十分钟快速入门 Pandas
十分钟快速入门 Pandas

编程派微信号:codingpy
本文由 Python 翻译组 最新翻译出品,原作者为 Jamal Moir,译者为 liubj2016,并由编程派作者 EarlGrey 校对。
译者简介:liubj2016,中南财经政法大学,金融工程系学生。Python使用方向:数据分析,机器学习和量化投资。
P.S. 弥补一下昨天的错误,大家回复“pybook04”即可获取PDF版分享链接。唉,本来昨天加上这个就不那么标题党了。。。回复完了别忘了接着看这篇教程哦
Pandas是我最喜爱的库之一。通过带有标签的列和索引,
Pandas使我们可以以一种所有人都能理解的方式来处理数据。它可以让我们毫不费力地从诸如
csv类型的文件中导入数据。我们可以用它快速地对数据进行复杂的转换和过滤等操作。
Pandas真是超级棒。
我觉得它和
Numpy、
Matplotlib一起构成了一个 Python 数据探索和分析的强大基础。
Scipy当然也是一大主力并且是一个绝对赞的库,但是我觉得前三者才是 Python 科学计算真正的顶梁柱。
那么,赶紧看看 python 科学计算系列的第三篇推文,一窥
Pandas的芳容吧。如果你还没看其它几篇文章的话,别忘了去看看。
导入 Pandas
第一件事当然是请出我们的明星 —— Pandas。
import pandas as pd # This is the standard
这是导入
pandas的标准方法。我们不想一直写
pandas的全名,但是保证代码的简洁和避免命名冲突都很重要,所以折中使用
pd。如果你去看别人使用
pandas的代码,就会看到这种导入方式。
Pandas 中的数据类型
Pandas 基于两种数据类型,series 和 dataframe。
series 是一种一维的数据类型,其中的每个元素都有各自的标签。如果你之前看过这个系列关于 Numpy 的推文,你可以把它当作一个由带标签的元素组成的
numpy数组。标签可以是数字或者字符。
dataframe 是一个二维的、表格型的数据结构。Pandas 的 dataframe 可以储存许多不同类型的数据,并且每个轴都有标签。你可以把它当作一个 series 的字典。
将数据导入 Pandas
在对数据进行修改、探索和分析之前,我们得先导入数据。多亏了 Pandas ,这比在
Numpy中还要容易。
这里我鼓励你去找到自己感兴趣的数据并用来练习。你的(或者别的)国家的网站就是不错的数据源。如果要举例的话,首推英国政府数据和美国政府数据。Kaggle也是个很好的数据源。
我将使用英国降雨数据,这个数据集可以很容易地从英国政府网站上下载到。此外,我还下载了一些日本降雨量的数据。
EarlGrey:英国降雨数据:下载地址
日本的数据实在是没找到,抱歉。
# Reading a csv into Pandas.
df = pd.read_csv('uk_rain_2014.csv', header=0)
译者注:如果你的数据集中有中文的话,最好在里面加上
encoding = 'gbk',以避免乱码问题。后面的导出数据的时候也一样。
这里我们从
csv文件里导入了数据,并储存在 dataframe 中。这一步非常简单,你只需要调用
read_csv然后将文件的路径传进去就行了。
header关键字告诉 Pandas 哪些是数据的列名。如果没有列名的话就将它设定为
None。Pandas 非常聪明,所以这个经常可以省略。
准备好要进行探索和分析的数据
现在数据已经导入到 Pandas 了,我们也许想看一眼数据来得到一些基本信息,以便在真正开始探索之前找到一些方向。
查看前 x 行的数据:
# Getting first x rows.
df.head(5)
我们只需要调用
head()函数并且将想要查看的行数传入。
得到的结果如下:

你可能还想看看最后几行:
# Getting last x rows.
df.tail(5)
跟
head一样,我们只需要调用
tail并且传入想要查看的行数即可。注意,它并不是从最后一行倒着显示的,而是按照数据原来的顺序显示。
得到的结果如下:

