[计算机视觉论文速递] 2018-03-11
通知:这篇推文有10篇论文速递信息,涉及目标检测、行人重识别Re-ID、图像检索和Zero-Shot Learning等方向
这篇文章本来是在2018-03-10推送的,但由于内容编辑出了问题,便忍痛删除了,让大家久等一天,在此说声抱歉!
先附上前三天的论文速递文章:
[计算机视觉论文速递] 2018-03-09
[计算机视觉论文速递] 2018-03-07
[计算机视觉论文速递] 2018-03-06
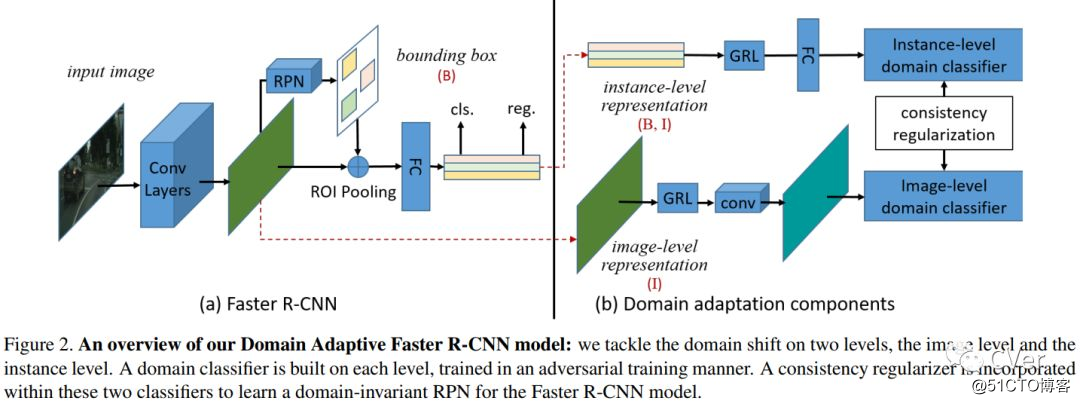
[1]《Domain Adaptive Faster R-CNN for Object Detection in the Wild》
Accepted to CVPR 2018
Abstract:Object detection typically assumes that training and test data are drawn from an identical distribution, which, however, does not always hold in practice. Such a distribution mismatch will lead to a significant performance drop. In this work, we aim to improve the cross-domain robustness of object detection. We tackle the domain shift on two levels: 1) the image-level shift, such as image style, illumination, etc, and 2) the instance-level shift, such as object appearance, size, etc. We build our approach based on the recent state-of-the-art Faster R-CNN model, and design two domain adaptation components, on image level and instance level, to reduce the domain discrepancy. The two domain adaptation components are based on H-divergence theory, and are implemented by learning a domain classifier in adversarial training manner. The domain classifiers on different levels are further reinforced with a consistency regularization to learn a domain-invariant region proposal network (RPN) in the Faster R-CNN model. We evaluate our newly proposed approach using multiple datasets including Cityscapes, KITTI, SIM10K, etc. The results demonstrate the effectiveness of our proposed approach for robust object detection in various domain shift scenarios.
