爬取周杰伦新歌《说好不哭》的所有评论,然后生成词云图
前两天
周杰伦发了新歌
说好不哭
顿时间就刷屏了
周杰伦
是一个时代的符号
是我们的青春
早些天
小帅b听周杰伦的歌
还湿润了眼眶了呢
那时候我们唱 k
周董的歌是必点的
他的电影《不能说的秘密》就刷了好几遍
这次的新歌MV 很 nice 啊
特别是里面的女主
上网搜了一下她的照片
小帅b瞬间就爱了啊
刚看了下qq音乐的评论
2500+ 的评论小帅b不禁好奇
这些评论都在说写什么呢
要不然就把它们爬下来
搞个词云图看看吧
接下来就是学习 python 的正确姿势
首先我们来分析一下这个网页
打开控制面板
我们点击下一页
发起请求
发现了一个 comment 的请求
点击进去
咦~这不就是评论的数据嘛
再具体看下 json 数据
原来评论的数据是被封装到 comment 对象下的commentlist 数组了
再来看看是怎么请求的吧
点击 Headers
哇靠请求链接这么长
看看请求参数
看来看去
主要就 pagenum 和 lasthostcommentid 在变
pagenum 一看就是页码
请求第一页的 pagenum 是 0
第二页是 1
lasthostcommentid 则是上一页请求的最后一条评论id
用 Python
8000
来模拟请求一下吧
前方高能
这么多请求参数
我可不想一个键值一个键值的复制粘贴
复制一下 cURL
然后打开我之前说的
postman
点击 Import 按钮
接着选择Past Raw Text
然后
把刚刚复制的 cURL 粘贴进去
点击 Import
点击 Send
可以看到评论数据返回了
接下来骚操作了点击 Code
此时会出现一个面板
选择
Python Requests
直接一键生成
Python请求代码
太太太太TM爽了
有了这么方便的请求代码爬取数据到 txt 文件不是
so easy 么
简单撸下代码把评论数据都爬下来
先直接把刚才生成的请求代码复制过来
创建一个文件用来存放评论数据
来个 for 循环请求每一页的数据
在每一次请求的时候
还要拿到最后一条评论的 id
作为下次请求的参数
我们知道
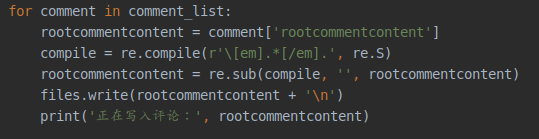
评论数据被封装在 json 数组里面
所以可以循环获取一下然后写到文件里面去
不过有些评论数据含有表情啥的
需要把它们顺便给替换掉
写完之后把文件给关了
跑一下吧
完事之后 jay.txt 就有所有的评论了
有了数据之后
咱们就可以生成词云了
准备个字体文件
准备张背景颜色图片
打开
因为中文
结巴分词整起
接着就可以使用
wordcloud 搞事情了
最后我们使用
pyplot 来 show 一下吧

运行一波
词云出来

可以看到
说好不哭和假面骑士
出现的频率最高
假面骑士说得是 mv 里的男主
其中的“自己”、“努力”、“人生”
也是能量满满
小帅b
谨以此篇
致敬周杰伦
以及我们的青春
下回见
peace

- 爬取周杰伦新歌《说好不哭》的所有评论,然后生成词云图
- 抓取网易云评论,生成词云图
- Python 爬取 20 万条评论,告诉你周杰伦新歌为啥弄崩 QQ 音乐?
- 周杰伦新歌《说好不哭》上线,程序员哭了......
- 扫描一个目录下的所有文件,根据这些文件的创建日期生成一个文件夹,然后把这些文件移入这个文件夹下面
- 周杰伦新歌《说好不哭》深夜刷屏,发售2小时破千万,“周董”的商业版图是怎样的?
- Python 爬取 20 万条评论,告诉你周杰伦新歌为啥弄崩 QQ 音乐?
- 如何判断一个C++对象是否在堆上(通过GetProcessHeaps取得所有堆,然后与对象地址比较即可),附许多精彩评论
- 我的挣扎日记——编写程序,生成一个包含50个随机整数的列表,然后删除其中所有奇数
- 【原创分享】django-m2doc, 自动根据project下的所有models生成数据表结构文档.
- irms模拟数据生成及数据分析 分类: H_HISTORY 2015-03-06 14:17 212人阅读 评论(0) 收藏
- PHP生成Excel,然后另存为的方法
- 非mapreduce生成Hfile,然后导入hbase当中
- 生成一个集合的所有子集 Subset
- 求出所有这些四位数是素数的个数cnt,再把所有满足此条件的四位数依次存入数组b中,然后对数组b中的四位数按从小到大的顺序进行排序
- 【Maven学习】Maven打包生成包含所有依赖的jar包
- 输入一个大于 2 的自然数,然后输出小于该数字的所有素数组成的列表
- 一个自动生成评论的小工具
- 【MYSQL 清空所有的的表中的数据的SQL的生成】
- 分享一个:如何把电商平台上的买家秀文字评论生成excel表格保存起来?