初识K-means算法

K-means属于非监督机器学习算法,主要用于聚类分析。比如咱们收集某新闻网站的新闻数据,但是在采集过程中忘了收集新闻的新闻类别(假设一共采集了军事、政治、文化、教育四大类),现在我们需要对成千上万的新闻文档进行分类,这时候我们可以使用k=4的簇数(聚类数)对新闻数据施行Kmeans算法,并对每篇文档进行标注。
但是我们还是要强调一点,K-means是无监督学习,虽然不需要标注好的数据,但是还是需要你对数据有一定的了解,能够大概猜测出k值(簇的数目)的范围。这样Kmeans算法才能开始更准确合理的学习数据中的类规律,并作出较好的分类。(其实还有分类算法的,这里我用分类吧,不太严谨哈。)
K-means原理
K-means,从字面看含有k和means两部分。K-means算法会将样本量N特征数m的数据X (其中X是N*m的矩阵)分到K个簇中,每个簇会有一个重心centroids。
聚类效果的目标是通过计算簇中各个点到重心的距离平方和Inetia尽可能的小。Inetia计算公式如下
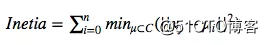
C是一个簇;u是簇C的重心;Xj是簇C中的任意点。
Inetia也有个问题,Inetia不是正规的度量方式;我们仅仅知道Inetia越小越好,0是最优状态。但是极端的情况下,如果有n条数据,我们将其分成n类,Inetia会等于0。
K-means算法:
K-means算法比较出名的的易于理解的是LIoyd算法,包含三个步骤:
1 、从数据集X中随机抽选k个样本点
2、按照距离最近原则,将剩余的点分派给k个簇。而上一步抽选的k个样本点就是k个簇的重心centorid。
3、根据每个簇所有的点求出新的重心centroid,并重复步骤2和步骤3。直到重心没什么显著变化,聚类结束。
优化K-means算法
充足运行时间条件下,K-means总能最终收敛,但是往往是局部最优。
聚类的表现高度依赖于重心centroid的最初的选择。所以K-means往往需要运行好几次,这里也就是max_iter参数的意义,一次随机抽选centroid误差较大,所以运行max_iter次,最终选择表现最好的作为最终聚类结果。
解决随机抽选centroid重心,有一种“k-means++”初始化方法,scikit-learn已经实现(通过使用init=k-means参数)。这种初始化选择重心centroid的方法,尽量保证k个重心彼此之间的距离尽可能的远,这样比随机抽选centroid更好。
K-means中海油一个n_job参数,可以加快模型学习速度。当n_job=-1时,电脑使用全部的处理器进行并行运算。但是并行运算虽然会提高运行速度,却以消耗大量内存为代价。
案例
这个例子是为了说明k-means会产生不直观和可能意想不到的簇的情况。
在前三幅图中,输入数据不符合一些隐含假设,使得k-means产生了不需要的聚类。最后一个图,虽然各个簇的样本量分布不均衡,但是从我们直觉还是能看出聚类的合理性。
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import make_blobs #画图,设置画布尺寸 plt.figure(figsize=(12, 12)) #随机生成1500个样本点 n_samples = 1500 #保证下次随机生成的数据与前一次生成的数据是相同的 random_state = 170 #给k-means算法生成测试数据的函数 X, y = make_blobs(n_samples=n_samples, random_state=random_state) #我们看看前10条数据 print(X[:10], y[:10])
make_blob生成n_samples*n_features特征矩阵X和标签y,X矩阵默认特征数n_features=2。所以我们现在获取的特征矩阵是1500行2列。而标签y是一维数组。
现在我们看看前10条数据。
[[ -5.19811282 0.64186932] [ -5.75229538 0.41862711] [-10.84489837 -7.55352273] [ -4.57098483 -0.80101741] [ -3.51916215 0.0393449 ] [ 1.60391611 0.76388041] [ -9.75157357 -5.2030262 ] [-11.51023635 -4.16284321] [ -7.72675795 -5.86656563] [ 2.67656739 3.29872756]] [1 1 0 1 1 2 0 0 0 2] ``
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
#画图,设置画布尺寸
plt.figure(figsize=(12, 12))
#随机生成1500个点(二维点)
n_samples = 1500
#记录状态,可以保证下次随机生成的数据与前一次生成的数据是相同的
random_state = 170
#make_blob主要是给k-means算法生成测试数据的函数。这里同时得到特征矩阵X和标签label
X, label = make_blobs(n_samples=n_samples, random_state=random_state)
#我也不知道有几类,随便将k=2去试试吧。让K-means学习X,并生成预测的标签
label_pred = KMeans(n_clusters=2, random_state=random_state).fit_predict(X)
#将figure设置的画布大小分成几个部分。参数‘221’表示2(row)x2(colu),即将画布分成2x2,两行两列的4块区域。1表示咱们绘制的第一幅图
plt.subplot(221)
#X[:, 0]意思是抽取X中所有行第一列,我们可以理解为坐标系的x; X[:, 1]是X的第二列,我们可以理解为坐标系的y;再用scatter在二维坐标系中绘制散点图,颜色c使用label_pred标注。
plt.scatter(X[:, 0], X[:, 1], c=label_pred)
plt.title("k=2 cluster")
#k=3
label_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X)
plt.subplot(222)
plt.scatter(X[:, 0], X[:, 1], c=label_pred)
plt.title("k=3 cluster")
#生成不同类数据的,且各类的方差是存在差异的
X_varied, y_varied = make_blobs(n_samples=n_samples,cluster_std=[1.0, 2.5, 0.5],random_state=random_state)
label_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_varied)
plt.subplot(223)
plt.scatter(X_varied[:, 0], X_varied[:, 1], c=label_pred)
plt.title("k=3 Unequal Variance")
#生成不同类数据的,且各类样本量不均衡#0类有500个点;1类有100点;2类仅有10个点;
X_filtered = np.vstack((X[label == 0][:500], X[label == 1][:100], X[label == 2][:10]))
label_pred = KMeans(n_clusters=3,random_state=random_state).fit_predict(X_filtered)
plt.subplot(224)
plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=label_pred)
plt.title("Unevenly Sized Blobs")
plt.show()

- 数字图像处理,初识压缩感知Compressive Sensing
- 初识:LevelDB
- .Net Pet Shop 4 初探之一:初识PetShop4
- 实战 Lucene,第 1 部分: 初识 Lucene
- json初识
- python小白之路:第一章 初识python
- 初识Q-Patterns
- Linux学习笔记 (一)初识linux
- 深度学习-卷积神经网络初识-2
- JDBC-初识
- 毕业设计---之 初识 高低地形 Terrain (效果)
- Android Volley完全解析(一),初识Volley的基本用法
- jstorm学习笔记--初识(一)
- 初识DockerFile
- 初识OOAD-面向对象设计模式
- 初识AngularJS
- K-means算法
- 小曾的js学习笔记01(第一天-第三天)---初识js
- Struts2初识(三) ---> interceptors
- 12c 备份与恢复 - 初识resetlogs