pandas数据处理
一、查找重复值
既然我们这个系列是对比Excel,那么在Excel里是怎么查找重复值的呢?有很多种方法,这里就简单说一种:条件格式。在【开始】——【条件格式】里选择突出显示重复值,就将重复的值突出显示出来了:
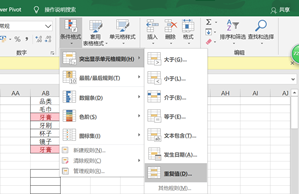
Pandas里如何查找重复值呢?
1、查找所有列
继之前用的短租数据集(后台回复:短租数据,即可获得),duplicated方法查找重复值,和isnull一样,得到的结果是布尔值,如果重复被标记为True,否则为False
# 查看所有列都重复的数据
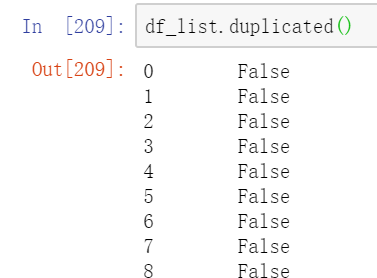
df_list.duplicated()
结果如下,得到的是一个序列,通过True/False来查看哪些行完全重复。
也可以把它具体的位置找出来:
# 定位出所有列都重复的行
df_list[df_list.duplicated()]
结果是一个空行,说明这个数据集里没有所有列都重复的行

2、查找单独列
对重复值的判断有时不需要判断所有列,只需要对某一列进行判断,还是用duplicated方法查找,如查找id列是否重复
# 查找id列是否重复
df_list[df_list.duplicated(["id"])]
结果为空,说明id列是唯一标识。

二、重复值的处理
对重复值的处理,就是删除
在Excel里专门有一个删除重复值的功能,用这个功能就可以将某一列的重复值删除,只保留不重复的值:
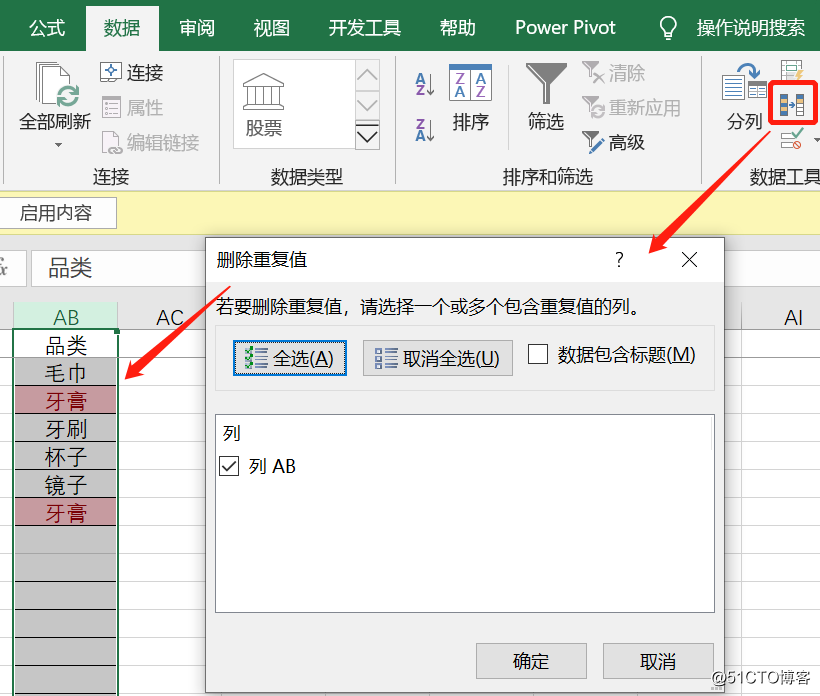
在Panda里用到drop_duplicates方法来删除重复值。
1、所有列去重
对所有列都重复的行去重
# 所有列去重
df_list = df_list.drop_duplicates()
df_list.head()
2、某一列去重
对某一列重复的行去重,添加subset参数
# 某一列去重
df_list.drop_duplicates(subset = "id")
3、某几列去重
对要去重的几列的列名用列表框起来,subset参数名可以不写
# 某几列去重
df_list.drop_duplicates(["id","name"])
4、去重后保留最后一个值
以上去重时默认都是保留第一个重复的值,但如果想要保留最后一个重复的值呢,添加keep参数,让keep = "last"
# 保留最后一个值
df_list.drop_duplicates(["id","name"],keep = "last")
5、查找后定位的方法去重
前面介绍了查找重复值用到的duplicated方法,那么也可以用这个方法直接去重。df_list[df_list.duplicated(["id","name"])]是定位出重复值,加个取反的符号df_list[~df_list.duplicated(["id","name"])]就将不重复的值取出来了,也就是去重了。
# 查找后定位去重
df_list[~df_list.duplicated(["id","name"])]
三、类型转换
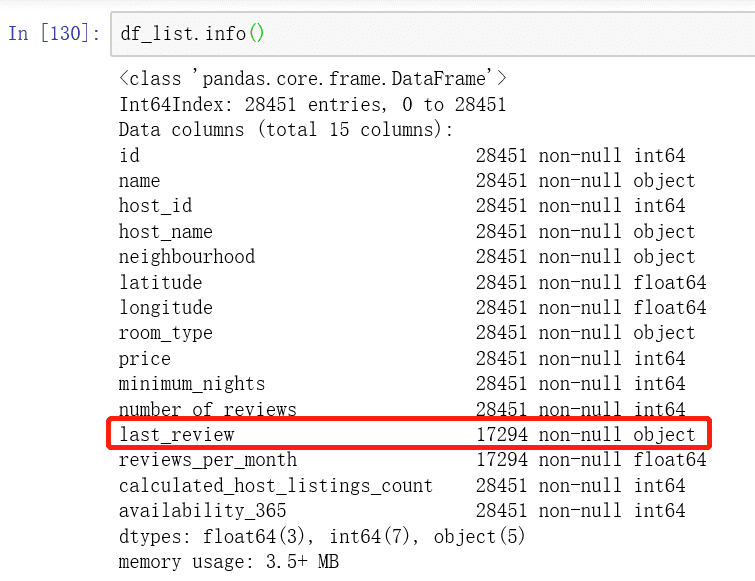
这个案例里last_review字段应该是日期时间的类型,但在这里是字符型展示,因此要把字符型转换成日期时间类型的数据,使用to_datetime方法,它有两个参数,第一个参数是要转换的列,第二个参数是设置日期时间格式。
# 字符转时间
df_list["last_review"] = pd.to_datetime(df_list["last_review"],
format = "%Y/%m/%d")
df_list.info()
结果如下,可以看到这一列已经由原先的字符型转化为了时间型。

