内联意味着简化?(1) 逃逸分析
有关 JVM 内联(inline)技术有很多说法。毫无疑问,内联可以降低函数调用开销,但更重要的是,当不符合条件时,JVM 会禁用或减少优化。然而,这里还要考虑如何在灵活性与内联的功能性之间取得平衡。在我看来,内联的重要性被高估了。这个系列文章用 JMH 实验评估内联失败对 C2 编译器优化带来的影响。本文是系列的第一篇,介绍内联如何影响逃逸分析及注意事项。
> 译注:在编译进程优化理论中,逃逸分析是一种确定指针动态范围的方法——分析在进程的哪些地方可以访问到指针。Java 没有提供手段直接指定内联方法,通常是在 JVM 运行时完成内联优化。
内联与数据库反范式化类似,是一个把函数调用替换为函数代码的过程。数据库反范式化通过提升数据复制级别、增加数据库大小从而降低 join 操作开销。内联以代码空间为代价,降低函数调用的开销。这种类比其实并不确切:拷贝函数代码到调用的地方,像 C2 这样的编译器能够进行方法内部优化,并且 C2 会积极主动完成优化。众所周知,让内联复杂化有两种办法:设置代码大小(`InlineSmallCode` 选项指定最大允许内联的代码大小,默认2KB)和大量使用多态,还可以调用 JMH `@CompilerControl(DONT_INLINE)` 注解关闭内联机制。
> 译注:数据库反范式化(Database Denormalisation),允许数据冗余或者同样的数据存储于多处。
第一个基准测试是一个刻意设计的示例程序。方法简短,可以在下面的函数式 Java 代码中找到。函数式编程利用了 Monad 函子和 bind 函数。Monad 函子将一般的计算表示为包装类型(Wrapper Type),被包装的操作称为单元函数。bind 函数可以组合函数应用到包装类型。你也可以把它们想象成墨西哥卷饼。Java 函数式编程常见的 Monad 类型有 Either、Try 和 Optional。Either 函子内部包含两个不同类型的实例,Try 函子会产生一个输出或抛出异常,Optional 是 JDK 自带的内建类型。Java 中 Monad 类型的一个缺点是需要实现包装类型,而不只是交给编译器负责。使用过程中存在分配失败的风险。
> 译注:Monad 函子保证返回的永远是一个单层的容器,不会出现嵌套的情况。相关介绍推荐《函数式编程入门教程》阮一峰http://www.ruanyifeng.com/blog/2017/02/fp-tutorial.html
下面的 `Escapee` 接口包含 `map` 方法,返回类型为 `Optional`。通过对未包装类型 `S` 和 `T` 映射安全地将类型 `S` 可能出现的 `null` 值映射为 `Optional<T>`。为了避免因实现不同带来开销的差异,接下来采用三次相同的实现,达到阈值让 Hotspot 放弃对 `escapee` 进行内联调用。
```java
public interface Escapee<T> {
<S> Optional<T> map(S value, Function<S, T> mapper);
}
public class Escapee1<T> implements Escapee<T> {
@Override
public <S> Optional<T> map(S value, Function<S, T> mapper) {
return Optional.ofNullable(value).map(mapper);
}
}
```
基准测试能够模拟调用一种到四种实现。输入 `null` 时,程序会选择不同分支执行,因此预期产生不同的测试结果。为了屏蔽不同分支执行开销的差异,在每个分支都调用了相同的函数分配 `Instant` 对象。这里没有考虑分支不可预测的情况,因为这不是本文的重点。选择 `Instant.now()` 是因为返回值是 volatile 且不规范的(impure),因此调用过程不会受其他优化影响。
```java
@State(Scope.Benchmark)
public static class InstantEscapeeState {
@Param({"ONE", "TWO", "THREE", "FOUR"})
Scenario scenario;
@Param({"true", "false"})
boolean isPresent;
