表数据量大读写缓慢如何优化(2)【查询分离】
上一篇聊到过,冷热分离解决方案的性价比高,但它并不是一个最优的方案,仍然存在诸多不足,比如:查询冷数据慢、业务无法再修改冷数据、冷数据多到一定程度系统依旧扛不住,我们如果想把这些问题一一解决掉,可以用另外一种解决方案——查询分离。(注意:查询分离与读写分离还是有区别的。)
业务场景二
某 SaaS 客服系统,系统里有一个工单查询功能,工单表中存放了几千万条数据,且查询工单表数据时需要关联十几个子表,每个子表的数据也是超亿条。
面对如此庞大的数据量,跟前面的冷热分离一样,每次客户查询数据时几十秒才能返回结果,即便我们使用了索引、SQL 等数据库优化技巧,效果依然不明显。
加上工单表中有些数据是几年前的,但是这些数据涉及诉讼问题,需要继续保持更新,因此无法将这些旧数据封存到别的地方,也就没法通过前面的冷热分离方案来解决。
最终采用了查询分离的解决方案,才得以将这个问题顺利解决:将更新的数据放在一个数据库里,而查询的数据放在另外一个系统里。因为数据的更新都是单表更新,不需要关联也没有外键,所以更新速度立马得到提升,数据的查询则通过一个专门处理大数据量的查询引擎来解决,也快速地满足了实际的查询需求。
通过这种解决方案处理后,每次查询数据时,500ms 内就可得到返回结果,客户再也不抱怨了。
通过上面这个例子,大家对查询分离的业务场景已经有了一定认知,但如果想掌握整个业务场景,继续往下看吧。
什么是查询分离?
关于查询分离的概念,从简单的字面意思上也好理解,即每次写数据时保存一份数据到另外的存储系统里,用户查询数据时直接从另外的存储系统里获取数据。示意图如下:
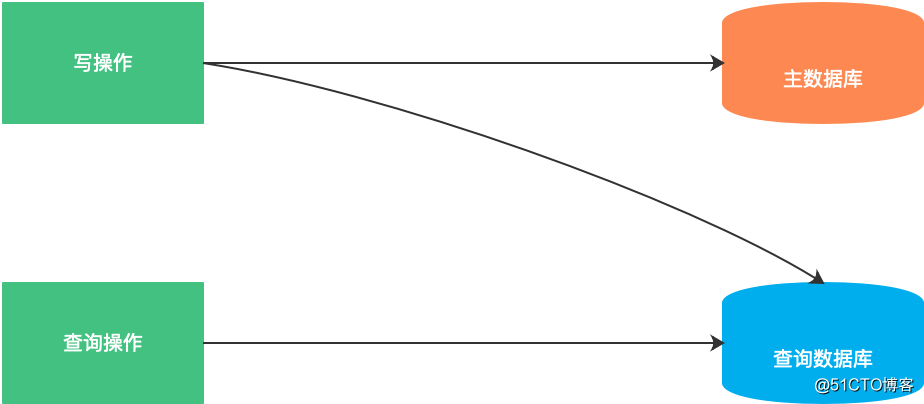
何种场景下使用查询分离?
当在实际业务中遇到以下情形,则可以考虑使用查询分离解决方案。
- 数据量大;
- 所有写数据的请求效率尚可;
- 查询数据的请求效率很低;
- 所有的数据任何时候都可能被修改;
- 业务希望优化查询数据的效率;
大家对查询分离这个概念特别熟悉,但是对于查询分离的使用场景一无所知,这可不行,只有了解了查询分离的真正使用场景,才能在遇到实际问题时采取最正确的解决方案。
查询分离实现思路
在实际工作中,如果业务要求必须使用查询分离的解决方案,我们就务必掌握查询分离的实现思路。也只有这样,我们真正遇到问题时才能有条不紊地开展工作。
查询分离解决方案的实现思路如下:
- 如何触发查询分离?
