深入讲解拉链表,还怕面试官问?
前言
今天给大家分享一个面试中经常会被问到的
拉链表,我在上篇文章中提出来一个需求如果不知道的请去→数仓缓慢变化维深层讲解查看,好,废话不多说我们直接开始。提出的问题会在末尾讲解。

一、拉链表介绍(百度百科)
拉链表:维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的客户记录
二、拉链表场景
数据仓库的数据模型设计过程中,经常会遇到这样的需求:
- 表中的部分字段会被update,例如:用户的地址,产品的描述信息,品牌信息等等;
需要查看某一个时间点或者时间段的历史快照信息
,例如:查看某一个产品在历史某一时间点的状态 查看某一个用户在过去某一段时间内,更新过几次等等变化的比例和频率不是很大
,例如:总共有1000万的会员,每天新增和发生变化的有10万左右
三、商品数据案例
需求:商品表:
| 列名 | 类型 | 说明 |
|---|---|---|
| goods_id | varchar(50) | 商品编号 |
| goods_status | varchar(50) | 商品状态(待审核、待售、在售、已删除) |
| createtime | varchar(50) | 商品创建日期 |
| modifytime | varchar(50) | 商品修改日期 |
2019年12月20日的数据如下所示:
| goods_id | goods_status | createtime | modifytime |
|---|---|---|---|
| 001 | 待审核 | 2019-12-20 | 2019-12-20 |
| 002 | 待售 | 2019-12-20 | 2019-12-20 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 |
| 004 | 已删除 | 2019-12-20 | 2019-12-20 |
商品的状态,会随着时间推移而变化,我们需要将商品的所有变化的历史信息都保存下来。如何实现呢?
方案一: 快照每一天的数据到数仓(图解)
该方案为:
- 每一天都保存一份全量,将所有数据同步到数仓中(
我这里就使用MySQL操作的
) - 很多记录都是重复保存,没有任何变化
12月20日(4条数据)
| goods_id | goods_status | createtime | modifytime |
|---|---|---|---|
| 001 | 待审核 | 2019-12-18 | 2019-12-20 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 |
12月21日(10条数据)
| goods_id | goods_status | createtime | modifytime |
|---|---|---|---|
| 以下为12月20日快照数据 | |||
| 001 | 待审核 | 2019-12-18 | 2019-12-20 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 |
| 以下为12月21日快照数据 | |||
| 001 | 待售(从待审核到待售) | 2019-12-18 | 2019-12-21 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 |
| 005(新商品) | 待审核 | 2019-12-21 | 2019-12-21 |
| 006(新商品) | 待审核 | 2019-12-21 | 2019-12-21 |
12月22日(18条数据)
| goods_id | goods_status | createtime | modifytime |
|---|---|---|---|
| 以下为12月20日快照数据 | |||
| 001 | 待审核 | 2019-12-18 | 2019-12-20 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 |
| 以下为12月21日快照数据 | |||
| 001 | 待售(从待审核到待售) | 2019-12-18 | 2019-12-21 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 |
| 005 | 待审核 | 2019-12-21 | 2019-12-21 |
| 006 | 待审核 | 2019-12-21 | 2019-12-21 |
| 以下为12月22日快照数据 | |||
| 001 | 待售 | 2019-12-18 | 2019-12-21 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 |
| 003 | 已删除(从在售到已删除) | 2019-12-20 | 2019-12-22 |
| 004 | 待审核 | 2019-12-21 | 2019-12-21 |
| 005 | 待审核 | 2019-12-21 | 2019-12-21 |
| 006 | 已删除(从待审核到已删除) | 2019-12-21 | 2019-12-22 |
| 007 | 待审核 | 2019-12-22 | 2019-12-22 |
| 008 | 待审核 | 2019-12-22 | 2019-12-22 |
方案一: MySQL到,MySQL数仓代码实现
MySQL初始化
- 在MySQL中
zw
库和商品表
用于到原始数据层
-- 创建数据库
create database if not exists zw;
-- 创建商品表
create table if not exists `zw`.`t_product`(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50) -- 商品修改时间
);
- 在MySQL中创建ods和dw层
模拟数仓
-- ods创建商品表