arXiv:https://arxiv.org/abs/1803.03243

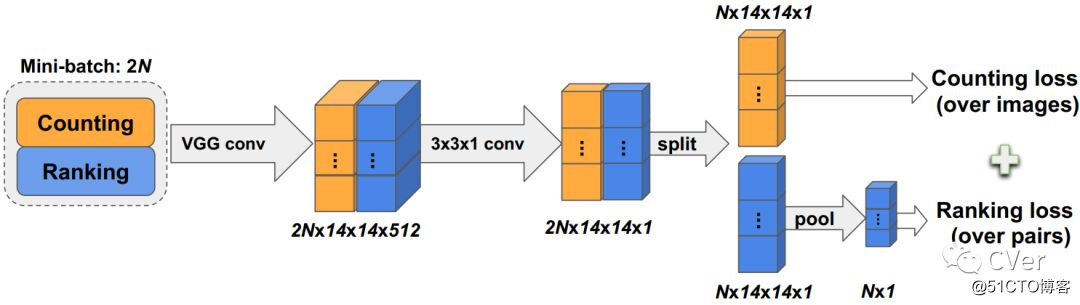
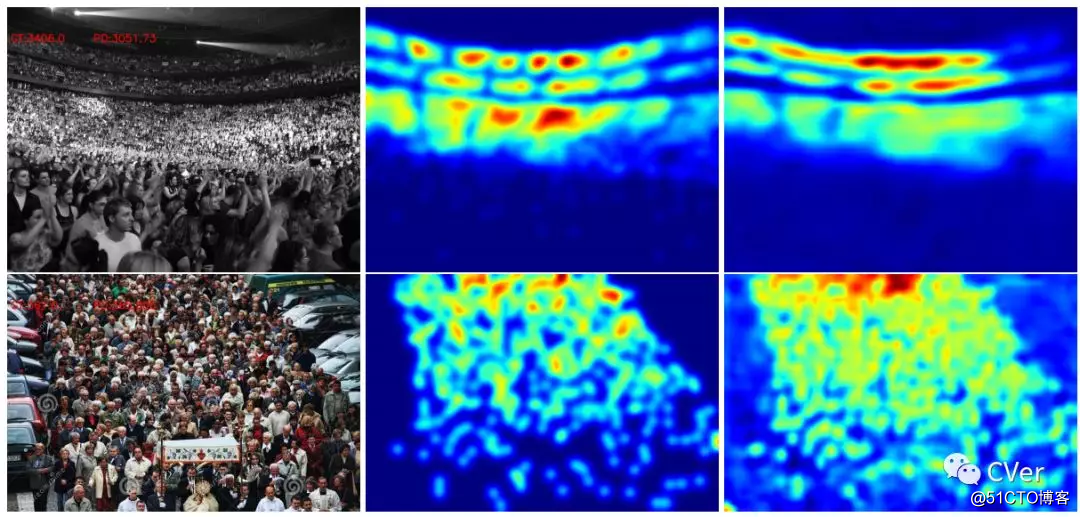
[2]《Leveraging Unlabeled Data for Crowd Counting by Learning to Rank》
Accepted by CVPR18
Abstract:We propose a novel crowd counting approach that leverages abundantly available unlabeled crowd imagery in a learning-to-rank framework. To induce a ranking of cropped images , we use the observation that any sub-image of a crowded scene image is guaranteed to contain the same number or fewer persons than the super-image. This allows us to address the problem of limited size of existing datasets for crowd counting. We collect two crowd scene datasets from Google using keyword searches and query-by-example image retrieval, respectively. We demonstrate how to efficiently learn from these unlabeled datasets by incorporating learning-to-rank in a multi-task network which simultaneously ranks images and estimates crowd density maps. Experiments on two of the most challenging crowd counting datasets show that our approach obtains state-of-the-art results.
arXiv:https://arxiv.org/abs/1803.03095
github:https://github.com/xialeiliu/CrowdCountingCVPR18


[3]《Preserving Semantic Relations for Zero-Shot Learning》
CVPR 2018
Abstract:Zero-shot learning has gained popularity due to its potential to scale recognition models without requiring additional training data. This is usually achieved by associating categories with their semantic information like attributes. However, we believe that the potential offered by this paradigm is not yet fully exploited. In this work, we propose to utilize the structure of the space spanned by the attributes using a set of relations. We devise objective functions to preserve these relations in the embedding space, thereby inducing semanticity to the embedding space. Through extensive experimental evaluation on five benchmark datasets, we demonstrate that inducing semanticity to the embedding space is beneficial for zero-shot learning. The proposed approach outperforms the state-of-the-art on the standard zero-shot setting as well as the more realistic generalized zero-shot setting. We also demonstrate how the proposed approach can be useful for making approximate semantic inferences about an image belonging to a category for which attribute information is not available.
