十分钟学会reqests模块爬取数据——从爬取疫情数据说起
在做疫情数据可视化的时候涉及到一些数据的爬取,一般python中爬取数据常用的就是requests和urllib,两者相比requests更加快速便捷。代码也更容易理解。
安装
pip install requests
pip install json
因为爬取下来的数据大多是json格式所以为了解析数据我们还会用到json模块
快速使用
为了更容易上手使用requests模块,本文略去各种介绍性文字,直接以实战代码来讲解。
直接使用API数据
OK,假如我们现在想对2020-nCov的疫情数据进行可视化分析,如果直接从丁香园或者百度疫情等平台获取数据的话就会设计到正则表达式等比较复杂的处理,所以最省事的就是看看能不能找到一些提供数据的接口,很幸运百度和腾讯都提供了数据接口百度APIi、腾讯API,我们以百度API为例,直接打开API地址发现是一个字典。

OK,是我们想要的数据,这时候只要两行代码就可以搞定
data = requests.get("https://service-nxxl1y2s-1252957949.gz.apigw.tencentcs.com/release/newpneumonia")
data = data.json()看到爬下来的数据正是我们需要的。接下来只需要从字典里面一个一个取出所需要的数据就可以进行可视化分析。
data = data['data']['conf']['component'][0]['caseList']
这里用到的就是最基本的requests用法,直接向网站请求数据就是get,当然还有其他一大堆请求方式。
requests.post(url)
requests.put(url)
requests.delete(url)
requests.head(url)
requests.options(url)
get方式也可以发送带参数的请求,按照以下方式就可以传递参数:
url = 'http://httpbin.org/get'
data = {
'name':'zhangsan',
'age':'25'
}
response = requests.get(url,params=data)
print(response.url)
print(response.text)
response.text返回的是Unicode格式,通常需要转换为utf-8格式,否则就是乱码。response.content是二进制模式,可以下载视频之类的,如果想看的话需要decode成utf-8格式。不管是通过response.content.decode("utf-8)的方式还是通过response.encoding="utf-8"的方式都可以避免乱码的问题发生。
接下来说下header的事情,header就是头部信息,有些网站在你发送请求的时候就必须要求你带一个请求头,否则就会报错。
因此我们从github上找到一些别人做的比较简易但是数据满足我们需求的页面进行爬取。比如我们想爬知乎并且和上面一样直接请求
url = 'https://www.zhihu.com/'
response = requests.get(url)
response.encoding = "utf-8"
print(response.text)
就会发现报错400
<html>
<head><title>400 Bad Request</title></head>
<body bgcolor="white">
<center><h1>400 Bad Request</h1></center>
<hr><center>openresty</center>
</body>
</html>
意思是“无法找到该网页”HTTP 错误400表示请求出错,网站被删除或者被屏蔽了。由于语法格式有误,服务器无法理解此请求。所以要按照以下方式进行请求:
url = 'https://www.zhihu.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
}
response = requests.get(url,headers=headers)
print(response.text)
就可以成功把知乎首页数据爬下来了。如果想在请求的同时传一些数据就可以通过post把数据提交到url地址,等同于一字典的形式提交form表单里面的数据
url = 'http://httpbin.org/post'
data = {
'name':'jack',
'age':'23'
}
response = requests.post(url,data=data)
print(response.text)
结果
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "23",
"name": "jack"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "16",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e3e9f1c-b6bdd9f63ad5a5f5bbce5f7b"
},
"json": null,
"origin": "60.169.239.171",
"url": "http://httpbin.org/post"
}扯远了,回到爬取疫情数据上来,刚刚说的是在找到了API的情况下也就是找到了直接提供数据的网址,那如果有些消息找不到API呢,比如想爬取关于安徽省的新闻,这两个API都没有直接提供,然而
https://yiqing.ahusmart.com/页面上就显示了有关安徽的新闻。
现在按下F12切换到network刷新一下页面,然后check一下里面的内容,发现几条信息的preview有点像新闻
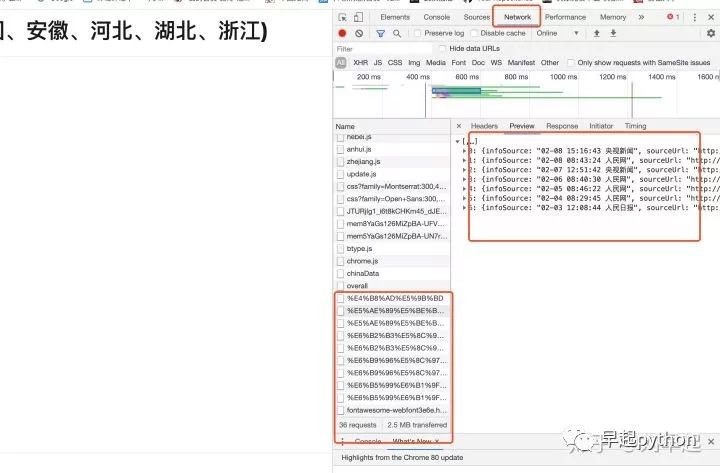
再check一下里面的内容,刚好是我们要的安徽新闻。

这时候回到headers里面看看请求的网址
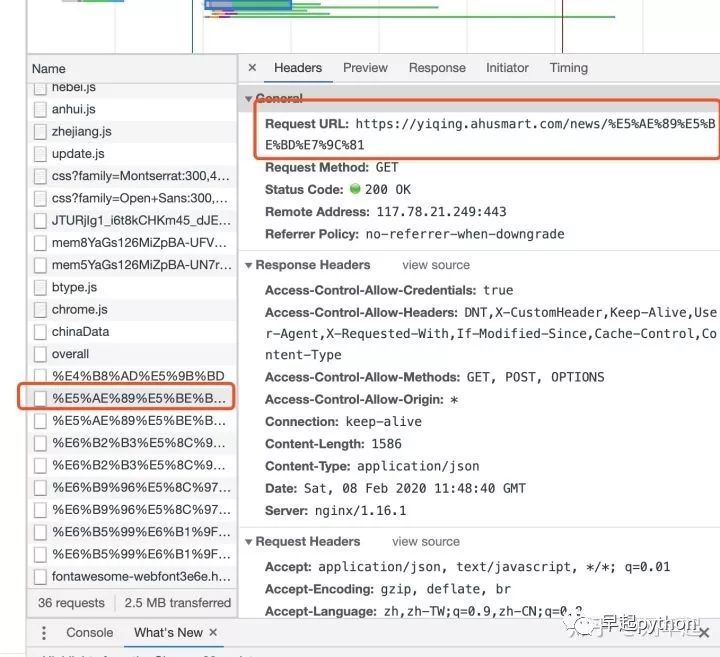
OK,就是这个,接下来按照刚刚的方法,向这个网址发送请求就可以把有关安徽的新闻拿下来了\
res = requests.get("https://yiqing.ahusmart.com/news/%E5%AE%89%E5%BE%BD%E7%9C%81")
data = res.json()一般常用的网站用get方法或者post方法就可以搞定,那么复杂一点的以后再讲。
附一些状态码的说明:
100: ('continue',),
101: ('switching_protocols',),
102: ('processing',),
103: ('checkpoint',),
122: ('uri_too_long', 'request_uri_too_long'),
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'),
201: ('created',),
