HashMap数据结构之道

问题1:HashMap的数据结构是什么样的?
同学1:嗯...数组+链表
同学2:数组+链表...
同学3:数组+链表...
同学4:数组+链表+红黑树...
同学n:.....
为什么答案会有两种?难道大家学习的HashMap有两个版本?我突然想起马克思哲学里面的一句话,真理是相对的,不是绝对的,变化才是唯一的真理。
不错,对于Java这种语言排行榜经常排于榜首的高级语言,变化也是它的生存之道。Java在推出新版本的同时,不断的完善重要class的数据结构,提升它的性能,稳固它的安全性。HashMap就是其中之一。
HashMap在Java1.7里使用的是数组+链表的数据结构,在Java1.8里使用的是数组+链表+红黑树。
问题2:HashMap为什么在1.8的版本,对它的数据结构进行了修改?
同学1:嗯,有bug(标准的程序员思维)
同学2:有漏洞...(有***思维的同学)
同学3:没事,无聊,寂寞,想搞事情...(有创业者思维的同学)
同学4:提升性能...(有架构师思维的同学)
......
Java在维护它全球顶级语言,近趋于霸主地位的时候,当然要从细节入手,从源码入手,完善它的性能,修复它的漏洞。Java如此,其他语言也是如此。
问题3:HashMap在1.7和1.8,性能上究竟有了多大的提升,我们上代码,看看速度如何?
import java.util.HashMap;public class Test100 {public static void main(String[] args) {
System.out.println("java version:" + System.getProperty("java.version"));
HashMap<String, String> hashMap = new HashMap<String, String>();
long putTotalTime = 0, getTotalTime = 0;
for (int i = 0; i < 100000; i++) {
long putStartTime = System.currentTimeMillis();
hashMap.put("yaoshen" + i, "yaoshen" + i);
putTotalTime += System.currentTimeMillis() - putStartTime;
long getStartTime = System.currentTimeMillis();
hashMap.get("yaoshen" + i);
getTotalTime += System.currentTimeMillis() - getStartTime;
}
System.out.println("10W data:put total time is :" + putTotalTime);
System.out.println("10W data:get total time is :" + getTotalTime);}}测试结果如下:

我们可以清楚的看见HashMap在1.8的版本,数据量非常大(10万条)的时候,查询的总时间明显比较低,也就是说HashMap在1.8的版本查找速度很快,插入或者是删除相对较慢。那么为什么会这样?
思考题:为什么HashMap在1.8的版本,查找速度有了大幅提升?
接下来,我将逐一带大家进行全面剖析HashMap的数据结构。
一. 数据结构不同
1. HashMap在1.7的版本数据结构如下:
数组+链表(单向链表)
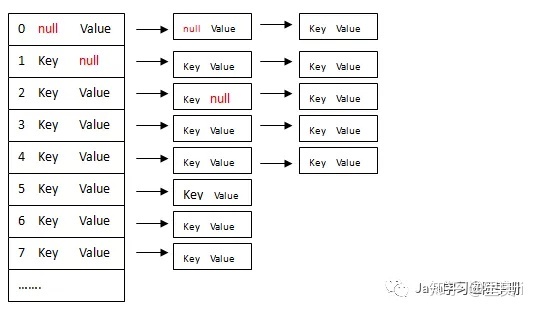
1.1 从数据结构我们来分析HashMap的put过程
插入元素的数据结构如下代码:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/** * Creates new entry. */
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}}第一步:计算key对应数组的index(索引),是通过hashcode & (length-1),就是hashcode值和(数组长度-1)的与运算。
第二步:将插入的元素放入数组index的位置,将next指针指向之前的元素。
图解过程:
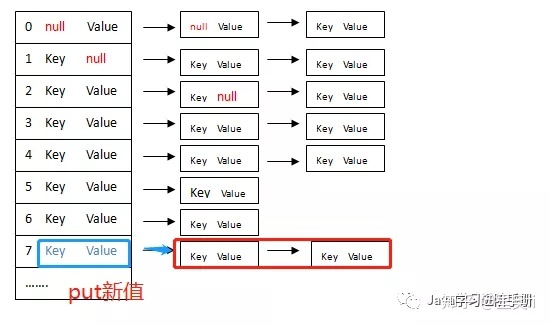
1.2 HashMap在1.7的版本的get过程
第一步:计算key对应数组的index(索引),找到数组的头结点
第二步:从头结点逐个向下遍历,直到key的hash值与节点的hash值碰撞相等,然后取出value值。
思考一下:get过程的时间复杂度应该是O(n),试着想一下,如果我们在插入的过程中对节点进行一些变换,例如将单向链表变成二叉树,或者是平衡二叉树,是不是下次在查找的过程,就能减少遍历的时间复杂度呢?
下面,我们引入HashMap在Java1.8里的数据结构
2. HashMap在1.8的版本数据结构如下:
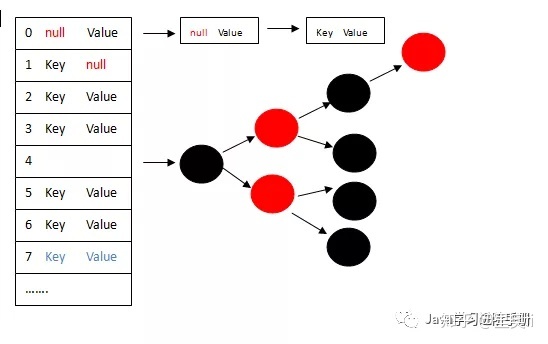
从源码中分析:
/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. */static final int TREEIFY_THRESHOLD = 8;
我们来翻译这句话:
HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时(>8个),采用红黑树(特点是查询时间是O(logn))存储(有一个阀值控制,大于阀值(8个),将链表存储转换成红黑树存储。
可能此时,对于数据结构,你会有知识断层,那么没关系,我来为你一一介绍这些数据结构。
1. 数组,带有索引的容器,固定长度(ArrayList中数据结构,自动扩容)

