GitHub上3k+star的python爬虫库你了解吗?详解MechanicalSoup爬虫库
提起python爬虫,大家想起的是requests还是bf4或者是scrapy?但是有一款爬虫库在GitHub上已经拿了3k+的小星星,那就是MechanicalSoup:

MechanicalSoup有什么特点
MechanicalSoup适合在哪些场景用
代码详解MechanicalSoup的工作流程
MechanicalSoup介绍
MechanicalSoup不仅仅像一般的爬虫包一样可以从网站上爬取数据,而且可以通过简单的命令来自动化实现与网站交互的python库。它的底层使用的是BeautifulSoup(也就是bs4)和requests库,因此如果各位读者熟悉以上两个库,那么使用起来会更加的顺手。
因此,如果在开发过程中需要不断的与网站进行交互,比如点击按钮或者是填写表单,那么MechanicalSoup将会派上很大的用场。接下来,让我们直接用代码展示这个神奇的爬虫包是怎样工作的。
MechanicalSoup安装
#直接安装pip install mechanicalsoup#从GitHub上下载并安装开发版本pip install git+https://github.com/MechanicalSoup/MechanicalSoup
代码详解MechanicalSoup
我们将分两个案例详解是怎样通过MechanicalSoup实现网页内容获取和网站交互,首先看第一个爬取虎扑热帖。
我们先打开虎扑社区首页,可以看到有几个帖子是红色标题,现在想把这几个帖子的标题爬下来并保存。首先创建一个浏览器实例:
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
现在我么在浏览器的实例中打开虎扑bbs的网站,提示200表示OK访问成功
browser.open('https://bbs.hupu.com/')<Response [200]>我们的浏览器实例现在位于虎扑bbs主页。现在,我们需要获取该页面上存在的文章列表。这部分有点棘手,因为我们需要唯一地标识包含文章列表的标签的属性。但是,借助Chrome之类的浏览器可以轻松完成此操作:我们通过检查元素发现发现它位于ul标签内,而这个ul标签在一个clss为list的div里面,然后进一步检查发现热帖的clss="red",这样我们就可以利用类似bs4的方法找到我们需要的文章标题。
result = browser.get_current_page().find('div', class_="list")
result= list(result.find('ul'))
bbs_list =[]for i in range(len(result)):
if result[i] != '\n'<
8000
span style="margin:0px;padding:0px;max-width:100%;color:rgb(153,153,153);">:
bbs_list.append(result[i])
bbs_top = []for i in bbs_list:
bbs_top.append(i.find('span',class_="red"))
bbs_top
看下结果,已经成功将带有标签的标题保存,接下来只要用.text就可以取出标题。
[<span class="red">唱的让人心碎,珍妮弗-哈德森赛前献唱,For Kobe and Gigi</span>,
<span class="red">[字幕]魔术师致敬科比斯特恩:斯特恩是我救命恩人,科比这样的球员永远不会再有</span>,
<span class="red">[流言板]Mambas Forever!如果1月27日能够重来,也许......</span>,
<span class="red">今天比赛不管谁赢,mamba never out</span>,
None,
None,
None,
None,
None,
None]
再看下一个例子, mechanicalsoup是怎样与网站进行交互。这次我们选择一个更简单的例子,使用mechanicalsoup来进行百度搜索。
和之前的操作一样,我们先在浏览器创建实例并打开百度首页。
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open('https://www.baidu.com/')
<Response [200]>
看到响应成功之后,我们再来提取一下需要提交的表单
browser.select_form()
browser.get_current_form().print_summary()
<input name="bdorz_come" type="hidden" value="1"/>
<input name="ie" type="hidden" value="utf-8"/>
<input name="f" type="hidden" value="8"/>
<input name="rsv_bp" type="hidden" value="1"/>
<input name="rsv_idx" type="hidden" value="1"/>
<input name="tn" type="hidden" value="baidu"/>
<input autocomplete="off" autofocus="autofocus" class="s_ipt" id="kw" maxlength="255" name="wd" value=""/>
<input autofocus="" class="bg s_btn" id="su" type="submit" value="百度一下"/>
可以看到需要填充的表单就是倒数第二行的内容,于是我们可以按照以下方法填充
browser["wd"] = '早起python'
然后可以用下面的命令打开一个与原始网页内容相同的本地网页,并在表格中填充我们提供的值。
browser.launch_browser()
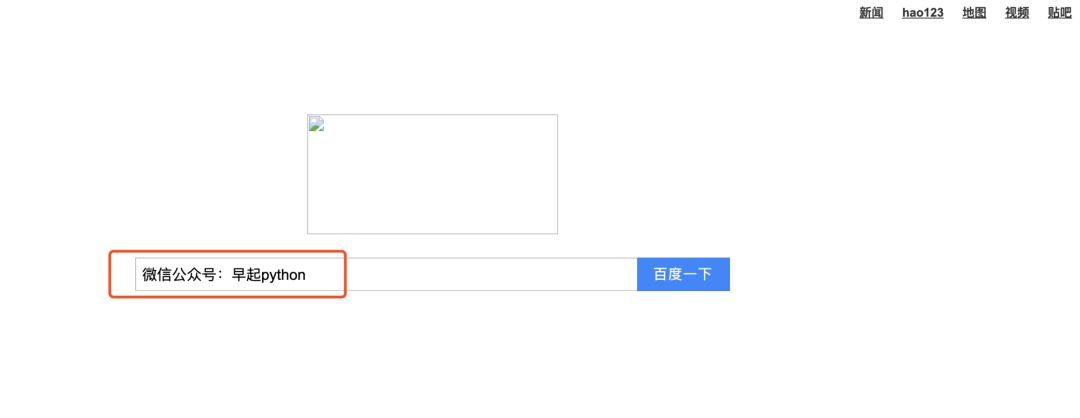
可以看到,搜索框内已经填好了需要搜索的内容,接下来只需要让我们创建出来的浏览器帮我们点击一下就行,执行:
browser.submit_selected()<Response [200]>
返回200代表相应成功,一次模拟点击就实现了。接下来通过browser.get_current_page()就可以查看到返回的页面内容了!
结束语
上面两个例子虽然简单,但是这就是mechanicalsoup的基本工作套路:先创建一个浏览器实例,然后通过这个浏览器去帮你执行你想要的相关操作,甚至还可以在提交之前打开一个本地的可视化页面预览你即将提交的表单内容!还等什么,抓紧去试试吧!

- Python之Scrapy框架Redis实现分布式爬虫详解
- python爬虫的一个常见简单js反爬详解
- 用python3 urllib破解有道翻译反爬虫机制详解
- 详解用python写网络爬虫-爬取新浪微博评论
- python爬虫之BeautifulSoup 使用select方法详解
- python 3.x 爬虫基础---http headers详解
- Python爬虫常见HTTP响应状态码详解
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
- Python 爬虫入门 1 了解爬虫Scrapy
- python 中xpath爬虫实例详解
- Python3爬虫学习之将爬取的信息保存到本地的方法详解
- Python大批量搜索引擎图像爬虫工具详解
- python爬虫系列Selenium定向爬取虎扑篮球图片详解
- Python爬虫入门:爬虫基础了解
- Python爬虫(一)——了解爬虫
- Python爬虫经典案例详解:爬取豆瓣电影写入Excel表格
- python爬虫之Beautifulsoup模块用法详解
- Python 3 爬虫之查询Github上哪些用户名没有被注册
- python爬虫中的cookie详解
- Python爬虫:学爬虫前得了解的事儿