Flink DataStream中CoGroup实现原理与三种 join 实现
CoGroup
CoGroup 表示联合分组,将两个不同的DataStream联合起来,在相同的窗口内按照相同的key分组处理,先通过一个demo了解其使用方式:
case class Order(id:String, gdsId:String, amount:Double)
case class Gds(id:String, name:String)
case class RsInfo(orderId:String, gdsId:String, amount:Double, gdsName:String)
object CoGroupDemo{def main(args:Array[String]):Unit={val env =StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val kafkaConfig =newProperties();
kafkaConfig.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
kafkaConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"test1");
val orderConsumer =newFlinkKafkaConsumer011[String]("topic1",newSimpleStringSchema, kafkaConfig)val gdsConsumer =newFlinkKafkaConsumer011[String]("topic2",newSimpleStringSchema, kafkaConfig)val orderDs = env.addSource(orderConsumer)
.map(x =>{val a = x.split(",")Order(a(0), a(1), a(2).toDouble)
})
val gdsDs = env.addSource(gdsConsumer)
.map(x =>{val a = x.split(",")Gds(a(0), a(1))
})
orderDs.coGroup(gdsDs)
.where(_.gdsId)// orderDs 中选择key
.equalTo(_.id)//gdsDs中选择key
.window(TumblingProcessingTimeWindows.of(Time.minutes(1)))
.apply(newCoGroupFunction[Order,Gds,RsInfo]{overridedef coGroup(first: lang.Iterable[Order], second: lang.Iterable[Gds],out:Collector[RsInfo]):Unit={//得到两个流中相同key的集合
}
})
env.execute()
}
}
从源码角度分析CoGrop的实现
两个DataStream进行CoGroup得到的是一个CoGroupedStreams类型,后面的where、equalTo、window、apply之间的一些转换,最终得到一个WithWindow类型,包含两个dataStream、key选择、where条件、window等属性
重点:WithWindow 的apply方法
对两个DataStream打标签进行区分,得到TaggedUnion,TaggedUnion包含one、two两个属性,分别对应两个流
将两个打标签后的流TaggedUnion 进行union操作合并为一个DataStream类型流unionStream
unionStream根据不同的流选择对应where/equalTo条件进行keyBy 得到KeyedStream流
通过指定的window方式得到一个WindowedStream,然后apply一个被CoGroupWindowFunction包装之后的function,后续就是window的操作
到这里已经将一个CoGroup操作转换为window操作,接着看后续是如何将相同的key的两个流的数据如何组合在一起的
1. 在用户定义CoGroupFunction 被CoGroupWindowFunction包装之后,会接着被InternalIterableWindowFunction包装,一个窗口相同key的所有数据都会在一个Iterable中, 会将其传给CoGroupWindowFunction
2. 在CoGroupWindowFunction中,会将不同流的数据区分开来得到两个list,传给用户自定义的CoGroupFunction中
JOIN
在理解了coGroup的实现后,join实现原理也就比较简单,DataStream join 同样表示连接两个流,也是基于窗口实现,其内部调用了CoGroup的调用链,使用姿势p与调用流程跟CoGroup及其相似,主要有以下两点不同:
不在使用CoGroupFunction,而是JoinFunction,在JoinFunction里面得到的是来自不同两个流的相同key的每一对数据
函数调用链
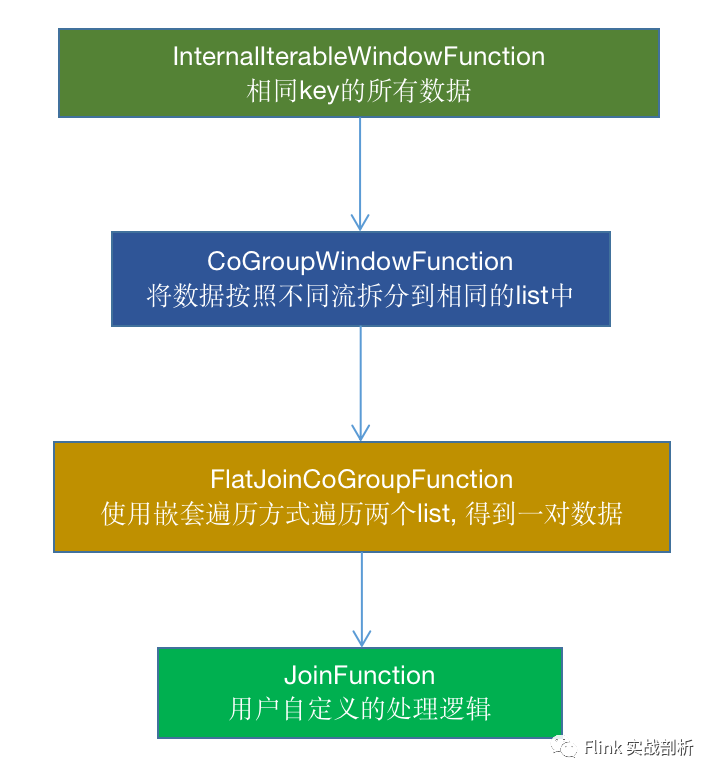
中间增加了FlatJoinCoGroupFunction函数调用,使用嵌套遍历方式得到两个流的笛卡尔积传给用户自定义函数

Left/Right join实现分析
Flink 中DataStream 只提供了inner join 的实现,并未提供left join 与 right join 的实现,那么同样可以通过CoGroup来实现这两种join,以left join 为例,处理逻辑在CoGroupFunction中,实现如下:
overridedef coGroup(first: lang.Iterable[Order], second: lang.Iterable[Gds],out:Collector[RsInfo]):Unit={first.foreach(x =>{if(!second.isEmpty){second.foreach(y=>{out.collect(newRsInfo(x.id,x.gdsId,x.amount,y.name))
})
}
if(second.isEmpty){out.collect(newRsInfo(x.id,x.gdsId,x.amount,null))
}
})
}

- join方法的实现原理
- MySQL Join 实现原理分析
- 浏览器三种刷新方式的缓存机制-----单点登录SSO的实现原理---PHP版单点登陆实现方案
- join方法的实现原理
- 深入理解join方法的实现原理
- 双向数据绑定原理(三种实现方式)
- MySQL中Join算法实现原理分析
- 转 Join的实现原理及优化思路
- 线程之间通信之join应用与实现原理剖析
- Android 总结:自定义键盘实现原理和三种实例详解
- MySQL-join的实现原理、优化及NLJ算法
- android三种动画实现原理及使用
- 图解 MySQL、Oracle、SQL Server 等数据库连接查询(JOIN)的三种实现算法
- 浅谈数据库Join的实现原理
- java多线程---顺序打印ABC的三种实现---join方法
- Android实现的三种翻页功能原理
- Nested loops、Hash join、Sort merge join(三种连接类型原理、使用要点)
- mysql join的实现原理及优化思路
- 读《MySQL性能调优与架构设计》笔记之Join 的实现原理及优化思路
- 【转载】MapReduce实现基本SQL操作的原理-join和group by,以及Dinstinct