你通常使用列的名字来在 Pandas 中查找列。这一点很好而且易于使用,但是有时列名太长,比如调查问卷的一整个问题。不过你把列名缩短之后一切就好说了。
# Changing column labels.
df.columns = ['water_year','rain_octsep', 'outflow_octsep',
'rain_decfeb', 'outflow_decfeb', 'rain_junaug', 'outflow_junaug']
df.head(5)
需要注意的一点是,我故意没有在每列的标签中使用空格和破折号。之后你会看到这样为变量命名可以使我们少打一些字符。
你得到的数据与之前的一样,只是换了列的名字:
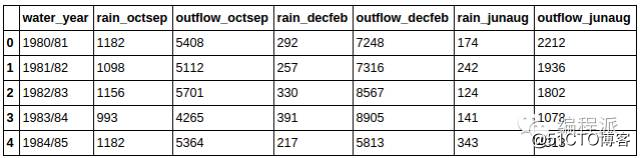
你通常会想知道数据的另一个特征——它有多少条记录。在 Pandas 中,一条记录对应着一行,所以我们可以对数据集调用
len方法,它将返回数据集的总行数:
# Finding out how many rows dataset has.
len(df)
上面的代码返回一个表示数据行数的整数,在我的数据集中,这个值是 33 。
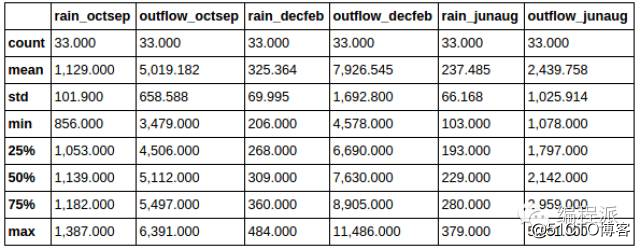
你可能还想知道数据集的一些基本的统计数据,在 Pandas 中,这个操作简单到哭:
# Finding out basic statistical information on your dataset.
pd.options.display.float_format = '{:,.3f}'.format
# Limit output to 3 decimal places.
df.describe()
这将返回一张表,其中有诸如总数、均值、标准差之类的统计数据:
过滤
在探索数据的时候,你可能经常想要抽取数据中特定的样本,比如你有一个关于工作满意度的调查表,你可能就想要提取特定行业或者年龄的人的数据。
在 Pandas 中有多种方法可以实现提取我们想要的信息:
有时你想提取一整列,使用列的标签可以非常简单地做到:
# Getting a column by label
df['rain_octsep']
注意,当我们提取列的时候,会得到一个 series ,而不是 dataframe 。记得我们前面提到过,你可以把 dataframe 看作是一个 series 的字典,所以在抽取列的时候,我们就会得到一个 series。
还记得我在命名列标签的时候特意指出的吗?不用空格、破折号之类的符号,这样我们就可以像访问对象属性一样访问数据集的列——只用一个点号。
# Getting a column by label using .
df.rain_octsep
这句代码返回的结果与前一个例子完全一样——是我们选择的那列数据。
如果你读过这个系列关于
Numpy的推文,你可能还记得一个叫做
布尔过滤(boolean masking)的技术,通过在一个数组上运行条件来得到一个布林数组。在 Pandas 里也可以做到。
# Creating a series of booleans based on a conditional
df.rain_octsep < 1000 # Or df['rain_octsep] < 1000
上面的代码将会返回一个由布尔值构成的 dataframe。
True表示在十月-九月降雨量小于 1000 mm,
False表示大于等于 1000 mm。
我们可以用这些条件表达式来过滤现有的 dataframe。
# Using a series of booleans to filter
df[df.rain_octsep < 1000]
这条代码只返回十月-九月降雨量小于 1000 mm 的记录:

也可以通过复合条件表达式来进行过滤:
# Filtering by multiple conditionals
df[(df.rain_octsep < 1000) & (df.outflow_octsep < 4000)]
# Can't use the keyword 'and'
这条代码只会返回
