jQuery选择器Sizzle原理分析(下)
曾经红级一时的jQuery还记得吗?拥有号称当时业界最快的DOM选择器Sizzle,那么为什么他能自称是最快呢?让我们来分析一下Sizzle.js的源码,了解他的设计精妙之处。虽然MVVM已经成为现在的主流,但是了解历史能让我们更了解现在,也为以后更好的设计和开发框架提供的参考。
作者:朱胜--腾讯web前端工程师
@IMWeb前端社区
好了有了之前的词法分析过程,现在我们来到select函数来,这个函数的整体流程,前面也大概说过:
1. 先做词法分析获得token列表
2. 如果有种子集合直接到编译过程
3. 如果没有种子集合并且是单组选择符(没有逗号)
(1)尝试缩小上下文:如果第一个token是ID选择符,则会执行Expr.find["ID"]的方法来找到这个上下文,以后所有的查询都是在这个上下文进行,然后把第一个ID选择符剔除。
(2)尝试寻找种子集合:从右开始往左分析token,如果遇到关系选择符(> + ~ 空)终止循环,否则通过Expr.find的方法尝试寻找符合条件的DOM集合,如果找到了就讲种子集合保存起来。
4. 进入到编译过程
这里面需要讲解下为何要进行筛选的工作,前面也说过,目的就是为了尽量缩小查询范围,首先缩小上下文范围,然后缩小种子集合范围,因为从右向左查询的过程更快,所以我们是从后面开始搜索种子集合,搜索到之后,后面所有的分析过程都是在这些种子集合基础之上进行的。
Expr.find = {
'ID' : context.getElementById,
'CLASS' : context.getElementsByClassName,
'NAME' : context.getElementsByName,
'TAG' : context.getElementsByTagName
}
Expr.find返回一个函数,这个函数根据当前参数进行验证,看看是否是指定类型的节点,可以查验ID,CLASS,NAME和TAG等等。我们以class为例:

Expr.find["CLASS"]返回一个函数,这个函数有两个参数,第一个参数className,第二个参数context,在select里面就是通过这个函数来查询指定className的DOM集合,找到以后就是seed种子集合。
select源码如下:
走到这里我们发现,我们现在已经拥有了哪些信息:token列表,缩小的context和种子集合,那么剩下的事情是不是对种子集合的每个元素再和token列表一一校验,留下符合条件的,删除不符合条件的是不是查询就完成了?
正常看起来是这样的,我们对每个种子进行边解析边分析的过程符合要求,但是Sizzle做了更进一步的处理,通过空间换时间的方式,提高了查询性能,他采用了一种叫先编译后执行的过程。首先把所有的token元素生成一个嵌套的函数,然后再针对种子集合,去执行这个函数,把符合条件的留下来,由于函数是通过闭包的方式来保存,所以当同一个选择符查询时,可以直接执行函数来查询,从而加快了查询的性能,而不用每次从头解析。
这个函数包括两种情况:
1. 关系选择器:如果token是关系选择器,则生成函数的时候需要同上一个选择器共同生成。
2. 非关系选择器:如果是非关系选择器,则直接判断种子是否满足条件即可。
比如 div > a 我们生成函数1 父节点是否是div 函数2 本身是否是a标签 函数1+函数2 就是我们最终生成的Match匹配函数,对每个种子进行执行Match匹配函数即可。
我们看看compile的整体思路:
1. 从缓存查询是否已经编译过,有的话直接拿出来
2. 判断是否tokenize过,没有的话,补一下
3. 对group的每个元素进行matcherFromTokens方法,获得该token组的组合函数,如果是包含伪类,则添加到setMatchers数组,否则添加到elementMatchers数组
4. 最后对setMatchers和elementMatchers执行matcherFromGroupMatchers方法。
这里要解释下matcherFromTokens和matcherFromGroupMatchers方法,生成最终的包含非伪类和伪类的最终匹配函数:
matcherFromTokens: 将一组token数组转换为一个Match匹配函数,比如div > a 就生成一个包含两个函数的Match匹配函数。
matcherFromGroupMatchers:由于存在伪类和非伪类选择符两种情况,这个函数的目的是融合这两种情况,最终生成一个超级匹配函数。
下面介绍下matcherFromTokens这个方法:输入参数是tokens,然后对每个token进行处理,这里需要了解一个知识点:
非伪类的选择符 有普通选择符和关系选择符两种,关系选择符包括以下几种情况:> 空格 + ~
保存在Expr.relative对象中
> : 表示是父子关系 对应DOM属性parentNode 是元素的第一个节点所以 first为true
空格:表示是后代关系 对应DOM属性parentNode
+:表示附近兄弟关系 对应DOM属性previousSibling 是元素的第一个节点所以 first为true
~:表示普通兄弟关系 对应DOM属性previousSibling
在matcherFromTokens方法中就会对非关系型和关系型分部处理:
matchers是存放各个选择符过滤函数的数组
1. 非关系型运算符:把该类型的过滤函数拷贝一份push到matchers数组中即可,比如前面#div_test > span input[checked=true]中的 input span等等
2. 关系型运算符:把当前的关系选择符和前面的选择符一起共同组成一个过滤函数,push到matchers数组中。
最后把matchers数组统一通过elementMatcher函数来生成一个最终的过滤函数
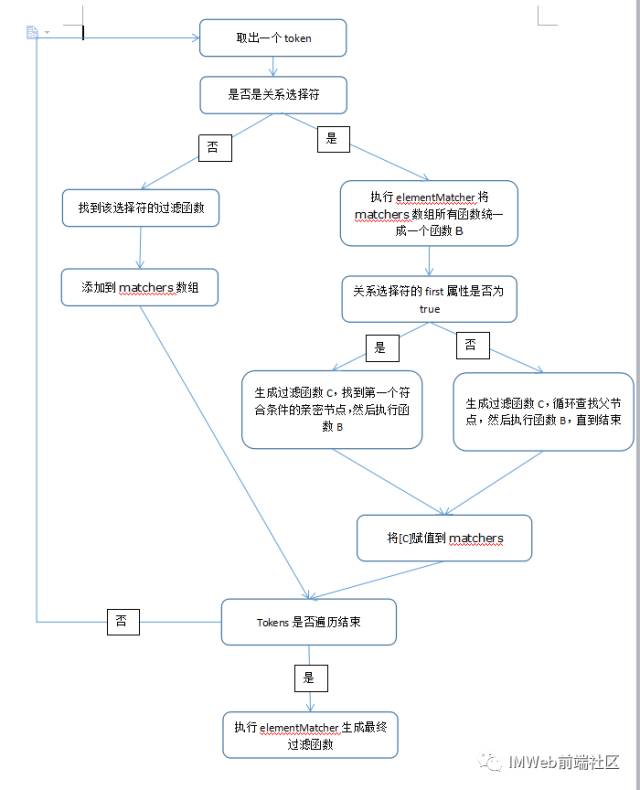
elementMatcher方法的作用是将一个函数数组,生成一个过滤函数,这个函数会遍历执行各个函数
addCombinator为关系选择符生成过滤函数,将上一个选择符和关系选择符联合起来查询
有了上面两个函数的支持后,matcherFromTokens的作用就遍历tokens数组
下面我们来看看Expr.filter,前面说过他总共有
ID:ID选择符
Class:类选择符
Tag:标签选择符
ATTR:属性标签
CHILD:包括(only|first|last|nth|nth-last)-(child|of-type)等等对子类的标签
PSEUDO:其他伪类选择符
这几种类型,那Expr.filter里面包含的分别是各种类型的过滤函数,比如Expr.filter["ID"]