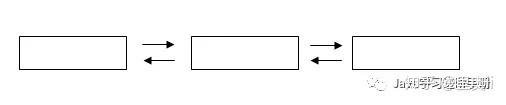
2. 双向链表,如下图(LinkedList)
3. 单向链表
4. 红黑树
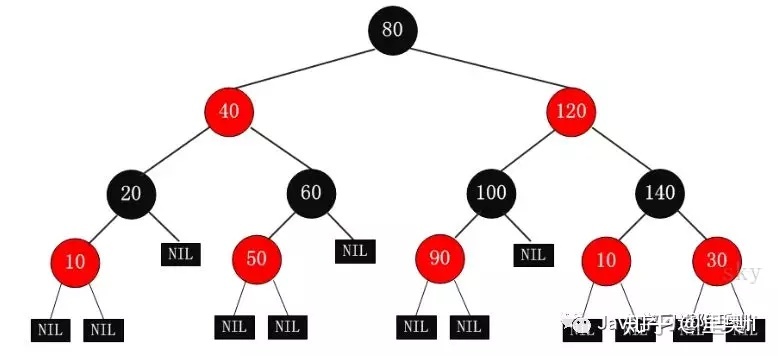
特点:
1)每个节点非红即黑
2)根节点是黑的;
3)每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
4)如图所示,如果一个节点是红的,那么它的两儿子都是黑的;
5)对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
6)每条路径都包含相同的黑节点;
2.1 此时,我们分析一下HashMap在1.8版本里面的put过程
插入元素包含如下
1)单向链表,代码如上面对应的1.7版本
2)红黑树
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}}分析put过程
第一步:计算key对应数组的index(索引),是通过hashcode & (length-1),就是hashcode值和(数组长度-1)的与运算。
第二步:当前索引所对应的单向链表长度<=8时,将插入的元素放入数组index的位置,将next指针指向之前的元素。反之,则把当前索引所有的元素转化为红黑树。
2.2 HashMap在1.8的版本的get过程
第一步:计算key对应数组的index(索引),找到数组的头结点
第二步:如果头节点是单向链表结构,则从头结点逐个向下遍历,知道key的hash值与节点的hash值碰撞相等,然后取出value值。如果是红黑树,则用红黑树的遍历,碰撞hash值,然后取出value值。
二. HashMap的扩容
当HashMap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。
比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
综上所述,我们得出结论:
一. HashMap在Java1.7的版本是数组+单向链表存储,在1.8的版本是数组+单向链表+红黑树(如果当前索引对应的单向链表长度小于等于8,则用单向链表,如果大于8,则转化为红黑树)
二. HashMap在1.8的版本中,大数据量的查找,性能有了提升,是因为在put的过程中,增加了红黑树的转化,牺牲了put的时间和空间复杂度
三. HashMap的扩容过程,是个非常消耗性能的,扩容后的HashMap,需要重新计算之前数组各个索引对应的头结点(根节点)在新数组中对应的索引。

- 比较分析Vector、ArrayList和hashtable hashmap数据结构
- 共同学习Java源代码-数据结构-HashMap(十八)
- JDK1.8的HashMap数据结构及红黑树
- Android开发中高效的数据结构用SparseArray代替HashMap
- Android开发中高效的数据结构用SparseArray代替HashMap
- [数据结构]--jdk1.8中HashMap源码解析
- HashMap的数据结构
- HashMap的原理,底层数据结构,rehash的过程,指针碰撞问题
- 一天一个数据结构之HashMap
- Android开发中高效的数据结构用SparseArray代替HashMap
- 数据结构:ArrayList、Vector、LinkedList和HashMap、HashTable、LinkedHashMap、TreeMap
- 数据结构探险之HashMap 与Hashtable
- 共同学习Java源代码-数据结构-HashMap(十九)
- 共同学习Java源代码-数据结构-HashMap(一)
- 探究HashMap数据结构
- Java常见的底层数据结构,一HashMap的分析为例子
- HashMap的数据结构
- hashMap的底层数据结构:数组+链表
- HashMap的数据结构
- 【金三银四】HashMap图解原理与数据结构二【JDK8红黑树】