注:Zero-shot learning 指的是我们之前没有这个类别的训练样本。但是我们可以学习到一个映射X->Y。如果这个映射足够好的话,我们就可以处理没有看到的类了。 比如,我们在训练时没有看见过狮子的图像,但是我们可以用这个映射得到狮子的特征。一个好的狮子特征,可能就和猫,老虎等等比较接近,和汽车,飞机比较远离。
arXiv:https://arxiv.org/abs/1803.03049
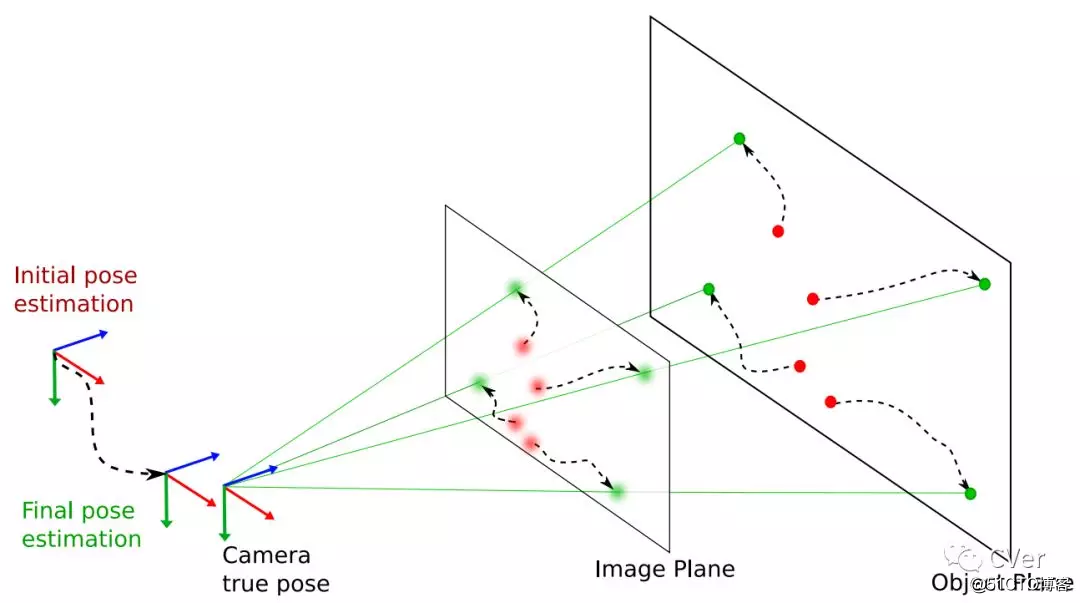
[4]《Robustness of control point configurations for homography and planar pose estimation》
Abstract:n this paper, we investigate the influence of the spatial configuration of a number of n≥4 control points on the accuracy and robustness of space resection methods, e.g. used by a fiducial marker for pose estimation. We find robust configurations of control points by minimizing the first order perturbed solution of the DLT algorithm which is equivalent to minimizing the condition number of the data matrix. An empirical statistical evaluation is presented verifying that these optimized control point configurations not only increase the performance of the DLT homography estimation but also improve the performance of planar pose estimation methods like IPPE and EPnP, including the iterative minimization of the reprojection error which is the most accurate algorithm. We provide the characteristics of stable control point configurations for real-world noisy camera data that are practically independent on the camera pose and form certain symmetric patterns dependent on the number of points. Finally, we present a comparison of optimized configuration versus the number of control points.
注:DLT、Homography、Pose Estimation真的是基础必备知识点!