rain_octsep中小于 1000 的和
outflow_octsep中小于 4000 的记录:
注意重要的一点:这里不能用
and关键字,因为会引发操作顺序的问题。必须用
&和圆括号。
如果你的数据中字符串,好消息,你也可以使用字符串方法来进行过滤:
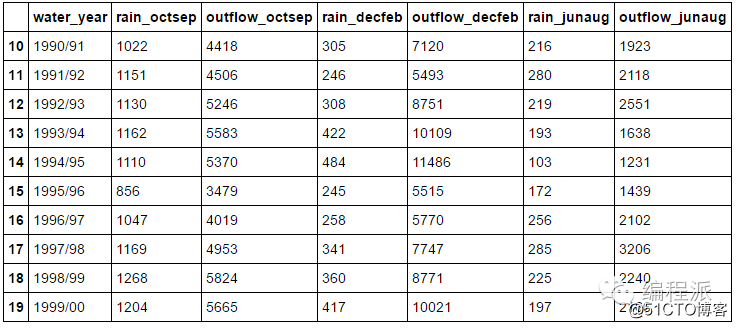
# Filtering by string methods
df[df.water_year.str.startswith('199')]
注意,你必须用
.str.[string method],而不能直接在字符串上调用字符方法。上面的代码返回所有 90 年代的记录:
索引
之前的部分展示了如何通过列操作来得到数据,但是 Pandas 的行也有标签。行标签可以是基于数字的或者是标签,而且获取行数据的方法也根据标签的类型各有不同。
如果你的行标签是数字型的,你可以通过
iloc来引用:
# Getting a row via a numerical index
df.iloc[30]
iloc只对数字型的标签有用。它会返回给定行的 series,行中的每一列都是返回 series 的一个元素。
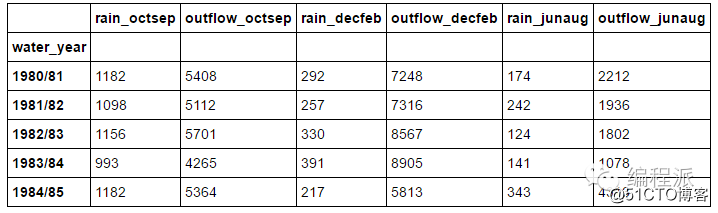
也许你的数据集中有年份或者年龄的列,你可能想通过这些年份或者年龄来引用行,这个时候我们就可以设置一个(或者多个)新的索引:
# Setting a new index from an existing column
df = df.set_index(['water_year'])
df.head(5)
上面的代码将
water_year列设置为索引。注意,列的名字实际上是一个列表,虽然上面的例子中只有一个元素。如果你想设置多个索引,只需要在列表中加入列的名字即可。
上例中我们设置的索引列中都是字符型数据,这意味着我们不能继续使用
iloc来引用,那我们用什么呢?用
loc。
# Getting a row via a label-based index
df.loc['2000/01']
和
iloc一样,
loc会返回你引用的列,唯一一点不同就是此时你使用的是基于字符串的引用,而不是基于数字的。
还有一个引用列的常用常用方法——
ix。如果
loc是基于标签的,而
iloc是基于数字的,那
ix是基于什么的?事实上,
ix是基于标签的查询方法,但它同时也支持数字型索引作为备选。
# Getting a row via a label-based or numerical index
df.ix['1999/00']
# Label based with numerical index fallback *Not recommended
与
iloc、
loc一样,它也会返回你查询的行。
如果
ix可以同时起到
loc和
iloc的作用,那为什么还要用后两个?一大原因就是
ix具有轻微的不可预测性。还记得我说过它所支持的数字型索引只是备选吗?这一特性可能会导致
ix产生一些奇怪的结果,比如讲一个数字解释为一个位置。而使用
iloc和
loc会很安全、可预测并且让人放心。但是我要指出的是,
ix比
iloc和
loc要快一些。
将索引排序通常会很有用,在 Pandas 中,我们可以对 dataframe 调用
sort_index方法进行排序。
df.sort_index(ascending=False).head(5)
#inplace=True to apple the sorting in place
我的索引本来就是有序的,为了演示,我将参数
ascending设置为
false,这样我的数据就会呈降序排列。
当你将一列设置为索引的时候,它就不再是数据的一部分了。如果你想将索引恢复为数据,调用
set_index相反的方法
reset_index即可:
# Returning an index to data
df = df.reset_index('water_year') df.head(5)
这一语句会将索引恢复成数据形式:
对数据集应用函数
