C# 合并和拆分PDF文件
2021-01-21 00:21
1696 查看
一、合并和拆分PDF文件的方式
PDF文件使用了工业标准的压缩算法,易于传输与储存。它还是页独立的,一个PDF文件包含一个或多个“页“,可以单独处理各页,特别适合多处理器系统的工作。PDF文件结构主要可以分为四个部分:首部、文件体、交叉引用表、尾部。PDF操作类库非常多,如下图所示,常用的类库有:Spire.Pdf、iTextSharp。
二、使用 Spire.Pdf 合并和拆分PDF文件
使用 Nuget 添加Spire.Pdf 类库,然后添加如下代码:
1 /// <summary>
2 /// 合并PDF文件
3 /// </summary>
4 /// <param name="files">待合并文件列表</param>
5 /// <param name="outFile">合并生成的文件名称</param>
6 static void SpirePdfMerge(string[] files, string outFile)
7 {
8 var doc = Spire.Pdf.PdfDocument.MergeFiles(files);
9 doc.Save(outFile, FileFormat.PDF);
10 }
11
12 /// <summary>
13 /// 按每页拆分PDF文件
14 /// </summary>
15 /// <param name="inFile">待拆分PDF文件名称</param>
16 static void SpirePdfSplit(string inFile)
17 {
18 var doc = new Spire.Pdf.PdfDocument(inFile);
19 doc.Split("SpirePdf_拆分-{0}.pdf");
20 doc.Close();
21 }
三、使用 iTextSharp 合并和拆分PDF文件
使用 Spire.Pdf 操作PDF文件,简单高效,但生成的PDF文件带有水印,即使使用破解版在第一页还是有水印,我们可以使用 iTextSharp 类库,该类库生成的PDF无水印,具体使用如下:
1 /// <summary>
2 /// 合并PDF文件
3 /// </summary>
4 /// <param name="inFiles">待合并文件列表</par
ad0
am>
5 /// <param name="outFile">合并生成的文件名称</param>
6 static void iTextSharpPdfMerge(List<String> inFiles, String outFile)
7 {
8 using (var stream = new FileStream(outFile, FileMode.Create))
9 {
10 using (var doc = new Document())
11 {
12 using (var pdf = new PdfCopy(doc, stream))
13 {
14 doc.Open();
15 inFiles.ForEach(file =>
16 {
17 var reader = new PdfReader(file);
18 for (int
56c
i = 0; i < reader.NumberOfPages; i++)
19 {
20 var page = pdf.GetImportedPage(reader, i + 1);
21 pdf.AddPage(page);
22 }
23 pdf.FreeReader(reader);
24 reader.Close();
25 });
26 }
27
56c
}
28 }
29 }
30
31 /// <summary>
32 /// 按每页拆分PDF文件
33 /// </summary>
34 /// <param name="inFile">待拆分PDF文件名称</param>
35 static void iTextSharpPdfSplit(string inFile)
36 {
37 using (var reader = new PdfReader(inFile))
38 {
39 // 注意起始页是从1开始的
40 for (int i = 1; i <= new PdfReader(inFile).NumberOfPages; i++)
41 {
42 using (var sourceDocument = new Document(reader.GetPageSizeWithRotation(i)))
43 {
44 var pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream($"iTextSharp_拆分_{i}.pdf", System.IO.FileMode.Create));
45 sourceDocument.Open();
46 var importedPage = pdfCopyProvider.GetImportedPage(reader, i);
47
ad8
pdfCopyProvider.AddPage(importedPage);
48 }
49 }
50 }
51 }
四、测试结果
完整代码如下:
1 using Spire.Pdf;
2 using System;
3 using System.Collections.Generic;
4 using System.IO;
5 using System.Linq;
6 using System.Net.Mime;
7 using System.Text;
8 using System.Threading.Tasks;
9 using iTextSharp.text;
10 using iTextSharp.text.pdf;
11 using PdfDocument = iTextSharp.text.pdf.PdfDocument;
12
13 namespace Pdf
14 {
15 class Program
16 {
17 static void Main(string[] args)
18 {
19 try
20 {
21 SpirePdfMerge(Directory.GetFiles("Merge"), "SpirePdfMerge.pdf");
22 Console.WriteLine("使用 Spire.Pdf 合并文件完成...");
23
24 SpirePdfSplit($"{AppDomain.CurrentDomain.BaseDirectory}Split\\1.pdf");
25 Console.WriteLine("使用 Spire.Pdf 拆分文件完成...");
26