arXiv:https://arxiv.org/abs/1803.03025

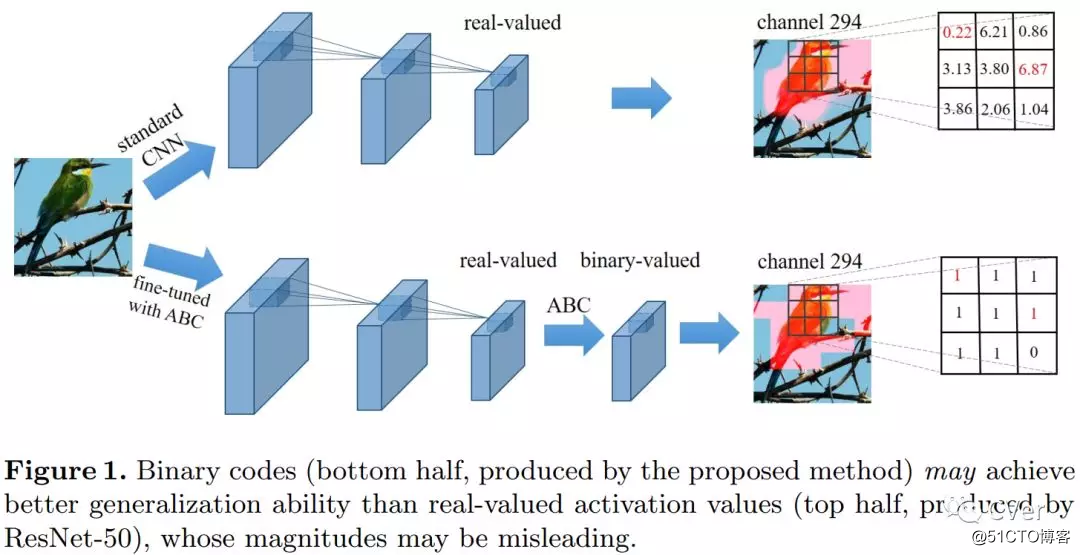
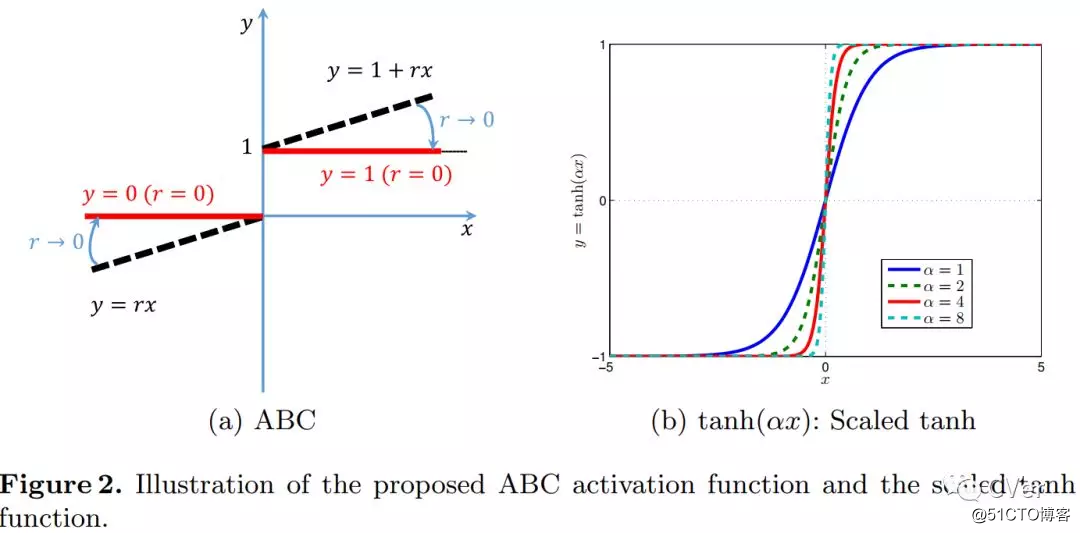
[5]《Learning Effective Binary Visual Representations with Deep Networks》
Abstract:Although traditionally binary visual representations are mainly designed to reduce computational and storage costs in the image retrieval research, this paper argues that binary visual representations can be applied to large scale recognition and detection problems in addition to hashing in retrieval. Furthermore, the binary nature may make it generalize better than its real-valued counterparts. Existing binary hashing methods are either two-stage or hinging on loss term regularization or saturated functions, hence converge slowly and only emit soft binary values. This paper proposes Approximately Binary Clamping (ABC), which is non-saturating, end-to-end trainable, with fast convergence and can output true binary visual representations. ABC achieves comparable accuracy in ImageNet classification as its real-valued counterpart, and even generalizes better in object detection. On benchmark image retrieval datasets, ABC also outperforms existing hashing methods.