- 如何实现查询分离?
- 查询数据如何存储?
- 查询数据如何使用?
针对以上问题,我们一点一点来讨论。
(一)如何触发查询分离?
这个问题说明的是我们应该在什么时候保存一份数据到查询数据中,即什么时候触发查询分离这个动作。
一般来说,查询分离的触发逻辑分为3种。
(1)修改业务代码:在写入常规数据后,同步建立查询数据。
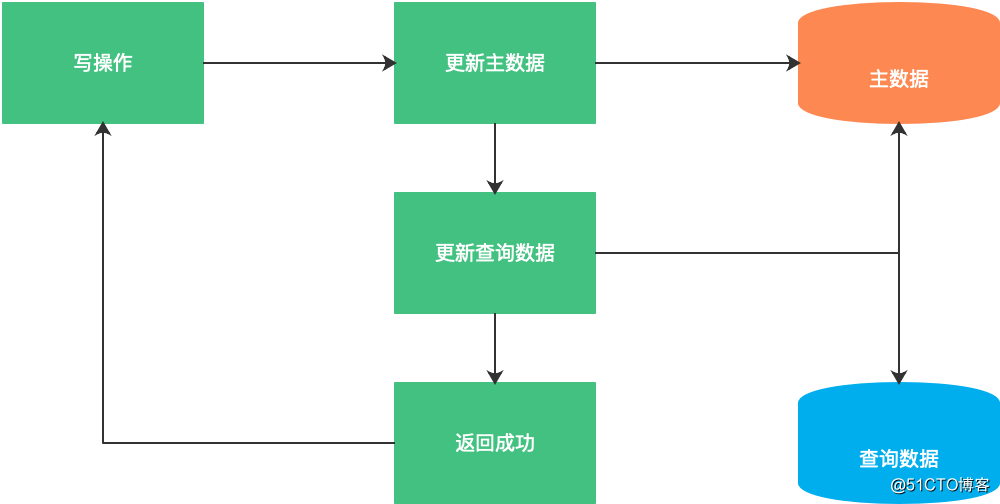
(2)修改业务代码:在写入常规数据后,异步建立查询数据。
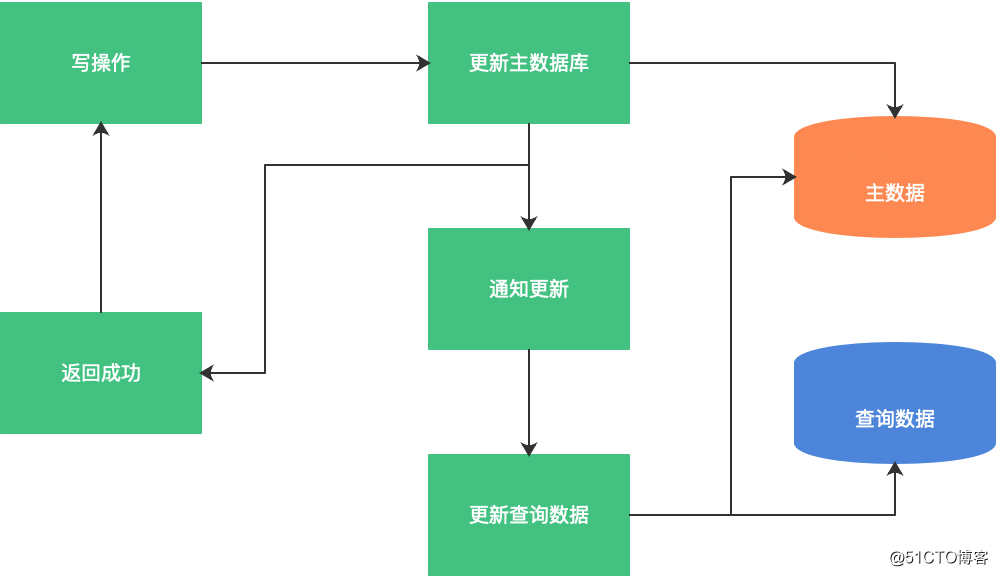
(3)监控数据库日志:如有数据变更,更新查询数据。
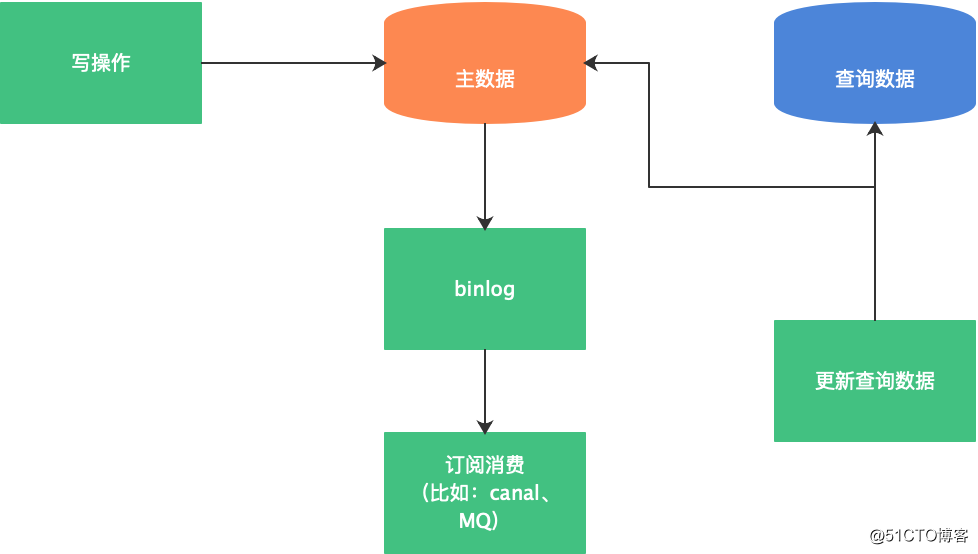
通过观察以上3种触发逻辑示意图,发现了什么吗?3种触发逻辑的优缺点对比表如下:
| 修改业务代码同步建立查询数据 | 修改业务代码异步建立查询数据 | 监控数据库日志 | |
|---|---|---|---|
