【爬虫实战】CC98抽卡机
抽卡?什么是抽卡?
CC98 抽卡是由
CC98和
NexusHD共同推出的一款抽卡小游戏。卡牌内容包括
CC98、
NexusHD,以及浙江大学相关的各种人事物,不同的卡片具有不同的等级,同时也具有不同的价值和抽取几率。
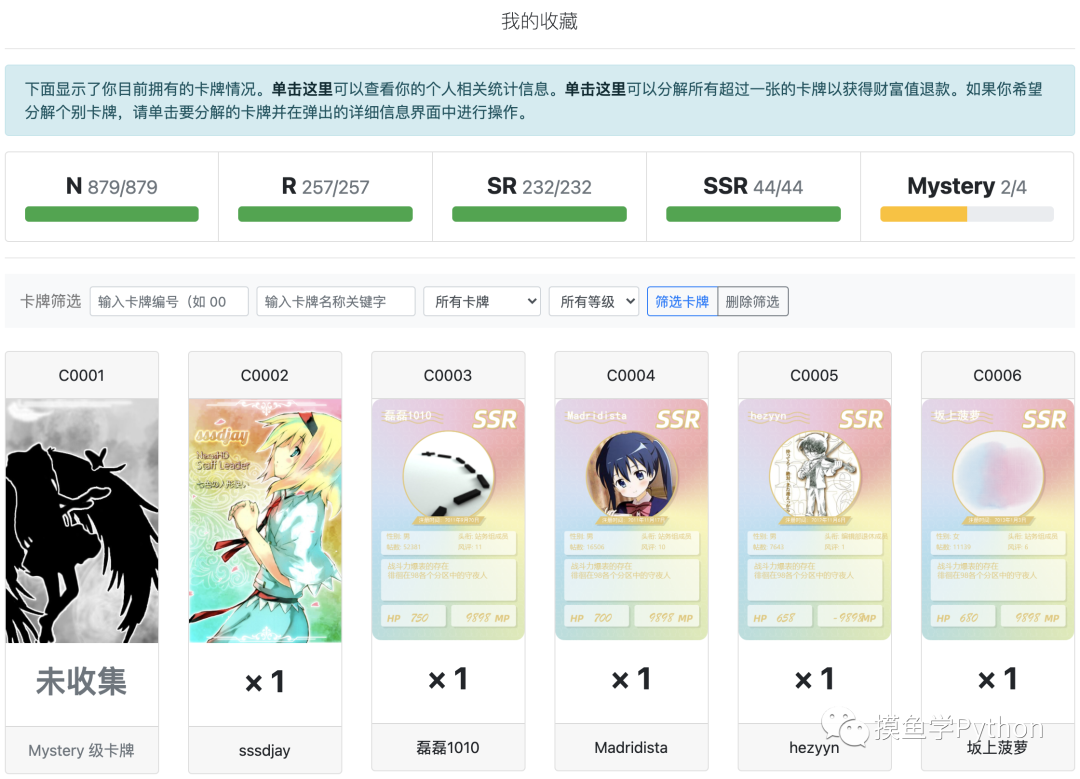 个人收藏页面
个人收藏页面等级介绍
Mystery
是对98、NHD有杰出贡献的四位用户***
是98站务组和技术组正式成员、荣誉站长、创始人逗逼形象和NHD维护开发员、管理员SR
是98正式版主和全站贵宾、拥有大于等于3个VIP(包括协会退休成员)或威望超过98或帖数超过10w的98用户,NHD总版主和发布员R
是98实习版主、认证用户、版面贵宾、98运营管理团队成员和帖数大于等于10000或威望大于等于15的用户N
是其他普通用户。
等级分布
| 等级 | N | R | SR | *** | Mystery |
|---|---|---|---|---|---|
| 比例 | 53.49% | 30.00% | 15.00% | 1.50% | 0.01% |
| 最低数量 | 0 | 0 | 1 | 0 | 0 |
为什么需要抽卡机,手动抽不好吗