arXiv:https://arxiv.org/abs/1803.03004
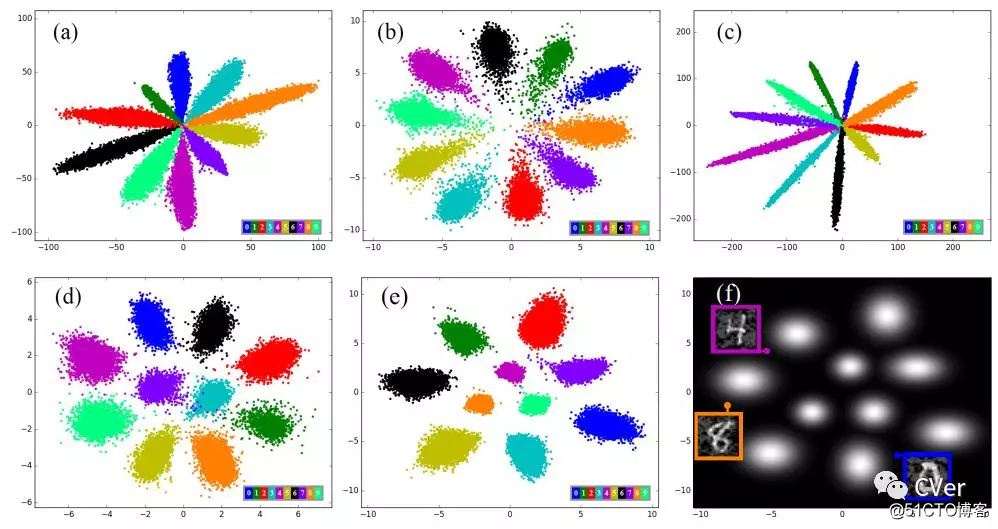
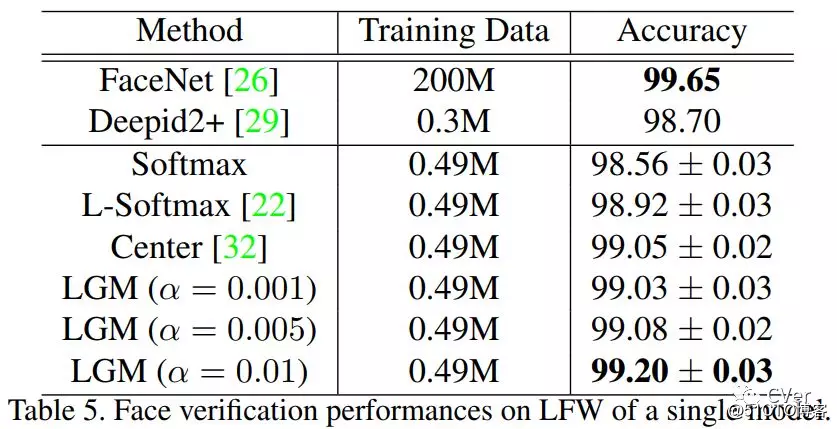
[6]《Rethinking Feature Distribution for Loss Functions in Image Classification》
Accepted to CVPR 2018 as spotlight
Abstract:We propose a large-margin Gaussian Mixture (L-GM) loss for deep neural networks in classification tasks. Different from the softmax cross-entropy loss, our proposal is established on the assumption that the deep features of the training set follow a Gaussian Mixture distribution. By involving a classification margin and a likelihood regularization, the L-GM loss facilitates both a high classification performance and an accurate modeling of the training feature distribution. As such, the L-GM loss is superior to the softmax loss and its major variants in the sense that besides classification, it can be readily used to distinguish abnormal inputs, such as the adversarial examples, based on their features' likelihood to the training feature distribution. Extensive experiments on various recognition benchmarks like MNIST, CIFAR, ImageNet and LFW, as well as on adversarial examples demonstrate the effectiveness of our proposal.