| 优点 | 1、保证查询数据的实时性和一致性。2、业务逻辑灵活可控 | 1、不影响主流程 | 1、不影响主流程。2、业务代码0侵入 |
| 缺点 | 1、侵入业务代码。2、减缓写操作速度。 | 1、查询数据更新前,用户可能会查询到过时的数据。 | 1、查询数据更新前,用户可能会查询到过时的数据。2、架构复杂一些 |
为方便理解表中的内容,我们来一起聊一下其中的几个概念。
什么叫业务灵活逻辑可控?举个例子:一般来说,写业务代码的人能从业务逻辑中快速判断出何种情况下更新查询数据,而监控数据库日志的人并不能将全部的数据库变更分支穷举,再把所有的可能性关联到对应的更新查询数据逻辑中,最终导致任何数据的变更都需要重新建立查询数据。
什么叫减缓写操作速度?建立查询数据的一个动作能减缓多少写操作速度?答案:很多。举个例子:当你只是简单更新了订单的一个标识,本来查询数据时间只需要 2ms,而在查询数据时可能会涉及重建(比如使用 ES 查询数据时会涉及索引、分片、主从备份,其中每个动作又细分为很多子动作,这些内容后面文章会聊到),这时建立查询数据的过程可能就需要 1s 了,从 2ms 变成 1s,你说减缓幅度大不大?
