Fluentd 的日志收集配置
前言
先简单说明一下,当前生产中我们所有的服务都运行在 docker 里面,到目前为止还没有使用 k8s 来管理 docker,日常的更新部署等主要还是使用 ansible + jenkins 结合来进行的,例如 docker 中服务的日志则是通过挂载到宿主机的目录当中,然后通过运行 fluentd 的 docker 也是通过挂载的方式读取宿主机所在的日志目录来进行收集。以下的配置说明示例使用的 fluentd 的 1.9.1 版本。
环境
fluentd 典型的部署架构需要包含两种不同角色:转发器(forwarder),聚合器(aggregator)
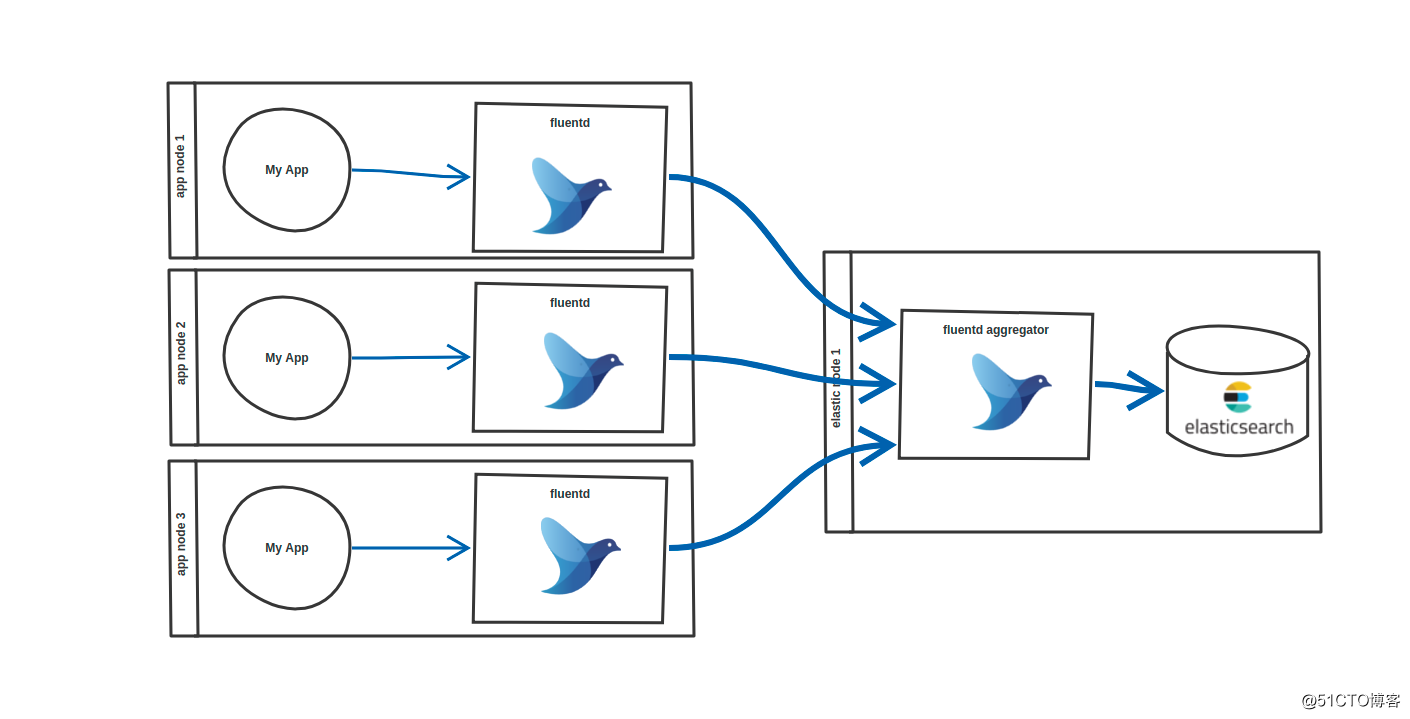
当前环境中:
转发器的 fluentd 是运行在每个主机的 docker,将每个主机上其他 docker 服务的日志收集起来然后转发到聚合器的 fluentd。
聚合器的 fluentd 是独立主机上运行的两个 docker,是将 docker 内部 24224 端口分别映射到主机的 24227 端口和 24228 端口。它将各个主机上转发过来的日志匹配过滤然后存储到 elasticsearch 中。
fluentd 在线测试工具:https://fluentular.herokuapp.com
定义 flunetd 镜像
fluentd 这里都是使用的官方的 docker 镜像然后安装的插件。默认的 fluentd 镜像没有我需要的 fluent-plugin-elasticsearch 插件和 fluent-plugin-forest 插件,所以需要在 fluentd 的镜像的基础上通过 Dockerfile 中执行如下命令安装插件:
fluent-gem install fluent-plugin-elasticsearch && fluent-gem install fluent-plugin-forest
重新构建的 fluentd 镜像上传到自己的 harbor 仓库中,然后通过 ansible 部署启动 fluentd 的 docker 到各个主机上。
转发器配置示例
<source> @type tail path /home/game/http_8001/logs/access.log,/home/game/http_8002/logs/access.log pos_file /home/game/access.log.pos tag game.http.host01 #read_from_head true format /^(?<log>.*)/ </source> <match game.**> @type forward <buffer> @type file path /home/game/td-gamex-buffer chunk_limit_size 128MB total_limit_size 8GB chunk_full_threshold 0.9 compress text flush_mode default flush_interval 15s flush_thread_count 1 delayed_commit_timeout 60 overflow_action throw_exception retry_timeout 10m </buffer> send_timeout 60s recover_wait 10s heartbeat_interval 1s transport tcp <server> name aggregator01 host 10.144.77.88 port 24227 weight 60 </server> <server> name aggregator02 host 10.144.77.88 port 24228 weight 60 </server>
聚合器配置示例
<source>
@type forward
port 24224
</source>
<filter game.http.**>
@type record_transformer
enable_ruby
<record>