202: ('accepted',),
203: ('non_authoritative_info', 'non_authoritative_information'),
204: ('no_content',),
205: ('reset_content', 'reset'),
206: ('partial_content', 'partial'),
207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),
208: ('already_reported',),
226: ('im_used',),
# Redirection.
300: ('multiple_choices',),
301: ('moved_permanently', 'moved', '\\o-'),
302: ('found',),
303: ('see_other', 'other'),
304: ('not_modified',),
305: ('use_proxy',),
306: ('switch_proxy',),
307: ('temporary_redirect', 'temporary_moved', 'temporary'),
308: ('permanent_redirect',
'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# Client Error.
400: ('bad_request', 'bad'),
401: ('unauthorized',),
402: ('payment_required', 'payment'),
403: ('forbidden',),
404: ('not_found', '-o-'),
405: ('method_not_allowed', 'not_allowed'),
406: ('not_acceptable',),
407: ('proxy_authentication_required', 'proxy_auth', 'proxy_
8000
authentication'),
408: ('request_timeout', 'timeout'),
409: ('conflict',),
410: ('gone',),
411: ('length_required',),
412: ('precondition_failed', 'precondition'),
413: ('request_entity_too_large',),
414: ('request_uri_too_large',),
415: ('unsupported_media_type', 'unsupported_media', 'media_type'),
416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'),
417: ('expectation_failed',),
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),
421: ('misdirected_request',),
422: ('unprocessable_entity', 'unprocessable'),
423: ('locked',),
424: ('failed_dependency', 'dependency'),
425: ('unordered_collection', 'unordered'),
426: ('upgrade_required', 'upgrade'),
428: ('precondition_required', 'precondition'),
429: ('too_many_requests', 'too_many'),
431: ('header_fields_too_large', 'fields_too_large'),
444: ('no_response', 'none'),
449: ('retry_with', 'retry'),
450: ('blocked_by_windows_parental_controls', 'parental_controls'),
451: ('unavailable_for_legal_reasons', 'legal_reasons'),
499: ('client_closed_request',),
# Server Error.
500: ('internal_server_error', 'server_error', '/o\\', '✗'),
501: ('not_implemented',),
502: ('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504: ('gateway_timeout',),
505: ('http_version_not_supported', 'http_version'),
506: ('variant_also_negotiates',),
507: ('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510: ('not_extended',),
511: ('network_authentication_required', 'network_auth', 'network_authe
- 十分钟学会reqests模块爬取数据——从爬取疫情数据说起!
- 十分钟学会reqests模块爬取数据——从爬取疫情数据说起
- 大数据处理之道(十分钟学会Python)
- 大数据处理之道(十分钟学会Python)
- 大数据处理之道(十分钟学会Python)
- 大数据处理之道(十分钟学会Python)
- (转)大数据处理之道(十分钟学会Python)
- python3 BeautifulSoup模块使用字典的方法抓取a标签内的数据示例
- 数据中台全景架构及模块解析!一文入门中台架构师!
- 关于原子哥ENC28J60网络通信模块接收数据代码的一点疑惑
- 数据挖掘三大模块
- 用struct模块处理二进制数据
- 日常生活中有哪些十分钟就能学会并可以终生受用的技能
- 当你学会抄菜的时候,你就学会了大数据
- stm32获取DHT11模块温湿度数据原理解析
- 对评论模块数据提取的一点心得
- pysam - 多种格式基因组数据(sam/bam/vcf/bcf/cram/…)读写与处理模块(python)--转载
- 作业1:关于使用python中scikit-learn(sklearn)模块,实现鸢尾花(iris)相关数据操作(数据加载、标准化处理、构建聚类模型并训练、可视化、评价模型)
- 模块 DLL C:\Windows\system32\inetsrv\aspnetcore.dll 未能加载。返回的数据为错误信息。(IIS7应用程序池自动关闭)
- Python里的数据存储模块:pickle使用方法