27 iTextSharpPdfMerge(Directory.GetFiles("Merge").ToList(), "iTextSharpPdfMerge.pdf");
28 Console.WriteLine("使用 iTextSharp 合并文件完成...");
29
30 iTextSharpPdfSplit($"{AppDomain.CurrentDomain.BaseDirectory}Split\\2.pdf");
31 Console.WriteLine("使用 iTextSharp 拆分文件完成...");
32
33 }
34 catch (Exception e)
35 {
36 Console.WriteLine(e);
37 }
38 finally
39 {
40 Console.ReadKey();
41 }
42 }
43
44 #region Spire.Pdf
45
46 /// <summary>
47 /// 合并PDF文件
48 /// </summary>
49 /// <param name="files">待合并文件列表</param>
50 /// <param name="outFile">合并生成的文件名称</param>
51 static void SpirePdfMerge(string[] files, string outFile)
52 {
53 var doc = Spire.Pdf.PdfDocument.MergeFiles(files);
54 doc.Save(outFile, FileFormat.PDF);
55 }
56
57 /// <summary>
58 /// 按每页拆分PDF文件
59 /// </summary>
60 /// <param name="inFile">待拆分PDF文件名称</param>
61 static void SpirePdfSplit(string inFile)
62 {
63 var doc = new Spire.Pdf.PdfDocument(inFile);
64 doc.Split("SpirePdf_拆分-{0}.pdf");
65 doc.Close();
66 }
67
68 #endregion
69
70 #region iTextSharp.text.pdf
71
72 /// <summary>
73 /// 合并PDF文件
74 /// </summary>
75 /// <param name="inFiles">待合并文件列表</param>
76 /// <param name="outFile">合并生成的文件名称</param>
77 static void iTextSharpPdfMerge(List<String> inFiles, String outFile)
78 {
79 using (var stream = new FileStream(outFile, FileMode.Create))
80 {
81 using (var doc = new Document())
82 {
83 using (var pdf = new PdfCopy(doc, stream))
84 {
85 doc.Open();
86 inFiles.ForEach(file =>
87 {
88 var reader = new PdfReader(file);
89 for (int i = 0; i < reader.NumberOfPages; i++)
90 {
91 var page = pdf.GetImportedPage(reader, i + 1);
92 pdf.AddPage(page);
93 }
94 pdf.FreeReader(reader);
95 reader.Close();
96 });
97 }
98 }
99
56c
}
100 }
101
102 /// <summary>
103 /// 按每页拆分PDF文件
104 /// </summary>
105 /// <param name="inFile">待拆分PDF文件名称</param>
106 static void iTextSharpPdfSplit(string inFile)
107 {
108 using (var reader = new PdfReader(inFile))
109 {
110 // 注意起始页是从1开始的
111 for (int i = 1; i <= new PdfReader(inFile).NumberOfPages; i++)
112 {
113 using (var sourceDocument = new Document(reader.GetPageSizeWithRotation(i)))
114 {
115 var pdfCopyProvider = new PdfCopy(sourceDocument, new System.IO.FileStream($"iTextSharp_拆分_{i}.pdf", System.IO.FileMode.Create));
116 sourceDocument.Open();
117 var importedPage = pdfCopyProvider.GetImportedPage(reader, i);
118 pdfCopyProvider.AddPage(importedPage);
119 }
120 }
121 }
122 }
123
124 #endregion
125
126 }
127 }
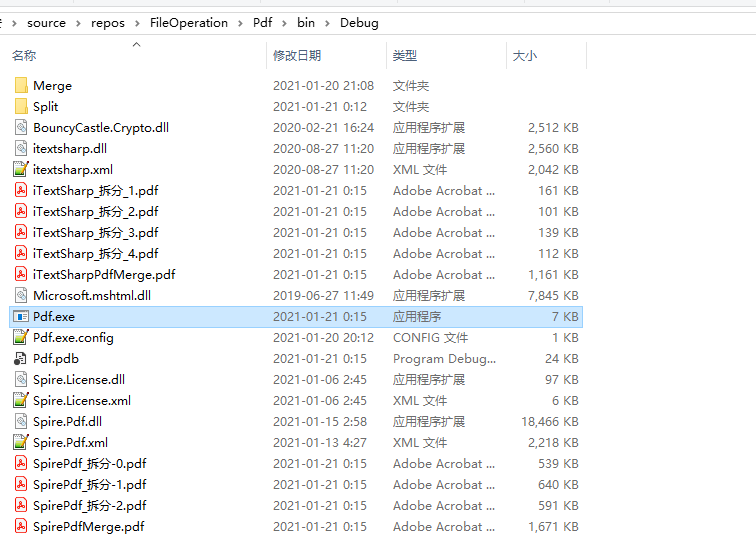
测试效果如下图所示:

相关文章推荐
- C#实现合并及拆分PDF文件的方法
- C# 合并及拆分PDF文件
- C# 合并及拆分PDF文件
- 使用C#创建修改合并PDF文件
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#生成word文档 、word转pdf、合并pdf文件等
- 使用C#创建修改合并PDF文件
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- Ubuntu下命令行方式对PDF文件进行缩放、合并、拆分
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#合并多种格式文件为PDF的方法
- C# 将多个office文件转换及合并为一个PDF文件
- PDF文件拆分合并工具PdfPageTool正式发布,欢迎下载试用
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径
- C#将制定文件夹下的PDF文件合并成一个并输出至指定路径