Escapee<Instant>[] escapees;
int size = 4;
String input;
@Setup(Level.Trial)
public void init() {
escapees = new Escapee[size];
scenario.fill(escapees);
input = isPresent ? "" : null;
}
}
// 译注:Blackhole 在 JMH 中定义,cosume 输入的 value,不做处理
// 避免对给定值的计算结果消除 dead-code
@Benchmark
@OperationsPerInvocation(4)
public void mapValue(InstantEscapeeState state, Blackhole bh) {
for (Escapee<Instant> escapee : state.escapees) {
bh.consume(escapee.map(state.input, x -> Instant.now()).orElseGet(Instant::now));
}
}
```
基于对 C2 编译器内联功能的了解,期望场景 THREE 和场景 FOUR 不做内联优化,而场景 ONE 会内联,场景 TWO 有条件内联。可使用 `-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining` 选项输出结果。参见 Aleksey Shipilёv 的[权威文章][1]。
[1]:https://shipilev.net/blog/2015/black-magic-method-dispatch/
基准测试使用下列参数运行。首先,禁用分层编译绕过 C1 编译器。接着,设置更大的 heap 避免测试结果受到垃圾回收暂停影响。最后,选择低开销 `SerialGC` 最大限度地减少 Write Barrier 带来的干扰。
```shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee.csv -prof gc
-jvmArgs="-XX:-TieredCompilation -XX:+UseSerialGC -mx8G" EscapeeBenchmark.mapValue$
```
> 译注:Write Barrier。在垃圾回收过程中,Write Barrier 指每次存储操作之前编译器调用的代码以保持 Generational Invariant。
虽然在吞吐量方面几乎没有绝对差异,预期发生内联场景的吞吐量略高于不发生内联时的吞吐量,但是实际的结果非常有趣。
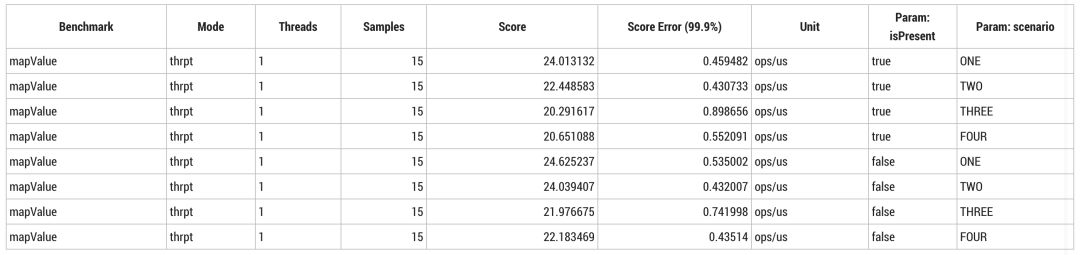
当输入 `null` 时,Megamorphic 内联实现会稍快一些,不加入其他优化可以很容易做到这一点。当输入总是 `null`,或当前只有一种实现(场景 ONE)并且输入不为 `null` 时,标准(normalised)分配速度都是 24B/op。输入非 `null` 时,过半的测试结果为 40B/op。
> 译注:Megamorphic inline caching(超对称内联缓存)。内联缓存技术(Inline Caching)包括 Monomorphic、Polymorphic、Megamorphic三类,通过为特定调用创建代码执行 first-level 方法查找可实现 Megamorphic 内联缓存。
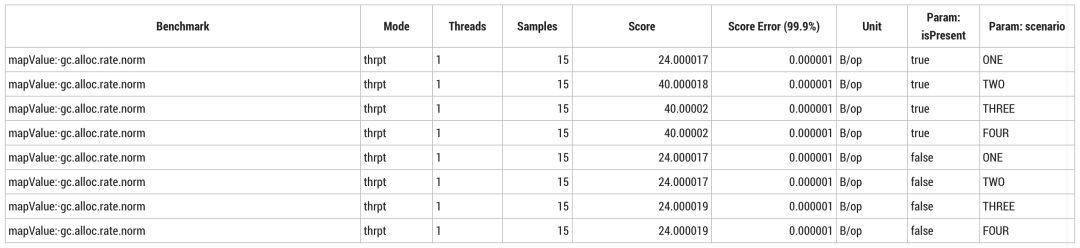
当使用 SerialGC 这样简单的垃圾收集器时,24B/op 表示 `Instant` 类的实例大小,包括8字节1970年到现在的秒数、4字节纳秒数以及12字节对象头。这种情况不会分配包装类型。40B/op 包括 `Optional` 占用的16字节,其中12字节存储对象头,4字节存储压缩过的 `Instance` 对象引用。当方法无法内联优化或者在条件语句中偶尔出现分配时,编译器会放弃内联。在场景 TWO 中,两种实现会引入一个条件语句,这意味着每个操作都为 `optional` 分配了16字节。
这些信息在上面的基准测试中表现得不够明显,几乎都被分配24字节 `Instant` 对象掩盖住了。为了突出差异,我们把后台分配从基准测试中分离出来,再一次跟踪相同的指标。