这个函数的作用就是通过参数ID返回新的函数FUNC_ID,这个函数参数传入一个DOM元素(其实就是之前的seed集合),判断这个DOM元素的ID是否是指定ID,也就是判断seed集合是否是选择符指定的ID元素。

TAG的函数的作用就是通过参数nodeNameSelector生成一个新的函数FUNC_NODE,这个函数判断传入的DOM元素是否是指定的nodeNameSelector类型标签。
总之就是一组过滤函数,判断DOM节点是否符合选择符的条件,满足就留下,否则剔除掉。
终于要对我们的Seed进行过滤了!前面我们通过matcherFromTokens方法生成了一个包含所有选择符过滤函数的统一过滤函数,下面还需要对seed集合进行挨个过滤,就是matcherFromGroupMatchers要做的事情:
matcherFromGroupMatchers函数主要针对伪类和非伪类综合处理,我们暂不考虑伪类情况matcherFromGroupMatchers可以简化许多:
可以看到整个代码最关键的地方就是有一个双层循环,把所有的seed集合拿出来对所有的过滤函数进行执行,把返回true的集合保留下来,就是我们最终要查询的结果:


至此,$("#div_test > span input[checked=true]") 从头到尾的流程就基本走通了。为此我们可以得出几个优化选择器的结论:
1. 尽量在选择器以ID来查询,或者至少开头是以ID来查询:这样可以快速缩小查询的根节点。
2. 在Classe前面使用Tags:因为getElementsByTagName方法是第二快的查询方法
3. 在选择器最后尽量指定seed元素(千万不能用*):因为Sizzle会从最后的选择符开始寻找符合条件的seed集合
4. 尽量使用父子查询来代替后代查询:后代查询需要循环查找,父子查询范围小很多。
5. 缓存已查询的jQuery对象:通过空间换时间的方式,不要每次都要执行过滤函数。
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理续(伪类选择器“PSEUDO”和子伪类选择器"CHILD"原子选择器详解)
- 「理论」jQuery选择器Sizzle原理分析(上)
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理续(伪类分割器setMatcher)
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理续(伪类选择器“PSEUDO”和子伪类选择器"CHILD"原子选择器详解)...
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理续(伪类分割器setMatcher)...
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理
- JQuery - Sizzle选择器引擎原理分析
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理续(伪类选择器“PSEUDO”和子伪类选择器"CHILD"原子选择器详解)
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——编译原理
- jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——一些有用的Sizzle API
- jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——总结与性能分析
- jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理
- jQuery源码分析之sizzle选择器详解
- jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——一些有用的Sizzle API
- jQuery源码分析随笔之Sizzle选择器
- jQuery源码剖析(七)——Sizzle选择器引擎之词法分析
- jQuery选择器源码解读(六):Sizzle选择器匹配逻辑分析