原因也简单,懒呗。如果要手动抽完每个月从N站兑换来的100万财富值(现在缩水到80万了),就算不每次都全部点开,也得十几二十分钟,费时费力费鼠标。之前有人用按键精灵来抽卡,也算是一种解放劳动力的方案。今年十月份的时候我自学了一些爬虫的基础知识,就想着能不能学以致用,写一个能够完成自动抽卡的Python程序。
第一版抽卡机——用Cookie绕过登录
起初,我以为所有网站的登录都差不多,无非就是用POST方法提交一个包含用户名和密码的表单,但是显然事情没有我想象得那么简单。
登录CC98抽卡中心需要先登录CC98登录中心:
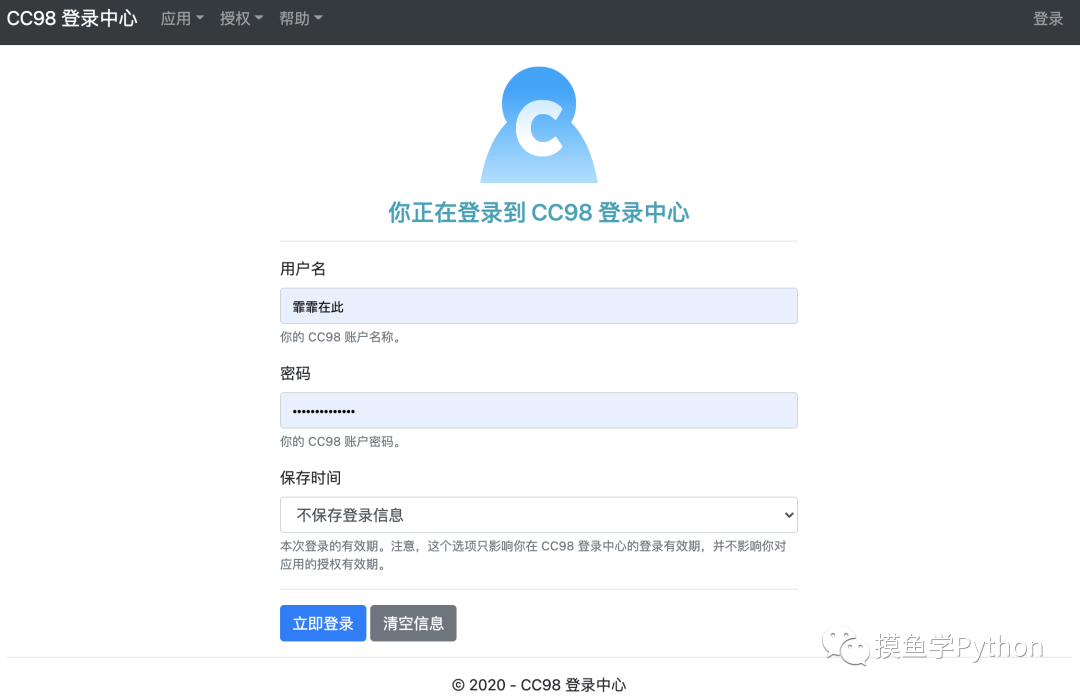 CC98登录中心登录页面
CC98登录中心登录页面
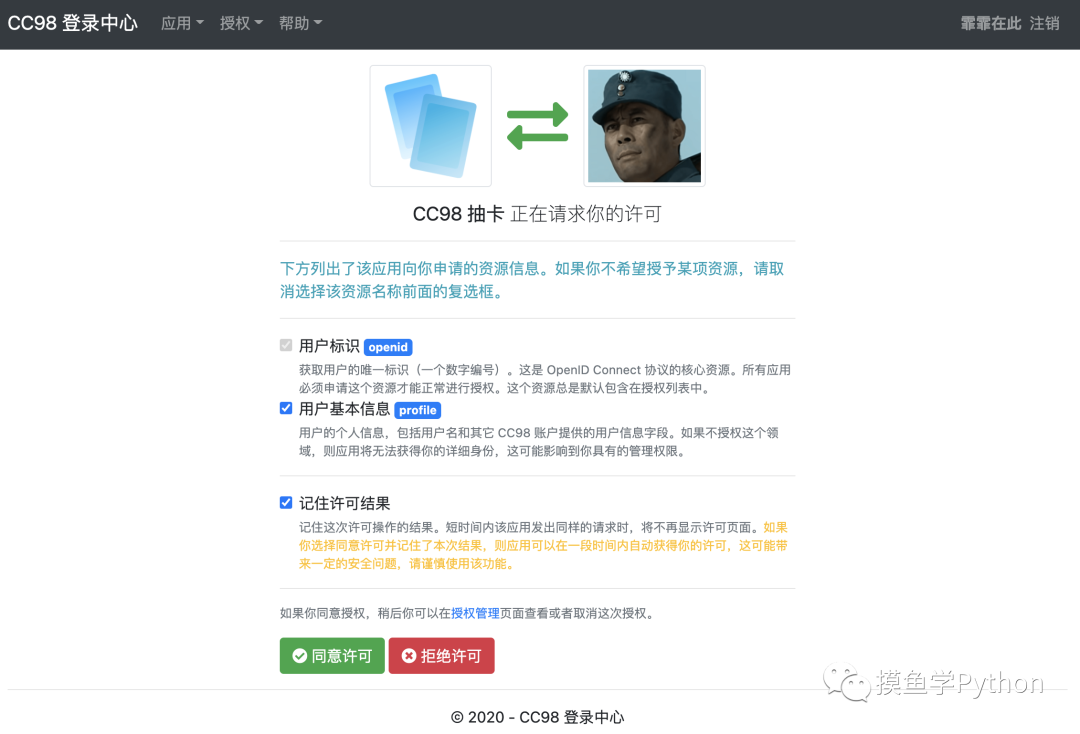
登录后,还需要通过抽卡中心发起的许可,方可进入CC98抽卡中心。
 授权许可页面
授权许可页面
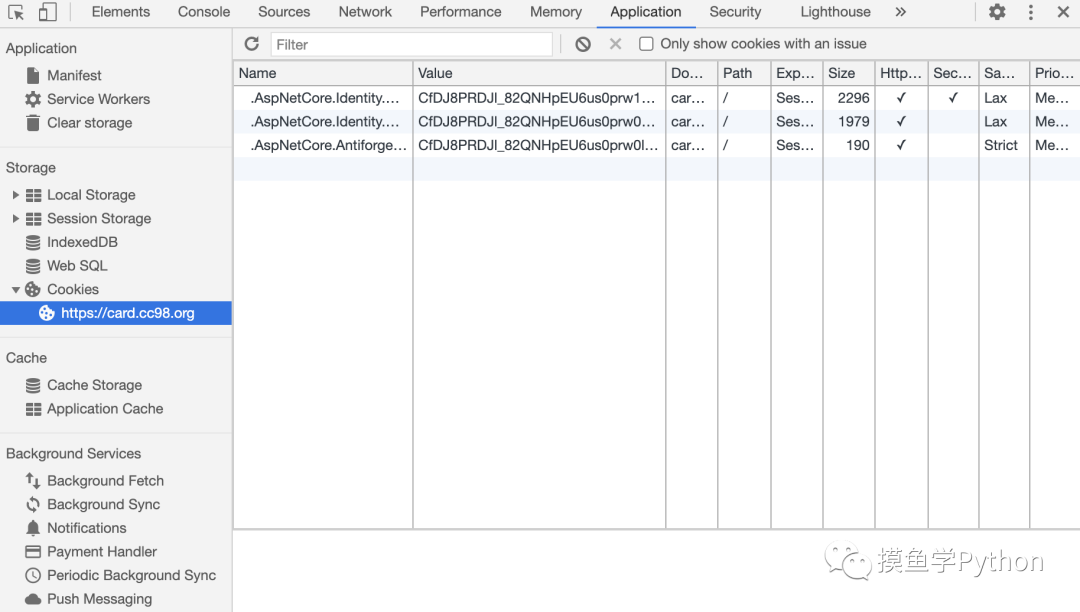
在Chrome的开发者工具中看了一下登录CC98登录中心需要提交的信息:
 登录CC98登录中心的Form Data
登录CC98登录中心的Form Data
这时我完全不知道这个
__RequestVerificationToken是从哪来的,复制下来尝试用
Requests来模拟登录,得到了状态码为400的响应——登录失败了。
在网上查了很多资料以后发现一种可以绕过登录的方法——保存
cookie。
于是我去开发者工具里把抽卡页面的
cookie保存了下来,然后对抽卡的API:
https://card.cc98.org/Draw/Run/发送一个POST请求,终于,我第一次成功用Python完成了抽卡。
 在Chrome中查看当前页面cookie
在Chrome中查看当前页面cookie
CSRF验证
虽然能够抽卡了,我还是十分好奇Form-data里的那个
__RequestVerificationToken是怎么来的,通过谷歌,我找到了这样一篇博客:
当爬虫遇到CSRF 验证(__RequestVerificationToken):https://www.jianshu.com/p/e0844a0a5e61
原来这个
__RequestVerificationToken是可以从页面的html中找到的,也就是说也可以用程序来获得:
import requests
from bs4 import BeautifulSoup
# 获取CSRF验证
r = requests.get('https://card.cc98.org/Draw', cookies=cookies)
bs = BeautifulSoup(r.text, 'html.parser')
token = bs.find('input', {'name':'__RequestVerificationToken'})['value']
于是第一版的抽卡机就完成了我还加了一个小功能,就是把抽到的
***和
M卡显示出来,代码如下:
