似懂非懂Google TPU

谷歌的这款芯片被称作 Tensor Processing Unit,简称 TPU,是Google专门为深度学习定制的芯片。
第一次出现是在2016年的Google I/O大会上,最近在体系结构顶级会议 ISCA 2017 上面,描述 TPU 的论文被评为最佳论文,让TPU又火了一把。
大家可以去搜索下论文:
In-Datacenter Performance Analysis of a Tensor Processing Unit™
一、我看了下,似懂非懂,论文要点总结如下:
• TPU不适合训练,适合做推断,TPU是一种ASIC,先用GPU训练神经网络,再用TPU做推断。
• TPU没有与CPU密切整合,而是设计成了一个PCIe I/O总线上的协处理器,可以像GPU一样插到现有的服务器上。
• 在推断任务中,TPU平均比英伟达的Tesla K80 GPU或英特尔至强E5-2699 v3 CPU速度快15至30倍左右。
• 一个TPU的MAC是Tesla K80的25倍,片上内存容量达到K80的3.5倍,而且体积更小。
• TPU的功耗效率(performance/Watt, 每耗电1瓦的性能)比GPU和CPU高出30至80倍。
• 如果对TPU进行优化,给它和K80一样大的内存,他的速度能比GPU和CPU高30-50倍,公好效率高70-200倍。
• 以上数据,都是Google基于自己公司的标准测试得出的。
• 一作Jouppi说,Google曾经考虑过像微软一样用FPGA,因为开发起来更快更灵活,但是测试后发现速度提升不够。
总结起来,就是为深度学习定制的ASCI芯片,要比FPGA/CPU/GPU做推断的时候都要快,能耗低。
二、快的原因是啥呢,关键是采用脉动阵列机架构:
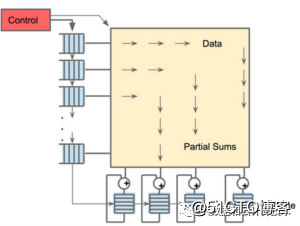
The Next Platform 评论称,TPU 并不复杂,看上去更像是雷达应用的信号处理引擎,而不是标准的 X86 衍生架构。Jouppi说,虽然 TPU 有很多矩阵乘法单元,但 TPU 比“GPU 在思路上更接近浮点单元协处理器”,TPU 没有任何存储程序,仅执行从主机发送的指令。
由于要获取大量的权重并将这些权重送到矩阵乘法单元,TPU 上的 DRAM 是作为一个独立的单元并行运行。同时,矩阵乘法单元通过减少统一缓冲区的读写降低能耗,也就是进行所谓的“脉动运行”(systolic execution)。
TPU 有两个内存,还有一个用于存储模型中参数的外部 DRAM。参数进来以后,从矩阵乘法单元的上层开始加载。同时,可以从左边加载激活,也就是“神经元”的输出。这些都以“systolic”脉动的方式进入矩阵单元,然后进行矩阵相乘,每个周期可以做 64,000 次累积。
三、再来看看什么是脉动阵列计算机:
脉动阵列计算机(systolic array computers),一种阵列结构的计算机。脉动意即其工作方式和过程犹如人体血液循环系统的工作方式和过程。
在这种阵列结构中,数据按预先确定的“流水”方式在阵列的处理单元间有节奏地“流动”。在数据流动的过程中,所有的处理单元同时并行地对流经它的数据进行处理,因而它可以达到很高的并行处理速度。同时,预先确定的数据流动模式使数据从流进处理单元阵列到流出处理单元阵列的过程中完成所有对它应做的处理,无需再重新输入这些数据 ,且只有阵列的“边界”处理单元与外界进行通信 ,由此实现在不增加阵列机输入、输出速率的条件下,提高阵列机的处理速度。由于阵列和处理单元的结构简单、规则一致 ,可达到很高的模块化程度,非常适合超大规模集成电路的设计和制造。计算任务一般分为以计算为主和以输入、输出为主两类。前者指任务的计算操作次数大于该任务的输入、输出次数;后者指任务的计算操作次数小于该任务的输入、输出次数。由于脉动阵列结构与它所处理的算法密切相关,所以说,脉动阵列结构是一种适于专用的,以计算为主应用的结构。
四、总结起来,Google的思路很有意思,相当于给深度学习的推断定制计算,取得很好的效果,不过同时也意味着通用性会相对差一些。

- 终于能用Google的TPU跑代码了,每小时6.5美元
- 基于论文分析Google的张量处理器TPU
- 终于能用Google的TPU跑代码了,每小时6.5美元
- Google深度揭秘TPU:一文看懂内部原理,以及为何碾压GPU
- Google TPU3 看点
- Google TPU 揭密——看TPU的架构框图,矩阵加乘、Pool等处理模块,CISC指令集,必然需要编译器
- 基于Google Edge TPU的Coral USB加速棒体验
- 详解Google第二代TPU 既能推理又能训练 性能霸道
- 寒武纪创始人陈天石:如何评价Google最新AI计算高性能专用硬件TPU
- Google再度发力本地化AI,新年伊始推迷你Edge TPU开发板!
- 深入浅出Google-ProtoBuf中的编码规则
- Google推荐的图片加载库Glide介绍
- 破而后立 -- 看Google如何超越网页性能优化
- 全新整理:微软、Google等公司的面试题及解答、第161-170题
- 【OpenSource】【Glide】Google 推荐的图片加载开源框架 Glide
- Google发布2019年6月Android安全补丁,包含22个安全修复
- Google 发现的十大真理
- 利用Google高级搜索功能做SEO调研
- OpenStreetMap/Google/百度/Bing瓦片地图服务(TMS)
- 今日开源介绍:Google Guava、Google Guice、Joda-Time