查询数据更新前,用户可能查询到过时数据。 这里我们结合第 2 种触发逻辑来讲,比如某个操作正处于订单更新状态,状态更新时会通过异步更新查询数据,更新完后订单才从“待审核”状态变为“已审核”状态。假设查询数据的更新时间需要 1 秒,这 1 秒中如果用户正在查询订单状态,这时主数据虽然已变为“已审核”状态,但最终查询的结果还是显示“待审核”状态。
根据前面的对比表,总结每种触发逻辑的适用场景如下:
| 触发逻辑 | 适用场景 |
|---|---|
| 修改业务代码,同步建立查询数据 | 业务代码比较简单且对写操作响应速度要求不高 |
| 修改业务代码,异步建立查询数据 | 业务代码比较简单且对写操作响应 |
| 监控数据库日志 | 业务代码比较复杂,或者改动代价太大 |
这里,结合实战案例说明下:在一个真实业务场景中,虽然我们对业务的代码比较熟悉,但是业务要求每次修改工单请求时响应速度快,我们最终就选择了修改业务代码异步建立查询数据这种触发逻辑。
(二)如何实现查询分离?
以上共谈到 3 种触发逻辑,第 1 种是同步建立查询数据的过程比较简单,这里就不展开说明,第 3 种监控数据库日志我会在 13 讲具体讲解,所以这部分内容我们主要围绕第 2 种讨论。
关于第 2 种触发方案:修改业务代码异步建立查询数据,最基本的实现方式是单独起一个线程建立查询数据,不过这种做法会出现如下情况:
- 写操作较多且线程太多,最终撑爆JVM。
- 建查询数据的线程出错了,如何自动重试。
- 多线程并发时,很多并发场景需要解决。
面对以上三种情况,我们该如何处理?此时使用MQ管理这些这些线程即可解决。
MQ的具体操作思路为每次主数据写操作请求处理时,都会发一个通知给MQ,MQ收到通知后唤醒一个线程更新查询数据,示意图如下:
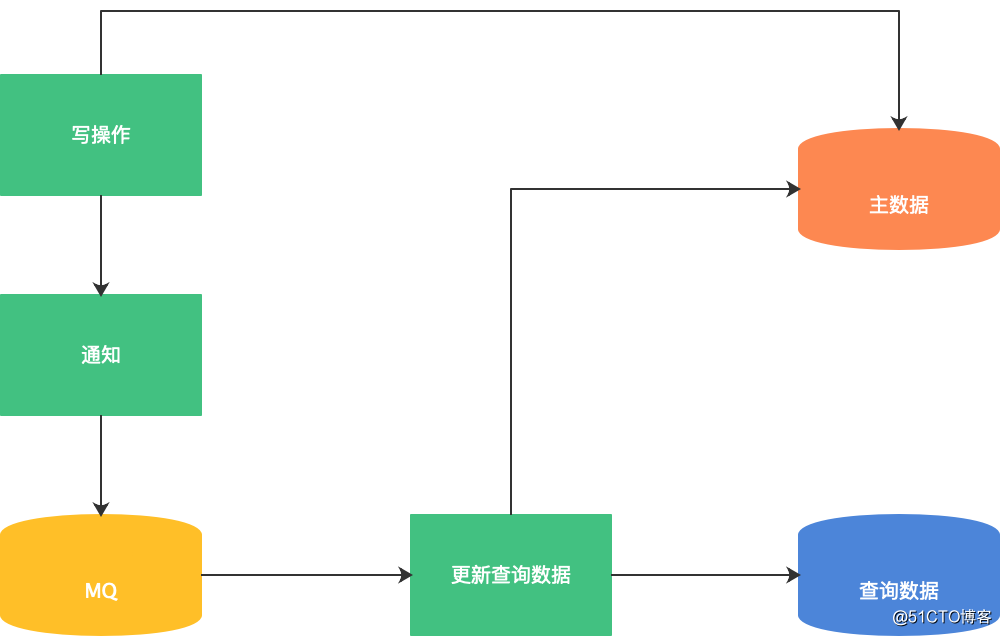
了解了MQ的具体操作思路后,我们还应该考虑以下5大问题。
问题一:MQ如何选型?