create table if not exists `zw`.`ods_t_product`(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50), -- 商品修改时间
cdat varchar(10) --模拟hive分区
)default character set = 'utf8'; ;
-- dw创建商品表
create table if not exists `zw`.`dw_t_product`(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50), -- 商品修改时间
cdat varchar(10) -- 模拟hive分区
)default character set = 'utf8'; ;
增量导入12月20号数据
- 原始数据导入12月20号数据(4条)
insert into `zw`.`t_product`(goods_id, goods_status, createtime, modifytime) values
('001', '待审核', '2019-12-18', '2019-12-20'),
('002', '待售', '2019-12-19', '2019-12-20'),
('003', '在售', '2019-12-20', '2019-12-20'),
('004', '已删除', '2019-12-15', '2019-12-20');
注意:
由于我这里使用的MySQL来模拟的数仓在这里偷个懒直接使用insert into的方式导入数据,在企业中可能会使用hive来做数仓使用kettle 或者sqoop或datax等来同步数据
# 从原始数据层导入到ods 层
insert into zw.ods_t_product
select *,'20191220' from zw.t_product ;
# 从ods同步到dw层
insert into zw.dw_t_product
select * from zw.ods_t_product where cdat='20191220';
增量导入12月21数据
- 原始数据层导入12月21日数据(6条数据)
UPDATE `zw`.`t_product` SET goods_status = '待售', modifytime = '2019-12-21' WHERE goods_id = '001';
INSERT INTO `zw`.`t_product`(goods_id, goods_status, createtime, modifytime) VALUES
('005', '待审核', '2019-12-21', '2019-12-21'),
('006', '待审核', '2019-12-21', '2019-12-21');
- 将数据导入到ods层与dw层
# 从原始数据层导入到ods 层
insert into zw.ods_t_product
select *,'20191221' from zw.t_product ;
# 从ods同步到dw层
insert into zw.dw_t_product
select * from zw.ods_t_product where cdat='20191221';
- 查看dw层的运行结果
select * from zw.dw_t_product where cdat='20191221';
增量导入12月22日数据
- 原始数据层导入12月22日数据(6条数据)
UPDATE `zw`.`t_product` SET goods_status = '已删除', modifytime = '2019-12-22' WHERE goods_id = '003';
UPDATE `zw`.`t_product` SET goods_status = '已删除', modifytime = '2019-12-22' WHERE goods_id = '006';
INSERT INTO `zw`.`t_product`(goods_id, goods_status, createtime, modifytime) VALUES
('007', '待审核', '2019-12-22', '2019-12-22'),
('008', '待审核', '2019-12-22', '2019-12-22');
- 将数据导入到ods层与dw层
# 从原始数据层导入到ods 层
insert into zw.ods_t_product
select *,'20191222' from zw.t_product ;
# 从ods同步到dw层
insert into zw.dw_t_productpeizhiwenjian
select * from zw.ods_t_product where cdat='20191222';
- 查看dw层的运行结果
select * from zw.dw_t_product where cdat='20191222';
从上述案例,可以看到:
表
每天保留一份
全量,每次全量中会保存
很多不变的信息,如果数据量很大的话,对存储是极大的浪费
可以讲表设计为
拉链表,既能满足反应数据的历史状态,又可以最大限度地节省存储空间。
方案二: 使用拉链表保存历史快照(思路/图解)
- 拉链表不存储冗余的数据,只有某
行的数据发生变化,才需要保存下来
,相比每次全量同步会节省存储空间 - 能够查询到历史快照
- 额外的增加了两列(
dw_start_date
、dw_end_date
),为数据行的生命周期
12月20日商品拉链表的数据:
| goods_id | goods_status | createtime | modifytime | dw_start_date | dw_end_date |
|---|---|---|---|---|---|
| 001 | 待审核 | 2019-12-18 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