```java
@State(Scope.Benchmark)
public static class StringEscapeeState {
@Param({"ONE", "TWO", "THREE", "FOUR"})
Scenario scenario;
@Param({"true", "false"})
boolean isPresent;
Escapee<String>[] escapees;
int size = 4;
String input;
String ifPresent;
String ifAbsent;
@Setup(Level.Trial)
public void init() {
escapees = new Escapee[size];
scenario.fill(escapees);
ifPresent = UUID.randomUUID().toString();
ifAbsent = UUID.randomUUID().toString();
input = isPresent ? "" : null;
}
}
@Benchmark
@OperationsPerInvocation(4)
public void mapValueNoAllocation(StringEscapeeState state, Blackhole bh) {
for (Escapee<String> escapee : state.escapees) {
bh.consume(escapee.map(state.input, x -> state.ifPresent).orElseGet(() -> state.ifAbsent));
}
}
```
```shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee-string.csv -prof gc
-jvmArgs="-XX:-TieredCompilation -XX:+UseSerialGC -mx8G" EscapeeBenchmark.mapValueNoAllocation
```
即使看起来非常简单的实际调用,比如分配时间戳,取消操作也足以减少内联失败的情况。而加入 no-op 的虚拟调用也会让内联失败的情况变得严重。场景 ONE 和场景 TWO 测试结果比其他更快,因为无论输入是否为 `null` 至少都消除了虚函数调用。
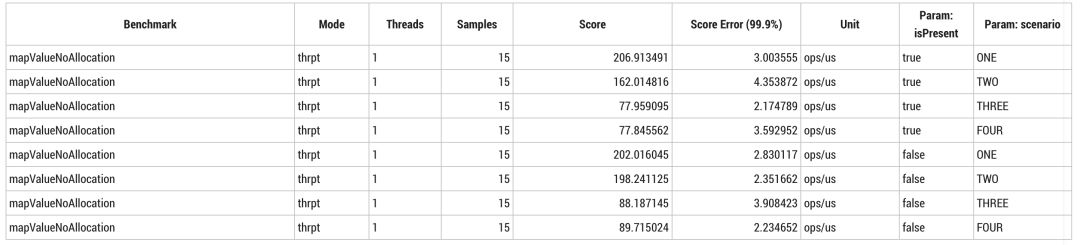
很容易想到内存分配被缩减了,只有在使用多态情况下会超过逃逸分析的限值。场景 ONE 不发生分配,一定是逃逸分析起效了。场景 TWO,由于存在条件内联,每次用非 `null` 调用时都会分配16字节 `Optional`;当输入一直为 `null` 时分配减少。然而,内联在场景 THREE 和场景 FOUR 中不起作用,每次调用会额外分配16字节。这个分配与内联无关,变量12字节对象头以及4字节压缩后的 String 引用。你会多久检查一次自己的基准测试,确保测量信息与设想的一致?
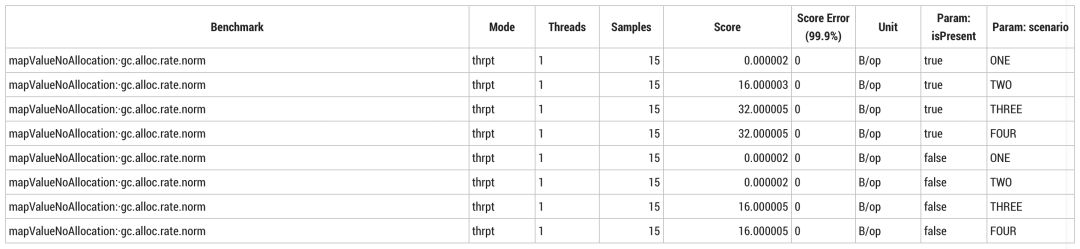
这不是实际编程中可以实用的技术,而是当方法传入 `null` 值,无论是虚函数或内联函数都可以更好地减少内存分配。实际上,`Optional.empty()` 总是返回相同实例,因此从测试开始就没有分配任何内存。
虽然上面通过设计的示例强调了内联失败带来的影响,但值得注意的是,与分配实例和使用不同垃圾回收器带来的开销差异相比内联失败的影响要小得多。一些开发人员似乎没有意识到这一类开销。
```java
@State(Scope.Benchmark)
public static class InstantStoreEscapeeState {
@Param({"ONE", "TWO", "THREE", "FOUR"})
Scenario scenario;
@Param({"true", "false"})
boolean isPresent;
int size = 4;
String input;
Escapee<Instant>[] escapees;
Instant[] target;
@Setup(Level.Trial)
public void init() {
escapees = new Escapee[size];
