在资源层面分析性能问题时就有了清晰的脉络。
火焰图方法是用来分析应用程序在CPU和非CPU两个方面的消耗时间,通过on-cpu和off-cpu的绘图方式能够直观的看出每个调用栈在不同阶段耗费的时间。
正常情况下性能无法通过单一指标来衡量,需要用到基线,也就是历史数据,这样才能判断出性能变化的好坏。
MySQL体系结构
MySQL整体上分为两大部分Connectors和Server。下方的Server端又被分为计算层和存储层,计算层负责所有连接的处理,包括SQL解析、SQL执行计算以及SQL优化等。MySQL的Server层的优点在于拥有抽象接口能够对接各种存储引擎,只要该引擎符合接口规范。
解决MySQL问题时要分析故障点具体在哪一层,针对不同层面选择不同的优化方式 。
快速诊断
当系统出现问题但还不能定位具体原因的时候,需要进行系统级的快速判断,这里列出一些常规的执行流程。
首先使用top命令判断主机负载以及cpu消耗情况。之后通过USE方法查看是否存在错误,比如oom-killer或tcp drop等。接下来是虚拟内存的情况,主要检查r、free、si、so、us、sy、id、wa、st列。然后检查进程的cpu使用率,多核利用情况;内存使用情况;网络吞吐量;tcp连接情况等。
MySQL诊断工具
对于数据库来说不仅要从系统层面找问题,还要从自身内部来分析。首先当然就是查看日志,不同的日志能够提供不同的信息,错误日志中有服务挂了或重启后的详细的信息和记录,slow日志中记录了超过一定阈值的查询和SQL请求,general日志一般不会开启,只有在故障重现的时候才会用到。
除了日志外还可以通过命令查看MySQL内部的状态信息,使用show procersslist就能看到当前MySQL的任务分布情况和线程处理状态。存储引擎的状态也要检测,通过show engine InnoDB status命令获取,主要关注点在事务状态和事务队列上。还可以使用Explain查看执行计算,对SQL进一步优化。最后是performance schema,它提供了更详细的内部状态,并且能通过SQL的方式出查询出来。
在出现实际问题后,诊断步骤大致如下。首先是结合快速诊断检查系统全局资源负载,然后检查MySQL错误日志和当前MySQL在做什么,接着查看InnoDB的事务情况,最后要检查下MySQL的复制状态。
InnoDB
InnoDB是MySQL中很重要的一个部分,开发者在使用的时候有几点需要注意。InnoDB表必须要有主键或唯一索引,组件应使用较小数据类型且有序,其次是要避免大事务(运行时间长或变更记录多)。

上图列出的是一些比较重要的参数。在并发有一定量的情况下,开发者一般都会将max_connection设置的比较大,不过这个值过大是会产生负面影响的。首先我们要理解并发和并行是完全不同的两个概念,就拿银行网点来说,并发可以理解为当前有多少顾客在存取款,并行则是有多少柜台在处理业务。由于并行量固定,所以当并发过多之后就要排队。正因为有这种情况,max_connection才不会设置的过大,通常来说不会超过1千。
Innodb_buffer_pool_size的配置同样也不是越多越好,这取决于数据量,一般建议设置在50-60之间,后续如果不够会再增加。Innodb_flush_neighbors是关于IO刷盘的参数,主要用在有机械硬盘的场景下,如果用的是SSD可以将它设置为0。Innodb_log_file_size的大小取决于当前是否在频繁刷新log日志,设置过大会影响启动效率,因此建议设为1-2G。
数据库的优化最重要的还是在于SQL优化,实现更好的物理设计包括表设计、索引设计、数据分布等等。
Note
优化的核心实际上是如何“少做事”,做的越多越复杂就意味着效率的降低,在优化之前要设法简化流程。另外切勿盲目追求最优配置模板,存在这样一个原则——在不知道参数含义的情况下不要随意改动它,只有在明确知道该参数能够解决问题的时候才去调整。还有就是避免过早优化,在遇到问题的时候在做优化。
观测工具用法
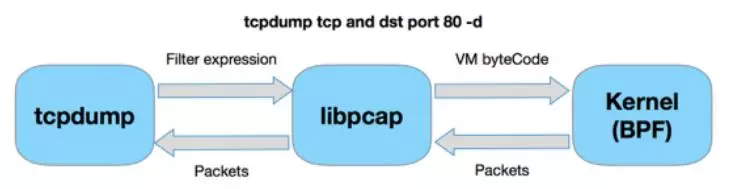
BPF是一个包过滤系统,用来解决抓包的性能问题,在tcp上的网络调试方面用的较多。Tcpdump和linux底层对接的就是BPF,在内核中BPF有一个虚拟机,能够接收一定的指令,这些指令可以提高抓包的性能。在3.18版本的时候,linux对BPF进行了扩展,从原来的抓包场景扩展到了更广的范围。
目前BPF的应用还不算太多,主要是因为它对内核的版本要求较高,liunx内核要在4.4以上。一般我们也不会直接使用BPF,而是使用社区中的Bcc(BPF工具集),它结合BPF的能力做了很多命令行式的工具,更方便使用。如果要用在Mysql上还需要进行编译。

Bcc提供的工具基本上能够覆盖系统的各个层面,具体介绍可以在项目的Github上查看。

- 如何诊断数据库突然出现性能问题?
- 如何使用AWR报告来诊断数据库性能问题
- 如何收集用来诊断性能问题的10046 Trace
- 如何解决 JMeter 通过 JDBC 访问 Oracle 和 MySQL 的问题 (留言中有 Test Plan 实例下载)
- 如何诊断RAC环境中节点重启问题(适用于11gR2)
- 如何解决 JMeter 通过 JDBC 访问 Oracle 和 MySQL 的问题 (留言中有 Test Plan 实例下载)
- 如何解决 JMeter 通过 JDBC 访问 Oracle 和 MySQL 的问题 (留言中有 Test Plan 实例下载)
- 如何诊断rac环境下sysdate 返回错误时间问题
- 真是环境下阿里云RDS实例mysql性能优化-慢查询分析、优化索引和配置
- 生产环境服务器变慢如何诊断,性能评估
- 如何诊断Oracle Redo Log引发的性能问题
- RAC 环境中最常见的 5 个数据库和/或实例性能问题 (文档 ID 1602076.1)
- 转 --如何收集用来诊断性能问题的10046 Trace
- RAC 环境中 gc block lost 和私网通信性能问题的诊断
- 如何诊断rac环境下sysdate 返回错误时间问题
- 如何解决 JMeter 通过 JDBC 访问 Oracle 和 MySQL 的问题 (留言中有 Test Plan 实例下载)
- 如何收集用来诊断性能问题的10046 Trace
- jprofiler如何诊断代码性能问题--MIS系统
- 如何收集用来诊断性能问题的10046 Trace(SQL_TRACE) (文档 ID 1523462.1)
- RAC 环境中 gc block lost 和私网通信性能问题的诊断 (文档 ID 1674865.1)