12月20日的数据是全新的数据导入到dw表
- dw_start_date表示某一条数据的生命周期起始时间,即数据从该时间开始有效(即
生效日期
) - dw_end_date表示某一条数据的生命周期结束时间,即数据到这一天(不包含)(即
失效日期
) - dw_end_date为
9999-12-31
,表示当前这条数据是最新的数据,数据到9999-12-31才过期
12月21日商品拉链表的数据
| goods_id | goods_status | createtime | modifytime | dw_start_date | dw_end_date |
|---|---|---|---|---|---|
| 001 | 待审核 | 2019-12-18 | 2019-12-20 | 2019-12-20 | 2019-12-21 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 001(变) | 待售 | 2019-12-18 | 2019-12-21 | 2019-12-21 | 9999-12-31 |
| 005(新) | 待审核 | 2019-12-21 | 2019-12-21 | 2019-12-21 | 9999-12-31 |
12月21日商品拉链表的数据
- 拉链表中没有存储冗余的数据,(
只要数据没有变化,无需同步
) - 001编号的商品数据的状态发生了变化(
从待审核
→待售
),需要将原有的dw_end_date从9999-12-31变为2019-12-21,表示待审核状态,在2019/12/20(包含) - 2019/12/21(不包含)
有效 - 001编号新的状态重新保存了一条记录,dw_start_date为2019/12/21,dw_end_date为9999/12/31
- 新数据005、006、dw_start_date为2019/12/21,dw_end_date为9999/12/31
12月22日商品拉链表的数据
| goods_id | goods_status | createtime | modifytime | dw_start_date | dw_end_date |
|---|---|---|---|---|---|
| 001 | 待审核 | 2019-12-18 | 2019-12-20 | 2019-12-20 | 2019-12-21 |
| 002 | 待售 | 2019-12-19 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 003 | 在售 | 2019-12-20 | 2019-12-20 | 2019-12-20 | 2019-12-22 |
| 004 | 已删除 | 2019-12-15 | 2019-12-20 | 2019-12-20 | 9999-12-31 |
| 001 | 待售 | 2019-12-18 | 2019-12-21 | 2019-12-21 | 9999-12-31 |
| 005 | 待审核 | 2019-12-21 | 2019-12-21 | 2019-12-21 | 9999-12-31 |
| 006 | 待审核 | 2019-12-21 | 2019-12-21 | 2019-12-21 | 9999-12-31 |
| 003(变) | 已删除 | 2019-12-20 | 2019-12-22 | 2019-12-22 | 9999-12-31 |
| 007(新) | 待审核 | 2019-12-22 | 2019-12-22 | 2019-12-22 | 9999-12-31 |
| 008(新) | 待审核 | 2019-12-22 | 2019-12-22 | 2019-12-22 | 9999-12-31 |
12月22日商品拉链表的数据
- 003编号的商品数据的状态发生了变化(
从在售→已删除
),需要将原有的 dw_end_date从9999-12-31变为2019-12-22,表示在售状态,在2019/12/20(包含) - 2019/12/22(不包含) 有效 - 003编号新的状态重新保存了一条记录,dw_start_date为2019/12/22,dw_end_date为9999/12/31
- 新数据007、008、dw_start_date为2019/12/22,dw_end_date为9999/12/31
方案二: 拉链表快照代码实现
操作流程:
- 在原有dw层表上,添加额外的两列
- 只同步当天修改的数据到ods层
- 拉链表算法实现
- 拉链表的数据为:当天最新的数据 UNION ALL 历史数据
代码实现:
- 在MySQL中
zw
库和商品表
用于到原始数据层
-- 创建数据库
create database if not exists zw;
-- 创建商品表
create table if not exists `zw`.`t_product_2`(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50) -- 商品修改时间
)default character set = 'utf8';
- 在MySQL中创建ods和dw层
模拟数仓
-- ods创建商品表
create table if not exists `zw`.`ods_t_product2`(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50), -- 商品修改时间
cdat varchar(10) -- 模拟hive分区
)default character set = 'utf8';
-- dw创建商品表
create table if not exists `zw`.`dw_t_product2`(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50), -- 商品修改时间
dw_start_date varchar(12), -- 生效日期