注:Paper很硬,L-GM能和the softmax cross-entroy loss进行PK?!
arXiv:https://arxiv.org/abs/1803.02988
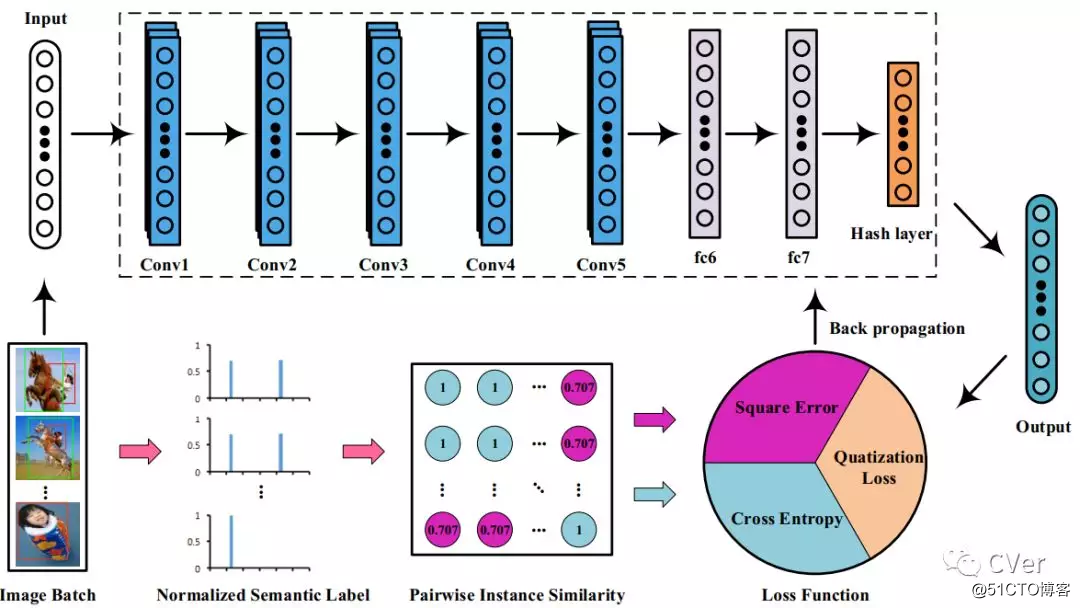
[7]《Instance Similarity Deep Hashing for Multi-Label Image Retrieval》
Abstract:Hash coding has been widely used in the approximate nearest neighbor search for large-scale image retrieval. Recently, many deep hashing methods have been proposed and shown largely improved performance over traditional feature-learning-based methods. Most of these methods examine the pairwise similarity on the semantic-level labels, where the pairwise similarity is generally defined in a hard-assignment way. That is, the pairwise similarity is '1' if they share no less than one class label and '0' if they do not share any. However, such similarity definition cannot reflect the similarity ranking for pairwise images that hold multiple labels. In this paper, a new deep hashing method is proposed for multi-label image retrieval by re-defining the pairwise similarity into an instance similarity, where the instance similarity is quantified into a percentage based on the normalized semantic labels. Based on the instance similarity, a weighted cross-entropy loss and a minimum mean square error loss are tailored for loss-function construction, and are efficiently used for simultaneous feature learning and hash coding. Experiments on three popular datasets demonstrate that, the proposed method outperforms the competing methods and achieves the state-of-the-art performance in multi-label image retrieval.