如果公司已使用 MQ,那选型问题也就不存在了,毕竟技术部门不会同时维护 2 套 MQ 中间件,而如果公司还没使用 MQ,这就需要考虑选型问题了。
这里我分享两点选型原则,希望对你有帮助。
(1)召集技术中心所有能做技术决策的人共同投票选型。
(2)不管我们选择哪个 MQ ,最终都能实现想要的功能,只不过是易用不易用、多写少写业务代码的问题,因此我们从易用性和代码工作量角度考量即可。
问题二:MQ宕机了怎么办?
如果 MQ 宕机了,我们只需要保证主流程正常进行,且 MQ 恢复后数据正常处理即可,具体方案分为三大步骤。
-
每次写操作时,在主数据中加个标识:NeedUpdateQueryData=true,这样发到 MQ 的消息就很简单,只是一个简单的信号告知更新数据,并不包含更新的数据 id。
-
MQ 的消费者获取信号后,先批量查询待更新的主数据,然后批量更新查询数据,更新完后查询数据的主数据标识 NeedUpdateQueryData 就更新成 false 了。
- 当然还存在多个消费者同时搬运动作的情况,这就涉及并发性的问题,因此问题与上一篇聊的冷热分离中的并发性处理逻辑类似,这里就不细聊了(有兴趣的同学可以去看看)。
问题三:更新查询数据的线程失败了怎么办?
如果更新的线程失败了,NeedUpdateQueryData 的标识就不会更新,后面的消费者会再次将有 NeedUpdateQueryData 标识的数据拿出来处理。但如果一直失败,我们可以在主数据中多添加一个尝试搬运次数,比如每次尝试搬运时 +1,成功后就清零,以此监控那些尝试搬运次数过多的数据。
问题四:消息的幂等消费
在编程中,一个幂等操作的特点是多次执行某个操作均与执行一次操作的影响相同。
举个例子,比如主数据的订单 A 更新后,我们在查询数据中插入了 A,可是此时系统出问题了,系统误以为查询数据没更新,又把订单 A 插入更新了一次。
所谓幂等,就是不管更新查询数据的逻辑执行几次,结果都是我们想要的结果。因此,考虑消费端并发性的问题时,我们需要保证更新查询数据幂等。
问题五:消息的时序性问题
比如某个订单 A 更新了 1 次数据变成 A1,线程甲将 A1 的数据搬到查询数据中。不一会儿,后台订单 A 又更新了 1 次数据变成 A2,线程乙也启动工作,将 A2 的数据搬到查询数据中。
所谓的时序性就是如果线程甲启动比乙早,但搬运数据动作比线程乙还晚完成,就有可能出现查询数据最终变成过期的 A1。如下图(动作前面的序号代表实际动作的先后顺序):