from skimage import io
# 开抽!
r = s.post('https://card.cc98.org/Draw/Run/{}'.format(action),
data=data,
headers={"content-type":"application/x-www-form-urlencoded; charset=UTF-8"},
cookies=cookies)
bs = BeautifulSoup(r.text, 'html.parser')
N_cards = bs.find_all('div', {'data-level':'0'})
R_cards = bs.find_all('div', {'data-level':'1'})
SR_cards = bs.find_all('div', {'data-level':'2'})
***_cards = bs.find_all('div', {'data-level':'3'})
M_cards = bs.find_all('div', {'data-level':'4'})
print('抽到{}张N卡,{}张R卡,{}张SR卡,{}张***卡,{}张M卡!'.format(len(N_cards), len(R_cards), len(SR_cards), len(***_cards), len(M_cards)))
***_M = ***_cards + M_cards
# 显示抽到的***卡和M卡
if ***_M:
for i in ***_M:
img_src = i.find_all('img')[1]['src']
image = io.imread('https://card.cc98.org'+img_src)
io.imshow(image)
io.show()
还发现了一个好用的chrome插件:EditThisCookie,可以方便的把cookie存下来
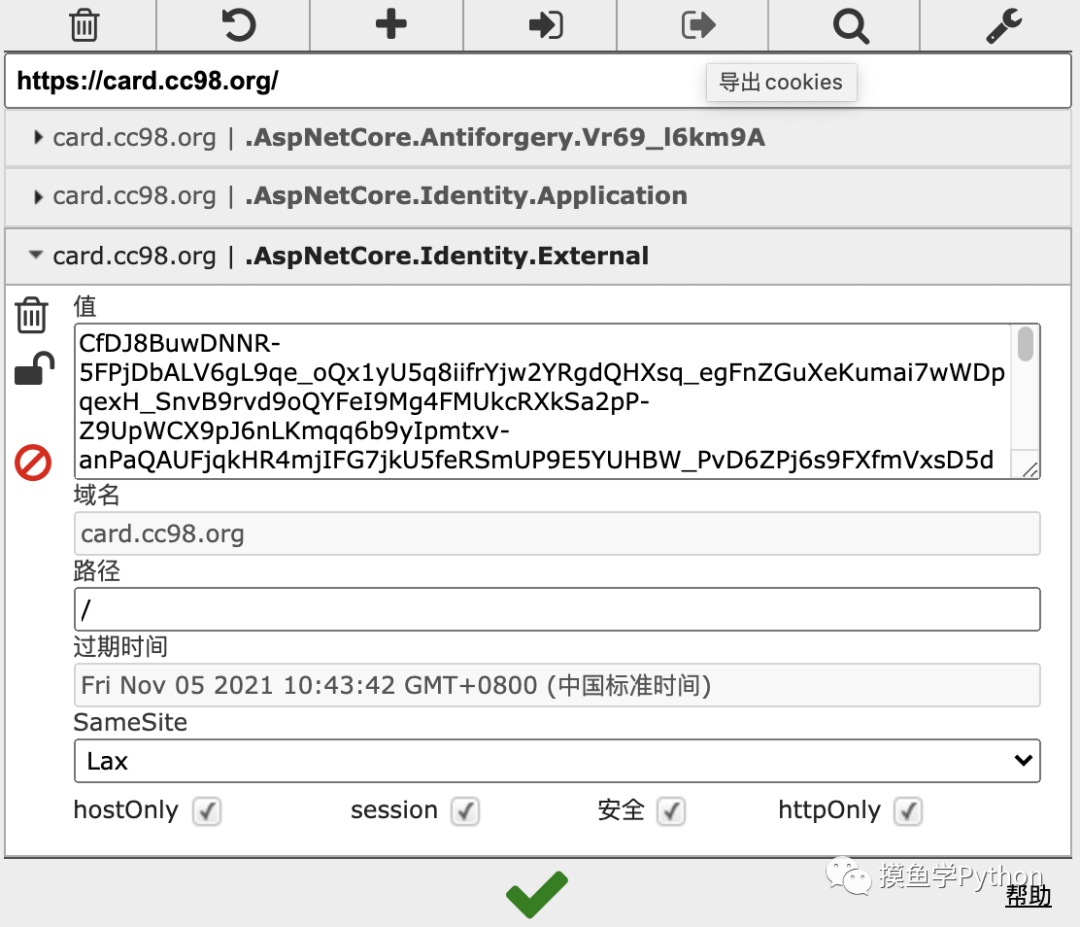 EditThisCookie插件
EditThisCookie插件
第二版抽卡机——用Selenium获取Cookie
第一版的抽卡机虽然可以将大部分工作自动完成,但是还是有一个手动操作的环节——复制一下
cookie。
实验室旁边工位的师兄是一个
Selenium大师,他建议用它试试,试试就试试。其实并没有什么难度,就是学习
xpath表达式的时候略微花了一些功夫。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# 登录CC98登录中心
driver.get('https://openid.cc98.org/Account/LogOn')
driver.find_element_by_id('UserName').send_keys('用户名')
driver.find_element_by_id('Password').send_keys('密码')
driver.find_element_by_xpath('//button[text()="立即登录"]').click()
# # 授权给CC98抽卡中心
driver.get('https://card.cc98.org/')
driver.find_element_by_xpath('//*[text()="登录"]').click()
driver.find_element_by_xpath("//button[@class='btn btn-success']").click()
