上百G文本数据集等你来认领|免费领取
2021-01-03 22:25
295 查看

玩机器学习的童鞋都知道数据集的重要性,没有数据粮食喂养,好的模型是长不出来的,形象的比喻就是“巧妇难为无米之炊”。
这一年多来一直在摸索文本分析领域,文科生一枚摸着石头过河,很可惜一直没有出什么东西。不过却也在这过程中积累了一些在线评论数据集。大多是在百度网盘、谷歌遇到我觉得有用的数据我一般会下载下来。大邓都整理到csv中,方便大家使用pandas进行数据分析。今天我整理了一下,分享给大家。
中文在线评论数据
中文的数据主要电商平台在线评论数据,且均标注正负情感标签的,领域包括:
-
计算机
-
热水器
-
服装
-
手机
-
书籍
-
洗发水
- 外卖
通过这些标注的各个领域评论数据,我们可以训练各自领域的情感分析模型。有余力的童鞋也可以构建相关领域属性词典,想想就很激动。大邓这里打开其中一个文件,样子大概是这样的。
此外还有微博评论数据,有人将其标注为4种情绪,数据量10万条。再次感谢他们的辛勤劳动。
亚马逊评论数据集
该数据集的发现要感谢山东烟台的一位网友,向我咨询问题的时候给我留下了 加州大学圣地哥分校Julian McAuley教授的Amazon product ata数据集页面。
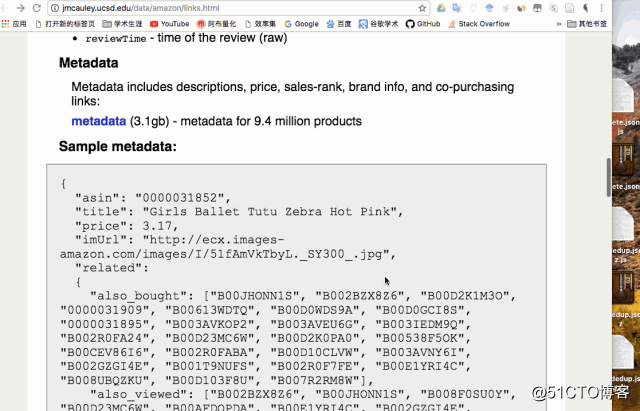
数据集简介:
该数据集包含来自亚马逊的产品评论和元数据,其中包括1996年5月至2014年7月的1.4亿条评论。 该数据集包括评论(评分,文字,乐于投票),产品数据(产品描述,类别信息,价格,品牌和图像特征)以及产品链接。
亚马逊1996-2014年 近200G数据(这只是部分数据,更大更大的数据需要找Julian McAuley教授要)。这是教授的官方介绍,居然还有一个视频直播。大邓写这篇文章时美国大概是晚上十点,可能教授下班了,所以屋子里没有。如果赶巧的话,你们能看到教授搞学习。

相关文章推荐
- 情感分析︱网络公开的免费文本语料训练数据集汇总
- 免费领取全新30套训练数据集, 包含:“股票数据”、“行人检测常用数据”、“汽车数据集” 点击链接,立即领取: http://mp.weixin.qq.com/s/rm_SBbGSVtrmhJcGUp
- 黑马视频免费领取了。
- 关于几个iOS 7 API的功能分析:文本转语音、免费托管IAP以及3D地图等
- android官方文档译文, 同步更新中(百度阅读免费领取)
- 一百多个微信小程序源码,限量免费领取中!!!
- 分众Q卡:免费领取的“维络卡” 基于此对SOLOMO模式的思考;
- Q妹带你赚外快:这些Java问题赏金等你来领取
- Notepad2 V4.1.24.62 免费版 是一个外观类似系统记事本的文本编辑工具
- 百度云IT超大容量免费领取,不要错…
- 百度云IT超大容量免费领取,不要错…
- 淘宝网的购物返现券怎么用,淘宝优惠券免费领取 淘宝购物分享红包
- QQ电子密保卡已经于今日上线 可免费领取
- 阿里云幸运券免费领取 阿里云幸运券使用方法
- 插件一:JAVA微信砍价活动源码分享[商品帮砍到0元,免费领取奖品]
- 支付宝现金红包,免费领取,小伙伴们,给大家发红包喽!
- 【推荐】免费领取QQ密保卡,提高QQ安全!
- 免费领取 | 140G+AI人工智能/复杂系统/数据挖掘/深度学习/Python资料
- 免费领取 | 10G+AI人工智能/复杂系统/数据挖掘/深度学习/Python资料
- 腾讯云新活动免费领取试用4核8G服务器长达180天6个月