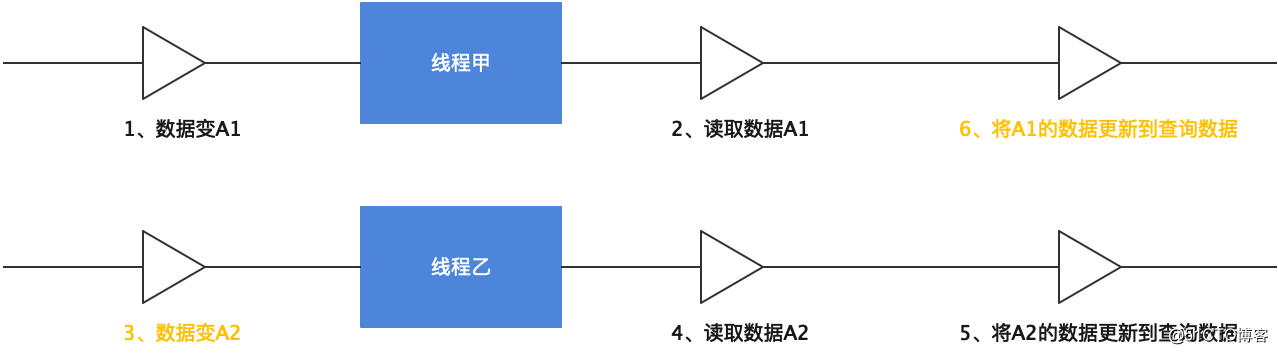
此时解决方案为主数据每次更新时,都更新上次更新时间 last_update_time,然后每个线程更新查询数据后,检查当前订单 A 的 last_update_time 是否跟线程刚开始获得的时间一样,且 NeedUpdateQueryData 是否等于 false,如果都满足的话,我们就将 NeedUpdateQueryData 改为 true,然后再做一次搬运。
看到这,你心中可能有个疑问:MQ 在这里的作用只是一个触发信号的工具,如果不用 MQ 好像也没啥问题啊,这你就大错特错了,MQ 的作用还不少呢,不信你往下看。
- 服务的解耦:这样主业务逻辑就不会依赖更新查询数据这个服务了。
- 控制更新查询数据服务的并发量:如果我们直接调用更新查询数据服务,因写操作速度快,更新查询数据速度慢,写操作一旦并发量高,会给更新查询数据服务造成超负荷压力。如果通过消息触发更新查询数据服务,我们就可以通过控制消息消费者的线程数来控制负载。
(三)查询数据如何存储?
我们应该使用什么技术存储查询数据呢?目前,市面上主要使用 Elasticsearch 实现大数据量的搜索查询,当然还可能会使用到MongoDB、HBase 这些技术,这就需要我们对各种技术的特性了如指掌,再进行技术选型。
关于技术选型这个问题,我觉得很多时候我们不能单单只考虑业务功能的需求,还需要考虑组织结构。团队最熟悉哪款中间件,花费的成本最小,优先考虑的就应该是这种。
(四)查询数据如何使用?
因 ES 自带 API,所以使用查询数据时,我们在查询业务代码中直接调用 ES 的 API 就行。
不过,这个办法会出现一个问题:数据查询更新完前,查询数据不一致怎么办?这里分享 2 种解决思路。
- 在查询数据更新到最新前,不允许用户查询。(我们没用过这种设计,但我确实见过市面上有这样的设计。
- 给用户提示:您目前查询到的数据可能是 1 秒前的数据,如果发现数据不准确,可以尝试刷新一下,这种提示用户一般比较容易接受。
整体方案
以上,我们已经把四个问题都讨论完了,我们再一起看看查询分离的整体方案,如下图所示:
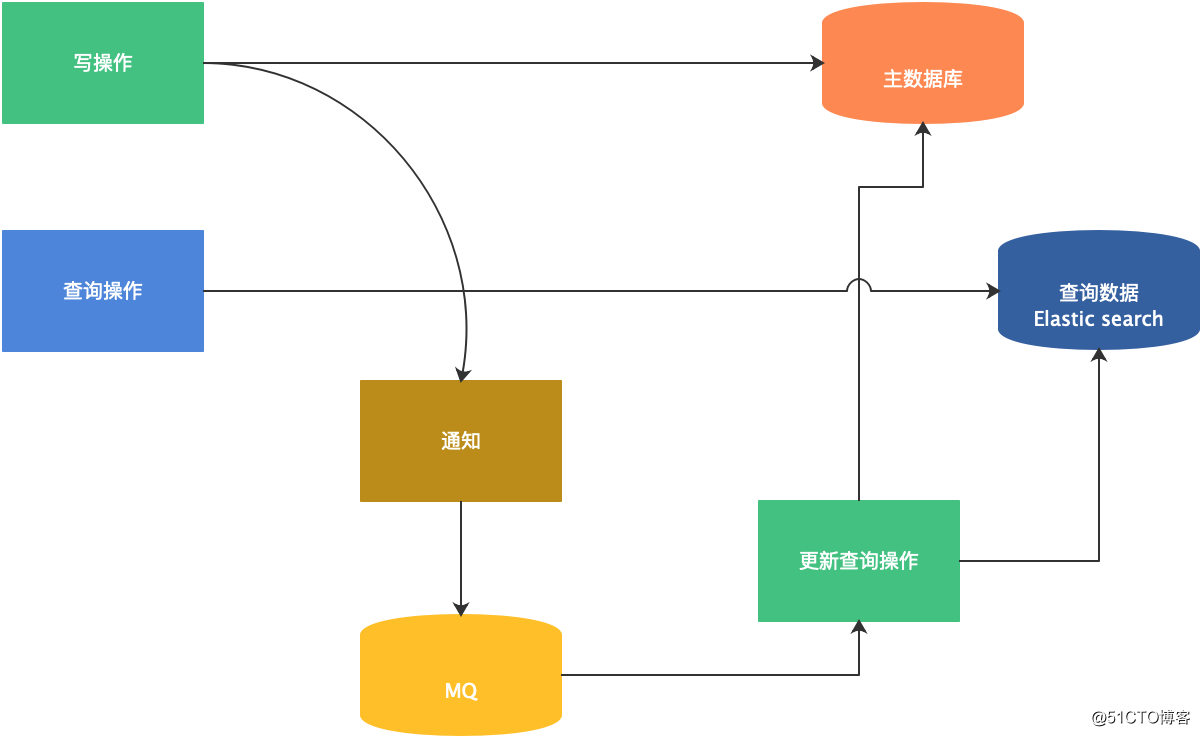
总结一下,本篇关于查询分离的架构主要分为四个部分:如何触发查询分离?如何实现查询分离?查询数据如何存储?查询数据如何使用?
