pandas数据分析之缺失数据处理
转眼国庆假期已经过去,实在不想投身工作啊。祖国母亲,咱们再过个农历生日可好,让我们再为你庆生几天。一想到2018年已无法定节假日,还是收拾心情,开始认真搬砖吧。

前言
原因
数据缺失在数据处理的过程中十分常见,其原因有很多,主要可以总结为三大类:
无意的:信息被遗漏,例如数据采集过程的故障导致数据缺失,例如记录过程的缺失等。
有意的:有些数据集的特征描述中将缺失值作为特征值。
不存在:有些数据的特征属性本身不存在。
类型
数据缺失的类型可以分为以下三类:
完全随机损失(missing completely at random,MCAR):数据的缺失完全是随机的,不依赖于任何不完全变量或完全变量。
随机缺失(missing at random,MAR):数据的缺失不是完全随机的,依赖于其他完全变量。
非随机缺失(missing not at random:MNAR):指的是数据的缺失依赖于不完全变量自身。
处理方式
缺失数据的处理方法包括:删除记录、数据插补和不处理。
处理方法
pandas的设计目标之一就是让缺失数据的处理任务尽量轻松,pandas使用浮点值NaN表示浮点和非浮点数组中的缺失数据。

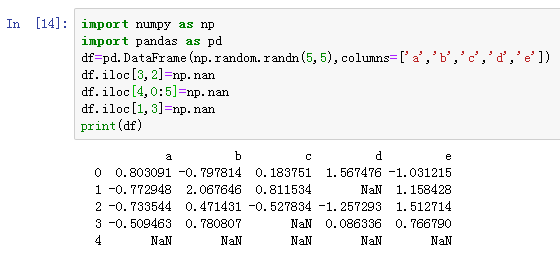
生成数据集

删除记录
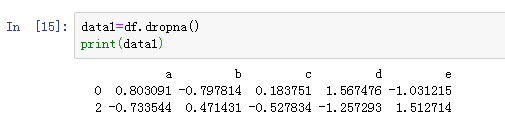
使用pandas的dropna直接删除有缺失值的特征,该方法是根据各标签中的值是否存在缺失数据对轴标签进行过滤。
dropna默认删除任何含有缺失值得行:
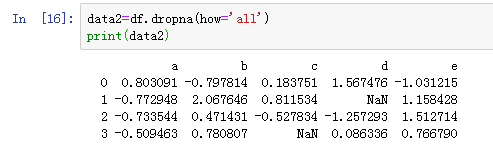
传入how='any'将只丢弃全为NaN的行:
要用这种方式丢弃列,只需传入axis=1即可。
对于一个Series,dropna返回一个仅含非空数据和索引值的Series。
判断缺失情况
pandas采用isnull和notnull方法,返回一个含有布尔值的对象,这些布尔值表示哪些值是缺失值。

获得含有缺失数据的列采用如下方法:

说明a、b、c、d、e列均含有缺失值。
获得全部为缺失数据的列的方法如下:
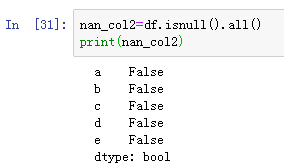
说明a、b、c、d、e列均不是全部为NA值的列。
填充缺失数据
有时候,并不希望删除记录,需要通过某种方法来填充缺失数据。fillna方法是最主要的函数。
其参数主要说明如下:
value:用于填充缺失值的标量值或字典对象
method : 插值方式(ffill或bfill),如果函数调用时未指定其他参数的话,默认为“ffill”
axis :待填充的轴,默认axis=0
inplace :修改调用者对象而不产生副本
limit :(对于前向和后向填充)可以连续填充的最大数量
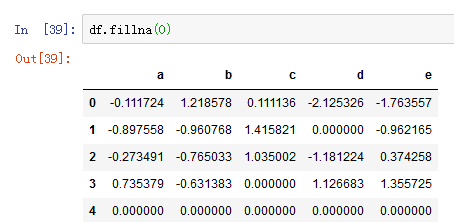
通过一个常数调用fillna将缺失值替换为那个常数值。例如将所有缺失值替换为0:
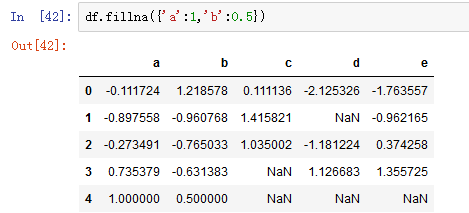
通过一个字典调用fillna,就可以实现对不同列填充不同的值。例如对a列填充常数1,对b列填充常数0.5:
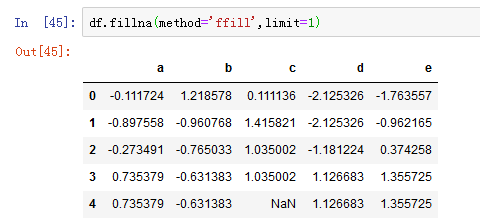
方法ffill代表后向填充,limit代表填充的最大数量:
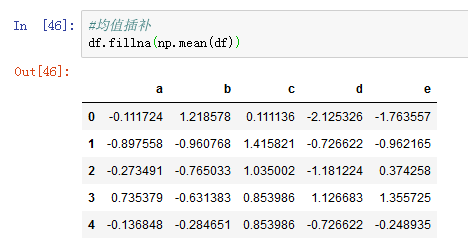
也可以采用均值、中位数或众数插补:
总结
以上介绍了对于缺失数据的简单处理方法,包括删除记录,数据插补和不处理。具体的处理方法还要根据不同的需求来制定,需要考虑多个方面,包括数据缺失的原因、类型和随机性。关于数据插补这块,只是介绍了一个fillna函数,后续会进一步介绍其他方法,例如热卡填补、极大似然估计、拉格朗日插值等等。

- 利用Python进行数据分析 pandas基础: 处理缺失数据
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
- 数据分析之Pandas缺失数据处理
- 利用Pandas进行数据分析(3)——统计、处理缺失值、层次化索引
- Pandas数据分析工具快速进阶一(索引的选取和过滤&缺失值的处理&索引的排序)
- 利用Python进行数据分析——第二章 引言(2):利用pandas对babynames数据集进行简单处理
- 数据分析学习总结笔记05:缺失值分析及处理
- python:pandas(4),缺失数据处理
- 数据分析处理库Pandas-数据读取
- Day25(pandas电影评分数据实例分析,数据的处理分类提取)
- 利用python进行数据分析(三):pandas--处理数据的工具
- Pandas —— 处理缺失数据dropna( )和fillna( )
- 数据分析中的缺失值处理
- Python数据分析处理库Pandas
- Python数据分析:pandas时间序列处理及操作
- 数据分析之Pandas(九)高级处理-交叉表与透视表
- 基于pandas缺失数据处理
- 人工智能学习笔记——数据分析处理库Pandas
- pandas(五)处理缺失数据和层次化索引