有时你想对数据集中的数据进行改变或者某种操作。比方说,你有一列年份的数据,你需要新的一列来表示这些年份对应的年代。Pandas 中有两个非常有用的函数,
apply和
applymap。
# Applying a function to a column
def base_year(year):
base_year = year[:4]
base_year= pd.to_datetime(base_year).year
return base_year df['year'] = df.water_year.apply(base_year)
df.head(5)
上面的代码创建了一个叫做
year的列,它只将
water_year列中的年提取了出来。这就是
apply的用法,即对一列数据应用函数。如果你想对整个数据集应用函数,就要使用
applymap。
操作数据集的结构
另一常见的做法是重新建立数据结构,使得数据集呈现出一种更方便并且(或者)有用的形式。
掌握这些转换最简单的方法就是观察转换的过程。比起这篇文章的其他部分,接下来的操作需要你跟着练习以便能掌握它们。
首先,是
groupby:
#Manipulating structure (groupby, unstack, pivot)# Grouby
df.groupby(df.year // 10 *10).max()
groupby会按照你选择的列对数据集进行分组。上例是按
 照年代分组。不过仅仅这样做并没有什么用,我们必须对其调用函数,比如
照年代分组。不过仅仅这样做并没有什么用,我们必须对其调用函数,比如
max、
min、
mean等等。例中,我们可以得到 90 年代的均值。
你也可以按照多列进行分组:
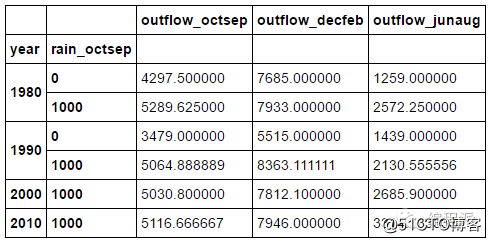
# Grouping by multiple columns
decade_rain = df.groupby([df.year // 10 * 10, df.rain_octsep // 1000 * 1000])[['outflow_octsep',
'outflow_decfeb', 'outflow_junaug']].mean()
decade_rain
接下来是
unstack,最开始可能有一些困惑,它可以将一列数据设置为列标签。最好还是看看实际的操作:
# Unstacking
decade_rain.unstack(0)
这条语句将上例中的 dataframe 转换为下面的形式。它将第 0 列,也就是
year列设置为列的标签。

让我们再操作一次。这次使用第 1 列,也就是
rain_octsep列:
# More unstacking
decade_rain.unstack(1)

在进行下次操作之前,我们先创建一个用于演示的 dataframe :
# Create a new dataframe containing entries which # has rain_octsep values of greater than 1250
high_rain = df[df.rain_octsep > 1250] high_rain
上面的代码将会产生如下的 dataframe ,我们将会在上面演示轴向旋转(pivoting)。

轴旋转其实就是我们之前已经看到的那些操作的一个集合。首先,它会设置一个新的索引(
set_index()),然后对索引排序(
sort_index()),最后调用
unstack。以上的步骤合在一起就是
pivot。接下来看看你能不能搞清楚下面的代码在干什么:
#Pivoting#does set_index, sort_index and unstack in a row
high_rain.pivot('year', 'rain_octsep')[['outflow_octsep', 'outflow_decfeb', 'outflow_junaug']].fillna('')
注意,最后有一个
.fillna('') 。pivot产生了很多空的记录,也就是值为
NaN的记录。我个人觉得数据集里面有很多
NaN会很烦,所以使用了