arXiv:https://arxiv.org/abs/1803.02987
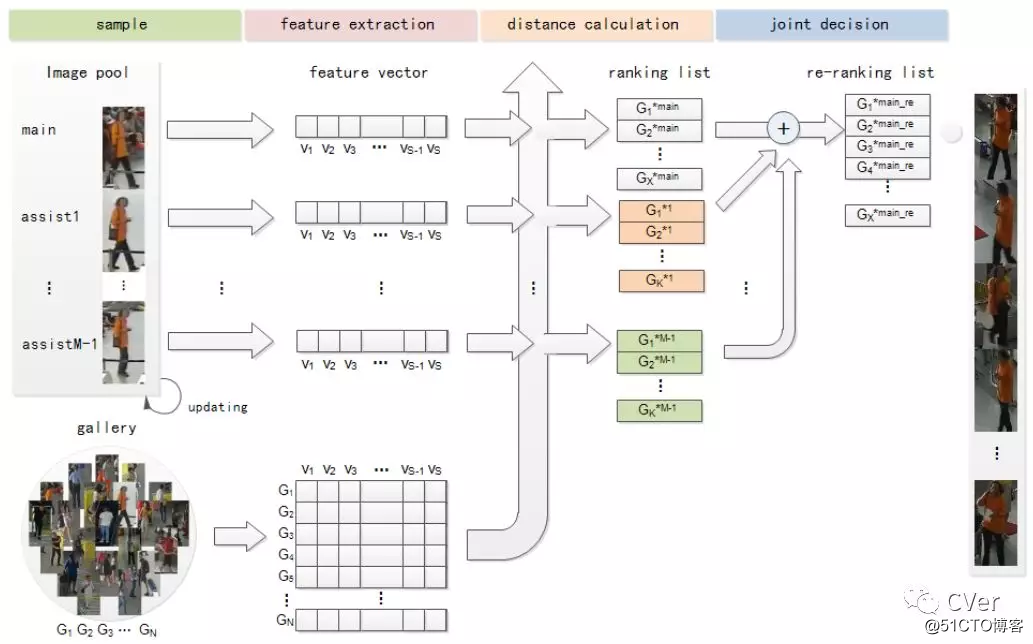
[8]《A framework with updateable joint images re-ranking for Person Re-identification》
submitted to JVCI
Abstract:Person re-identification plays an important role in realistic video surveillance with increasing demand for public safety. In this paper, we propose a novel framework with rules of updating images for person re-identification in real-world surveillance system. First, Image Pool is generated by using mean-shift tracking method to automatically select video frame fragments of the target person. Second, features extracted from Image Pool by convolutional network work together to re-rank original ranking list of the main image and matching results will be generated. In addition, updating rules are designed for replacing images in Image Pool when a new image satiating with our updating critical formula in video system. These rules fall into two cat 8000 egories: if the new image is from the same camera as the previous updated image, it will replace one of assist images; otherwise, it will replace the main image directly. Experiments are conduced on Market-1501, iLIDS-VID and PRID-2011 and our ITSD datasets to validate that our framework outperforms on rank-1 accuracy and mAP for person re-identification. Furthermore, the update ability of our framework provides consistently remarkable accuracy rate in real-world surveillance system.
arXiv:https://arxiv.org/abs/1803.02983

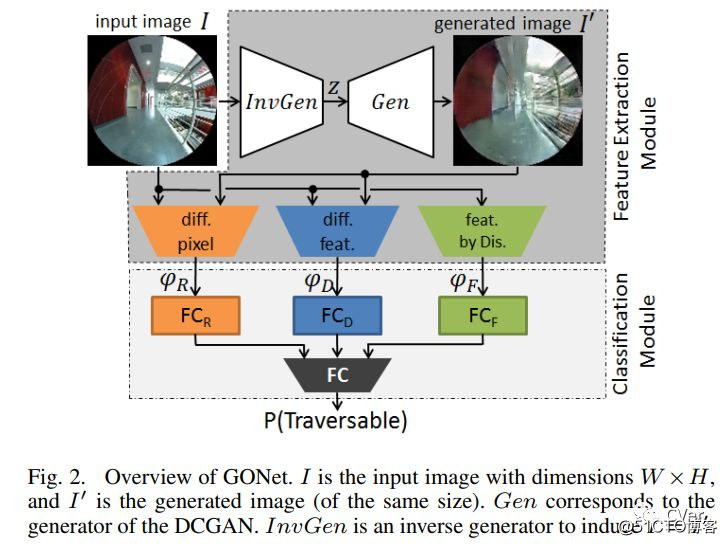
[9]《GONet: A Semi-Supervised Deep Learning Approach For Traversability Estimation》
Abstract:We present semi-supervised deep learning approaches for traversability estimation from fisheye images. Our method, GONet, and the proposed extensions leverage Generative Adversarial Networks (GANs) to effectively predict whether the area seen in the input image(s) is safe for a robot to traverse. These methods are trained with many positive images of traversable places, but just a small set of negative images depicting blocked and unsafe areas. This makes the proposed methods practical. Positive examples can be collected easily by simply operating a robot through traversable spaces, while obtaining negative examples is time consuming, costly, and potentially dangerous. Through extensive experiments and several demonstrations, we show that the proposed traversability estimation approaches are robust and can generalize to unseen scenarios. Further, we demonstrate that our methods are memory efficient and fast, allowing for real-time operation on a mobile robot with single or stereo fisheye cameras. As part of our contributions, we open-source two new datasets for traversability estimation. These datasets are composed of approximately 24h of videos from more than 25 indoor environments. Our methods outperform baseline approaches for traversability estimation on these new datasets.