类型转换还可以将字符转数值,数值转字符,用到astype(dtype)方法,dtype参数表示要转换的数据类型,整型为int,小数型位float,字符型为str
# 数值转字符
df_list["id"].astype(str).dtype
如把id列的整型转为字符型,可以看到转换话数据类型为Object。

四、字段拆分
发现这里neighbourhood字段是“朝阳区 / Chaoyang ”形式,只想要保留“/”符号前的字段,因此需要对这个字段进行拆分,在Excel里拆分很简单,就用【数据】选项卡中的【分列】功能即可,分割符号选择“/”。
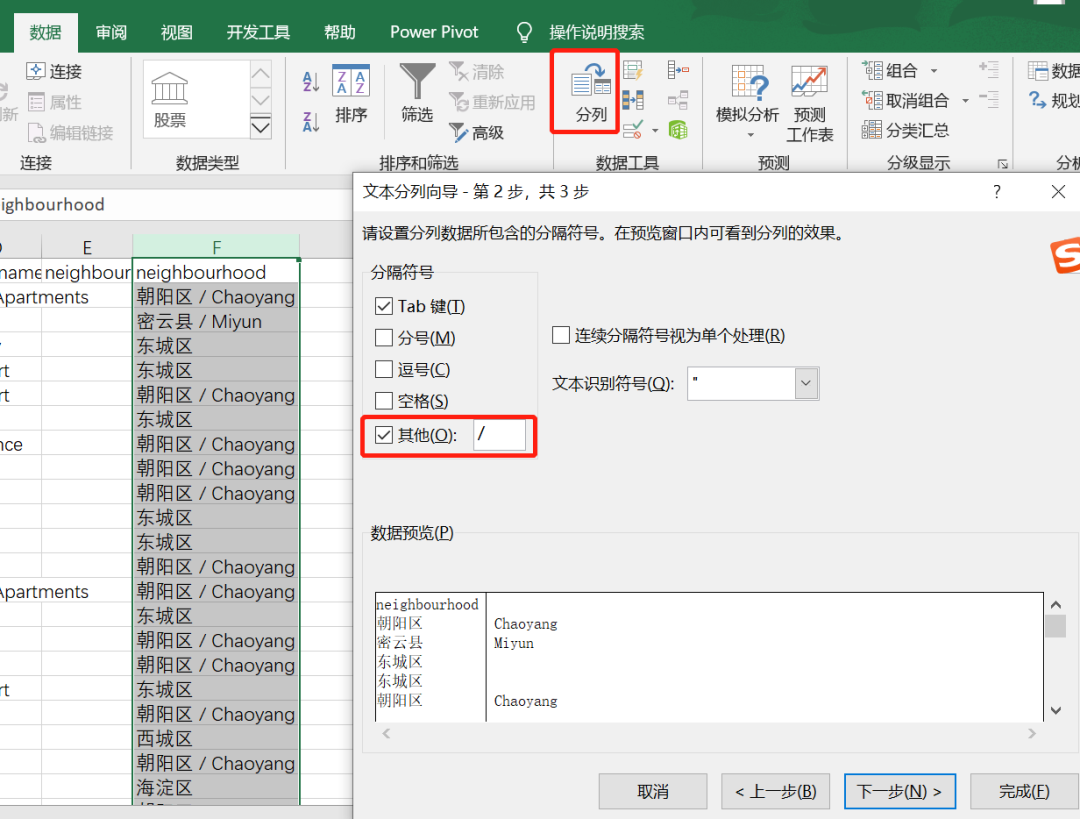
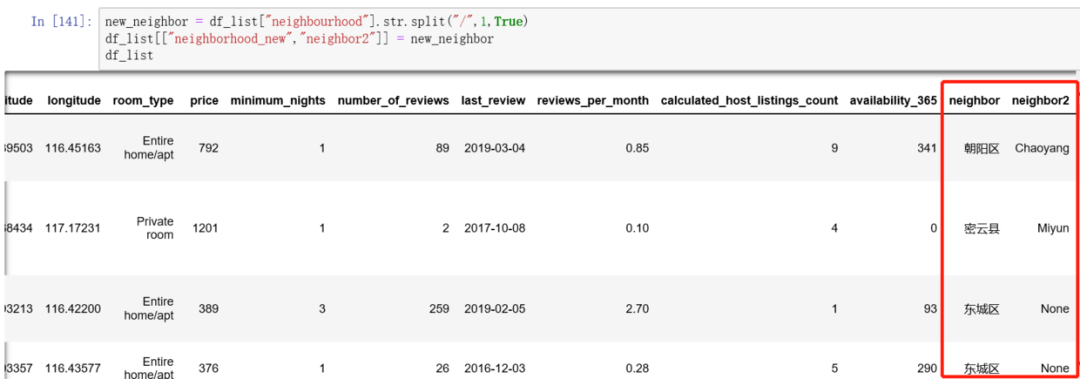
在pandas里我们用split方法来拆分
# 字段拆分
new_neighbor = df_list["neighbourhood"].str.split("/",1,True)
df_list[["neighborhood_new","neighbor2"]] = new_neighbor
df_list
第一个参数是指定分隔符,第二个参数填的是1,表示分割成1+1=2列,第三个参数填True,表示展开为数据框,默认是False,所以一般填True,结果如图
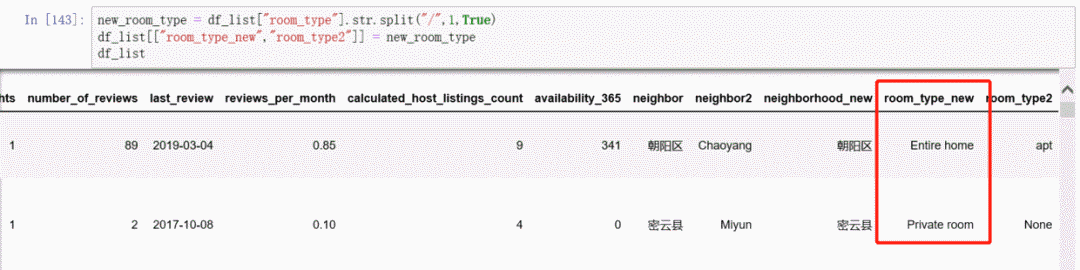
同样地把room_type这个字段也拆分一下
new_room_type = df_list["room_type"].str.split("/",1,True)
df_list[["room_type_new","room_type2"]] = new_room_type
df_list
结果如图:

- Python 数据处理扩展包: pandas 模块的DataFrame介绍(读写数据库的操作)
- pandas 空数据处理和数据过滤
- Pandas数据处理基础6
- 学机器学习,不会数据处理怎么行?—— 二、Pandas详解
- 用 Python 做数据处理必看:12 个使效率倍增的 Pandas 技巧(上下)
- 数据处理 numpy and pandas——004_numpy_array合并
- Pandas数据处理之Pandas的Index对象
- Pandas 数据处理之缺失数据处理
- pandas数据处理-0722
- Python数据处理pandas、numpy等第三方库函数笔记(持续更新)
- 数据处理之Pandas
- pandas数据处理进阶详解
- Pandas数据处理基础5
- Pandas数据处理
- Pandas 数据处理,数据清洗
- Python数据科学手册(3) Pandas数据处理
- 数据处理 numpy and pandas——006_pandas基本介绍
- 数据分析——使用pandas进行数据处理
- Python numpy pandas数据处理2
- pandas (六)数据处理 GroupBy 透视