fillna('') 。你也可以用别的别的东西,比方说 0 。我们也可以使用 dropna(how = 'any')来删除有
NaN的行,不过这样就把所有的数据都删掉了,所以不这样做。
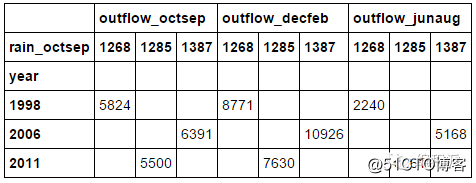
上面的 dataframe 展示了所有降雨超过 1250 的
outflow。诚然,这并不是讲解
pivot实际应用最好的例子,但希望你能明白它的意思。看看你能在你的数据集上得到什么结果。
合并数据集
有时你有两个相关联的数据集,你想将它们放在一起比较或者合并它们。好的,没问题,在 Pandas 里很简单:
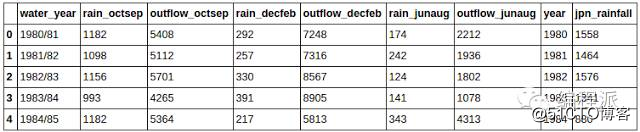
# Merging two datasets together
rain_jpn = pd.read_csv('jpn_rain.csv')
rain_jpn.columns = ['year', 'jpn_rainfall']
uk_jpn_rain = df.merge(rain_jpn, on='year')
uk_jpn_rain.head(5)
首先你需要通过
on关键字来指定需要合并的列。通常你可以省略这个参数,Pandas 将会自动选择要合并的列。
如下图所示,两个数据集在年份这一类上合并了。
jpn_rain数据集只有年份和降雨量两列,通过年份列合并之后,
jpn_rain中只有降雨量那一列合并到了
UK_rain数据集中。
使用 Pandas 快速作图
Matplotlib很棒,但是想要绘制出还算不错的图表却要写不少代码,而有时你只是想粗略的做个图来探索下数据,搞清楚数据的含义。Pandas 通过
plot来解决这个问题:
# Using pandas to quickly plot graphs
uk_jpn_rain.plot(x='year', y=['rain_octsep', 'jpn_rainfall'])
这会调用
Matplotlib快速轻松地绘出了你的数据图。通过这个图你就可以在视觉上分析数据,而且它能在探索数据的时候给你一些方向。比如,看到我的数据图,你会发现在 1995 年的英国好像有一场干旱。
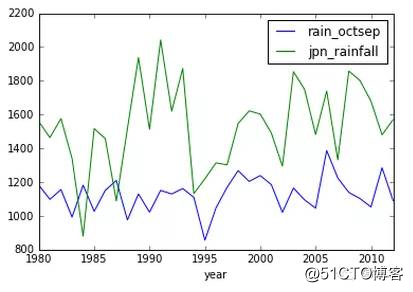
你会发现英国的降雨明显少于日本,但人们却说英国总是下雨。
保存你的数据集
在清洗、重塑、探索完数据之后,你最后的数据集可能会发生很大改变,并且比最开始的时候更有用。你应该保存原始的数据集,但是你同样应该保存处理之后的数据。
# Saving your data to a csv
df.to_csv('uk_rain.csv')
上面的代码将会保存你的数据到
csv文件以便下次使用。
我们对 Pandas 的介绍就到此为止了。就像我之前所说的, Pandas 非常强大,我们只是领略到了一点皮毛而已,不过你现在知道的应该足够你开始清洗和探索数据了。
像以前一样,我建议你用自己感兴趣的数据集做一下练习,坐下来,一杯啤酒配数据。这确实是你唯一熟悉
Pandas以及这个系列其他库的方式。而且你也许会发现一些有趣的东西。

- Java基础系列:多线程基础
- 码农男友用 Python 写了个机器人,租到了让女友满意的房子
- 如何用 Python 制作 GIF 动图?
- 高手分享:如何立即跳出两重嵌套循环?
- 跟着一起写一个多人在线游戏(一)
- 惊艳!还能用代码生成这样的画作
- 看完这三篇教程,估计你可以写一个多人在线游戏出来了
- CSS系列 (01):属性书写分类-个人向
- nacos注册中心源码流程分析
- aliyun-sdk-vod-upload爆红
- 探究 position-sticky 失效问题
- 最通俗易懂的囚徒困境
- 闭关修炼180天--手写持久层框架(mybatis简易版)
- 制作3D小汽车游戏(上)
- 算法入门题:如何反转一个单向链表?
- 利用nginx为多个xxljob配置统一入口
- SkyWalking拓朴图group功能改造
- R语言分布滞后线性和非线性模型(DLM和DLNM)建模
- MySQL资料整理
- 快速搭建一款鸿蒙分布式分歧终端机原型