历史数据迁移
新的架构方案上线后,旧的数据如何适用新的架构方案?这是实际业务中需要我们考虑的问题。
在这个方案里,我们只需要把所有的历史数据加上这个标识:NeedUpdateQueryData=true,程序就会自动处理了。
查询分离解决方案的不足
查询分离这个解决方案虽然能解决一些问题,但我们也要清醒地认识到它的不足。
不足一: 使用 Elasticsearch 存储查询数据时,注意事项是什么(此方案并未详细展开)?
不足二: 主数据量越来越大后,写操作还是慢,到时还是会出问题。
不足三: 主数据和查询数据不一致时,假设业务逻辑需要查询数据保持一致性呢?
接下来的文章将会来聊使用elastic search做查询数据的存储系统时需要注意哪些问题,这个问题不管是面试还是实际工作中,我们都会碰到。一个技术使用起来并不难,难的是使用这个技术时你会碰到什么问题,你又是如何解决的?

- SqlServer优化:当数据量查询不是特别多,但数据库服务器的CPU资源一直100%时,如何优化?
- 如何优化数据上千百万的数据表查询
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!(zz)
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!
- 有一张表里面有上百万的数据,在做查询的时候,如何优化?从数据库端,java端和查询语句上回答
- MySQL 百万级数据量分页查询如何优化?
- 如何优化数据库中数据的查询
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!(zz)
- 在ES数十亿数据量级的场景下,如何优化查询性能?
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!(zz)
- 如何优化Mysql执行查询数据的速度
- 如何优化数据库中数据的查询
- oracle高级查询之数据优化(1)------如何创建效率高sql-建立索引
- 如何优化SQL查询当前数据上一条和下一条的记录?
- 如何优化Mysql执行查询数据的速度
- SQL 大数据查询如何进行优化?sqlserver和oracle整理
- SQL 大数据查询如何进行优化?
- SQL 大数据查询如何进行优化?
- 如何解决百万级数据查询优化
- 如何查询优化100万条数据的一张表?