cookies = {c['name']: c['value'] for c in driver.get_cookies()}
这里要注意的是,使用
XPATH时应该避免使用数组索引(从Chrome的开发者工具里直接复制
XPATH就会是这个样子),而应该使用有意义的
class或者
id来定位。
第三版抽卡机——层层剥开验证登录
通过学习各种参考资料,我的爬虫水平有了一定程度的提高,也决定用Requests硬刚一下CC98抽卡中心的登录。
在Network标签页中可以看到两次302跳转:
 两次跳转
两次跳转
登录CC98登录中心

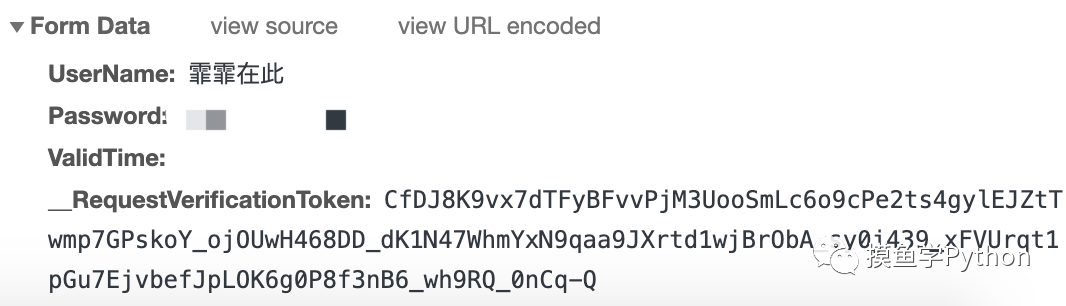
首先是
用户名、
密码、然后
ValidTime为空字符串,
__RequestVerificationToken和前面一样从html里解析出来。
通过验证界面
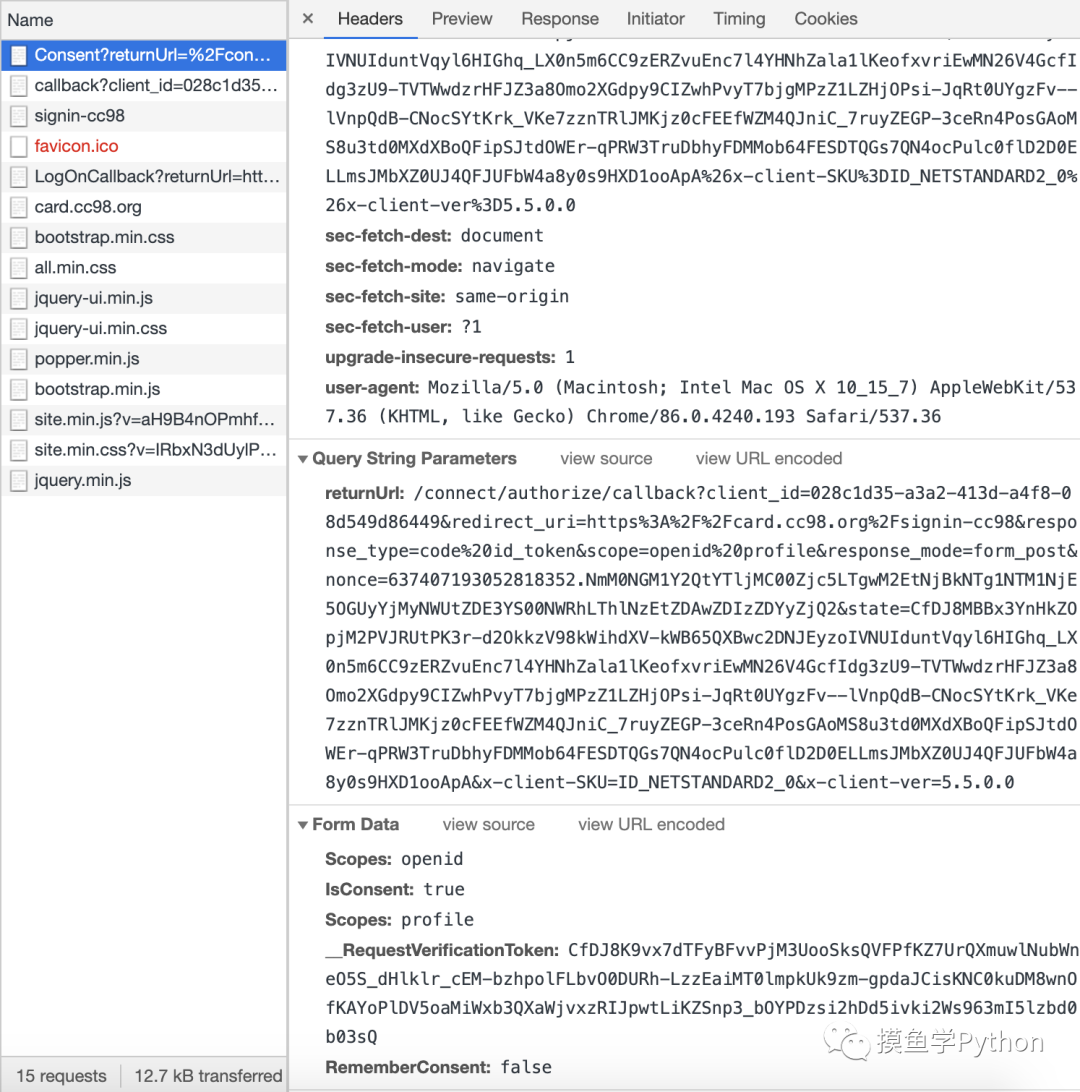 第二次POST请求的Form Data
第二次POST请求的Form Data
在Python中模拟,结果收到的响应是这样的:
 错误的Response
错误的Response
花了很长时间我才发现,Scopes这个参数竟然赋了两次值,第一次复制的结果自然就被第二次覆盖掉了。删掉第二次赋值
Scopes: profile以后的响应是这样的:
 正确的Response
正确的Response
返回的这段
html代码里包含了最后给
signin-cc98发送POST请求时需要的表单信息,把他们都解析出来来就可以了。
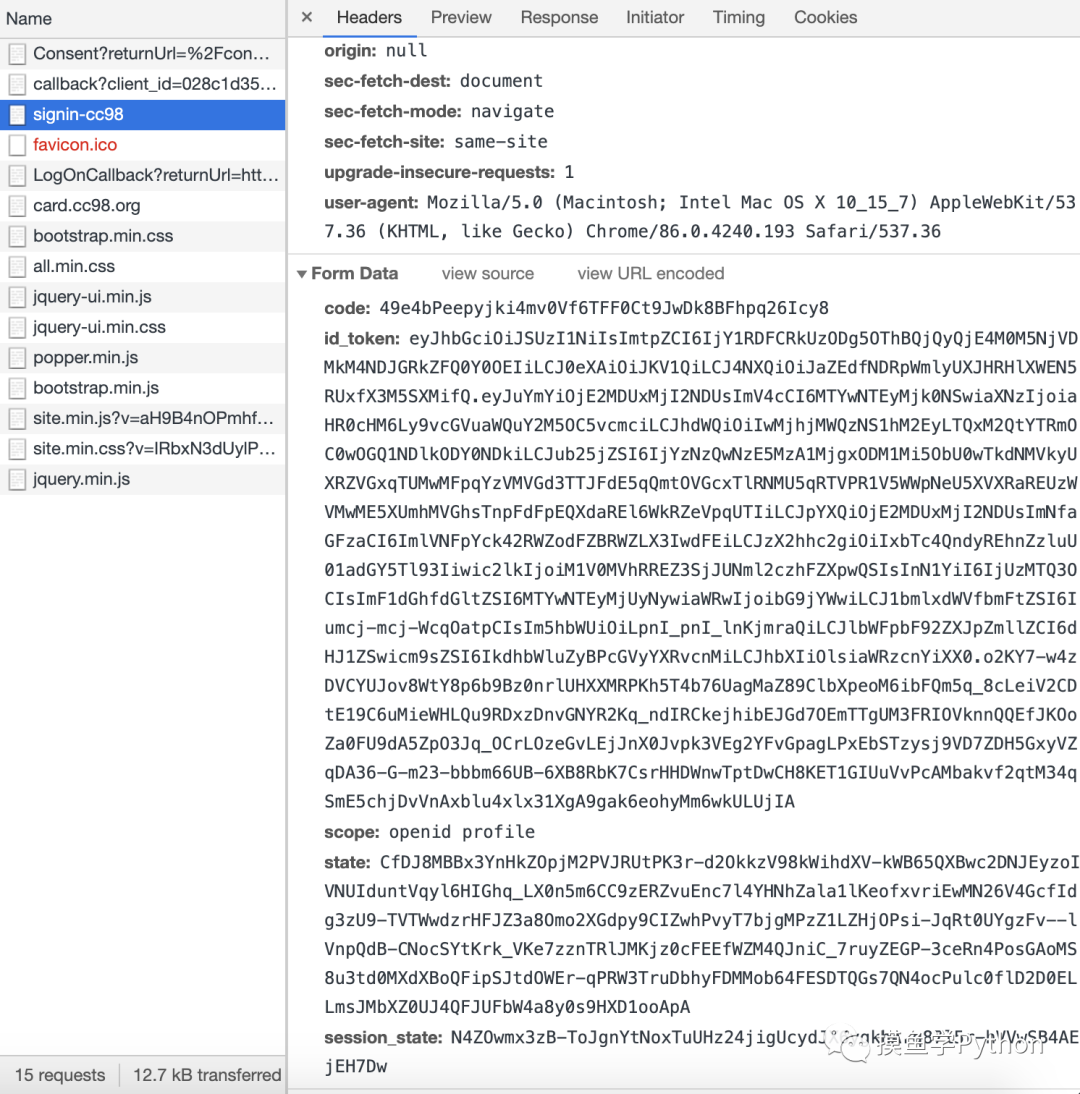
