阅读源码,HashMap回顾
本文一是总结前面两种集合,补充一些遗漏,再对HashMap进行简单介绍。
回顾
因为前两篇ArrayList和LinkedList都是针对单独的集合类分析的,只见树木未见森林,今天分析HashMap,可以结合起来看一下java中的集合框架。下图只是一小部分,而且为了方便理解去除了抽象类。
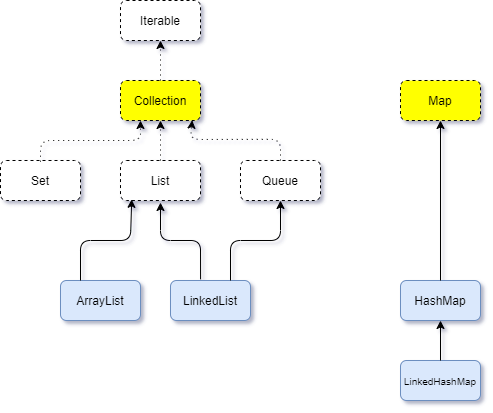
Java中的集合(有时也称为容器)是为了存储对象,而且多数时候存储的不止一个对象。
可以简单的将Java集合分为两类:
-
一类是Collection,存储的是独立的元素,也就是单个对象。细分之下,常见的有List,Set,Queue。其中List保证按照插入的顺序存储元素。Set不能有 ad8 重复元素。Queue按照队列的规则来存取元素,一般情况下是“先进先出”。
-
一类是Map,存储的是“键值对”,通过键来查找值。比如现实中通过姓名查找电话号码,通过身份证号查找个人详细信息等。
理论上说我们完全可以只用Collection体系,比如将键值对封装成对象存入Collection的实现类,之所以提出Map,最主要的原因是效率。
HashMap简介
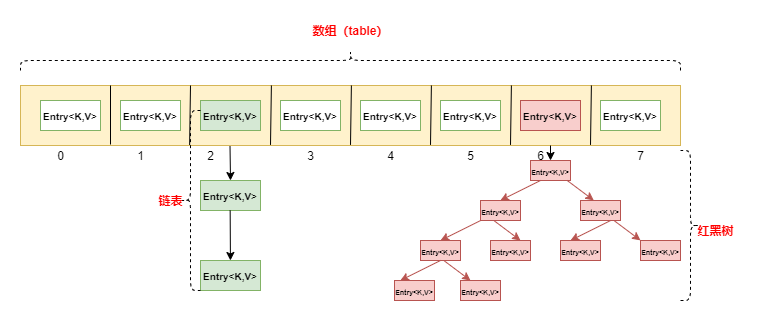
HashMap用来存储键值对,也就是一次存储两个元素。在jdk1.8中,其实现是基于数组+链表+红黑树,简单说就是普通情况直接用数组,发生哈希冲突时在冲突位置改为链表,当链表超过一定长度时,改为红黑树。
可以简单理解为:在数组中存放链表或者红黑树。
- 完全没有哈希冲突时,数组每个元素是一个容量为1的链表。如索引0和1上的元素。
- 发生较小哈希冲突时,数组每个元素是一个包含多个元素的链表。如索引2上的元素。
- 当冲突数量超过8时,数组每个元素是一棵红黑树。如索引6上的元素。
下图为示意图,相关结构没有严格遵循规范。
类签名
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
如下图
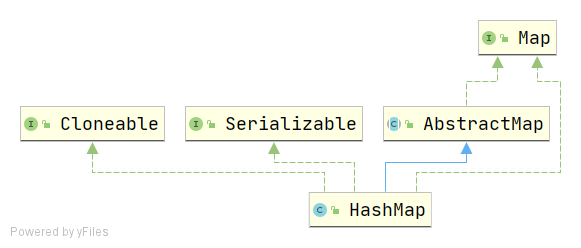
实现Cloneable和Serializable接口,拥有克隆和序列化的能力。
HashMap继承抽象类AbstractMap的同时又实现Map接口的原因同样见上一篇LinkedList。
常量
//序列化版本号 private static final long serialVersionUID = 362498820763181265L; //默认初始化容量为16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //最大容量,2的30次方 static final int MAXIMUM_CAPACITY = 1 << 30; //默认负载因子,值为0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f; //以下三个常量应结合看 //链表转为树的阈值 static final int TREEIFY_THRESHOLD = 8; //树转为链表的阈值,小于6时树转链表 static final int UNTREEIFY_THRESHOLD = 6; //链表转树时的集合最小容量。只有总容量大于64,且发生冲突的链表大于8才转换为树。 static final int MIN_TREEIFY_C 2e36 APACITY = 64;
上述变量的关键在于链表转树和树转链表的时机,综合看:
- 当数组的容量小于64是,此时不管冲突数量多少,都不树化,而是选择扩容。
- 当数组的容量大于等于64时, 冲突数量大于8,则进行树化。
- 当红黑树中元素数量小于6时,将树转为链表。
变量
//存储节点的数组,始终为2的幂 transient Node<K,V>[] table; //批量存入时使用,详见对应构造函数 transient Set<Map.Entry<K,V>> entrySet; //实际存放键值对的个数 transient int size; //修改map的次数,便于快速失败 transient int modCount; //扩容时的临界值,本质是capacity * load factor int threshold; //负载因子 final float loadFactor;
数组中存储的节点类型,可以看出,除了K和Value外,还包含了指向下一个节点的引用,正如一开始说的,节点实际是一个单向链表。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//...省略常见方法
}
构造方法
常见的无参构造和一个参数的构造很简单,直接传值,此处省略。看一下两个参数的构造方法。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: "+initialCapacity);