target = new Instant[size];
scenario.fill(escapees);
input = isPresent ? "" : null;
}
}
@Benchmark
@OperationsPerInvocation(4)
public void mapAndStoreValue(InstantStoreEscapeeState state, Blackhole bh) {
for (int i = 0; i < state.escapees.length; ++i) {
state.target[i] = state.escapees[i].map(state.input, x -> Instant.now()).orElseGet(Instant::now);
}
bh.consume(state.target);
}
```
用两种模式运行相同的基准测试:
```shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee-store-serial.csv
-prof gc -jvmArgs="-XX:-TieredCompilation -XX:+UseSerialGC -mx8G" EscapeeBenchmark.mapAndStoreValue$
```
```shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee-store-g1.csv
-prof gc -jvmArgs="-XX:-TieredCompilation -XX:+UseG1GC -mx8G" EscapeeBenchmark.mapAndStoreValue$
```
改变垃圾回收器触发 Write Barrier(对串行回收器来说很简单,对 G1 来说很复杂)带来的开销与内联失败的开销相当。注意:这并不代表垃圾回收器开销不可接受。
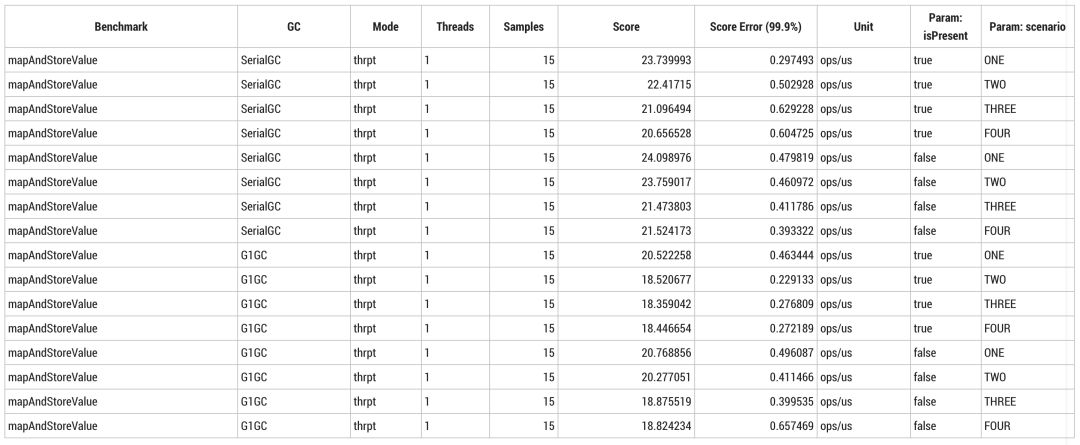
内联优化使逸出分析成为可能,但是仅在只有一种实现时起效。即使出现很小的内存分配也会降低边际效益也会下降,但随着内存分配减少边际效益会逐渐增大。这种差异甚至会比某些垃圾回收器中 Write Barrier 带来的开销更小。基准测试可以在 [github] 上找到,本文的测试环境为 OpenJDK 11+28,操作系统为 Ubuntu 18.04.2 LTS。
[2]:https://github.com/richardstartin/runtime-benchmarks/tree/master/src/main/java/com/openkappa/runtime/inlining/escapee
这种分析也许是肤浅的,许多优化比依赖内联技术的逸出分析更强大。下一篇将讨论类似 hash code 这样的简化操作(Reduction Operation)内联可能带来的好处,或者没有好处。

- 逃逸分析
- 什么是逃逸分析(Escape Analysis)?
- Java内存对象的逃逸分析
- JVM优化之逃逸分析(Escape Analysis)
- 敏捷开发绩效管理之七:敏捷开发生产率(下)(简化功能点分析,NESMA,两级简化)
- JVM的栈上分配与逃逸分析(Escape Analysis)
- Java逃逸分析
- Go 语言机制之逃逸分析
- microwindows代码分析 (一)c/s模型的简化
- JVM的栈上分配与逃逸分析
- 逃逸分析
- 敏捷开发绩效管理之七:敏捷开发生产率(下)(简化功能点分析,NESMA,两级简化)
- 查漏补缺,JVM优化篇,锁消除+逃逸分析
- 深入理解Java中的逃逸分析
- 逃逸分析(Escape Analysis)
- JVM优化手段 - 逃逸分析
- 敏捷开发绩效管理之七:敏捷开发生产率(下)(简化功能点分析,NESMA,两级简化)
- 黑马程序员--10.网络编程--07.【C_S编程中服务器端和客户端的读写流】【C_S常见的“双卡”现象和解决--TCP文本转换器示例】【TCP文本转换器客户端和服务器端循环结束分析】【网络流简化】
- jQuery源码逐行分析学习01(jQuery的框架结构简化)
- spss统计分析软件IBM SPSS Statistics 25 for Mac,简化您的数据分析和报表制作