dw_end_date varchar(12), -- 失效时间
cdat varchar(10) -- 模拟hive分区
)default character set = 'utf8';
全量导入2019年12月20日数据
- 原始数据层导入12月20日数据(4条数据)
insert into `zw`.`t_product_2`(goods_id, goods_status, createtime, modifytime) values
('001', '待审核', '2019-12-18', '2019-12-20'),
('002', '待售', '2019-12-19', '2019-12-20'),
('003', '在售', '2019-12-20', '2019-12-20'),
('004', '已删除', '2019-12-15', '2019-12-20');
- 将数据导入到数仓中的ods层
insert into zw.ods_t_product2
select *,'20191220' from zw.t_product_2 where modifytime >='2019-12-20'
- 将数据从ods层导入到dw层
insert into zw.dw_t_product2
select goods_id, goods_status, createtime, modifytime, modifytime,'9999-12-31', cdat from zw.ods_t_product2 where cdat='20191220'
增量导入2019年12月21日数据
- 原始数据层导入12月21日数据(6条数据)
UPDATE `zw`.`t_product_2` SET goods_status = '待售', modifytime = '2019-12-21' WHERE goods_id = '001';
INSERT INTO `zw`.`t_product_2`(goods_id, goods_status, createtime, modifytime) VALUES
('005', '待审核', '2019-12-21', '2019-12-21'),
('006', '待审核', '2019-12-21', '2019-12-21');
- 原始数据层同步到ods层
insert into zw.ods_t_product2
select *,'20191221' from zw.t_product_2 where modifytime >='2019-12-21';
- 编写ods层到dw层重新计算 dw_end_date
注意:我这里直接将结果的SQL语句放在这里语句 因为需要将覆盖写入到数据库中我这里就没有写了,但是不影响我们结果。
12月22 号的操作流程跟21 一样我就里就不写了
select t1.goods_id, t1.goods_status, t1.createtime, t1.modifytime,
t1.dw_start_date,
case when (t2.goods_id is not null and t1.dw_end_date>'2019-12-21') then '2019-12-21'else t1.dw__date end as end ,
t1.cdat
from zw.dw_t_product2 t1
left join (select * from zw.ods_t_product2 where cdat='20191221')t2 on t1.goods_id=t2.goods_id
union
select goods_id, goods_status, createtime, modifytime, modifytime,'9999-12-31', cdat from zw.ods_t_product2 where cdat='20191221'
- 查询结果
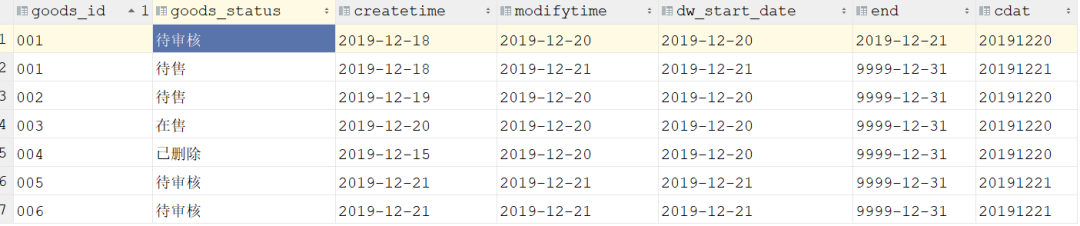
总结
到这里我们终于将拉链表实现完了,虽然实现拉链表这个功能有点复杂有点绕,但是它真的帮助我们节省很多的资源,以公司层面难道不选它吗,也就为什么面试数仓的时候基本上都会问拉链表的原因。很多小伙伴对
dw_start_date与
ds_end_date有疑惑我们可以在评论区一起讨论。信自己,努力和汗水总会能得到回报的。我是大数据老哥,我们下期见~~~
获取Flink面试题,Spark面试题,程序员必备软件,hive面试题,Hadoop面试题,Docker面试题,简历模板等资源请去GitHub自行下载 https://github.com/lhh2002/Framework-Of-BigData

- BAT面试官教你校招-项目讲解模块如何备战
- 【SSH进阶之路】Spring的IOC逐层深入——为什么要使用IOC[实例讲解](二)
- 【php基础班】第12天 网页对象介绍、对象深入讲解、事件、定时器
- mongoDB中CRUD的深入讲解
- 深入讲解Android中Activity launchMode
- Tomcat中的Session与Cookie深入讲解
- 第79讲:单例深入讲解及单例背后的链式表达式
- ASP.NET2.0自定义控件组件开发 第六章 深入讲解控件的属性
- 深入讲解防火墙的概念原理与实现
- 结合丰富示例深入讲解Ajax架构和最佳实践——《深入Ajax:架构与最佳实践》
- 深入讲解PHP Session及如何保持其不过期的方法
- 深入讲解Java中的流程控制与运算符
- 深入讲解string和StringBuilder的区别
- 【备忘】2017年最新Google面试官亲授备战Java校招面试视频讲解教程
- 深入讲解Python编程中的字符串
- 深入讲解Android中Activity launchMode
- Shell中重定向的深入讲解
- 深入讲解spring boot中servlet的启动过程与原理
- 深入讲解数据库设计的相关概念
- 深入PHP购物车模块功能分析(函数讲解,附源码)