第三次POST请求的Form Data
几个很坑的点
- url多次跳转,要搞清楚现在在哪个页面
- 在开发者工具里看不到consent的response
- consent表单的字典里有两个相同的key
总结
通过这个小项目,我不经意间学到了很多东西,也发现了目标明确的时候一个人的效率可以有多高。全部代码已经上传到了GitHub,点击原文链接即可获取。

- python3 [爬虫实战] selenium + requests 爬取安居客
- python3.x爬虫实战:爬今天头条的图集
- python爬虫实战-模拟登陆网站(验证码手工输入)
- python3爬虫实战一: 爬取豆瓣最新上映电影及画出词云分布
- Python网络爬虫实战项目代码大全
- Python 网络爬虫反爬破解策略实战
- python爬虫学习实践(一):requests库和正则表达式之淘宝爬虫实战
- 爬虫实战--简单爬取小说网站的小说(面对过程)
- 分享百度云链接 Python 3网络爬虫开发实战 ,崔庆才著
- 爬虫实战--糗事百科
- 爬虫实战--抓取糗事百科前10页数据
- 爬虫新手实战——爬去男人团图片加神秘代码归类到指定目录
- Python 爬虫实战(1):分析豆瓣中最新电影的影评并制作词云
- Python实战——爬虫
- python爬虫实战笔记(二)数据缓存mangodb实现类方法
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
- Java爬虫实战(二):抓取一个视频网站上2015年所有电影的下载链接
- python:爬虫实战讲解及源码
- python3爬虫 - cookie登录实战
- python3--爬虫实战一:爬取豆瓣电影250