//指定容量不能超过最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//将给定容量转换为不小于其自身的2的幂
this.threshold = tableSizeFor(initialCapacity);
}
tableSizeFor方法
上述方法中有一个非常巧妙的方法tableSizeFor,它将给定的数值转换为不小于自身的最小的2的整数幂。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
比如cap=10,转换为16;cap=32,则结果还是32。用了位运算,保证效率。
有一个问题,为啥非要把容量转换为2的幂?之前讲到的ArrayList为啥就不需要呢?其实关键在于hash,更准确的说是转换为2的幂,一定程度上减小了哈希冲突。
关于这些运算,画个草图很好理解,关键在于能够想到这个方法很牛啊。解释的话配图太多,这里篇幅限制,将内容放在另一篇文章。
添加元素
在上面构造方法中,我们没有看到初始化数组也就是
Node<K,V>[] table的情况,这一步骤放在了添加元素put时进行。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
可以看出put调用的是putVal方法。
putVal方法
在此之前回顾一下HashMap的构成,数组+链表+红黑树。数组对应位置为空,存入数组,不为空,存入链表,链表超载,转换为红黑树。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//数组为空,则扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据key计算hash值得出数组中的位置i,位置i上为空,直接添加。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//数组对应位置不为空
else {
Node<K,V> e;
K k;
//对应节点key上的key存在,直接覆盖value
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//为红黑树时
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//为链表时
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//下次添加前需不需要扩容,若容量已满则提前扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
resize()方法比较复杂,最好是配合IDE工具,debug一下,比较容易弄清楚扩容的方式和时机,如果干讲的话反而容易混淆。
获取元素
根据键获取对应的值,内部调用getNode方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
getNode方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;
Node<K,V> first,
e; int n;
K k;
//数组不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//第一个节点满足则直接返回对应值
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//红黑树中查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//链表中查找
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
总结
HashMap的内容太多,每个内容相关的知识点也很多,篇幅和个人能力限制,很难讲清所有内容,比如最基础的获取hash值的方法,其实也很讲究的。有机会再针对具体的细节慢慢详细写吧。

- HashMap源码阅读
- JDK1.8 -- HashMap源码阅读
- JDK源码阅读——HashMap(1.7)
- JDK 1.8 HashMap 源码阅读一
- HashMap源码阅读
- Java Jdk1.8 HashMap源码阅读笔记一
- JAVA 集合类(java.util)源码阅读笔记------HashMap
- HashMap 源码阅读
- 源码阅读技巧篇:RocketMQ DLedger 多副本即主从切换专栏回顾
- HashMap源码阅读(1)- 初始值、数据结构、hash计算、2的n次幂
- HashMap源码阅读(2)- 碰撞(冲突)与扩容
- JDK源码阅读之HashMap的实现
- HashMap源码阅读与解析
- HashMap 1.7源码阅读
- HashMap源码阅读
- HashMap源码阅读(1)-构造函数
- HashMap源码阅读
- hashmap源码阅读
- jdk源码阅读笔记-HashMap
- javase基础回顾(二)LinkedList需要注意的知识点 阅读源码收获