注:Traversability Estimation很有意思的研究应用!
arXiv:https://arxiv.org/abs/1803.03254

[10]《Applicability and interpretation of the deterministic weighted cepstral distance》
Abstract:Quantifying similarity between data objects is an important part of modern data science. Deciding what similarity measure to use is very application dependent. In this paper, we combine insights from systems theory and machine learning, and investigate the weighted cepstral distance, which was previously defined for signals coming from ARMA models. We provide an extension of this distance to invertible deterministic linear time invariant single input single output models, and assess its applicability. We show that it can always be interpreted in terms of the poles and zeros of the underlying model, and that, in the case of stable, minimum-phase, or unstable, maximum-phase models, a geometrical interpretation in terms of subspace angles can be given. We then devise a method to assess stability and phase-type of the generating models, using only input/output signal information. In this way, we prove a connection between the extended weighted cepstral distance and a weighted cepstral model norm. In this way, we provide a purely data-driven way to assess different underlying dynamics of input/output signal pairs, without the need for any system identification step. This can be useful in machine learning tasks such as time series clustering. An iPython tutorial is published complementary to this paper, containing implementations of the various methods and algorithms presented here, as well as some numerical illustrations of the equivalences proven here.
注:很硬的文章!
arXiv:https://arxiv.org/abs/1803.03104
-------我是题外话-------
最近有小伙伴私信我说,Abstract有时候翻译的不严谨。这个问题我也意识到,因为每次更新的paper较多,我做不到每篇人工翻译,所以偷懒就用了Google翻译,所以涉及到专业词汇时,翻译的效果就gg了。
此次推文,全是原文(英文),让大家感受一下。下面发起一个投票,接受一下大家的反馈,最终以票高的选项为准。

- [计算机视觉论文速递] 2018-04-23
- [计算机视觉论文速递] 2018-04-28
- [计算机视觉论文速递] 2018-05-08
- [计算机视觉论文速递] 2018-05-10
- [计算机视觉论文速递] 2018-05-16
- [计算机视觉论文速递] 2018-03-14
- [计算机视觉论文速递] 2018-05-19
- [计算机视觉论文速递] 2018-03-16
- [计算机视觉论文速递] 2018-03-18
- 2019计算机视觉论文精选速递(2019/1/23-2018/1/28)
- [计算机视觉论文速递] 2018-03-20
- [计算机视觉论文速递] 2018-03-30
- [计算机视觉论文速递] 2018-03-31
- [计算机视觉论文速递] 2018-04-03
- [计算机视觉论文速递] 2018-04-17
- [计算机视觉论文速递] 2018-04-19
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- 计算机视觉领域经典论文源码大全
- 图像处理和计算机视觉中的经典论文
- 为什么不去读顶级会议上的论文?适应于机器学习、计算机视觉和人工智能