service ${tag_parts[1]}
host ${tag_parts[2]}
</record>
</filter>
<filter game.http.**>
@type parser
reserve_data yes
key_name log
<parse>
@type regexp
expression /^(?<remote>[^ ]*) - (?<server_id>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<body_bytes_sent>[^ ]*) "(?<referer>[^\"]*)" "(?<agent>[^\"]*)" (?<response-time>[^ ]*) (?<uid>[^ ]*) "(?<header_dvt>[^\"]*)" (?<header_did>[^ ]*) (?<header_sv>[^ ]*) (?<header_v>[^ ]*) (?<body>[^ ]*)/
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
</filter>
<match game.**>
@type copy
<store>
@type forest
subtype elasticsearch
<buffer>
@type file
path /tmp/elastic-buffer-191
total_limit_size 1024MB
chunk_limit_size 16MB
flush_mode interval
flush_interval 5s
flush_thread_count 8
</buffer>
<template>
hosts 10.144.77.99:9200
logstash_format true
logstash_prefix ${tag_parts[1]}
</template>
<case game.http.**>
logstash_prefix ${tag}
</case>
<case game.socket.**>
logstash_prefix ${tag}
</case>
</store>
</match>

- 开源日志收集软件fluentd 转发(forward)架构配置
- 开源日志收集软件fluentd 转发(forward)架构配置
- Fluentd (td-agent) 日志收集系统
- Flume(NG)架构设计要点及配置实践 Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集
- 使用开源工具fluentd-pilot收集容器日志
- 利用fluent-bit收集Kubernetes集群日志
- 使用Fluentd + MongoDB构建实时日志收集系统
- elk收集nginx日志配置实例!
- 日志配置,日志收集,日志切割
- 使用Fluentd + MongoDB构建实时日志收集系统
- ELK6.3.1版本使用filebeat收集nginx的日志配置文件
- 分布式日志收集系统: Facebook Scribe之配置文件
- C#实现多级子目录Zip压缩解压实例 NET4.6下的UTC时间转换 [译]ASP.NET Core Web API 中使用Oracle数据库和Dapper看这篇就够了 asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程 asp.net core异步进行新增操作并且需要判断某些字段是否重复的三种解决方案 .NET Core开发日志
- fluentd+mongodb构建分布式日志收集系统
- Nginx容器日志收集方案fluentd+elasticsearch+kilbana
- 使用Fluentd + MongoDB构建实时日志收集系统
- 分布式日志收集系统: Facebook Scribe之配置文件
- Syslog-ng+Rsyslog收集日志:rsyslog-v8.X版 配置(二)
- 收集EVA日志和配置信息
- 配置kibana和logstash、filebeat 日志统一收集